Transformer les rapports de maintenance solaire et éolienne avec Genie et des agents AI
Comment Plenitude utilise Databricks Genie et Agent Bricks pour transformer les PDF de maintenance non structurés en une couche de données interrogeable et en analyses en langage naturel sur l'ensemble des centrales solaires et éoliennes.
par Maria Vallarelli
- Plenitude a conçu un système basé sur des agents sur Databricks Genie qui convertit les PDF non structurés de maintenance solaire et éolienne en un modèle de données unifié et interrogeable.
- La solution utilise Genie, associé aux métadonnées sémantiques de Unity Catalog et aux fonctions AI, pour permettre aux utilisateurs de poser des questions en langage naturel et de créer des visualisations sur l'ensemble des centrales et au fil du temps.
- Les premiers résultats incluent une analyse multi-centrale plus rapide, un accès en libre-service gouverné avec une sécurité au niveau des lignes, ainsi qu'une base pour la maintenance prédictive d'équipements critiques tels que les onduleurs.
Des PDF de maintenance aux insights exploitables grâce aux agents AI
Les fournisseurs d'exploitation et de maintenance des centrales solaires et éoliennes fournissent généralement des rapports au format PDF, les informations clés étant réparties dans du texte libre, des tableaux et des images. Ce format est accessible mais n'est pas évolutif : les équipes doivent lire manuellement chaque document pour comprendre les pannes, les tendances ou les problèmes récurrents, ce qui rend les comparaisons entre centrales lentes et irrégulières à mesure que le nombre d'actifs augmente.
Plenitude et Databricks ont conçu un système basé sur des agents qui convertit ces rapports de maintenance PDF en données structurées. L'idée de base est simple : transformer les documents en données, puis utiliser un agent AI pour en tirer des insights exploitables. Les utilisateurs peuvent désormais poser des questions en langage naturel, analyser les tendances au fil du temps, comparer les centrales et exporter des résultats structurés, au lieu de parcourir les rapports un par un.
Architecture basée sur des agents pour l'analyse de données issues de PDF
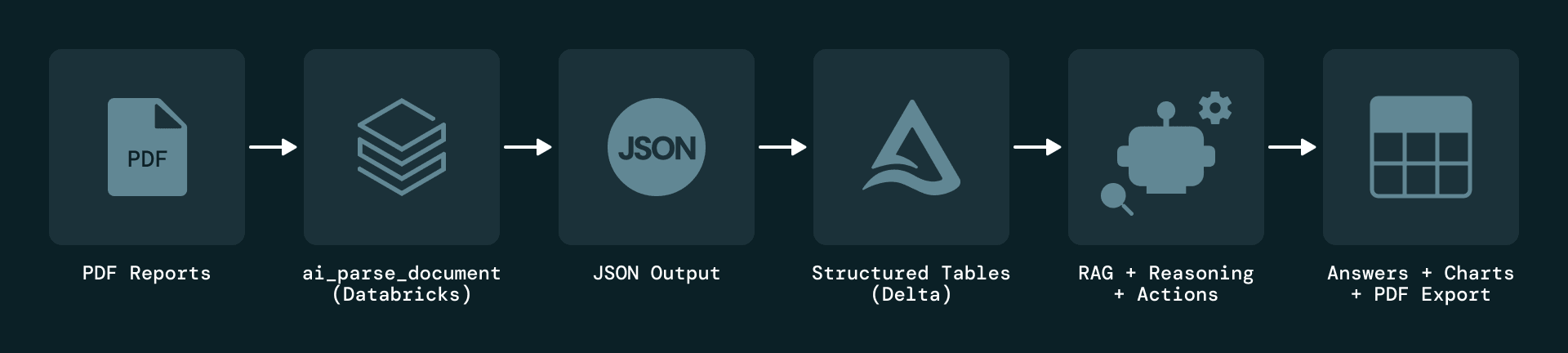
La solution commence par l'ingestion pilotée par les événements des rapports PDF au niveau des centrales. Chaque nouveau rapport déclenche un job Databricks qui analyse le document et applique une extraction basée sur un LLM. Les éléments extraits sont sérialisés au format JSON et stockés dans Delta Lake, qui conserve l'historique complet des versions pour l'audit et la réexécution.
