L'IA TabPFN accélère la transformation métier sur Databricks
Découvrez comment TabPFN sur Databricks accélère les prédictions de ML structurées, élimine les cycles de réentraînement et met l'IA à l'échelle au sein des opérations métier principales avec une gouvernance complète
par Dominik Safari, Philipp Singer, Diana Kriuchkova, Sauraj Gambhir, Ryuta Yoshimatsu , Bryan Smith et Dael Williamson
- Pourquoi les workflows de ML classiques restent complexes et gourmands en Ressources — et comment TabPFN change fondamentalement cela
- Comment Databricks permet aux équipes de créer, déployer et gouverner les prédictions TabPFN directement à côté des données du Lakehouse
- La valeur métier débloquée : un temps de prédiction plus rapide, une réduction des frais généraux de la Data Science et une adoption plus large du ML dans les Opérations principales
De nos jours, il est difficile de trouver une revue économique, une conférence sur les résultats trimestriels, un livre blanc du secteur ou une présentation de stratégie sur la transformation métier qui ne soit pas axée sur l'Intelligence Artificielle (IA). L'IA moderne représente un changement fondamental dans la manière dont les organisations abordent la consommation, l'interprétation et la génération de contenu, permettant aux entreprises d'augmenter et d'automatiser un large éventail de tâches qui nécessitaient auparavant une expertise approfondie et des années de connaissances spécialisées.
Mais malgré toute l'attention suscitée par la capacité de l'IA à comprendre et à produire du contenu non structuré, c'est-à-dire des textes, des images, des fichiers audio, etc., de très nombreux processus métier essentiels reposent depuis longtemps sur le Machine Learning (ML) classique, une technologie différente mais connexe, qui produit des étiquettes prédictives à partir de données d'entrée structurées (Figure 1). Jusqu'à présent, le pouvoir de transformation de l'IA a laissé le ML classique largement inchangé.
La persistance des workflows de ML traditionnels provient de leur complexité inhérente et de leur forte intensité en main-d'œuvre. Les data scientists passent couramment plus de 80 % de leur temps à des activités qui précèdent même l'entraînement du modèle : préparer et valider les données d'entrée structurées, concevoir des features et sélectionner la bonne classe de modèle. De plus, à mesure que les distributions de données sous-jacentes évoluent et que les performances du modèle se dégradent avec le temps, ce travail n'est pas un investissement ponctuel mais un cycle continu de monitoring, de debugging et de réentraînement.
À grande échelle, ce défi s'intensifie. Les organisations qui déploient des centaines, voire des milliers de modèles de ML, s'appuient sur des frameworks d'expérimentation automatisés pour évaluer des milliers de combinaisons de paramètres. Mais même l'automatisation ne peut pas surmonter les contraintes de ressources fondamentales.
La réalité est brutale : les entreprises doivent choisir quels modèles bénéficieront d'une optimisation et lesquels fonctionnent « assez bien », compte tenu des ressources limitées et de la nécessité d'obtenir rapidement des résultats commerciaux. Mais l'émergence de nouveaux modèles d'IA axés sur les données d'entrée structurées et les sorties prédictives pourrait enfin offrir une voie à suivre.
