Modèle d'embedding SOTA pour les flux de travail d'agents maintenant en préversion publique
Qwen3-Embedding-0.6B est le premier modèle d'embedding multilingue sur le service de modèles fondamentaux avec des performances de premier ordre dans toutes les tâches d'embedding
par Felix Zhu, Cade Daniel et Wai Wu
- Qwen3-Embedding-0.6B est maintenant disponible dans Model Serving, offrant des performances de récupération de pointe dans un modèle compact de 0.6B optimisé pour la recherche vectorielle et les charges de travail d'agents IA.
- Le premier modèle d'embedding multilingue sur Databricks, prenant en charge la récupération translingue dans plus de 100 langues pour les données d'entreprise mondiales.
- Les embeddings Matryoshka permettent des compromis flexibles entre coût et performance, permettant de tronquer les embeddings de 1024 à 32 dimensions pour une recherche plus rapide et des coûts de stockage réduits.
La récupération est le fondement des systèmes d'IA modernes, et la qualité du modèle d'embedding détermine l'efficacité avec laquelle les applications peuvent trouver et raisonner sur les données de l'entreprise. Aujourd'hui, nous lançons Qwen3-Embedding-0.6B sur Databricks, un modèle d'embedding à la pointe de la technologie offrant de solides performances de récupération, une couverture multilingue et un déploiement serverless sécurisé.
Associé à Agent Bricks et AI Search, ce modèle permet aux équipes de créer des agents IA directement sur les données de l'entreprise dans Databricks, en récupérant le contexte pertinent et en raisonnant sur des données gouvernées sans déplacer les données hors de la plateforme.
Créer des agents basés sur la récupération avec Agent Bricks
Les modèles d'embedding à la pointe de la technologie sont une base essentielle pour les systèmes d'IA modernes, permettant aux applications de récupérer le bon contexte à partir de vastes collections de données d'entreprise. Qwen3-Embedding-0.6B, désormais disponible sur Databricks, offre de solides performances de récupération pour ces charges de travail.
Qwen3-Embedding-0.6B est construit sur la puissante base Qwen3 et provient de la même équipe de recherche à l'origine des séries GTE largement adoptées. Avec une longueur de contexte maximale de 32k tokens, ce modèle offre une flexibilité incroyable pour découper les documents en différentes tailles. De plus, sa conception axée sur les instructions permet aux développeurs d'adapter le modèle à des tâches et des langues spécifiques avec une simple invite, améliorant généralement les performances de récupération de 1 à 5 %.
Sur Databricks, cela peut être combiné avec Agent Bricks et AI Search pour créer des agents IA basés sur la récupération directement sur les données de l'entreprise. Les équipes peuvent indexer des documents avec AI Search et récupérer le contexte pertinent pendant l'exécution de l'agent, en ancrant les agents dans des données gouvernées stockées dans Databricks.
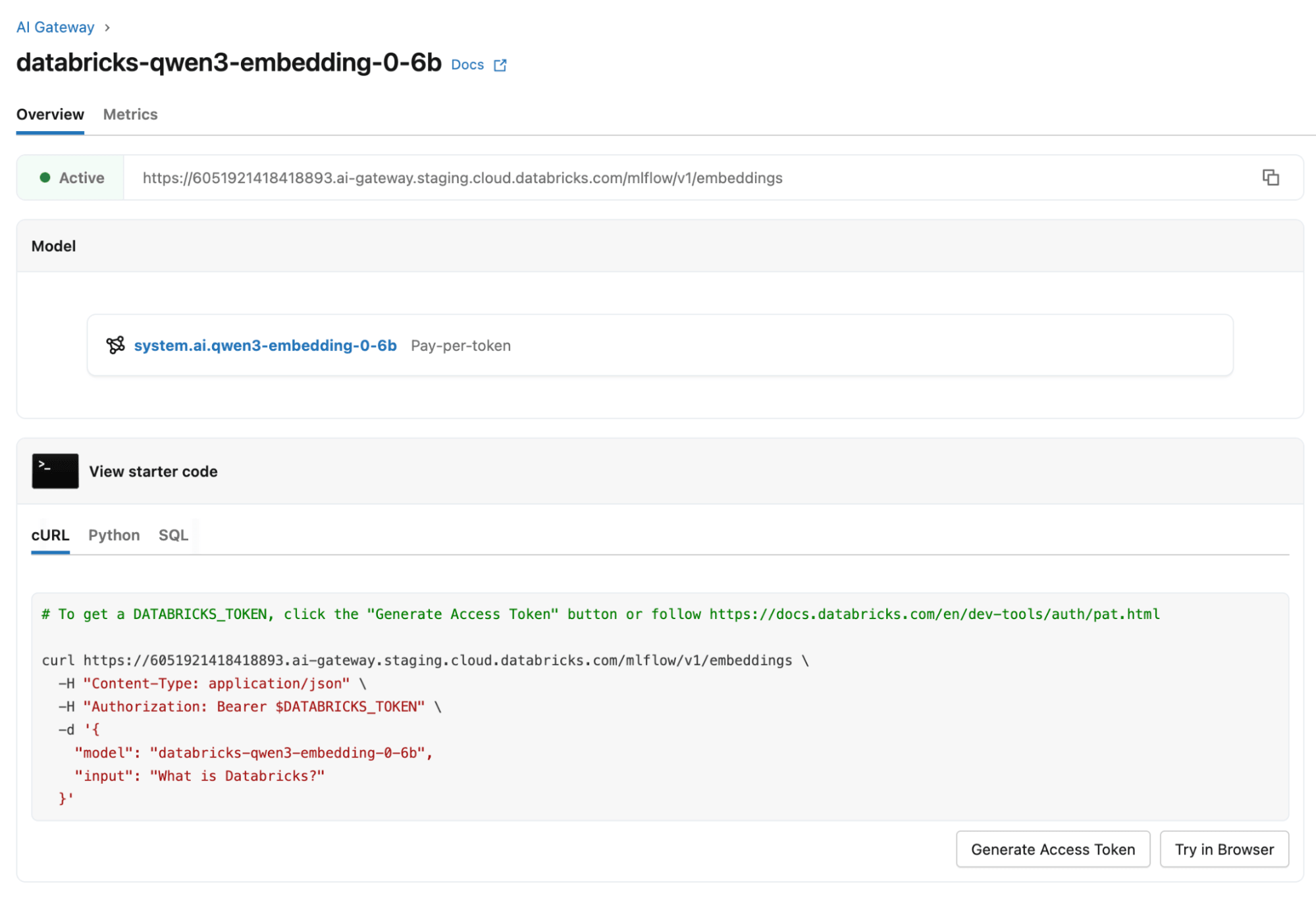
Comment ce modèle d'embedding améliore les agents IA sur Databricks
Qwen3-Embedding-0.6B offre une qualité de pointe pour sa taille. Sur les classements MTEB multilingue et anglais v2, il surpasse la plupart des autres modèles de classe 0.6B et surpasse les modèles phares d'embedding d'OpenAI et de Cohere, tout en rivalisant avec des modèles beaucoup plus grands de plus de 7B. Cela signifie que vous pouvez obtenir des performances de récupération de premier ordre sans la latence et le coût de très grands modèles.