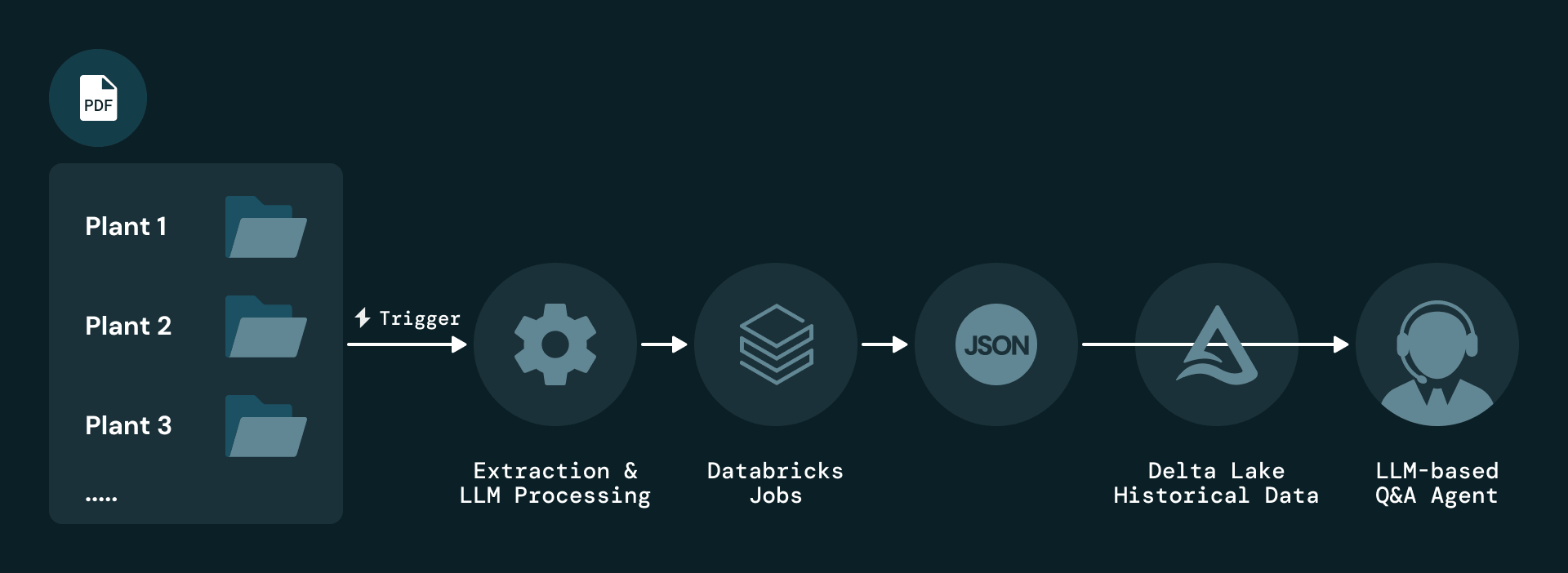
Pour répondre au problème fondamental selon lequel les informations de maintenance résident presque entièrement dans des PDF non structurés, Plenitude utilise les fonctions AI de Databricks Document Intelligence — plus précisément ai_parse_document, pour extraire plusieurs types d'éléments de chaque page, notamment des blocs de texte, des tableaux, des illustrations et des métadonnées. Chaque élément est enrichi d'attributs tels que la centrale, la période de rapport, le numéro de page et le type de contenu, et chaque enregistrement conserve un lien direct vers le rapport d'origine pour assurer la traçabilité.
Cette structure offre de puissantes capacités :
- Le filtrage par période, catégorie et zone géographique.
- L'identification des types de contenu et l'utilisation de coordonnées spatiales.
- La traçabilité de chaque insight jusqu'au PDF d'origine.
- L'intégration avec des outils de BI et des agents digitaux sans modifier les documents sous-jacents.
Au lieu de fichiers statiques, les rapports de maintenance deviennent une couche de données persistante, prête pour l'analyse avancée et le raisonnement des agents.
Traitement des données sur Databricks : du PDF à Delta Lake
L'architecture est organisée en trois couches principales : l'ingestion et l'analyse, la structuration des données et l'interaction basée sur des agents.