Vidéo 1. Interaction avec le modèle TabPFN dans le cadre de l'accélérateur de solution Databricks
Présentation de TabPFN, un modèle d'IA pour le Machine Learning
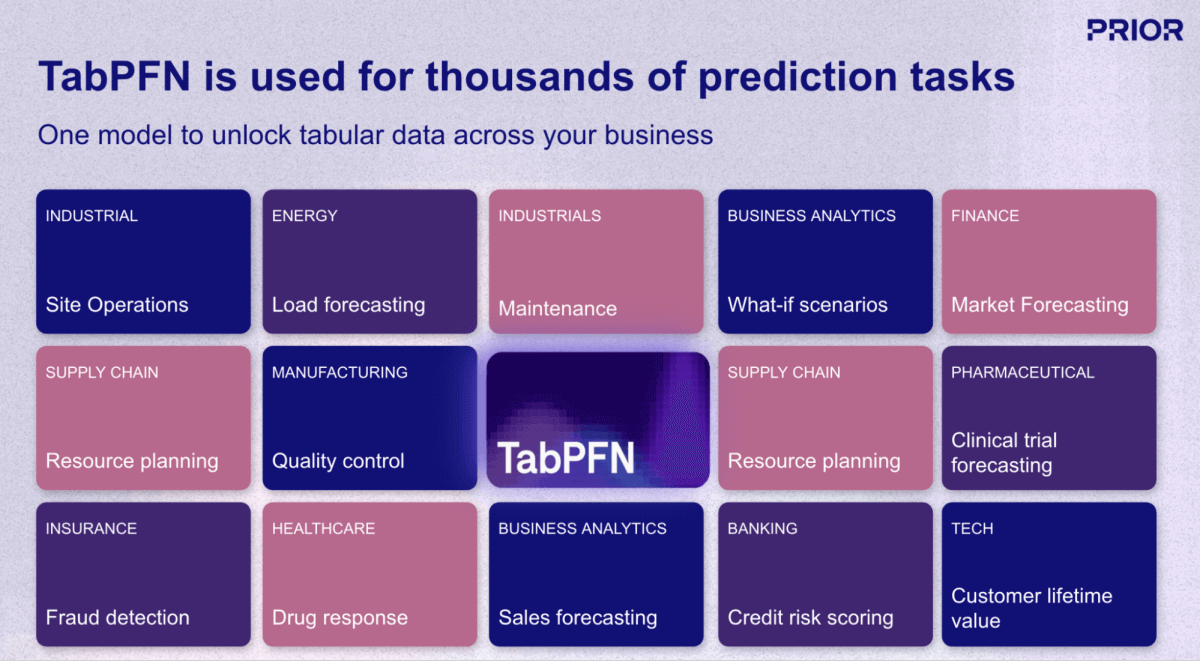
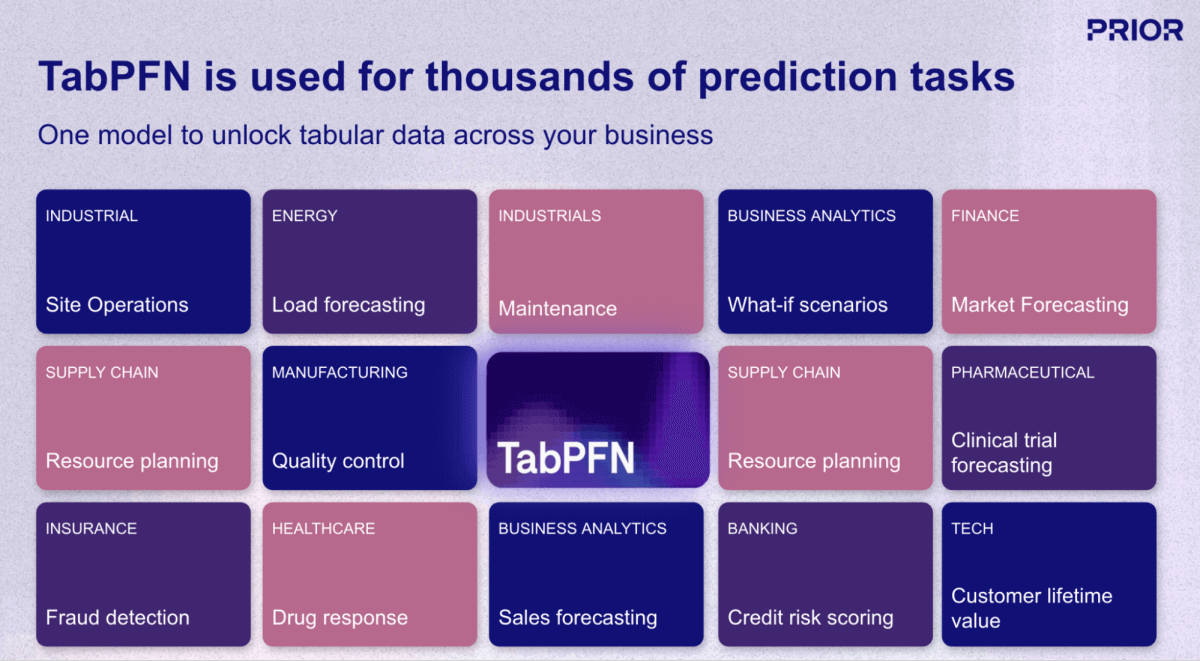
L'un des développements les plus prometteurs dans ce domaine est TabPFN, un modèle de fondation (IA) de Prior Labs qui réinvente fondamentalement le workflow de Machine Learning (ML) pour les données structurées. Contrairement aux approches de ML traditionnelles qui nécessitent de créer et d'entraîner un modèle unique pour chaque tâche de prédiction, TabPFN applique le même paradigme « pré-entraîné, prêt à l'emploi » des LLM aux données d'entreprise tabulaires. Le modèle a été pré-entraîné sur plus de 130 millions de datasets synthétiques, apprenant ainsi à « apprendre à apprendre » à partir de données structurées dans pratiquement n'importe quel domaine ou cas d'usage (Figure 1).
