Qu'est-ce qu'un réseau neuronal bayésien ?
Les réseaux neuronaux utilisent des distributions de probabilité comme pondérations au lieu d'estimations ponctuelles, permettant ainsi la quantification de l'incertitude et la confiance dans les prédictions.
- Modélise les poids et les biais sous forme de distributions de probabilité (par exemple, gaussiennes) avec des paramètres apprenables pour les moyennes et les variances, au lieu d'estimations ponctuelles fixes issues de réseaux de neurones classiques.
- Entraîné par inférence variationnelle approximant les distributions a posteriori ou par des méthodes d'échantillonnage MCMC, plus coûteuses en calcul mais fournissant des estimations d'incertitude rigoureuses.
- Essentiel pour les applications de sécurité, l'apprentissage actif où l'incertitude guide la collecte de données, la détection des entrées hors distribution et les scénarios nécessitant des intervalles de confiance sur les prédictions.
Que sont les réseaux de neurones bayésiens ?
Les réseaux de neurones bayésiens (BNN) sont des réseaux standards étendus auxquels s'ajoute une inférence ultérieure visant à contrôler le surajustement. D'un point de vue plus large, l'approche bayésienne emploie une méthodologie statistique, de sorte que tout est associé à une répartition de probabilité, y compris les paramètres des modèles (pondérations et biais dans les réseaux de neurones). Dans les langages de programmation, des variables qui peuvent recevoir une valeur spécifique renvoient le même résultat chaque fois que vous y accédez. Commençons par la révision d'un simple modèle linéaire, qui doit prédire le résultat de la somme pondérée d'une série de fonctionnalités d'entrée.
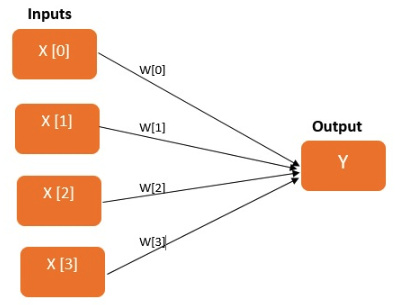
Pour comparer, dans un univers bayésien, des entités similaires, appelées variables aléatoires, vous donneront une valeur différente chaque fois que vous y accéderez. En termes bayésiens, les données historiques représentent notre connaissance antérieure du comportement global, et chaque variable possède ses propres propriétés statistiques qui varient au fil du temps. Imaginons que X est une variable aléatoire qui représente une distribution normale. Chaque fois que vous accédez à X, le résultat renvoyé aura une valeur différente. Le processus consistant à obtenir une nouvelle valeur à partir d'une variable aléatoire s'appelle échantillonnage. La valeur que nous obtenons dépend de la distribution de probabilité associée à la variable aléatoire. Autrement dit, dans l'espace des paramètres, on peut déduire la nature et la forme des paramètres appris par le réseau de neurones. Ce domaine a été le théâtre d'une activité intense ces derniers temps, notamment avec la publication de nombreuses bibliothèques programmatiques probabilistes comme PyMC3, Edward, Stan, etc. Les méthodes bayésiennes sont employées dans de nombreux secteurs, du développement de jeux à la découverte de médicaments.
Quels sont les principaux avantages des BNN ?
- Les réseaux de neurones bayésiens sont utiles pour résoudre des problèmes dans des domaines où les données sont insuffisantes, car ils offrent un moyen d'éviter le surajustement. La biologie moléculaire et le diagnostic médical, des disciplines où les données proviennent d'un travail expérimental difficile et coûteux, en sont deux très bons exemples.
- Les réseaux bayésiens ont une utilité universelle
- Ils peuvent produire de meilleurs résultats pour un grand nombre de tâches, mais il est difficile de les faire évoluer pour traiter des problèmes de grande envergure.
- Les BNN vous permettent de calculer l'erreur associée à vos prédictions lorsque vous traitez les données de cibles inconnues.
- Ils permettent également d'estimer l'incertitude des prédictions, ce qui est particulièrement utile dans des domaines comme la médecine.
Le guide pratique de l'IA agentique pour l'entreprise

Pourquoi utiliser les réseaux de neurones bayésiens ?
Plutôt que de prendre en compte une réponse unique à une question unique, les méthodes bayésiennes vous permettent d'envisager toute une répartition de réponses. Cette approche permet d'aborder naturellement des problématiques telles que :
- la régularisation (surajustement ou non),
- la sélection/comparaison de modèles, sans qu'il faille un dataset distinct de validation croisée
Ressources complémentaires
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.