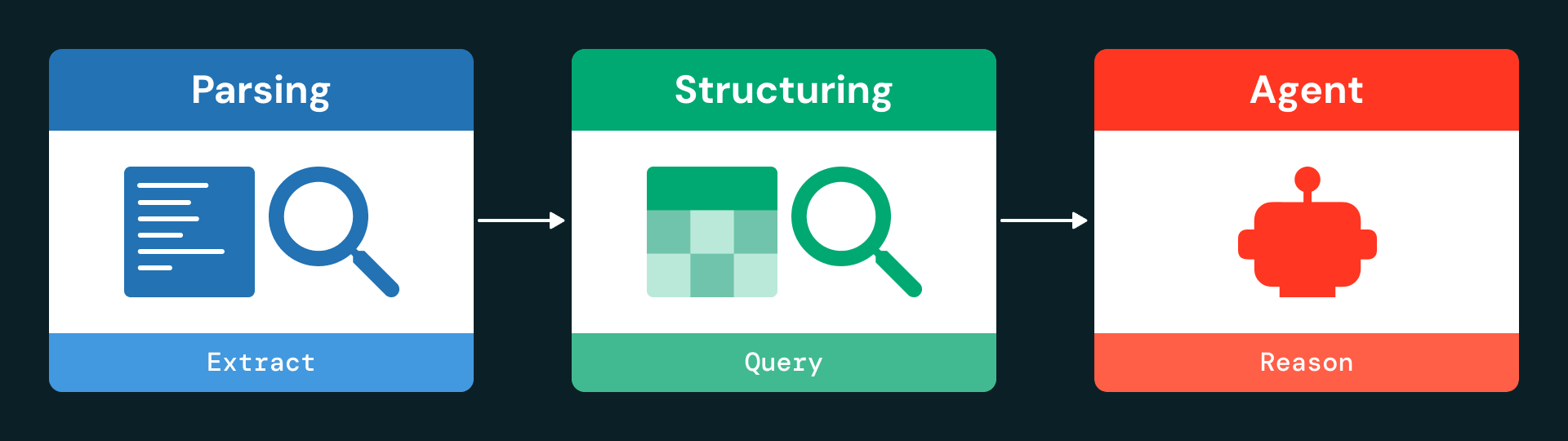
Étape 1 : l'analyse
À l'aide de ai_parse_document, le pipeline extrait le texte, les tableaux et les métadonnées de chaque page et les sérialise sous forme d'objets JSON structurés. Même les tableaux complexes sont capturés avec leur contexte complet, y compris leur emplacement sur la page et leur représentation HTML.
Étape 2 : la normalisation et le stockage
Pour chaque page (page_id) and objet (id), le système crée une ligne dans une table Delta Lake. Chaque ligne contient :
- Le contenu JSON extrait.
- Les identifiants de page et d'objet.
- Les coordonnées (coords) représentant la boîte englobante (bounding box) sur la page.
- Le type de contenu (par exemple, du texte ou un tableau).
- Des métadonnées à forte valeur ajoutée telles que le mois, l'année, le nom du fichier, la catégorie et le pays.
Ce modèle normalisé transforme les PDF en un ensemble de données unifié et interrogeable, transparent et facile à associer à d'autres sources, tout en préservant une traçabilité complète vers les documents d'origine.
Étape 3 : l'espace Genie et le mode Agent
En plus de cette couche de données organisée, Plenitude crée un espace Genie dédié, puis s'appuie sur le mode Agent de Genie pour effectuer des recherches approfondies sur les données. Genie utilise les tables Delta Lake structurées comme contexte principal et permet aux utilisateurs d'interagir avec les données de maintenance en langage naturel.
Lorsqu'un utilisateur pose une question, Genie :
- Utilise les métadonnées sémantiques dans Unity Catalog pour identifier les tables et les colonnes disponibles.
- S'appuie sur des descriptions détaillées des colonnes, une base de connaissances organisée et des exemples SQL pour guider la génération de requêtes.
- Génère et exécute du code SQL sur la couche structurée.
- Renvoie des réponses, des visualisations et, en option, des résultats exportables.
