Qu'est-ce que l'apprentissage automatique opérationnel ?
Le déploiement de modèles d'apprentissage automatique en production pour des prédictions en temps réel sur des données réelles nécessite une infrastructure pour la diffusion, la surveillance, le réentraînement et l'intégration.
- Les modèles de déploiement incluent les API REST pour les prédictions synchrones, le traitement par lots pour l'inférence hors ligne, le déploiement en périphérie sur les appareils et les modèles intégrés aux applications, en optimisant la latence, le débit et les ressources.
- La surveillance permet de suivre la précision des prédictions, les indicateurs de performance du modèle, la dérive des données (détection des changements de distribution), la dérive des concepts (identification des changements de relations), l'utilisation des ressources et les KPI métier mesurant l'impact du mod�èle.
- Les pratiques MLOps englobent les pipelines CI/CD pour le déploiement des modèles, les déclencheurs de réentraînement automatisés, les frameworks de tests A/B, les déploiements progressifs (canary) pour minimiser les risques, les capacités de restauration et les procédures de réponse aux incidents en cas de défaillance du modèle.
Auteur : Kevin Stumpf, cofondateur et CTO
En 2015, lorsque nous avons commencé à déployer la plateforme de Machine Learning d'Uber, Michelangelo, nous avons remarqué une tendance intéressante : 80 % des modèles de ML lancés sur la plateforme alimentaient des cas d'utilisation de machine learning opérationnel, qui ont un impact direct sur l'expérience de l'utilisateur final (les passagers et les chauffeurs d'Uber). Seulement 20 % étaient des cas d'utilisation de machine learning analytique, qui alimentent la prise de décision analytique.
Le ratio ML opérationnel/ML analytique que nous avons observé était l'exact opposé de la façon dont la plupart des autres entreprises appliquaient le ML dans la pratique : le ML analytique était roi. Avec le recul, l'adoption massive du ML opérationnel par Uber n'est pas une grande surprise : Michelangelo a rendu extrêmement facile la mise en œuvre du ML opérationnel, et l'entreprise disposait d'une longue liste de cas d'usage à fort impact. Aujourd'hui, 7 ans plus tard, la dépendance d'Uber vis-à-vis du ML opérationnel n'a fait qu'augmenter : sans lui, vous verriez des prix de trajet non rentables, de terribles prédictions d'ETA et des centaines de millions de dollars perdus à cause de la fraude. En bref, sans le ML opérationnel, l'entreprise serait paralysée.
Le ML opérationnel a été la clé de la réussite d'Uber et, pendant longtemps, il a semblé que seuls les géants de la technologie pouvaient y parvenir. Mais la bonne nouvelle, c'est que beaucoup de choses ont changé au cours des 7 dernières années. Il existe de nouvelles technologies et tendances qui permettent à n'importe quelle entreprise de passer d'une utilisation principalement analytique du ML à une utilisation opérationnelle du ML, et nous avons quelques conseils pour quiconque souhaite le faire. C'est parti.
ML opérationnel vs ML analytique
Le machine learning opérationnel consiste en une application qui utilise un modèle de ML pour prendre des décisions de manière autonome et continue qui ont un impact sur l'entreprise en temps réel. Ces applications sont critiques et s'exécutent « en ligne » en production sur la pile opérationnelle d'une entreprise.
Les exemples courants incluent les systèmes de recommandation, le classement des recherches, les Tarifs dynamiques, la détection des fraudes et l'approbation des demandes de prêt.
Le grand frère du ML opérationnel dans le monde « hors ligne » est le machine learning analytique. Ce sont des applications qui aident un utilisateur professionnel à prendre de meilleures décisions grâce au machine learning. Les applications de ML analytique se trouvent dans la stack analytique de l'entreprise et alimentent généralement directement les rapports, les tableaux de bord et les outils de business intelligence.
Les exemples courants incluent la prévision des ventes, les prédictions de churn et la segmentation client.
