Simplifiez l'ingestion de données avec la nouvelle API Python Data Source
par Craig Lukasik et Allison Wang
Ce billet de blog explique comment la nouvelle API Python Data Source de Spark simplifie l'ingestion des données IoT.
Les équipes d'ingénierie des données sont souvent chargées de créer des solutions d'ingestion personnalisées pour une multitude de sources de données personnalisées, propriétaires ou spécifiques à un secteur. De nombreuses équipes trouvent que ce travail de création de solutions d'ingestion est fastidieux et prend beaucoup de temps. Conscient de ces défis, nous avons interrogé de nombreuses entreprises de différents secteurs pour mieux comprendre leurs divers besoins en matière d'intégration de données. Ces commentaires complets nous ont conduits au développement de l'API Python pour les sources de données personnalisées pour Apache Spark™.
L'un des clients avec lesquels nous avons travaillé en étroite collaboration est Shell. Les défaillances d'équipement dans le secteur de l'énergie peuvent avoir des conséquences importantes, affectant la sécurité, l'environnement et la stabilité opérationnelle. Chez Shell, la minimisation de ces risques est une priorité, et l'une des façons d'y parvenir est de se concentrer sur le fonctionnement fiable des équipements.
Shell possède un vaste parc d'actifs et d'équipements d'une valeur de plus de 180 milliards de dollars. Pour gérer les énormes quantités de données générées par les opérations de Shell, ils s'appuient sur des outils avancés qui améliorent la productivité et permettent à leurs équipes de données de travailler de manière transparente sur diverses initiatives. La plateforme d'intelligence de données Databricks joue un rôle crucial en démocratisant l'accès aux données et en favorisant la collaboration entre les analystes, les ingénieurs et les scientifiques de Shell. Cependant, l'intégration des données IoT a posé des défis pour certains cas d'utilisation.
En utilisant notre travail avec Shell comme exemple, ce blog explorera comment cette nouvelle API aborde les défis précédents et fournira un exemple de code pour illustrer son application.
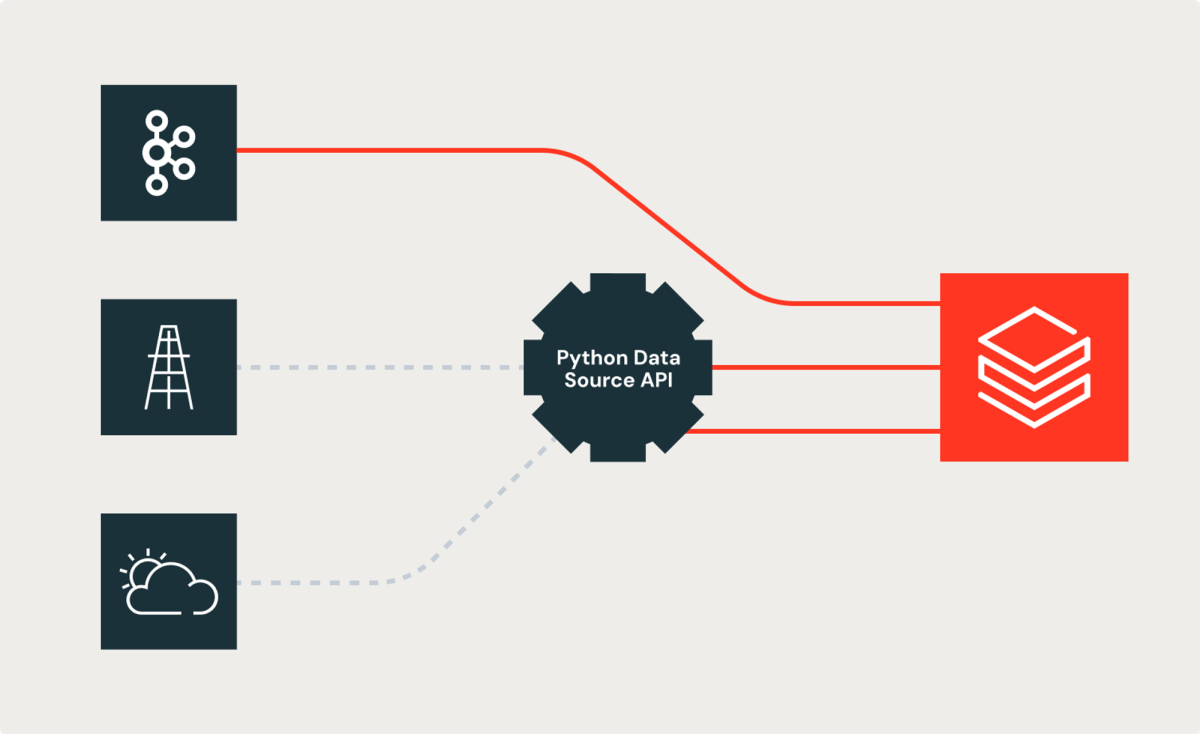
Le défi
Tout d'abord, examinons le défi rencontré par les ingénieurs de données de Shell. Bien que de nombreuses sources de données dans leurs pipelines de données utilisent des sources Spark intégrées (par exemple, Kafka), certaines s'appuient sur des API REST, des SDK ou d'autres mécanismes pour exposer les données aux consommateurs. Les ingénieurs de données de Shell ont eu du mal avec ce fait. Ils ont fini par créer des solutions personnalisées pour joindre des données provenant de sources Spark intégrées avec des données provenant de ces sources. Ce défi a consumé le temps et l'énergie des ingénieurs de données. Comme on le voit souvent dans les grandes organisations, de telles implémentations personnalisées introduisent des incohérences dans les implémentations et les résultats. Bryce Bartmann, conseiller en technologie numérique chez Shell, souhaitait la simplicité, nous disant : « Nous écrivons beaucoup d'API REST intéressantes, y compris pour les cas d'utilisation de streaming, et nous aimerions simplement les utiliser comme source de données dans Databricks au lieu d'écrire nous-mêmes tout le code de plomberie. »
« Nous écrivons beaucoup d'API REST intéressantes, y compris pour les cas d'utilisation de streaming, et nous aimerions simplement les utiliser comme source de données dans Databricks au lieu d'écrire nous-mêmes tout le code de plomberie. » - Bryce Bartmann, conseiller en technologie numérique, Shell
