Reranking dans Databricks AI Search pour une récupération plus rapide et plus intelligente dans les agents RAG
Fournissez des réponses plus pertinentes en moins de temps avec une seule ligne de code
par Adam Gurary, Andrew Drozdov, Erik Lindgren, Ankit Vij, Dima Kotlyarov, Michael Carbin, Sergei Tsarev et Bruce Fontaine
- Changement de code en une ligne pour un boost instantané de la qualité de l'agent : Ajoutez un seul paramètre à vos requêtes AI Search pour améliorer la qualité de l'agent de 15 points de pourcentage en moyenne sur nos benchmarks d'entreprise.
- Intégration transparente avec vos agents : Prise en charge native de LangChain et d'autres frameworks, reranking multi-colonnes pour un contexte plus riche, et métriques de performance intégrées.
- Performances constantes à l'échelle : Une nouvelle architecture de reranking parallélisée atteint une latence aussi basse que 1,5 seconde sur 50 documents tout en offrant une pertinence extrêmement élevée, surpassant les principales alternatives cloud.
Pour de nombreuses organisations, le plus grand défi avec les agents IA construits sur des données non structurées n'est pas le modèle, mais le contexte. Si l'agent ne parvient pas à récupérer les bonnes informations, même le modèle le plus avancé manquera des détails clés et donnera des réponses incomplètes ou incorrectes.
Nous introduisons le reranking dans Databricks AI Search, maintenant en aperçu public. Avec un seul paramètre, vous pouvez améliorer la précision de la récupération de 15 points de pourcentage en moyenne sur nos benchmarks d'entreprise. Cela signifie des réponses de meilleure qualité, un meilleur raisonnement et des performances d'agent plus cohérentes, sans infrastructure supplémentaire ni configuration complexe.
Qu'est-ce que le reranking ?
Le reranking est une technique qui améliore la qualité de l'agent en garantissant que l'agent obtient les données les plus pertinentes pour accomplir sa tâche. Alors que les bases de données vectorielles excellent à trouver rapidement des documents pertinents parmi des millions de candidats, le reranking applique une compréhension contextuelle plus approfondie pour garantir que les résultats les plus pertinents sémantiquement apparaissent en haut. Cette approche en deux étapes - récupération rapide suivie d'un réordonnancement intelligent - est devenue essentielle pour les systèmes d'agents RAG où la qualité compte.
Pourquoi avons-nous ajouté le reranking ?
Vous pourriez construire des agents de chat internes pour répondre aux questions sur vos documents. Ou vous pourriez construire des agents qui génèrent des rapports pour vos clients. Dans tous les cas, si vous voulez construire des agents capables d'utiliser avec précision vos données non structurées, la qualité est liée à la récupération. Le reranking est la façon dont les clients de AI Search améliorent la qualité de leur récupération et, par conséquent, la qualité de leurs agents RAG.
D'après les retours des clients, nous avons constaté deux problèmes courants :
- Les agents peuvent manquer un contexte critique enfoui dans de grands ensembles de documents non structurés. Le passage « juste » se trouve rarement tout en haut des résultats récupérés d'une base de données vectorielle.
- Les systèmes de reranking maison augmentent considérablement la qualité des agents, mais il faut des semaines pour les construire, puis une maintenance importante.
En faisant du reranking une fonctionnalité native de AI Search, vous pouvez utiliser vos données d'entreprise gouvernées pour faire remonter les informations les plus pertinentes sans ingénierie supplémentaire.