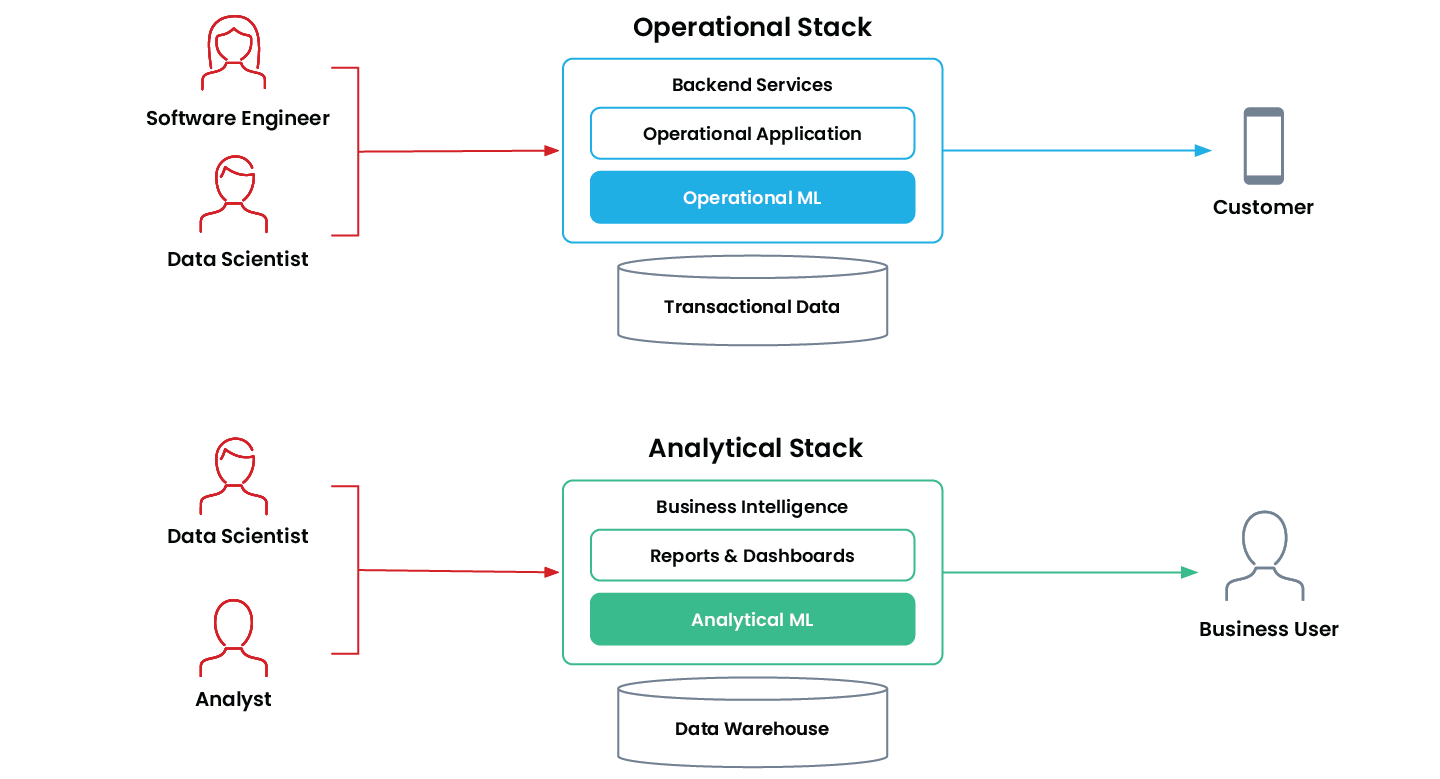
Les organisations utilisent le ML opérationnel et le ML analytique à des fins différentes, et chacun d'eux a des exigences techniques différentes.
| ML analytique | ML opérationnel | |
|---|---|---|
| Automatisation de la décision | Humain dans la boucle | Entièrement autonome |
| Vitesse de décision | Vitesse humaine | Temps réel |
| Optimisé pour | Traitement par lots à grande échelle | Faible latence et haute disponibilité |
| Audience principale | Utilisateur professionnel interne | Client |
| Pouvoirs | Rapports et tableaux de bord | Applications de production |
| Exemples | Prévision des ventes Scoring des leads Segmentation de la clientèle Prédictions du taux de résiliation | Recommandations de produits Détection de la fraude Prédiction du trafic Tarification en temps réel |
Caractéristiques du ML analytique vs. ML opérationnel
Le Machine Learning opérationnel en pratique
Examinons plus concrètement un exemple réel de machine learning opérationnel provenant d'Uber Eats. Lorsque vous ouvrez l'application, elle vous recommande une liste de restaurants et vous suggère le temps d'attente avant que la commande n'arrive à votre porte. Ce qui semble simple dans l'application est en réalité assez complexe en coulisses :
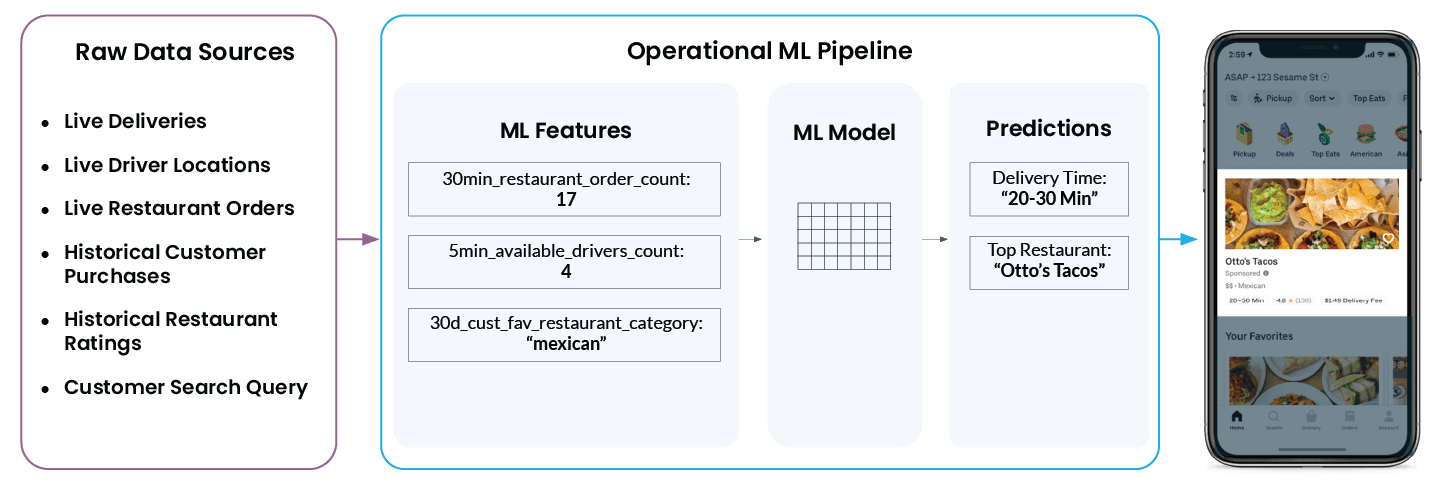
Pour finir par afficher « Otto’s Tacos » et « 20-30 min » dans l'application, la plateforme de ML d'Uber doit analyser un large éventail de données provenant de diverses sources de données brutes :
- Combien de Drivers se trouvent à proximité du restaurant en ce moment ? Sont-ils en train de livrer une commande ou sont-ils disponibles pour la prochaine course ?
- Quel est le niveau d'activité dans la cuisine du restaurant en ce moment ? Plus un restaurant traite de commandes, plus il lui faudra de temps pour commencer à préparer une nouvelle commande.
- Quels restaurants le client a-t-il bien et mal notés par le passé ?
- Quel type de cuisine, le cas échéant, l'utilisateur recherche-t-il activement en ce moment ?
- Et... quelle est la position actuelle de l'utilisateur ?
La plateforme de fonctionnalités de Michelangelo convertit ces données en fonctionnalités de ML. Ce sont les signaux sur lesquels un modèle est entraîné et qu'il utilise pour faire des prédictions en temps réel. Par exemple, ‘num_orders_last_30_min’ est utilisé comme fonctionnalité d'entrée pour prédire le délai de livraison, qui s'affichera à terme dans votre application mobile.