La solution
La nouvelle API Python pour les sources de données personnalisées atténue le problème en permettant d'aborder le problème à l'aide de concepts orientés objet. La nouvelle API fournit des classes abstraites qui permettent d'encapsuler du code personnalisé, tel que des recherches basées sur des API REST, et de les présenter comme une autre source ou un autre récepteur Spark.
Les ingénieurs de données veulent la simplicité et la composabilité. Par exemple, imaginez que vous êtes un ingénieur de données et que vous souhaitez ingérer des données météorologiques dans votre pipeline de streaming. Idéalement, vous aimeriez écrire du code qui ressemble à ceci :
Ce code semble simple, et il est facile à utiliser pour les ingénieurs de données car ils sont déjà familiers avec l'API DataFrame. Auparavant, une approche courante pour accéder à une API REST dans un travail Spark consistait à utiliser un PandasUDF. Cet article montre à quel point il peut être compliqué d'écrire du code réutilisable capable de transférer des données vers une API REST en utilisant un Pandas UDF. La nouvelle API, en revanche, simplifie et standardise la manière dont les travaux Spark – en streaming ou par lots, récepteur ou source – fonctionnent avec des sources et des récepteurs non natifs.
Ensuite, examinons un exemple concret et montrons comment la nouvelle API nous permet de créer une nouvelle source de données (« weather » dans cet exemple). La nouvelle API offre des fonctionnalités pour les sources, les récepteurs, les lots et le streaming, et l'exemple ci-dessous se concentre sur l'utilisation de la nouvelle API de streaming pour implémenter une nouvelle source « weather ».
Utilisation de l'API Python pour les sources de données personnalisées – un scénario réel
Imaginez que vous êtes un ingénieur de données chargé de construire un pipeline de données pour un cas d'utilisation de maintenance prédictive qui nécessite des données de pression provenant d'équipements de tête de puits. Supposons que les métriques de température et de pression de la tête de puits transitent par Kafka à partir des capteurs IoT. Nous savons que Structured Streaming prend en charge nativement le traitement des données de Kafka. Jusqu'ici, tout va bien. Cependant, les exigences métier présentent un défi : le même pipeline de données doit également capturer les données météorologiques liées au site de la tête de puits, et ces données ne transitent pas par Kafka mais sont accessibles via une API REST. Les parties prenantes et les scientifiques des données savent que la météo a un impact sur la durée de vie et l'efficacité des équipements, et ces facteurs influencent les calendriers de maintenance des équipements.
Commencer simplement
La nouvelle API offre une option simple adaptée à de nombreux cas d'utilisation : l'API SimpleDataSourceStreamReader. L'API SimpleDataSourceStreamReader est appropriée lorsque la source de données a un faible débit et ne nécessite pas de partitionnement. Nous l'utiliserons dans cet exemple car nous n'avons besoin que de relevés météorologiques pour un nombre limité de sites de têtes de puits, et la fréquence des relevés météorologiques est faible.
Examinons un exemple simple utilisant l'API SimpleDataSourceStreamReader.
Nous expliquerons une approche plus complexe plus tard. L'autre approche, plus complexe, est idéale pour créer une source de données Python partitionnée. Pour l'instant, nous ne nous soucierons pas de ce que cela signifie. Au lieu de cela, nous montrerons un exemple utilisant l'API simple.