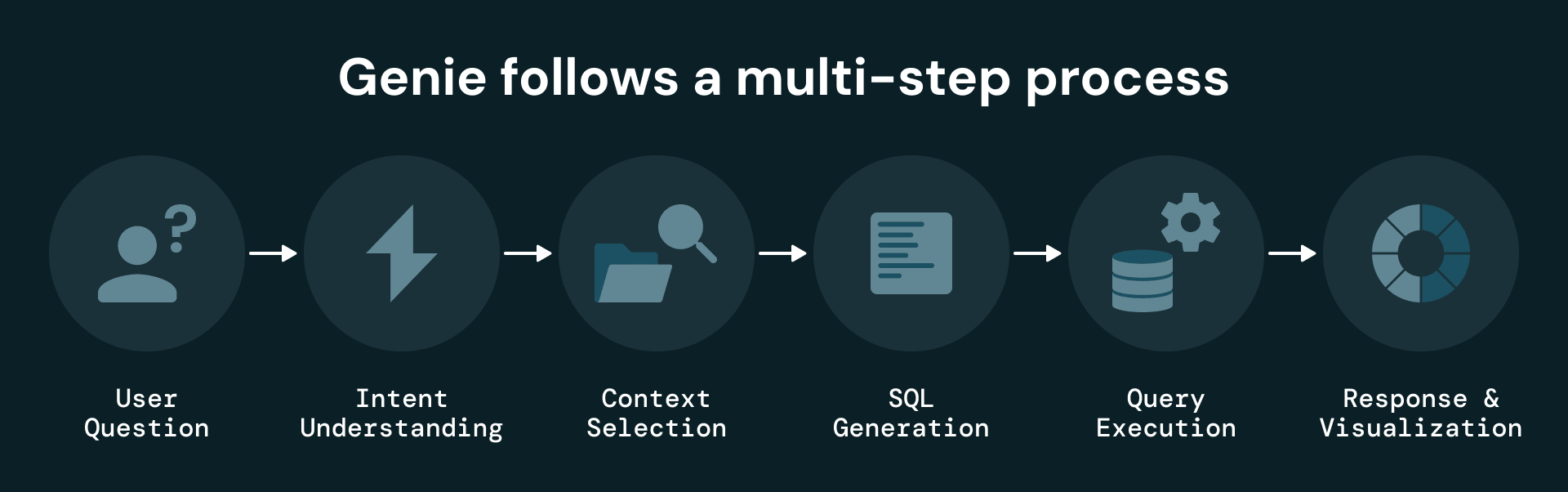
Cette conception permet à Genie de comprendre à la fois la sémantique métier des données de maintenance et leur structure sous-jacente, ce qui permet d'obtenir des réponses précises et adaptées au contexte.
Pourquoi les métadonnées et les instructions sont importantes pour Genie
Pour obtenir des résultats fiables à partir de jeux de données complexes issus de PDF, le contexte seul ne suffit pas. Plenitude a constaté que deux modèles de conception sont essentiels : des métadonnées riches et des instructions explicites pour l'espace Genie.
Les métadonnées comme contrat avec l'agent
Des descriptions de tables et de colonnes bien définies indiquent à Genie la signification de chaque champ et la manière dont il doit être utilisé. Par exemple, page_id identifie la page source dans le rapport d'origine, type indique si l'élément est du texte ou un tableau, coords encode l'emplacement spatial, et content contient le texte extrait ou la représentation du tableau. Ces métadonnées transforment le JSON brut en connaissances compréhensibles sur lesquelles Genie peut raisonner.
Les instructions générales comme ancrage opérationnel
Lorsque les données sont fragmentées ou s'étendent sur plusieurs pages, les instructions spécifiques au domaine ajoutées à la base de connaissances locale de l'espace Genie deviennent essentielles. Plenitude encode des règles pour gérer les tableaux multipages, ignorer les artefacts HTML, exclure les lignes d'en-tête et appliquer des filtres spécifiques aux centrales.
Un exemple concret : même avec des métadonnées complètes, Genie pourrait calculer un total trimestriel incorrect s'il additionne les colonnes YTD ou ignore les mois manquants. En ajoutant des instructions claires telles que « utilisez uniquement les colonnes au niveau du mois, jamais les champs YTD » et « validez que tous les mois requis sont présents avant de faire la somme », l'équipe fournit à Genie des garde-fous opérationnels qui garantissent des résultats cohérents.
Ces instructions spécifiques à l'espace Genie, combinées aux métadonnées d'Unity Catalog, aident Genie à appliquer la bonne logique pour interpréter correctement les données.
Utilisation de Genie et d'Agent Bricks pour des workflows d'agents évolutifs
Bien que Genie offre une expérience d'agent de recherche puissante sur la couche de maintenance structurée, Plenitude a également besoin de workflows reproductibles et d'orchestration pour prendre en charge un ensemble croissant de cas d'usage. Agent Bricks est la prochaine étape de cette évolution.
Avec Agent Bricks, Plenitude peut passer de modèles « LLM plus prompt » à des workflows d'agents qui exécutent des séquences d'actions pour le compte d'analystes et d'ingénieurs de maintenance. Les mêmes tables Delta Lake, métadonnées et instructions organisées qui alimentent Genie peuvent être réutilisées par des agents de type superviseur conçus avec Agent Bricks pour :
- Décomposer des questions complexes en tâches analytiques plus simples.
