Visualisation native en PySpark
Créez facilement des visualisations directement à partir des DataFrames PySpark
par Xinrong Meng et Ruifeng Zheng
- Introduction à la visualisation native en PySpark : Ce blog explique le besoin de capacités de visualisation intégrées en PySpark, s'alignant sur les fonctionnalités que les utilisateurs attendent de Pandas API sur Spark et des DataFrames pandas natifs.
- Fonctionnalités clés et capacités : Nous expliquons les différents types de graphiques pris en charge, comment la visualisation PySpark exploite des stratégies de traitement de données efficaces (par exemple, échantillonnage, métriques globales) et l'intégration avec Plotly pour les visualisations.
- Exemple pratique : Nous démontrons la visualisation PySpark avec un exemple pratique, guidant les lecteurs à travers la création et la personnalisation de visualisations, et mettant en évidence les informations exploitables dérivées des graphiques.
Introduction
Nous sommes ravis de présenter la visualisation native en PySpark avec Databricks Runtime 17.0 (notes de mise à jour), un bond en avant passionnant pour la visualisation des données. Fini le passage d'un outil à l'autre juste pour visualiser vos données ; vous pouvez désormais créer des graphiques magnifiques et intuitifs directement à partir de vos DataFrames PySpark. C'est rapide, transparent et intégré. Cette fonctionnalité tant attendue rend l'exploration de vos données plus facile et plus puissante que jamais.
Travailler avec de grands volumes de données en PySpark a toujours été puissant, en particulier lorsqu'il s'agit de transformer et d'analyser des ensembles de données à grande échelle. Bien que les DataFrames PySpark soient conçus pour l'échelle et la performance, les utilisateurs devaient auparavant les convertir en DataFrames Pandas API sur Apache Spark™ pour générer des graphiques. Mais cette étape supplémentaire rendait les flux de travail de visualisation plus compliqués qu'ils ne devaient l'être. La différence de structure entre PySpark et les DataFrames de style pandas entraînait souvent des frictions, ralentissant le processus d'exploration visuelle des données.
Exemple
Voici un exemple d'utilisation de la visualisation PySpark pour analyser les ventes, les profits et les marges bénéficiaires dans diverses catégories de produits.
Nous commençons avec un DataFrame contenant des données de ventes et de profits pour différentes catégories de produits, comme montré ci-dessous :
Notre objectif est de visualiser la relation entre les ventes et les profits, tout en intégrant la marge bénéficiaire comme dimension visuelle supplémentaire pour rendre l'analyse plus significative. Voici le code pour créer le graphique :
Notez que « fig » est de type « plotly.graph_objs._figure.Figure ». Nous pouvons améliorer son apparence en mettant à jour la mise en page à l'aide des fonctionnalités Plotly existantes. La figure ajustée ressemble à ceci :
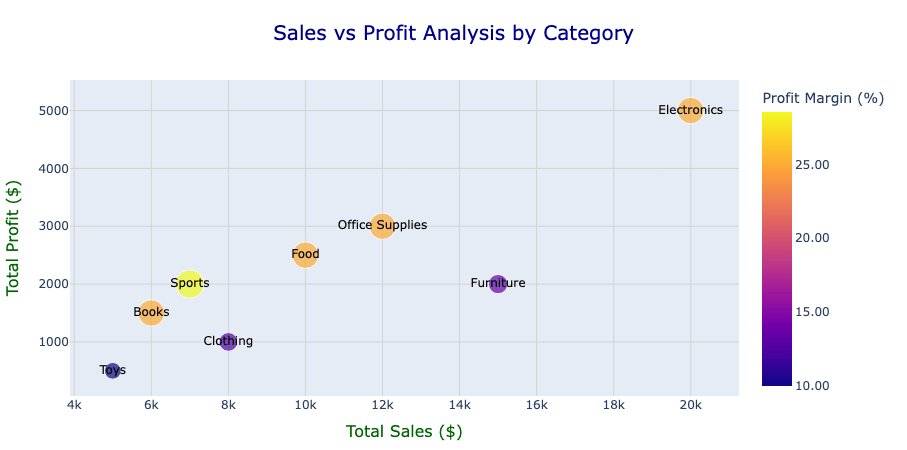
D'après la figure, nous pouvons observer des relations claires entre les ventes et les profits dans différentes catégories. Par exemple, l'électronique montre des ventes et des profits élevés avec une marge bénéficiaire relativement modérée, indiquant une forte génération de revenus mais une marge d'amélioration de l'efficacité.
