Clusters partagés dans Unity Catalog pour la victoire : Présentation des bibliothèques de clusters, des UDF Python, de Scala, du Machine Learning et plus encore
par Jakob Mund, Stefania Leone, Martin Grund, Herman van Hövell, Andrew Li et Sven Wagner-Boysen
Nous sommes ravis d'annoncer que vous pouvez exécuter encore plus de charges de travail sur les clusters multi-utilisateurs hautement efficaces de Databricks grâce aux nouvelles fonctionnalités de sécurité et de gouvernance dans Unity Catalog. Les équipes de données peuvent désormais développer et exécuter des charges de travail SQL, Python et Scala en toute sécurité sur des ressources de calcul partagées. Avec cela, Databricks est la seule plateforme de l'industrie offrant un contrôle d'accès granulaire sur le calcul partagé pour les charges de travail Scala, Python et SQL Spark.
À partir de Databricks Runtime 13.3 LTS, vous pouvez déplacer en toute transparence vos charges de travail vers des clusters partagés, grâce aux fonctionnalités suivantes disponibles sur les clusters partagés :
- Bibliothèques de cluster et scripts d'initialisation : Simplifiez la configuration du cluster en installant des bibliothèques de cluster et en exécutant des scripts d'initialisation au démarrage, avec une sécurité et une gouvernance améliorées pour définir qui peut installer quoi.
- Scala : Exécutez en toute sécurité des charges de travail Scala multi-utilisateurs aux côtés de Python et SQL, avec une isolation complète du code utilisateur entre les utilisateurs simultanés et en appliquant les autorisations Unity Catalog.
- UDF Python et Pandas. Exécutez en toute sécurité les UDF Python et (scalaires) Pandas, avec une isolation complète du code utilisateur entre les utilisateurs simultanés.
