Comment lire les tables Unity Catalog dans Snowflake, en 3 étapes simples
Unity Catalog fonctionne désormais avec Snowflake, Dremio, Starburst, EMR et plus encore - pour vous aider à unifier les données et l'IA
par Aniruth Narayanan, Randy Pitcher, Susan Pierce et Ryan Johnson
Apprenez à vous connecter aux API REST Iceberg d'Unity Catalog depuis Snowflake pour lire un fichier de données source unique en tant qu'Iceberg.
Mise à jour : Ce billet de blog a été mis à jour pour refléter la prise en charge par Snowflake des identifiants fournis par le catalogue.
Databricks a été le pionnier de l'architecture ouverte de lakehouse de données et est à l'avant-garde de l'interopérabilité des formats. Nous sommes ravis de voir davantage de plateformes adopter l'architecture lakehouse et commencer à utiliser des formats et des normes interopérables. L'interopérabilité permet aux clients de réduire la duplication coûteuse des données en utilisant une seule copie des données avec les outils d'analyse et d'IA de leur choix pour leurs charges de travail. En particulier, un modèle courant pour nos clients consiste à utiliser les meilleures performances/prix ETL de Databricks pour les données en amont, en y accédant à partir d'outils de BI et d'analyse, tels que Snowflake.
Unity Catalog est une solution de gouvernance unifiée et ouverte pour les actifs de données et d'IA. Une fonctionnalité clé d'Unity Catalog est son implémentation des API Iceberg REST Catalog. Cela permet d'utiliser facilement un lecteur compatible Iceberg sans avoir à actualiser manuellement votre emplacement de métadonnées.
Dans ce billet de blog, nous expliquerons l'utilité de l'API Iceberg REST Catalog et présenterons un exemple de lecture des tables Unity Catalog dans Snowflake.
Remarque : Cette fonctionnalité est disponible sur tous les fournisseurs de cloud. Les instructions suivantes sont spécifiques à AWS S3, mais il est possible d'utiliser d'autres plateformes de stockage d'objets telles qu'Azure Data Lake Storage (ADLS) ou Google Cloud Storage (GCS).
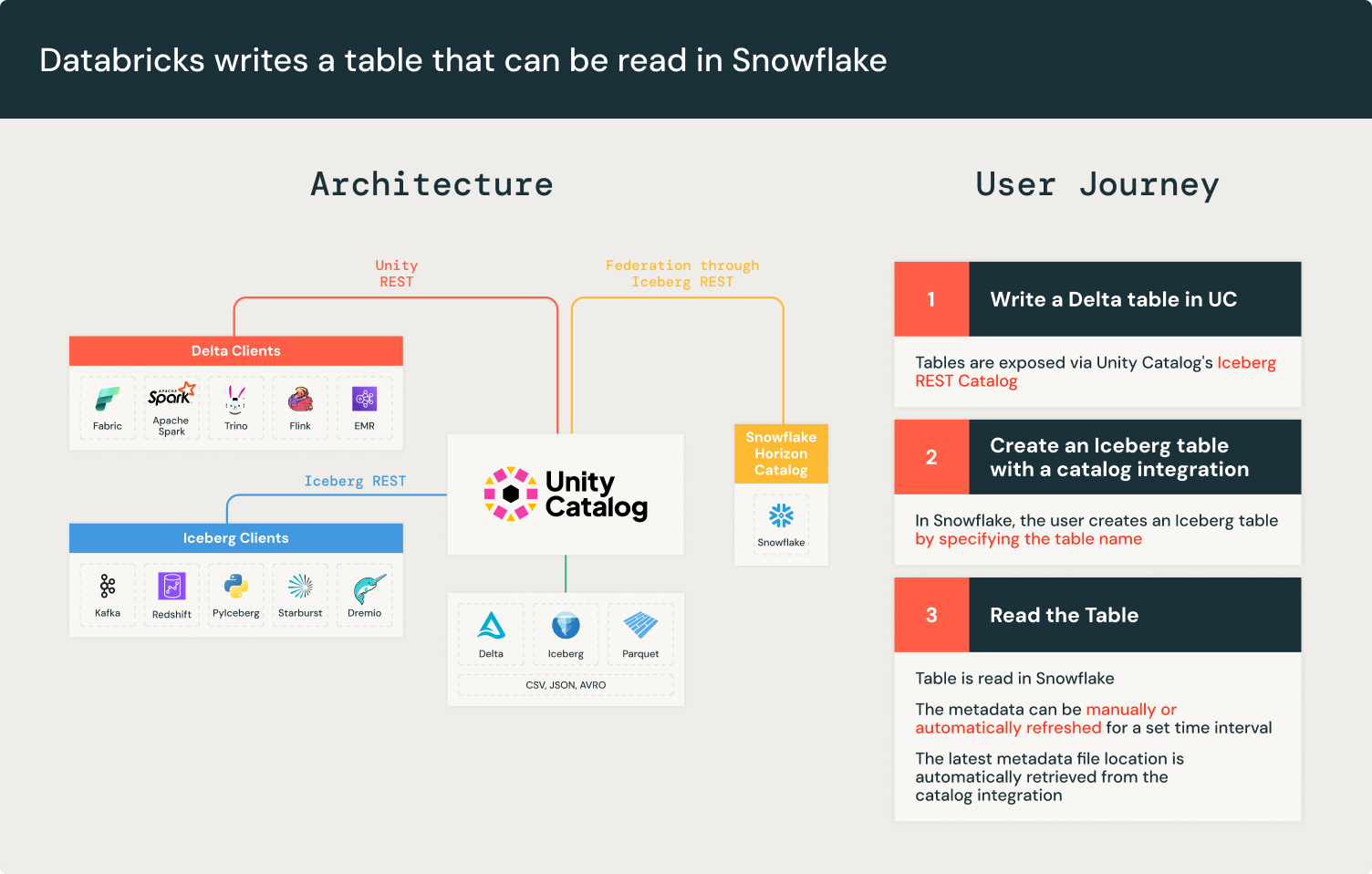