{kind=link}
Raccourcir le cycle de vie du ML
Les implications pour la productivité du ML sont spectaculaires. Alors que les approches traditionnelles exigent des data scientists qu'ils consacrent des heures, voire des jours, à la préparation des données, à l'ingénierie des features, à la sélection des modèles et au réglage des hyperparamètres, TabPFN fournit des prédictions de qualité production en une seule passe avant, généralement mesurée en secondes.
Le modèle traite directement les entrées brutes, gérant automatiquement les valeurs manquantes, les types de données mixtes, les caractéristiques catégorielles et textuelles, et les valeurs aberrantes, sans nécessiter le prétraitement approfondi qui consomme généralement la majeure partie de l'effort de la Data Science. Peut-être plus important encore, TabPFN élimine la charge de maintenance continue liée au réentraînement du modèle : lorsque de nouvelles données sont disponibles, les organisations mettent simplement à jour le contexte du modèle plutôt que de lancer un nouveau cycle d'entraînement.
Performance sans compromis
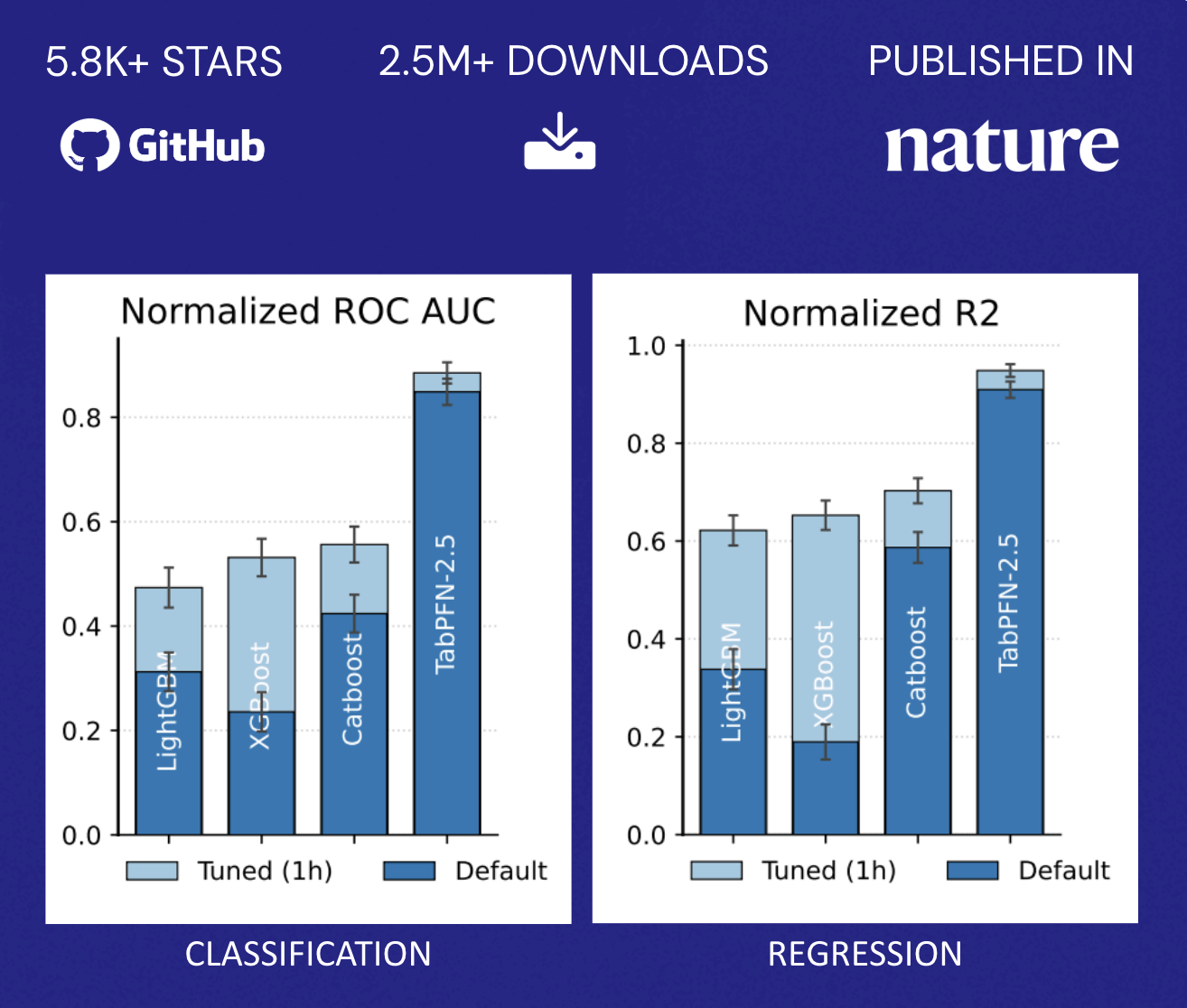
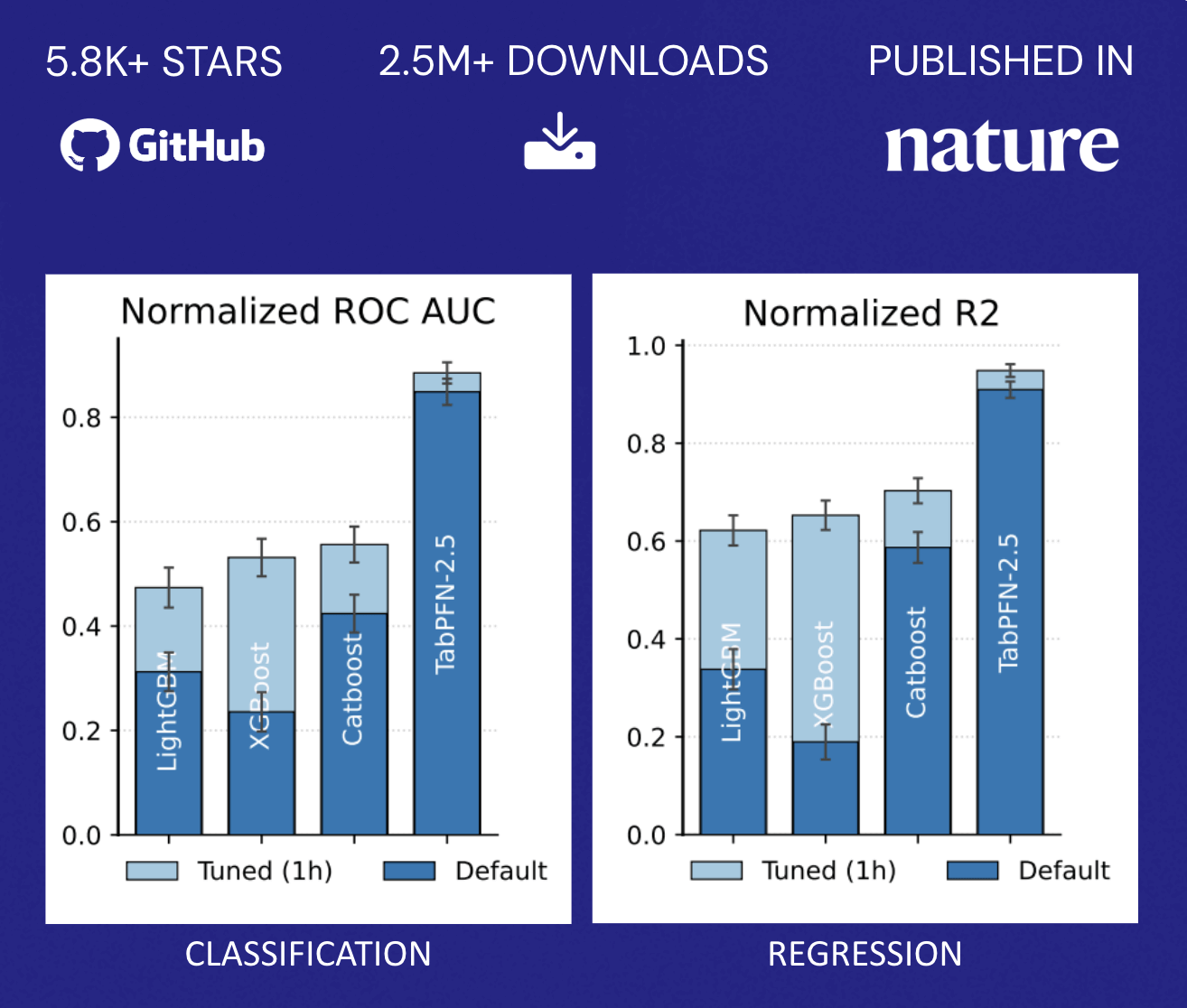
TabPFN surpasse la précision des méthodes traditionnelles qui nécessitent des heures de réglage automatisé. Ce profil de performance modifie fondamentalement le modèle économique décrit précédemment : les organisations ne sont plus confrontées à un choix binaire entre la précision du modèle et l'allocation des ressources. Au lieu de cela, elles peuvent déployer rapidement des capacités prédictives sur un plus large éventail de cas d'usage sans avoir à agrandir proportionnellement leurs équipes de data science, démocratisant ainsi le ML au-delà de la poignée d'applications à plus forte valeur ajoutée qui justifient généralement des efforts d'optimisation dédiés (Figure 2).