- Apprentissage automatique sur un seul nœud : Exécutez scikit-learn, XGBoost, prophet et d'autres bibliothèques ML populaires en utilisant le nœud pilote Spark, et utilisez MLflow pour gérer le cycle de vie complet de l'apprentissage automatique.
- Structured Streaming : Développez des solutions de traitement et d'analyse de données en temps réel en utilisant Structured Streaming.
Accès aux données simplifié dans Unity Catalog
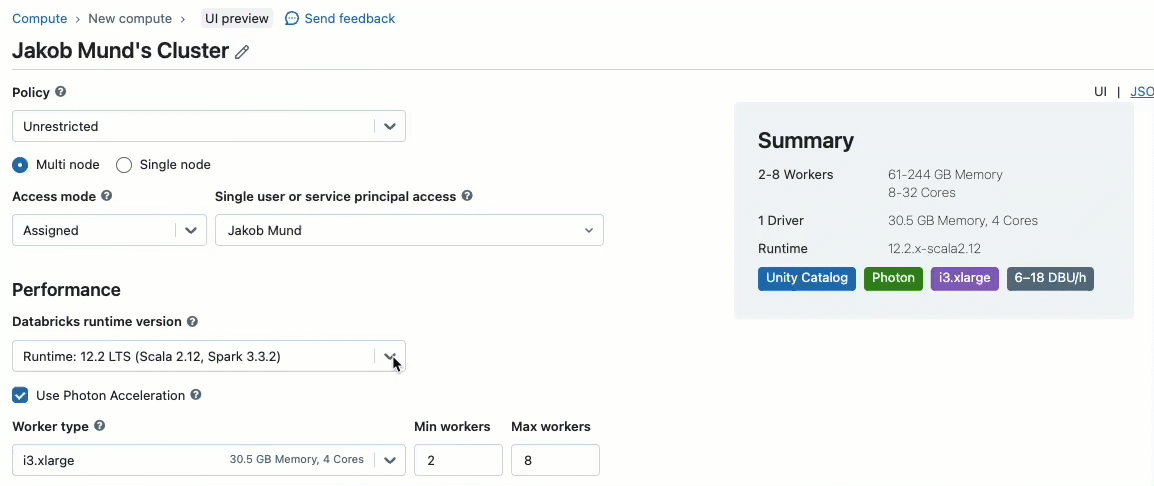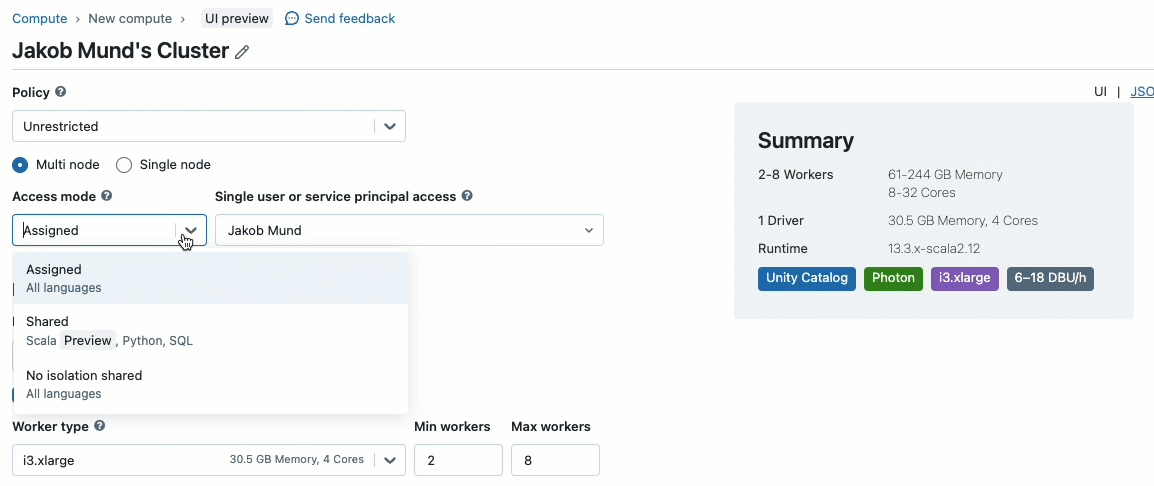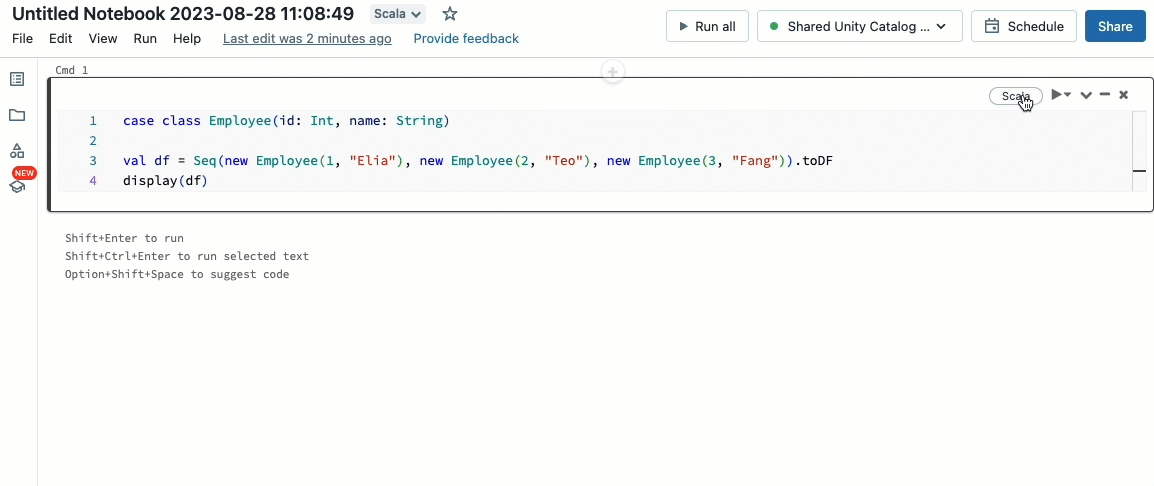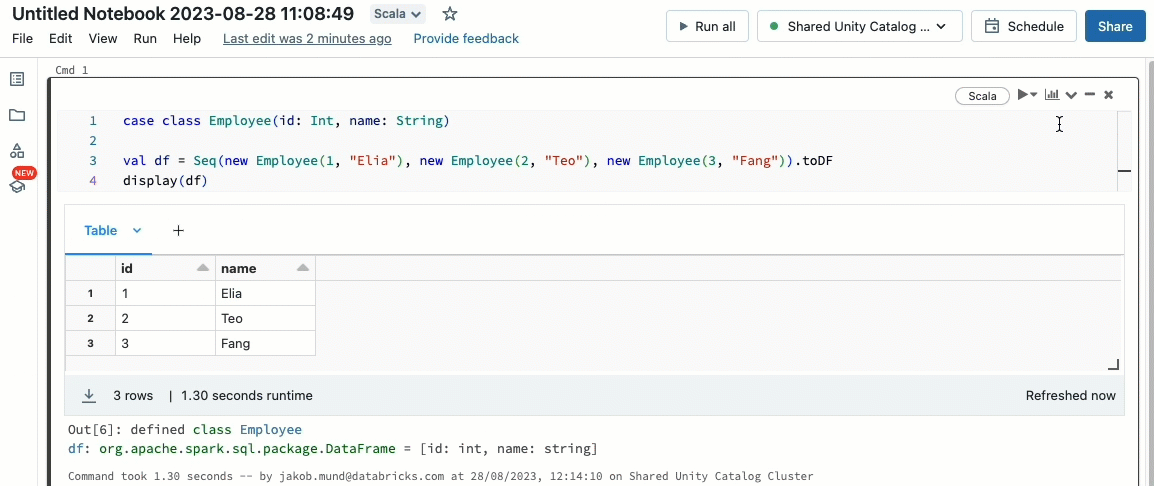
Lors de la création d'un cluster pour travailler avec des données régies par Unity Catalog, vous pouvez choisir entre deux modes d'accès :
- Clusters en mode d'accès partagé – ou simplement clusters partagés – sont les options de calcul recommandées pour la plupart des charges de travail. Les clusters partagés permettent à un nombre illimité d'utilisateurs de se connecter et d'exécuter simultanément des charges de travail sur la même ressource de calcul, permettant des économies de coûts importantes, une gestion simplifiée des clusters et une gouvernance des données holistique, y compris un contrôle d'accès granulaire. Ceci est réalisé grâce à l'isolation des charges de travail utilisateur d'Unity Catalog qui exécute tout code utilisateur SQL, Python et Scala en isolation complète sans accès aux ressources de niveau inférieur.
- Clusters en mode d'accès mono-utilisateur sont recommandés pour les charges de travail nécessitant un accès privilégié à la machine ou utilisant des API RDD, le ML distribué, les GPU, Databricks Container Service ou R.