Exemple de code
L'exemple de code ci-dessous suppose que l'API « simple » est suffisante. La méthode __init__ est essentielle car c'est ainsi que la classe de lecteur (WeatherSimpleStreamReader ci-dessous) comprend les sites de puits que nous devons surveiller. La classe utilise une option « locations » pour identifier les emplacements à partir desquels émettre les informations météorologiques.
Maintenant que nous avons défini la classe de lecteur simple, nous devons l'intégrer dans une implémentation de la classe abstraite DataSource.
Maintenant que nous avons défini la DataSource et intégré une implémentation du lecteur de flux, nous devons enregistrer la DataSource auprès de la session Spark.
Cela signifie que la source de données météorologiques est une nouvelle source de flux avec les opérations familières de DataFrame que les ingénieurs de données connaissent bien. Ce point mérite d'être souligné car ces sources de données personnalisées profitent à toute l'équipe. Avec une approche plus orientée objet, l'équipe élargie devrait bénéficier de cette source de données si elle a besoin de données météorologiques dans le cadre de son cas d'utilisation. Ainsi, les ingénieurs de données pourraient vouloir extraire les sources de données personnalisées dans une bibliothèque Python wheel pour les réutiliser dans d'autres pipelines.
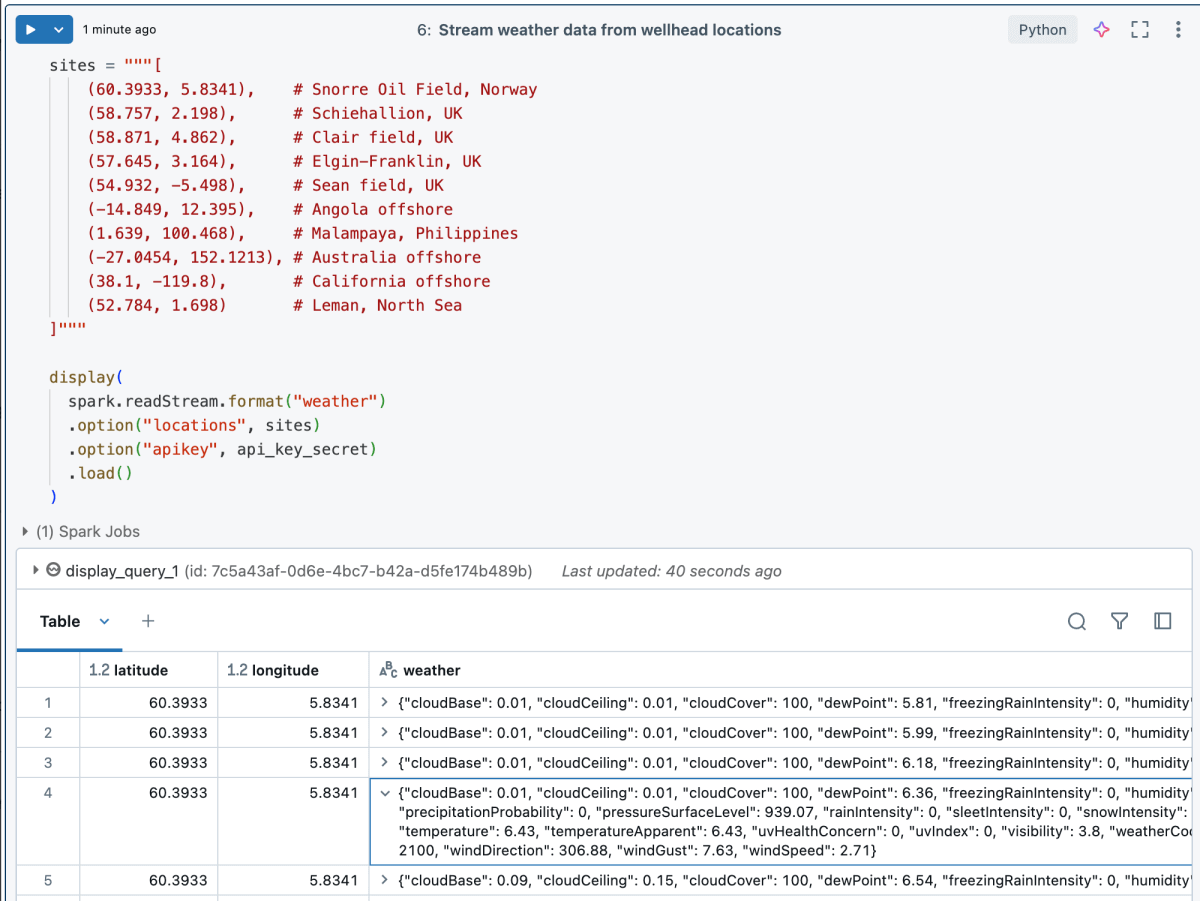
Ci-dessous, nous voyons à quel point il est facile pour l'ingénieur de données d'exploiter le flux personnalisé.