Fonctionnalités de la visualisation PySpark
Interface utilisateur
L'utilisateur interagit avec la visualisation PySpark en appelant la propriété plot sur un DataFrame PySpark et en spécifiant le type de graphique souhaité soit comme sous-méthode, soit en définissant le paramètre « kind ». Par exemple :
ou de manière équivalente :
Cette conception s'aligne sur les interfaces de Pandas API sur Apache Spark et de pandas natif, offrant une expérience cohérente et intuitive aux utilisateurs déjà familiarisés avec la visualisation pandas.
Types de graphiques pris en charge
La visualisation PySpark prend en charge une variété de types de graphiques courants, tels que les graphiques linéaires, à barres (y compris horizontaux), en aires, de dispersion, circulaires, en boîte, histogrammes et graphiques de densité/KDE. Cela permet aux utilisateurs de visualiser les tendances, les distributions, les comparaisons et les relations directement à partir des DataFrames PySpark.
Fonctionnement interne
La fonctionnalité est alimentée par Plotly (version 4.8 ou ultérieure) comme backend de visualisation par défaut, offrant des capacités de visualisation riches et interactives, tandis que pandas natif est utilisé en interne pour traiter les données de la plupart des graphiques.
Selon le type de graphique, le traitement des données dans la visualisation PySpark est géré selon l'une des trois stratégies suivantes :
- Top N lignes : Le processus de visualisation utilise un nombre limité de lignes du DataFrame (par défaut : 1000). Cela peut être configuré à l'aide de l'option « spark.sql.pyspark.plotting.max_rows », ce qui le rend efficace pour des aperçus rapides. Cela s'applique aux graphiques à barres, aux graphiques à barres horizontales et aux graphiques circulaires.
- Échantillonnage : L'échantillonnage aléatoire représente efficacement la distribution globale sans traiter l'ensemble du jeu de données. Cela garantit la scalabilité tout en maintenant la représentativité. Cela s'applique aux graphiques en aires, aux graphiques linéaires et aux graphiques de dispersion.
- Métriques globales : Pour les graphiques en boîte, les histogrammes et les graphiques de densité/KDE, les calculs sont effectués sur l'ensemble du jeu de données. Cela permet une représentation précise des distributions de données, garantissant l'exactitude statistique.
Cette approche respecte les stratégies de visualisation de Pandas API sur Apache Spark pour chaque type de graphique, avec des améliorations de performance supplémentaires :
- Échantillonnage : Auparavant, deux passages sur l'ensemble du jeu de données étaient nécessaires : un pour calculer le ratio d'échantillonnage et un autre pour effectuer l'échantillonnage réel. Nous avons implémenté une nouvelle méthode basée sur l'échantillonnage par réservoir, la réduisant à un seul passage.
- Sous-graphiques : Dans les cas où chaque colonne correspond à un sous-graphique, nous calculons désormais les métriques pour toutes les colonnes ensemble, améliorant ainsi l'efficacité.
- Graphiques basés sur ML : Nous avons introduit des expressions SQL internes dédiées pour ces graphiques, permettant des optimisations côté SQL telles que la génération de code.
Conclusion
La visualisation native en PySpark comble le fossé entre PySpark et la visualisation intuitive des données. Cette fonctionnalité permet aux utilisateurs de PySpark de créer des graphiques de haute qualité directement à partir de leurs DataFrames PySpark, rendant l'analyse des données plus rapide et plus accessible que jamais. N'hésitez pas à essayer cette fonctionnalité sur Databricks Runtime 17.0 pour améliorer votre expérience de visualisation des données !
Prêt à en explorer davantage ? Consultez la documentation de l'API PySpark pour des guides et des exemples détaillés.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.