Alors que les clusters mono-utilisateur suivent l'architecture Spark traditionnelle, où le code utilisateur s'exécute sur Spark avec un accès privilégié à la machine sous-jacente, les clusters partagés assurent l'isolation utilisateur de ce code. La figure ci-dessous illustre l'architecture et les primitives d'isolation uniques aux clusters partagés : tout code utilisateur côté client (Python, Scala) s'exécute en isolation complète et les UDF s'exécutant sur les exécuteurs Spark s'exécutent dans des environnements isolés. Avec cette architecture, nous pouvons multiplexer en toute sécurité les charges de travail sur les mêmes ressources de calcul et offrir une solution collaborative, rentable et sécurisée en même temps.
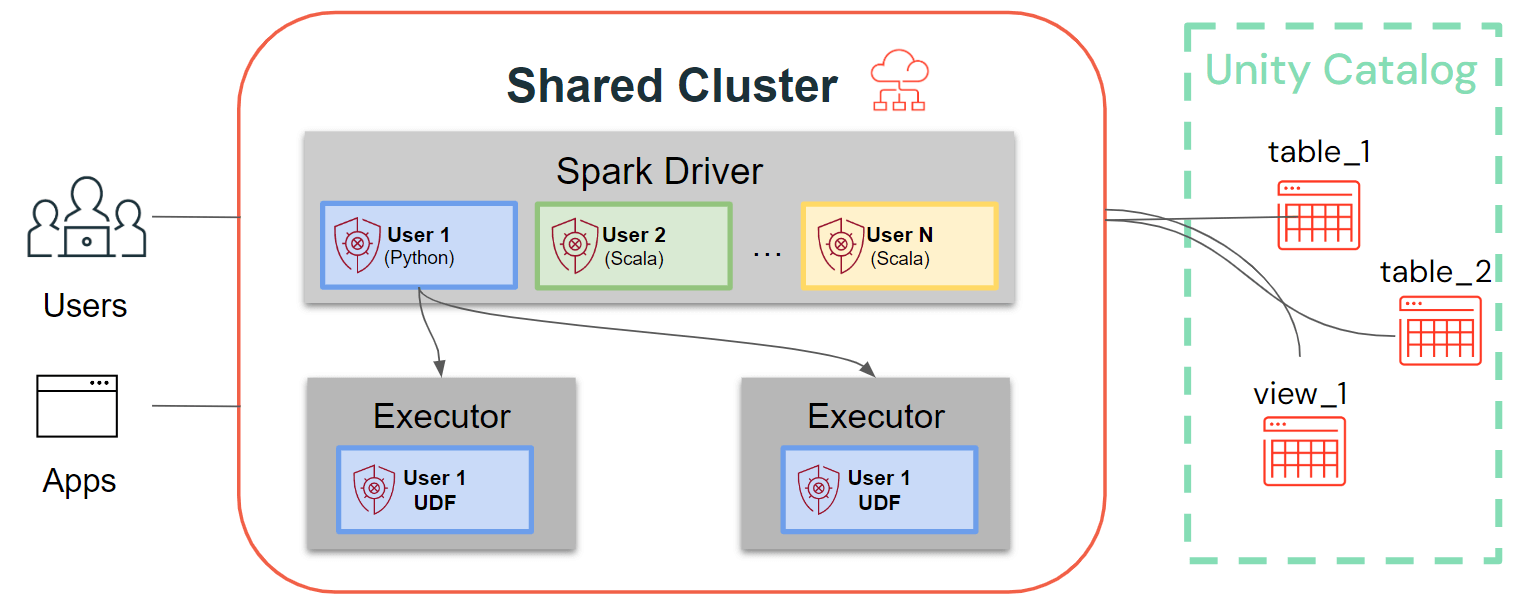
Dernières améliorations pour les clusters partagés : bibliothèques de cluster, scripts d'initialisation, UDF Python, Scala, ML et prise en charge du streaming