Le modèle offre également un contrôle granulaire sur le coût et le rappel grâce à Matryoshka Representation Learning (MRL), qui concentre les informations les plus importantes dans les premières dimensions vectorielles. Cela permet de tronquer les embeddings en toute sécurité pour un stockage moins cher et une recherche plus rapide tout en préservant la majeure partie du signal. Avec Qwen3-Embedding-0.6B, vous pouvez choisir n'importe quelle taille d'embedding de 32 à 1024 dimensions au moment de la requête, en utilisant des vecteurs plus petits pour les index de rappel à grande échelle et des vecteurs pleine taille pour un réordonnancement de plus haute précision.
Pour utiliser cette fonctionnalité avec databricks-qwen3-embedding-0-6b, définissez le champ facultatif dimensions dans votre requête API REST Embeddings à la taille de sortie souhaitée (une puissance de deux comprise entre 32 et 1024). Consultez la documentation de l'API REST des modèles fondamentaux pour plus de détails.
Multilingue par conception
Qwen3-Embedding-0.6B est le premier modèle d'embedding multilingue hébergé par Databricks, conçu dès le départ pour les charges de travail mondiales. Alors que de nombreux modèles d'embedding sont d'abord en anglais avec un support multilingue limité, Qwen3-Embedding-0.6B hérite d'une large couverture linguistique du modèle de base Qwen3, qui a été pré-entraîné sur du texte couvrant plus de 100 langues.
Cela permet de fortes performances non seulement pour la récupération en anglais, mais aussi pour les tâches multilingues et translingues. Les applications peuvent rechercher dans une langue et récupérer des résultats dans une autre, ou prendre en charge des ensembles de données mixtes et la récupération de code dans plusieurs langages de programmation.
Déploiement serverless sécurisé
Comme les autres modèles fondamentaux hébergés par Databricks, Qwen3-Embedding-0.6B s'exécute sur des GPU serverless sécurisés et entièrement gérés au sein de la plateforme Databricks.
Appelez simplement les API des modèles fondamentaux, et Databricks s'occupe du provisionnement, de la mise à l'échelle automatique et de la fiabilité. Comme le modèle s'exécute sur une infrastructure conforme et géo-consciente, vous pouvez garder les embeddings à proximité de vos données, respecter les exigences de résidence des données et intégrer la récupération directement aux charges de travail Databricks existantes.
Essayez Qwen3-Embedding-0.6B dès aujourd'hui !
Que vous construisiez des systèmes de recherche sémantique, des pipelines RAG, de récupération multilingue ou de classification de texte, Qwen3-Embedding-0.6B offre une combinaison exceptionnelle de vitesse, d'efficacité et de précision de pointe. Ce modèle est disponible sous le nom de databricks-qwen3-embedding-0-6b sur tous les clouds dans toutes les régions qui prennent en charge le service de modèles fondamentaux, et vous pouvez essayer ce modèle sur la page de service Databricks. Il est disponible sur toutes les surfaces de service de modèles : Pay-Per-Token, AI Functions (inférence par lots) et Provisioned Throughput. Vous pouvez également sélectionner ce modèle pour des cas d'utilisation de AI Search.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.