Intégration du catalogue Iceberg REST API
Apache Iceberg™ maintient l'atomicité et la cohérence en créant de nouveaux fichiers de métadonnées pour chaque modification de table. Cela garantit que les écritures incomplètes ne corrompent pas un fichier de métadonnées existant. Le catalogue Iceberg suit les nouvelles métadonnées par écriture. Cependant, tous les moteurs ne peuvent pas se connecter à tous les catalogues Iceberg, ce qui oblige les clients à suivre manuellement l'emplacement du nouveau fichier de métadonnées.
Iceberg résout l'interopérabilité entre les moteurs et les catalogues avec l'API Iceberg REST Catalog. Le catalogue REST Iceberg est une spécification d'API ouverte et standardisée qui est une interface unifiée pour les catalogues Iceberg, découplant les implémentations de catalogue des clients.
Unity Catalog implémente les API Iceberg REST Catalog depuis le lancement d'Universal Format (UniForm) en 2023. Unity Catalog expose les métadonnées de table les plus récentes, garantissant l'interopérabilité avec tout client Iceberg compatible avec l'API Iceberg REST Catalog tel qu'Apache Spark™, Apache Trino et Snowflake. Les points de terminaison Iceberg REST Catalog d'Unity Catalog permettent aux systèmes externes d'accéder aux tables et de bénéficier d'améliorations de performances telles que Liquid Clustering et Predictive Optimization, tandis que les charges de travail Databricks continuent de bénéficier des fonctionnalités avancées d'Unity Catalog telles que Change Data Feed. De plus, les points de terminaison Iceberg REST Catalog d'Unity Catalog étendent la gouvernance via des identifiants fournis.
L'intégration de catalogue REST de Snowflake permet de se connecter aux API Iceberg REST d'Unity Catalog pour récupérer l'emplacement du dernier fichier de métadonnées. Cela signifie qu'avec Unity Catalog, vous pouvez lire les tables directement dans Snowflake.
Remarque : Au moment de la rédaction, la prise en charge par Snowflake de l'API Iceberg REST Catalog est en préversion publique. Cependant, les API Iceberg REST d'Unity Catalog sont généralement disponibles.