Configurez votre cluster partagé à l'aide de bibliothèques de cluster et de scripts d'initialisation
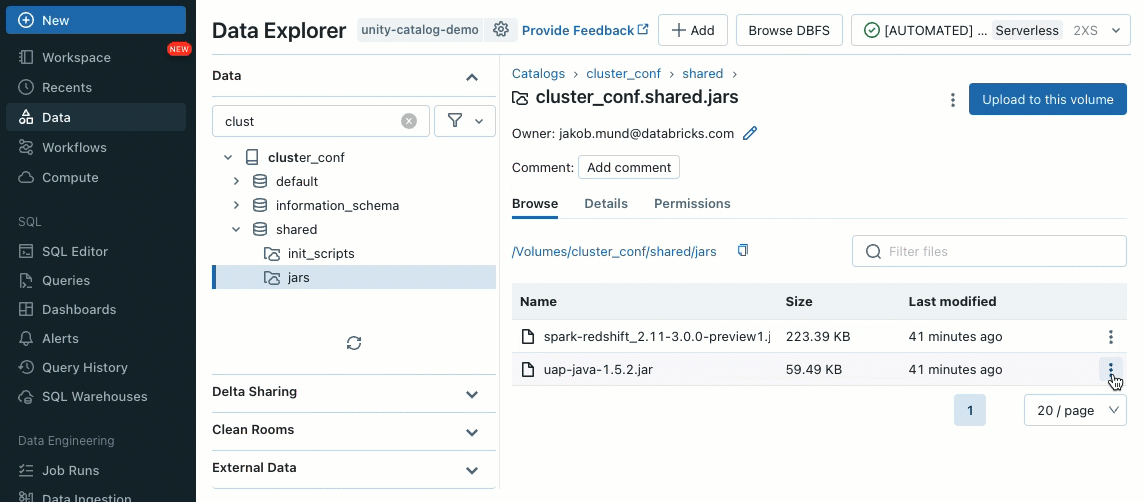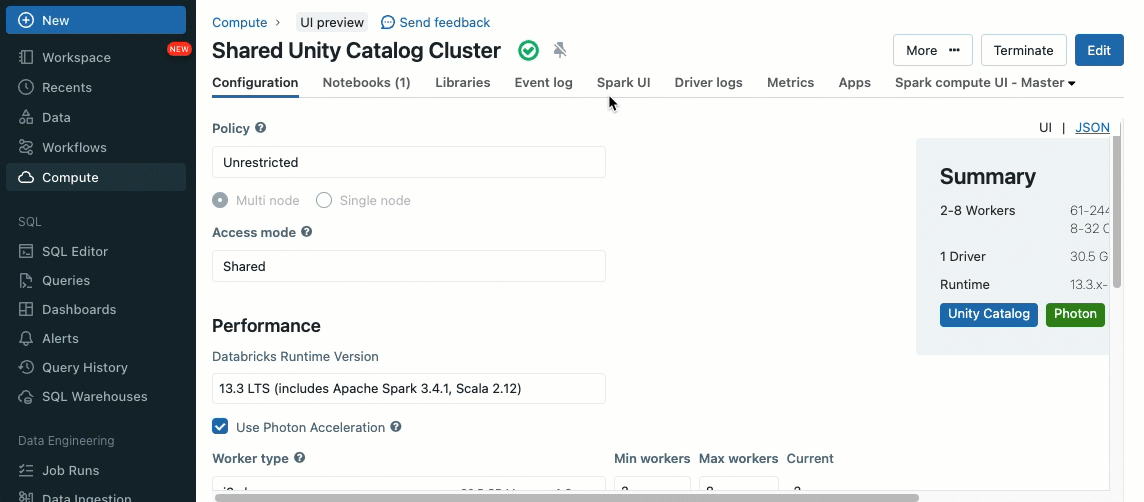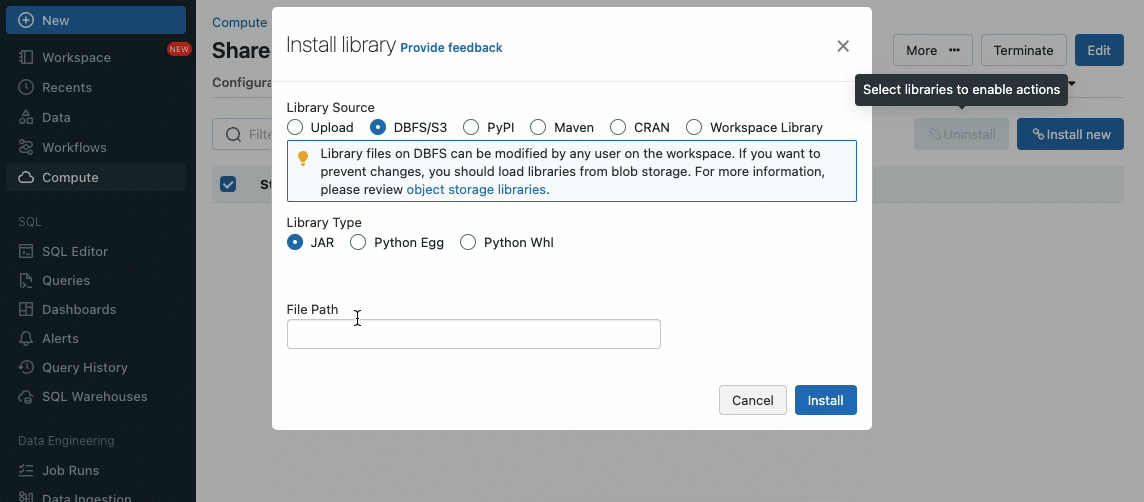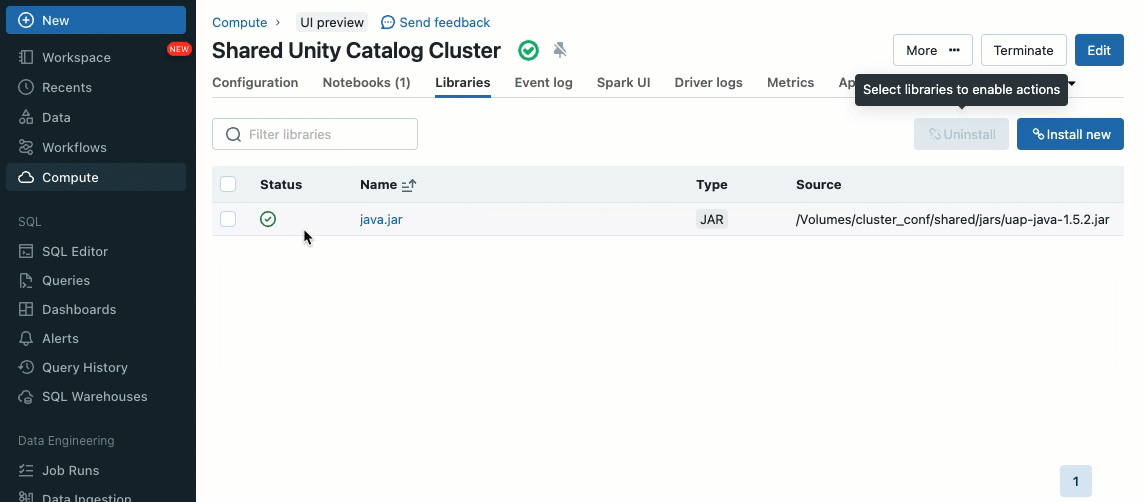
Les bibliothèques de cluster vous permettent de partager et de gérer facilement des bibliothèques pour un cluster, voire pour plusieurs clusters, en garantissant des versions cohérentes et en réduisant le besoin d'installations répétitives. Que vous ayez besoin d'intégrer des frameworks d'apprentissage automatique, des connecteurs de base de données ou d'autres composants essentiels à vos clusters, les bibliothèques de cluster offrent une solution centralisée et sans effort désormais disponible sur les clusters partagés.