{kind=link}
Mettre à l'échelle l'impact de l'IA sur la prédiction structurée
TabPFN prend actuellement en charge des jeux de données allant jusqu'à 100 000 lignes et 2 000 caractéristiques, avec des versions d'entreprise allant jusqu'à 10 millions de lignes, couvrant la grande majorité des cas d'utilisation du ML opérationnel dans les secteurs de la vente au détail, de la finance, de la santé, de la fabrication et autres Secteurs d'activité. Pour les organisations qui cherchent à opérationnaliser l'IA au-delà de la génération de contenu et des tâches de langage naturel, les modèles de fondation comme TabPFN représentent la pièce manquante, apportant les mêmes améliorations de productivité par paliers aux données structurées et à l'analytique prédictive qui constituent depuis longtemps l'épine dorsale de la prise de décision data-driven (Figure 3).
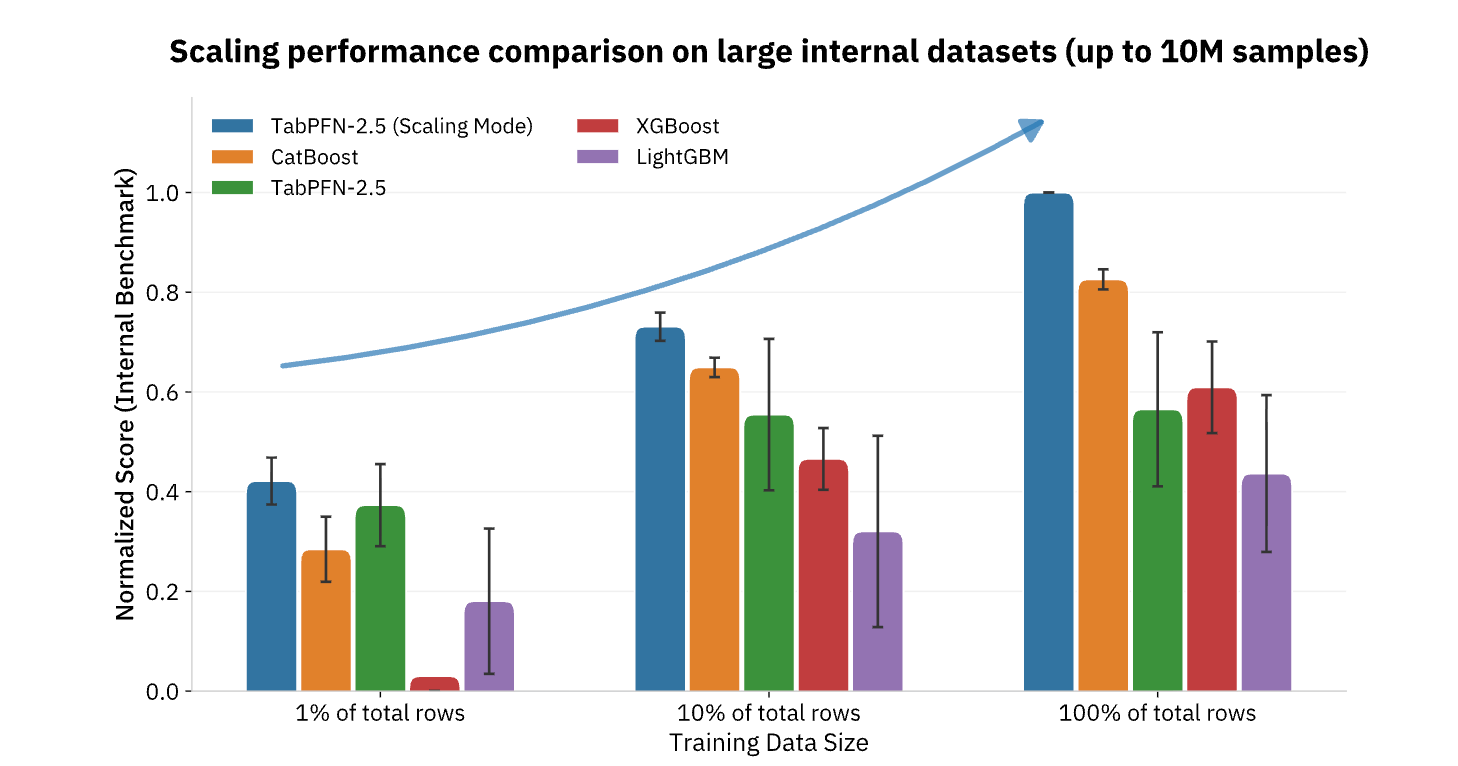
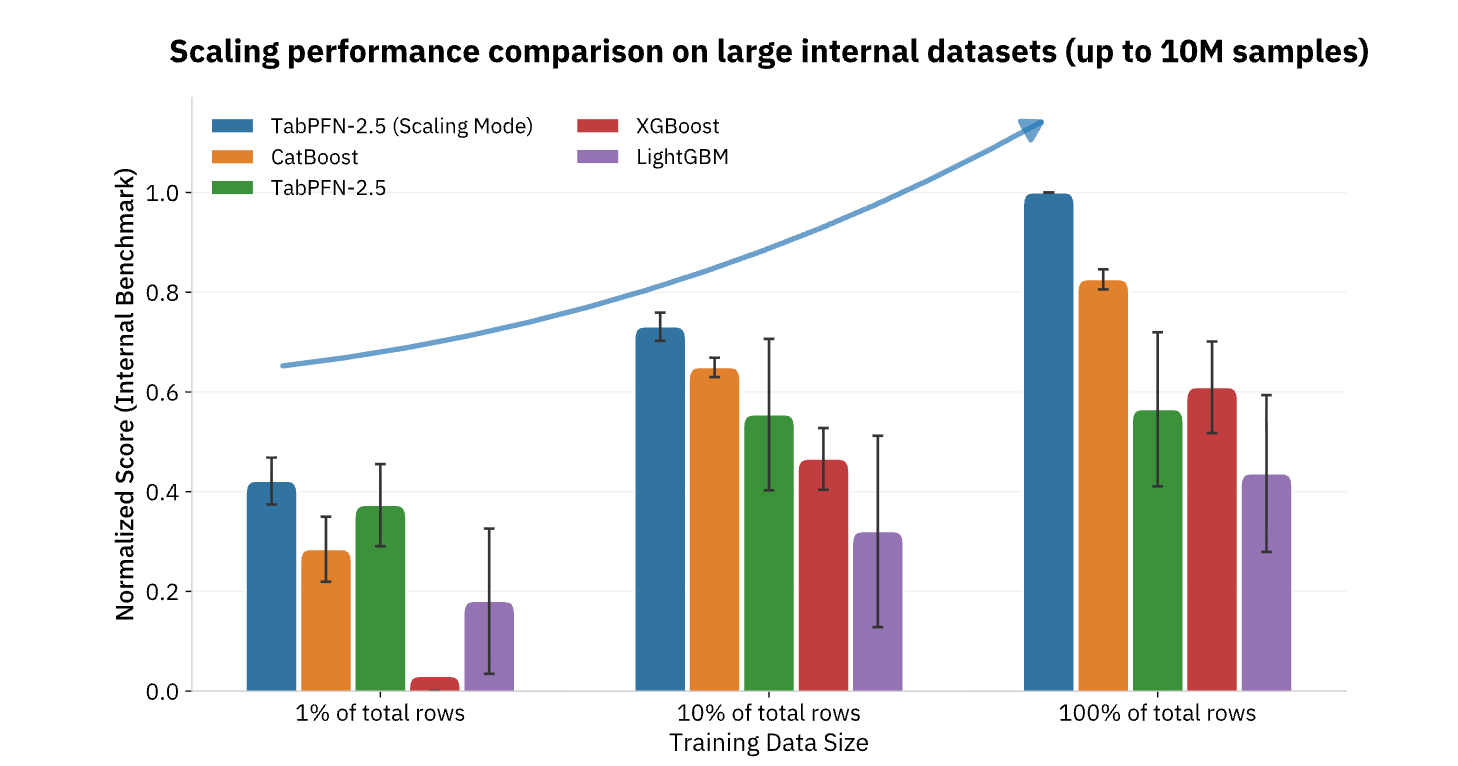{kind=link}
TabPFN alimente déjà de nombreuses applications concrètes pour des entreprises du monde entier. Des déploiements dans divers domaines, de la gestion des risques financiers avec Taktile à l'évaluation des résultats en matière de santé avec NHS, en passant par la maintenance prédictive avec Hitachi, ont constaté une nette amélioration, tant en termes d'efficacité que de qualité des résultats. TabPFN surpasse constamment les méthodes de ML traditionnelles, améliorant la performance de référence de 10%-65% et accélérant les workflows de data science de 90 %. Les organisations bénéficient de revenus accrus, de meilleurs résultats en matière de santé, d'économies sur les coûts de maintenance, de la prévention du désabonnement, et bien plus encore.