Il y a 3 étapes pour créer une intégration de catalogue REST dans Snowflake :
- Activer UniForm sur une table Delta Lake dans Databricks pour générer des métadonnées Iceberg
- Enregistrer Unity Catalog dans Snowflake comme votre catalogue
- Créer une table Iceberg dans Snowflake afin que vous puissiez interroger vos données
Démarrage
Nous commencerons dans Databricks, avec notre table gérée par Unity Catalog, et nous nous assurerons qu'elle peut être lue en tant qu'Iceberg. Ensuite, nous passerons à Snowflake pour effectuer les étapes restantes.
Avant de commencer, quelques composants sont nécessaires :
- Un compte Databricks avec Unity Catalog (activé par défaut pour les nouveaux espaces de travail)
- Un compartiment S3 AWS et des privil�èges IAM
- Un compte Snowflake capable d'accéder à votre instance Databricks et à S3
Les espaces de noms Unity Catalog suivent le format nom_catalogue.nom_schema.nom_table. Dans l'exemple ci-dessous, nous utiliserons uc_catalog_name.uc_schema_name.uc_table_name pour notre table Databricks.
Étape 1 : Activer UniForm sur une table Delta dans Databricks
Dans Databricks, vous pouvez activer UniForm sur une table Delta Lake. Par défaut, les nouvelles tables sont gérées par Unity Catalog. Les instructions complètes sont disponibles dans la documentation UniForm mais sont également incluses ci-dessous.
Pour une nouvelle table, vous pouvez activer UniForm lors de la création de la table dans votre espace de travail :
Si vous avez une table existante, vous pouvez le faire via une commande ALTER TABLE :
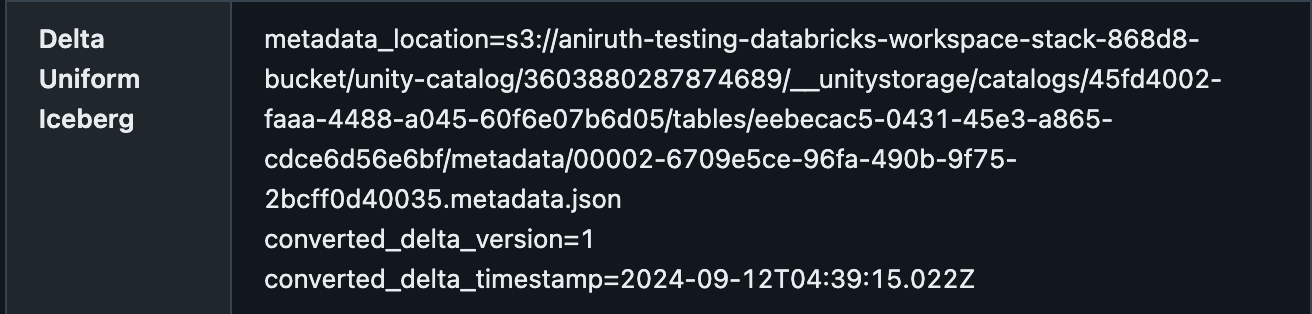
Vous pouvez confirmer qu'une table Delta a UniForm activé dans le Catalog Explorer sous l'onglet Détails, avec l'emplacement des métadonnées. Cela devrait ressembler à ceci :
Étape 2 : Enregistrer Unity Catalog dans Snowflake
Toujours dans Databricks, créez un principal de service à partir des paramètres d'administration de l'espace de travail et générez le secret et l'ID client associés. Au lieu d'un principal de service, vous pouvez également vous authentifier avec des jetons personnels à des fins de débogage et de test. Nous recommandons d'utiliser un principal de service pour les charges de travail de développement et de production. Pour cette étape, vous aurez besoin de votre <deployment-name> et des valeurs de votre <client-id> et <secret> OAuth afin de pouvoir authentifier l'intégration dans Snowflake.
Passez maintenant à votre compte Snowflake.
Remarque : Il existe quelques différences de nommage entre Databricks et Snowflake qui peuvent prêter à confusion :
- Un « catalogue » dans Databricks est un « entrepôt » dans la configuration de l'intégration du catalogue Iceberg de Snowflake.
- Un « schéma » dans Databricks est un « catalog_namespace » dans l'intégration du catalogue Iceberg de Snowflake.
Vous verrez dans l'exemple ci-dessous que la valeur CATALOG_NAMESPACE est uc_schema_name de notre table Unity Catalog.