La fonctionnalité de reranker a aidé à élever notre chatbot Lexi, passant d'un fonctionnement d'étudiant de lycée à celui de diplômé en droit. Nous avons constaté des gains transformateurs dans la façon dont nos systèmes comprennent, raisonnent et génèrent du contenu à partir de documents juridiques, débloquant des informations qui étaient auparavant enfouies dans des données non structurées. —David Brady, Senior Director, G3 Enterprises
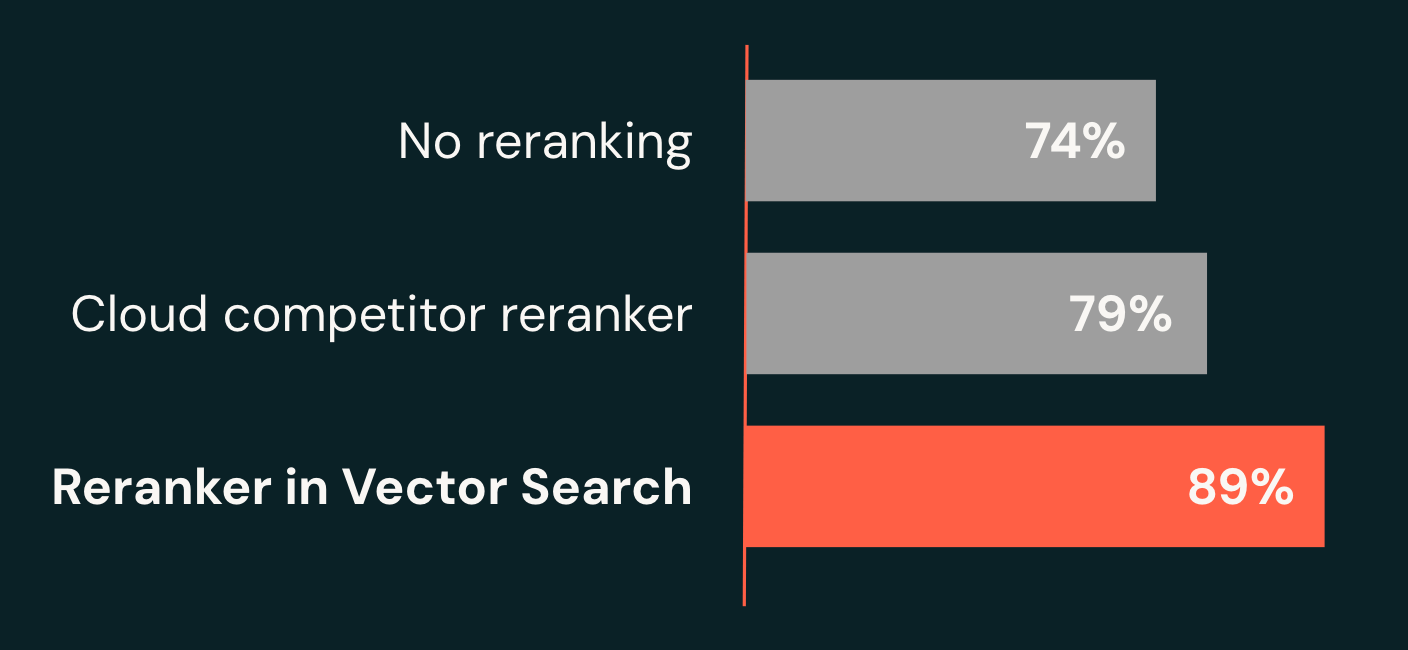
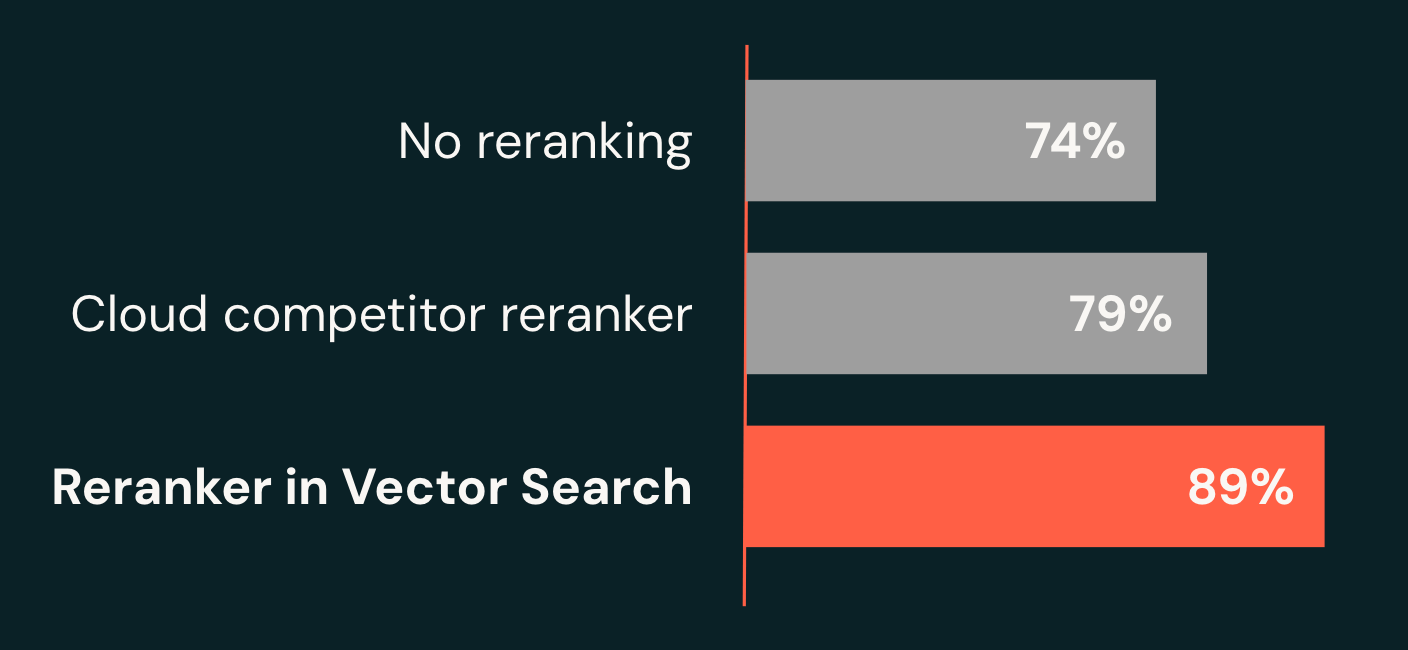
Une amélioration substantielle de la qualité par rapport aux bases de référence
Notre équipe de recherche a réalisé une percée en construisant un système d'IA composite novateur pour les charges de travail des agents. Sur nos benchmarks d'entreprise, le système récupère la bonne réponse dans ses 10 meilleurs résultats 89 % du temps (recall@10), soit une amélioration de 15 points par rapport à notre base de référence (74 %) et 10 points de plus que les principales alternatives cloud (79 %). De manière cruciale, notre reranker offre cette qualité avec des latences aussi basses que 1,5 seconde, alors que les systèmes contemporains prennent souvent plusieurs secondes, voire des minutes, pour renvoyer des réponses de haute qualité.
{kind=link}
Récupération facile et de haute qualité
Activez le reranking de niveau entreprise en quelques minutes, pas en quelques semaines. Les équipes passent généralement des semaines à rechercher des modèles, à déployer l'infrastructure et à écrire une logique personnalisée. En revanche, l'activation du reranking pour AI Search nécessite un seul paramètre supplémentaire dans votre requête AI Search pour obtenir instantanément une récupération de meilleure qualité pour vos agents. Aucun point de terminaison de service de modèle à gérer, aucun wrapper personnalisé à maintenir, aucune configuration complexe à régler.
En spécifiant plusieurs colonnes dans columns_to_rerank, vous amenez la qualité du reranker au niveau supérieur en lui donnant accès aux métadonnées au-delà du texte principal. Dans cet exemple, le reranker utilise les résumés de contrat et les informations de catégorie pour mieux comprendre le contexte et améliorer la pertinence des résultats de recherche.
Optimisé pour les performances des agents