Utilisation de TabPFN avec Databricks
Databricks est depuis longtemps la plateforme de prédilection des data scientists qui cherchent à développer des capacités prédictives avec le Machine Learning (ML). En tant que plateforme ouverte, TabPFN est bien adapté à une utilisation au sein de la Databricks Platform.
Développer là où se trouvent les données
La plupart des ML classiques d'entreprise commencent à partir des données Lakehouse : transactions, télémétrie opérationnelle, événements clients, signaux d'inventaire et indicateurs de risque. Le déplacement de ces données vers des environnements externes ralentit les équipes en créant des doublons, en augmentant le risque de sécurité et en affaiblissant la reproductibilité et l'auditabilité. Databricks permet d'exécuter des workflows TabPFN directement aux côtés des données gouvernées, afin que les équipes puissent minimiser le mouvement des données tout en maintenant les contrôles. Avec Unity Catalog, les organisations centralisent le contrôle d'accès et l'audit et préservent le lignage des données et des assets d'IA, ce qui est important lorsque vous devez prouver quelles données ont été utilisées, comment les features ont été dérivées et qui y avait accès au moment de la décision.
Opérationnaliser efficacement les résultats
TabPFN est une approche de modélisation. Pour créer un impact en production, il doit s'intégrer à des modèles d'entreprise reproductibles tels que le scoring par batch et en temps réel, l'évaluation, la gouvernance et le monitoring. Databricks est une plateforme robuste pour ces workflows, avec une compute évolutive et une infrastructure d'inférence en temps réel qui peut transformer TabPFN en un processus opérationnel fiable. Pour l'évaluation et la surveillance, MLflow fournit un suivi des expérimentations et un registre de modèles pour gérer les versions, la lignée et les workflows de promotion de manière auditable.