Dans Snowflake, créez une intégration de catalogue pour les catalogues REST Iceberg. En suivant ce processus, vous créerez une intégration de catalogue comme ci-dessous :
L'intégration de catalogue REST débloque également les informations d'identification fournies et l'actualisation automatique basée sur le temps.
Les informations d'identification fournies comprennent à la fois l'emplacement de stockage d'une table et une information d'identification d'accès temporaire pour accéder à cet emplacement. Cela permet aux clients d'accéder aux tables via le catalogue sans configurer l'accès direct du client à l'emplacement de stockage de la table. Nous recommandons d'utiliser les informations d'identification fournies pour simplifier et centraliser la gouvernance dans le catalogue. Dans l'exemple ci-dessus, nous configurons Snowflake pour utiliser les informations d'identification fournies par Unity Catalog avec le paramètre ACCESS_DELEGATION_MODE = VENDED_CREDENTIALS dans l'objet REST_CONFIG.
Actuellement, Snowflake ne prend en charge que les informations d'identification fournies pour les tables dans AWS S3. Pour les tables dans Azure Data Lake Storage (ADLS) ou Google Cloud Storage (GCS), Snowflake nécessite un accès direct à l'emplacement de stockage de la table avec un volume externe.
Avec l'actualisation automatique, Snowflake interrogera l'emplacement des métadonnées le plus récent d'Unity Catalog à un intervalle de temps défini pour l'intégration du catalogue. Cependant, l'actualisation automatique est incompatible avec l'actualisation manuelle, obligeant les utilisateurs à attendre jusqu'à l'intervalle de temps après une mise à jour de table. Le paramètre REFRESH_INTERVAL_SECONDS configuré sur l'intégration du catalogue s'applique à toutes les tables Snowflake Iceberg créées avec cette intégration. Il n'est pas personnalisable par table.
Étape 3 : Créer une table Apache Iceberg™ dans Snowflake
Dans Snowflake, créez une table Iceberg avec l'intégration de catalogue précédemment créée pour vous connecter à la table Delta Lake. Vous pouvez choisir le nom de votre table Iceberg dans Snowflake ; il n'a pas besoin de correspondre à la table Delta Lake dans Databricks.
Remarque : Le mappage correct pour CATALOG_TABLE_NAME dans Snowflake est le nom de la table Databricks. Dans notre exemple, il s'agit de uc_table_name. Vous n'avez pas besoin de spécifier le catalogue ou le schéma à cette étape, car ils ont déjà été spécifiés dans l'intégration du catalogue.
Facultativement, vous pouvez activer l'actualisation automatique en utilisant l'intervalle de temps de l'intégration du catalogue en ajoutant AUTO_REFRESH = TRUE à la commande. Notez que si l'actualisation automatique est activée, l'actualisation manuelle est désactivée.
Vous avez maintenant lu avec succès la table Delta Lake dans Snowflake.
Finalisation : Tester la connexion
Dans Databricks, mettez à jour les données de la table Delta en insérant une nouvelle ligne.
Si vous avez précédemment activé l'actualisation automatique, la table sera mise à jour automatiquement selon l'intervalle de temps spécifié. Si vous ne l'avez pas fait, vous pouvez actualiser manuellement en exécutant ALTER ICEBERG TABLE <snowflake_table_name> REFRESH.
Remarque : si vous avez précédemment activé l'actualisation automatique, vous ne pouvez pas exécuter la commande d'actualisation manuelle et devrez attendre que l'intervalle d'actualisation automatique soit terminé pour actualiser la table.
Nous sommes ravis du soutien continu à l'architecture lakehouse. Les clients n'ont plus à dupliquer de données, ce qui réduit les coûts et la complexité. Cette architecture permet également aux clients de choisir le bon outil pour la bonne charge de travail.
La clé d'un lakehouse ouvert est de stocker vos données dans un format ouvert tel que Delta Lake ou Iceberg. Les formats propriétaires enferment les clients dans un moteur, mais les formats ouverts vous offrent flexibilité et portabilité. Quelle que soit la plateforme, nous encourageons les clients à toujours posséder leurs propres données comme première étape vers l'interopérabilité. Dans les mois à venir, nous continuerons à développer des fonctionnalités qui simplifieront la gestion d'un lakehouse de données ouvert avec Unity Catalog.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.