Les bibliothèques peuvent être installées à partir de volumes Unity Catalog (AWS, Azure, GCP), de fichiers Workspace (AWS, Azure, GCP), PyPI/Maven et des emplacements de stockage cloud, en utilisant l'interface utilisateur ou l'API Cluster existante.
En utilisant les scripts d'initialisation, en tant qu'administrateur de cluster, vous pouvez exécuter des scripts personnalisés pendant le processus de création du cluster pour automatiser des tâches telles que la configuration des mécanismes d'authentification, la configuration des paramètres réseau ou l'initialisation des sources de données.
Les scripts d'initialisation peuvent être installés sur des clusters partagés, soit directement lors de la création du cluster, soit pour un parc de clusters à l'aide de politiques de cluster (AWS, Azure, GCP). Pour une flexibilité maximale, vous pouvez choisir d'utiliser un script d'initialisation à partir de volumes Unity Catalog (AWS, Azure, GCP) ou du stockage cloud.
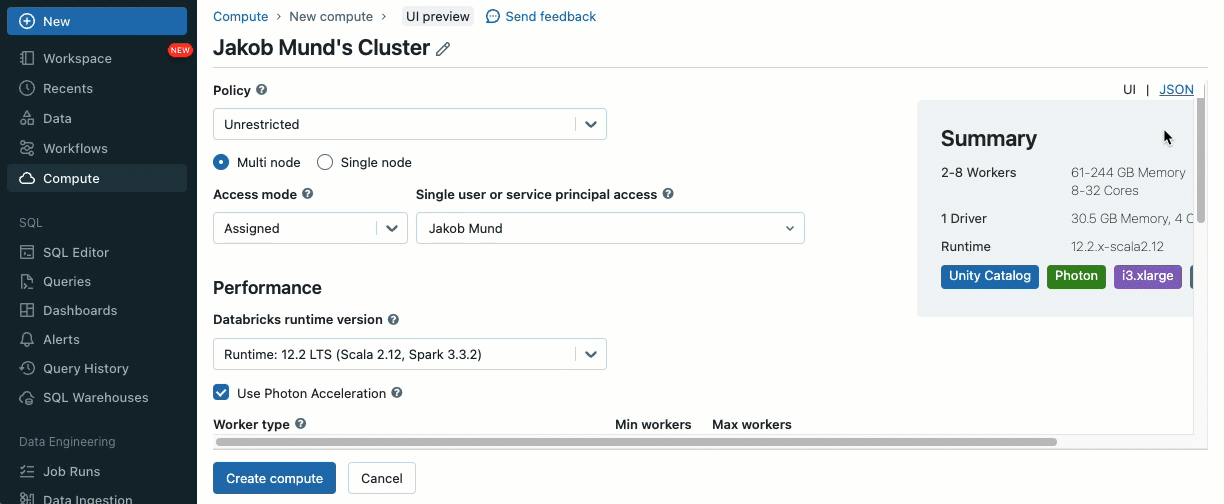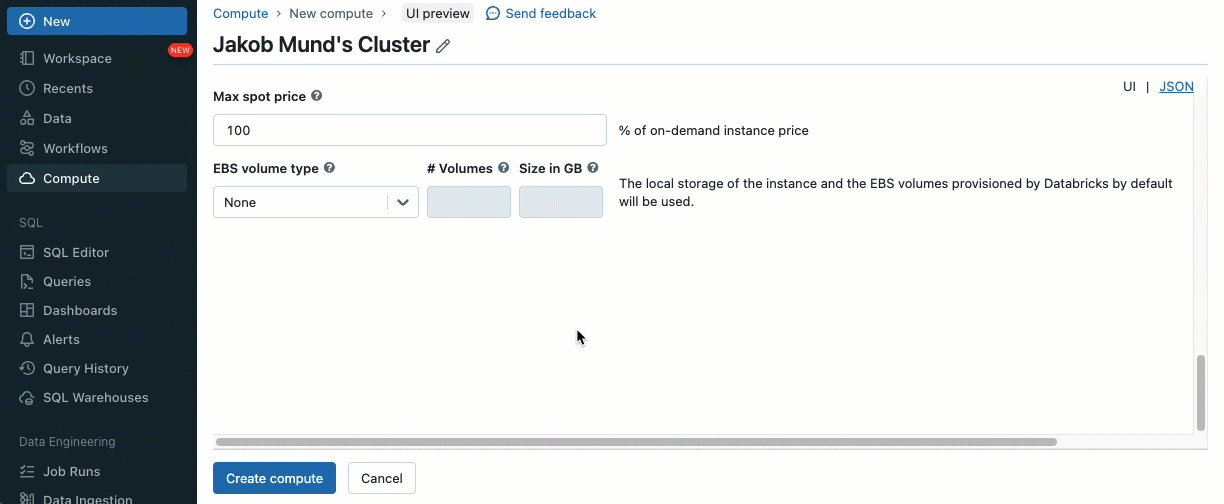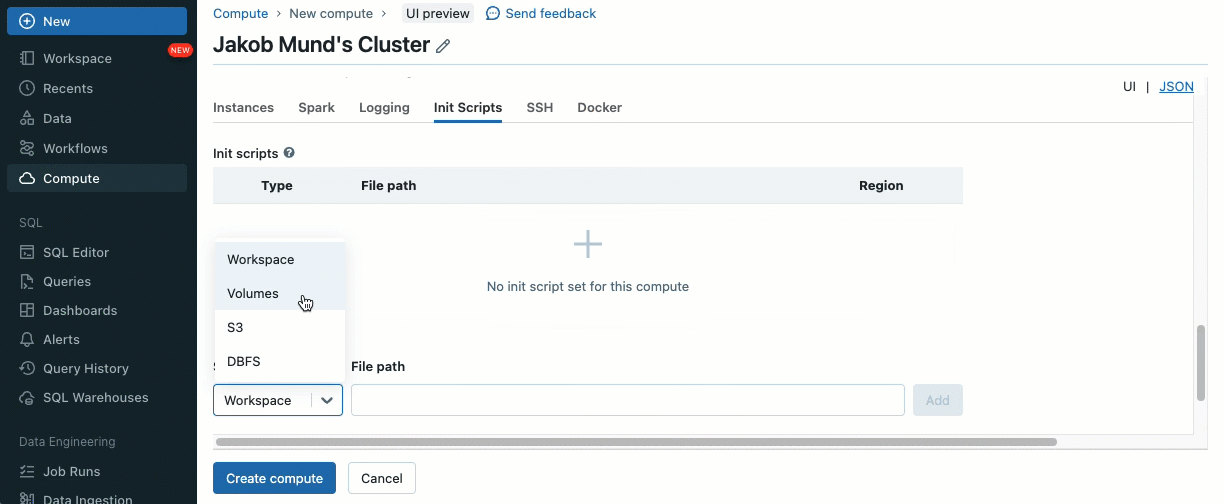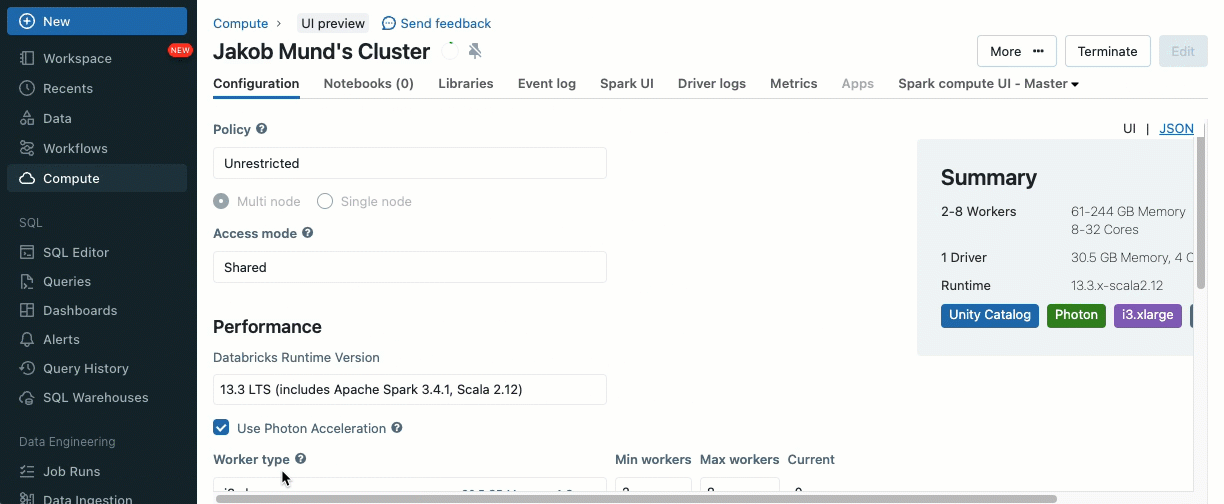
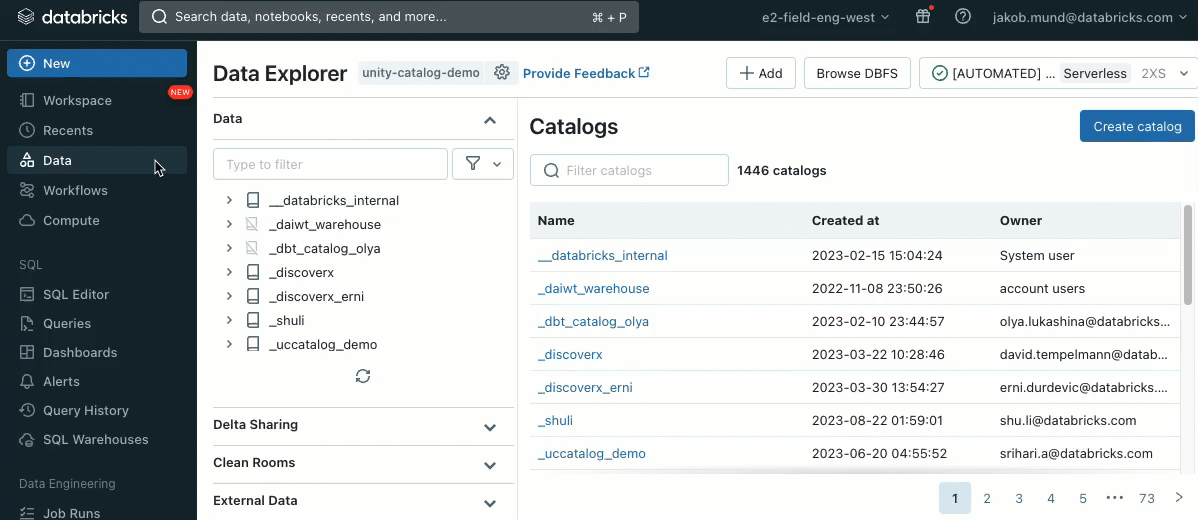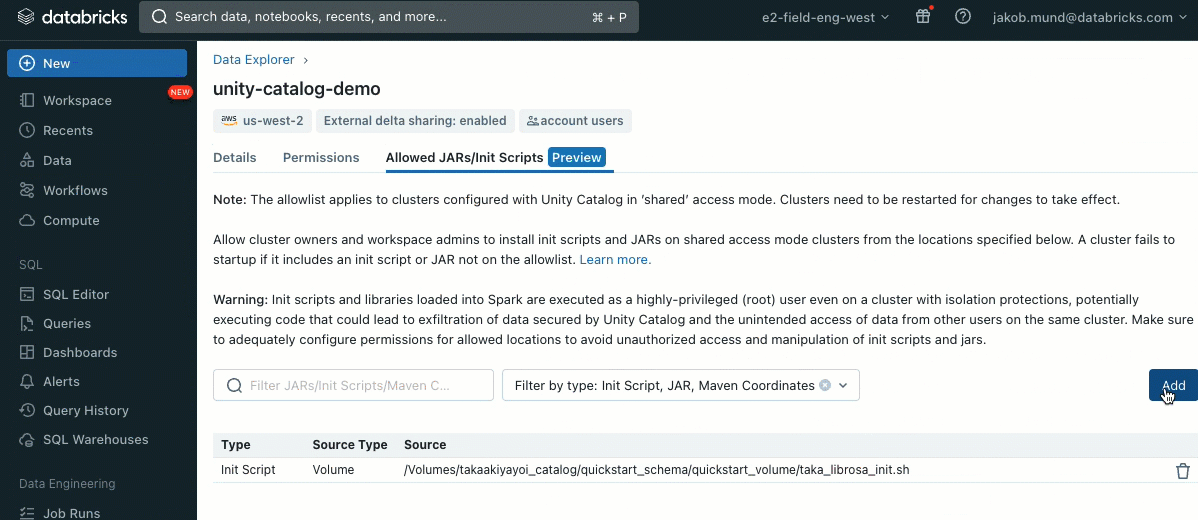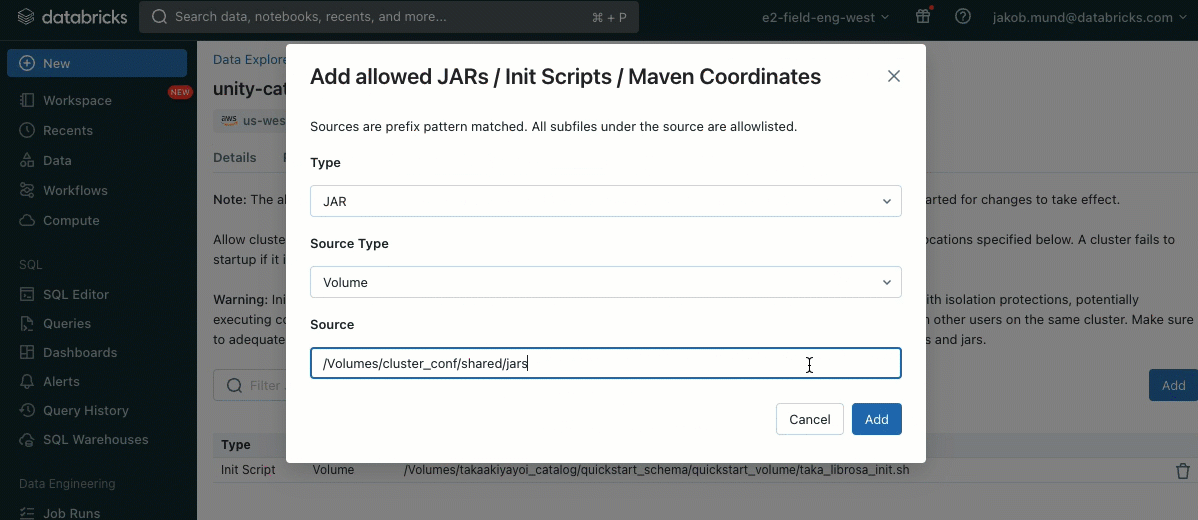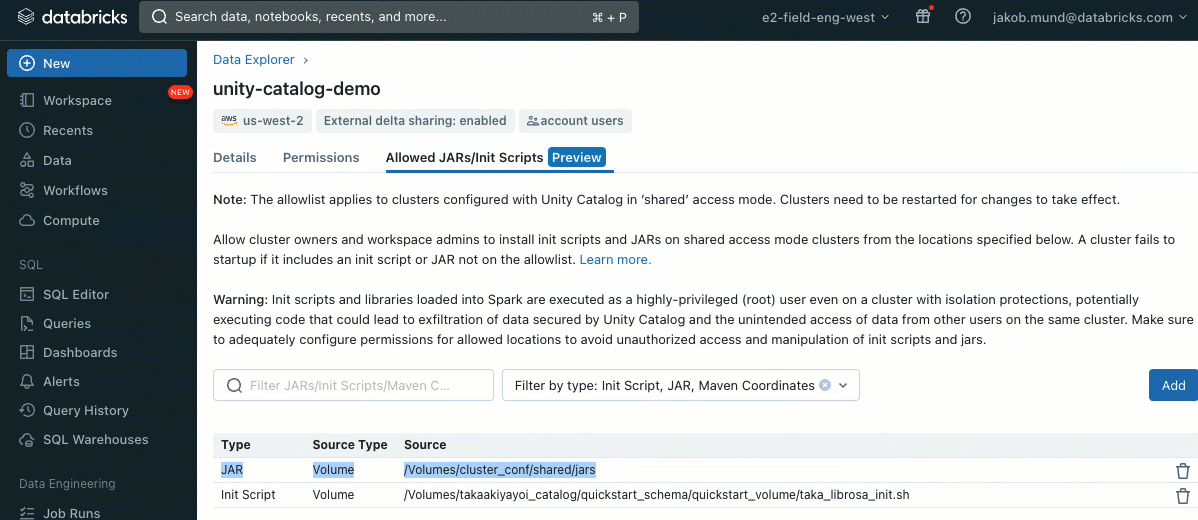