La vitesse rencontre la qualité pour l'IA en temps réel et les applications agentiques. Notre équipe de recherche a optimisé ce système d'IA composite pour reranker 50 résultats en aussi peu que 1,5 seconde. Cela le rend très efficace pour les systèmes d'agents qui exigent à la fois précision et réactivité. Cette performance révolutionnaire permet des stratégies de récupération sophistiquées sans compromettre l'expérience utilisateur.
Quand utiliser le reranking ?
Nous recommandons de tester le reranking pour tout cas d'utilisation d'agent RAG. Typiquement, les clients verront des gains de qualité massifs lorsque leurs systèmes actuels trouvent la bonne réponse quelque part dans les 50 meilleurs résultats de la récupération, mais peinent à la faire remonter dans les 10 meilleurs. En termes techniques, cela signifie que les clients ont un faible recall@10 mais un recall@50 élevé.
Expérience développeur améliorée
Au-delà des capacités de reranking de base, nous facilitons plus que jamais la création et le déploiement de systèmes de récupération de haute qualité.
Intégration LangChain : Reranker fonctionne de manière transparente avec VectorSearchRetrieverTool, notre intégration officielle LangChain pour AI Search. Les équipes qui construisent des agents RAG avec VectorSearchRetrieverTool peuvent bénéficier d'une récupération de meilleure qualité, sans modification de code.
Métriques de performance transparentes : La latence du reranker est désormais incluse dans les informations de débogage des requêtes, vous donnant une ventilation complète de bout en bout des performances de votre requête.
répartition de la latence de réponse en millisecondes
Sélection flexible des colonnes : Rerank basé sur n'importe quelle combinaison de colonnes de texte et de métadonnées, vous permettant d'exploiter tout le contexte du domaine disponible - des résumés de documents aux catégories en passant par les métadonn�ées personnalisées - pour une haute pertinence.
Commencez à construire dès aujourd'hui
Le reranker dans AI Search transforme la façon dont vous construisez des applications d'IA. Avec zéro surcharge d'infrastructure et une intégration transparente, vous pouvez enfin offrir la qualité de récupération que vos utilisateurs méritent.
Prêt à commencer ?
- Essayez Reranking dans AI Search dès aujourd'hui - ajoutez simplement un paramètre à vos requêtes AI Search existantes
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.