- Appeler les flux d'outils Genie pour générer et exécuter du code SQL.
- Déclencher des actions en aval, telles que la génération de rapports ou la création d'alertes.
Ce qui nécessitait auparavant l'assemblage manuel de prompts, d'outils et de logique de validation peut désormais être centralisé dans Agent Bricks, sur la même plateforme Databricks qui gère les données.
Optimiser les performances grâce au clustering liquide automatique
Les requêtes basées sur des agents étant exploratoires et dynamiques, l'optimisation traditionnelle basée sur Z-ORDER n'est pas toujours idéale. Plenitude a constaté que les modèles d'accès évoluent à mesure que de nouveaux rapports, utilisateurs et questions apparaissent, ce qui rend le clustering manuel difficile à maintenir.
Le clustering liquide automatique, en revanche, apprend comment les tables sont réellement utilisées et adapte leur disposition en conséquence. Cela réduit le besoin de concevoir des index au préalable et d'effectuer des ajustements continus, ce qui est particulièrement important lors des phases de preuve de concept et de mise en service initiale. Dans ce contexte, le clustering automatique est le choix privilégié pour les charges de travail basées sur des agents et des LLM sur les tables Delta.
Sécuriser l'accès aux données pour les Genie Rooms
Les données de maintenance sont souvent soumises à des exigences d'accès spécifiques par pays ou par région. Pour appliquer ces règles de manière cohérente, Plenitude utilise la sécurité au niveau des lignes en combinaison avec Unity Catalog et des tables.
Une fonction Unity Catalog détermine les pays auxquels l'utilisateur actuel peut accéder et renvoie une liste ou le mot-clé ALL s'il dispose d'une visibilité totale. Une table filtre ensuite les lignes en fonction de cette fonction, de sorte que chaque utilisateur ne voit que les données des pays pour lesquels il est autorisé.
Lorsque les utilisateurs interagissent via la Genie Room, toutes les requêtes s'exécutent sur la table filtrée, de sorte que la sécurité au niveau des lignes s'applique automatiquement. Cela signifie que les utilisateurs peuvent poser des questions en langage naturel, mais ne reçoivent que les résultats des données qu'ils sont autorisés à voir. Le même ensemble de données alimente Genie, les agents et les outils de BI, tandis que la visibilité s'ajuste par utilisateur.
Améliorations futures : vers la maintenance prédictive
Comme les rapports de maintenance contiennent des incidents ouverts et des détails sur les pannes, le modèle de données structuré constitue une base solide pour la maintenance prédictive. Les onduleurs en sont un bon exemple : les pannes peuvent entraîner la perte de plusieurs mégawattheures par unité, et les problèmes récurrents apparaissent souvent en premier dans les notes de maintenance.
En analysant les modèles de pannes au fil du temps, Plenitude peut :
- Identifier les problèmes d'enregistrement potentiels.
- Détecter les signaux d'alerte précoce.
- Prioriser les centrales qui nécessitent une investigation plus approfondie.
- Alimenter les modèles prédictifs avec des historiques d'incidents de meilleure qualité.
Le système basé sur des agents transforme ces signaux en analyses, tendances et visualisations accessibles afin que les équipes puissent anticiper les problèmes plutôt que de simplement y réagir.
Principaux avantages et fonctionnalités
Avec l'approche précédente, l'analyse se limitait à la lecture individuelle des rapports, ce qui rendait difficile l'établissement de tendances historiques, la comparaison des centrales ou la génération de résultats structurés. La création de graphiques, l'exportation de résultats ou la combinaison d'informations provenant de plusieurs rapports se faisaient au mieux manuellement, et étaient souvent impossibles.
Grâce au mode Agent de Genie sur Databricks et à un modèle de données adapté aux agents, Plenitude peut :
- Explorer les données de maintenance au fil du temps et sur l'ensemble des centrales.
- Générer des visualisations et exporter des résultats, y compris des fichiers PDF.
- Détecter les signaux précoces et les modèles récurrents.
- Faire évoluer l'analyse sans augmenter l'effort manuel.
En combinant données structurées, métadonnées métier et raisonnement de l'AI, le système génère des analyses, des tendances et des visualisations qui favorisent la détection précoce et l'anticipation des problèmes, plutôt qu'un simple rapport rétrospectif.
En savoir plus sur Databricks Genie et Agent Bricks.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.