Exemple de résultats :
Autres considérations
Quand utiliser l'API consciente des partitions
Maintenant que nous avons parcouru l'API "simple" de la source de données Python, nous allons expliquer une option pour la prise en compte des partitions. Les sources de données conscientes des partitions vous permettent de paralléliser la génération de données. Dans notre exemple, une implémentation de source de données consciente des partitions entraînerait la division des emplacements entre plusieurs tâches par les tâches worker, afin que les appels à l'API REST puissent se propager sur les workers et le cluster. Encore une fois, notre exemple n'inclut pas cette sophistication car le volume de données attendu est faible.
API Batch vs. API Stream
Selon le cas d'utilisation et si vous avez besoin que l'API génère le flux source ou qu'elle ingère les données, vous devez vous concentrer sur l'implémentation de différentes méthodes. Dans notre exemple, nous ne nous soucions pas de l'ingestion des données. Nous aurions également dû inclure l'implémentation du lecteur batch. Cependant, vous pouvez vous concentrer sur l'implémentation des classes nécessaires dans votre cas d'utilisation spécifique.
| source | sink | |
|---|---|---|
| batch | reader() | writer() |
| streaming | streamReader() ou simpleStreamReader() | streamWriter() |
Quand utiliser les API Writer
Cet article s'est concentré sur les API Reader utilisées dans readStream. Les API Writer permettent une logique arbitraire similaire du côté de la sortie du pipeline de données. Par exemple, supposons que les responsables des opérations au niveau du puits souhaitent que le pipeline de données appelle une API sur le site du puits qui affiche un statut d'équipement rouge/jaune/vert, en s'appuyant sur la logique du pipeline. L'API Writer permettrait aux ingénieurs de données la même opportunité d'encapsuler la logique et d'exposer un sink de données qui fonctionnerait comme les formats familiers writeStream.
Conclusion
"La simplicité est la sophistication ultime." - Léonard de Vinci
En tant qu'architectes et ingénieurs de données, nous avons maintenant l'opportunité de simplifier les charges de travail batch et de flux en utilisant l'API de source de données personnalisée PySpark. Lorsque vous trouvez des opportunités pour de nouvelles sources de données qui bénéficieraient à vos équipes de données, envisagez de séparer les sources de données pour les réutiliser dans toute l'entreprise, par exemple, grâce à l'utilisation d'une roue Python.
L'API Python Data Source est exactement ce dont nous avions besoin. Elle offre aux ingénieurs de données la possibilité de modulariser le code nécessaire à l'interaction avec nos API REST et SDK. Le fait que nous puissions désormais construire, tester et proposer des sources de données Spark réutilisables dans toute l'organisation aidera nos équipes à progresser plus rapidement et à avoir plus confiance dans leur travail." - Bryce Bartmann, Conseiller en technologie numérique, Shell
En conclusion, l'API Python Data Source pour Apache Spark™ est un ajout puissant qui résout des défis importants rencontrés précédemment par les ingénieurs de données travaillant avec des sources et des destinations de données complexes, en particulier dans les contextes de streaming. Que ce soit en utilisant l'API "simple" ou celle consciente des partitions, les ingénieurs disposent désormais des outils nécessaires pour intégrer efficacement un plus large éventail de sources et de destinations de données dans leurs pipelines Spark. Comme l'ont démontré notre présentation et l'exemple de code, la mise en œuvre et l'utilisation de cette API sont simples, permettant d'obtenir rapidement des résultats pour la maintenance prédictive et d'autres cas d'utilisation. La documentation Databricks (et la documentation Open Source) expliquent l'API plus en détail, et plusieurs exemples de sources de données Python sont disponibles ici.
Enfin, l'accent mis sur la création de sources de données personnalisées en tant que composants modulaires et réutilisables ne peut être surestimé. En abstraiant ces sources de données dans des bibliothèques autonomes, les équipes peuvent favoriser une culture de réutilisation du code et de collaboration, améliorant ainsi la productivité et l'innovation. Alors que nous continuons à explorer et à repousser les limites de ce qui est possible avec le big data et l'IoT, des technologies comme l'API Python Data Source joueront un rôle essentiel dans le façonnement de l'avenir de la prise de décision basée sur les données dans le secteur de l'énergie et au-delà.
Si vous êtes déjà client Databricks, récupérez et modifiez l'un de ces exemples pour débloquer vos données qui se trouvent derrière une API REST. Si vous n'êtes pas encore client Databricks, commencez gratuitement et essayez l'un des exemples dès aujourd'hui.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.