En tant que couche de sécurité supplémentaire, nous introduisons une liste d'autorisation (AWS, Azure, GCP) qui régit l'installation des bibliothèques de cluster (jars) et des scripts d'initialisation. Cela permet aux administrateurs de les gérer sur les clusters partagés. Pour chaque metastore, l'administrateur du metastore peut configurer les volumes et les emplacements de stockage cloud à partir desquels les bibliothèques (jars) et les scripts d'initialisation peuvent être installés, fournissant ainsi un référentiel centralisé de ressources de confiance et empêchant les installations non autorisées. Cela permet un contrôle plus granulaire sur les configurations des clusters et aide à maintenir la cohérence dans les flux de données de votre organisation.
Intégrez vos charges de travail Scala
Scala est désormais pris en charge sur les clusters partagés régis par Unity Catalog. Les ingénieurs de données peuvent tirer parti de la flexibilité et des performances de Scala pour relever toutes sortes de défis liés aux données volumineuses, de manière collaborative sur le même cluster et en profitant du modèle de gouvernance d'Unity Catalog.
L'intégration de Scala dans votre flux de travail Databricks existant est un jeu d'enfant. Sélectionnez simplement Databricks runtime 13.3 LTS ou une version ultérieure lors de la création d'un cluster partagé, et vous serez prêt à écrire et à exécuter du code Scala aux côtés d'autres langages pris en charge.