Assurer une gouvernance continue des modèles
Databricks assure un monitoring continu des performances du modèle TabPFN, en détectant quand les prédictions commencent à drift par rapport aux résultats métier réels. Lorsque des ajustements sont nécessaires, l'architecture de TabPFN élimine le cycle de réentraînement traditionnel qui dure des semaines : les équipes mettent simplement à jour le contexte du modèle avec des données récentes et le redéploient en quelques minutes plutôt qu'en quelques jours. Cette combinaison de monitoring automatisé et de capacité de refresh rapide garantit que la qualité des prédictions reste alignée sur l'évolution des conditions du marché, tout en réduisant considérablement les Ressources de Data Science généralement nécessaires pour la maintenance continue du modèle.
Pour aider les équipes à tester TabPFN avec une configuration minimale, nous avons publié un accélérateur de solution disponible publiquement qui montre comment exécuter TabPFN de bout en bout sur Databricks avec des données Lakehouse gouvernées. L'accélérateur comprend une série de Notebooks qui simulent de manière réaliste des données provenant de divers scénarios industriels et construisent des prédictions à l'aide de TabPFN (Vidéo 1).
Commencez dès aujourd'hui en apportant la puissance transformatrice de l'IA à vos workloads ML et en stimulant la transformation de l'ensemble de vos processus métier.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.