Qu'est-ce que l'architecture Lambda ?
Architecture combinant traitement par lots et traitement en flux continu, avec une couche de traitement par lots pour la précision, une couche de vitesse pour les résultats en temps réel et une couche de diffusion fusionnant les deux.
- La couche de traitement par lots stocke l'ensemble de données principal sous une forme immuable en mode ajout uniquement. Elle précalcule les vues par lots via un traitement de type MapReduce, fournissant des résultats précis et complets, mais avec une latence de plusieurs heures.
- La couche de traitement rapide traite uniquement les flux de données récents à l'aide de systèmes à faible latence tels que Storm ou Flink, créant des vues en temps réel qui compensent le délai de la couche de traitement par lots. La cohérence est finalement atteinte lorsque les vues par lots sont mises à jour.
- La couche de service indexe les vues par lots et les vues de traitement rapide, permettant des requêtes ad hoc rapides et combinant les deux perspectives. La complexité de l'architecture a diminué grâce aux systèmes de flux comme Apache Spark, qui offrent des capacités de traitement par lots et en temps réel.
Qu’est-ce que l’architecture Lambda ?
L’architecture Lambda est une façon de traiter d’énormes volumes de données, commele Big Data. Elle permet d’accéder aux méthodes de traitement par batch et en streaming avec une approche hybride. Cette architecture est utilisée pour résoudre le problème du calcul de fonctions arbitraires. L’architecture Lambda elle-même est composée de trois couches :
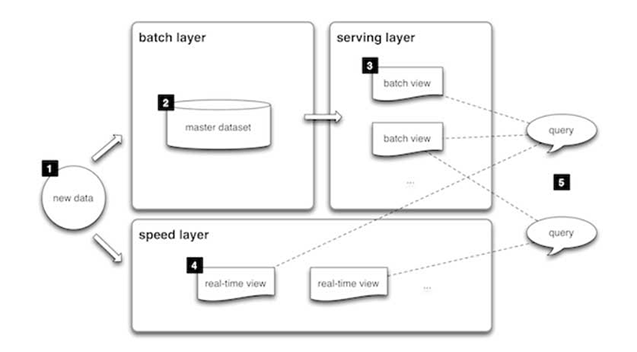
La couche batch
De nouvelles données sont introduites en continu dans le système de données. Ces données sont transmises simultanément à la couche batch et à la couche vitesse / temps réel. Le système examine toutes les données en même temps et corrige éventuellement les données dans la couche de streaming. On y trouve de nombreux processus ETL ainsi qu’un data warehouse traditionnel. Cette couche est développée selon une planification prédéfinie, généralement une ou deux fois par jour. La couche batch possède deux fonctions très importantes :
- Gérer le master dataset
- Pré-calculer les vues batch
Couche service
Les données de sorties de la couche batch, sous la forme de vues batch, et celles provenant de la couche vitesse, sous la forme de vues quasi temps réel, sont transmises à la couche service. Cette couche indexe les vues batch de manière à ce qu’elles puissent être interrogées à faible latence sur une base ad hoc.
Couche vitesse (temps réel)
Cette couche traite les données qui n’ont pas encore été fournies dans la vue batch en raison du temps de latence de la couche batch. De plus, elle traite uniquement les données récentes afin de fournir une vue complète des données à l’utilisateur en créant des vues temps réel.
Le guide pratique de l'IA agentique pour l'entreprise

Avantages de l’architecture Lambda
Voici les principaux avantages de l’architecture Lambda :
- Pas de gestion de serveur : vous n’avez pas à installer, maintenir ou administrer un quelconque logiciel.
- Mise à l’échelle flexible : votre application peut être mise à l’échelle automatiquement ou par ajustement de sa capacité.
- Haute disponibilité gérée automatiquement : en effet, les applications serverless ont déjà intégré la disponibilité et la tolérance aux pannes. Cela garantit que toutes les requêtes recevront une réponse pour signaler si elles ont abouti ou non.
- Agilité commerciale : cette architecture permet de réagir en temps réel à l’évolution des scénarios de l’entreprise ou du marché.
Défis de l’architecture Lambda
- Complexité : l’architecture Lambda peut s’avérer très complexe. Les administrateurs doivent généralement gérer deux bases de code distinctes pour la couche batch et la couche temps réel, ce qui peut compliquer le débogage.
Ressource connexe
Delta Lake : source et récepteur unifiés par lots comme en streaming
Ressources complémentaires
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.