Tirez parti des fonctions définies par l'utilisateur (UDF), de l'apprentissage automatique et de Structured Streaming
Ce n'est pas tout ! Nous sommes ravis de dévoiler d'autres avancées révolutionnaires pour les clusters partagés.
Prise en charge des fonctions définies par l'utilisateur (UDF) Python et Pandas : Vous pouvez désormais exploiter la puissance des UDF Python et (scalaires) Pandas également sur les clusters partagés. Apportez simplement vos charges de travail aux clusters partagés de manière transparente - aucune adaptation de code n'est nécessaire. En isolant l'exécution du code utilisateur des UDF sur les exécuteurs Spark dans un environnement sandbox, les clusters partagés offrent une couche de protection supplémentaire pour vos données, empêchant les accès non autorisés et les violations potentielles.
Prise en charge de toutes les bibliothèques ML populaires utilisant le nœud pilote Spark et MLflow : Que vous travailliez avec Scikit-learn, XGBoost, prophet et d'autres bibliothèques ML populaires, vous pouvez désormais créer, entraîner et déployer en toute transparence des modèles d'apprentissage automatique directement sur des clusters partagés. Pour installer des bibliothèques ML pour tous les utilisateurs, vous pouvez utiliser les nouvelles bibliothèques de cluster. Avec la prise en charge intégrée de MLflow (2.2.0 ou version ultérieure), la gestion du cycle de vie complet de l'apprentissage automatique n'a jamais été aussi simple.
Structured Streaming est également désormais disponible sur les clusters partagés régis par Unity Catalog. Cet ajout transformateur permet le traitement et l'analyse de données en temps réel, révolutionnant la façon dont vos équipes de données gèrent les charges de travail de streaming de manière collaborative.
Commencez dès aujourd'hui, d'autres bonnes choses à venir
Découvrez la puissance de Scala, des bibliothèques de cluster, des UDF Python, du ML sur nœud unique et du streaming sur des clusters partagés dès aujourd'hui en utilisant simplement Databricks Runtime 13.3 LTS ou une version ultérieure. Veuillez consulter les guides de démarrage rapide (AWS, Azure, GCP) pour en savoir plus et commencer votre parcours vers l'excellence des données.
Dans les semaines et les mois à venir, nous continuerons à unifier l'architecture de calcul d'Unity Catalog et à simplifier encore davantage l'utilisation d'Unity Catalog !
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.