Les étapes que j'ai présentées ci-dessus, qui transforment des données brutes provenant d'une myriade de sources de données différentes en caractéristiques, et les caractéristiques en prédictions, sont communes à tous les cas d'utilisation du machine learning opérationnel. Qu'un système essaie de détecter la fraude à la carte de crédit, de prédire le taux d'intérêt d'un prêt automobile, de suggérer un article de journal dans la section des affaires internationales ou de recommander le meilleur jouet pour un enfant de 2 ans, les défis techniques sont identiques. Et c'est précisément cette similitude technique fondamentale qui nous a permis de créer une plateforme centrale unique pour tous les cas d'utilisation du ML opérationnel.
Le guide pratique de l'IA agentique pour l'entreprise

Les tendances qui favorisent le machine learning opérationnel
Uber était en bonne position pour tirer parti du ML opérationnel, car l'entreprise a bâti toute sa stack technologique sur une architecture de données et des principes modernes. Au cours des dernières années, nous avons assisté à une modernisation similaire bien au-delà de la Silicon Valley :
Les données historiques sont conservées presque indéfiniment
Les coûts de stockage des données se sont effondrés ces dernières années. Par conséquent, les entreprises ont pu collecter, acheter et stocker des informations sur chaque point de contact avec les clients. C'est crucial pour le ML : l'entraînement d'un bon modèle nécessite une grande quantité de données historiques. Et sans données, il n'y a pas de machine learning.
Les silos de données sont décloisonnés
Dès le premier jour, Uber a centralisé la quasi-totalité de ses données dans son système de fichiers distribué basé sur Hive. Le stockage de données centralisé (ou, comme alternative, l'accès centralisé à des magasins de données décentralisés) est important car il permet aux data scientists, qui entraînent les modèles de ML, de savoir quelles données sont disponibles, où les trouver et comment y accéder. La plupart des entreprises n'ont pas encore tout à fait centralisé l'intégralité de l'accès à leurs données. Cependant, les tendances architecturales telles que The Modern Data Stack ont rapproché le rêve du data scientist d'un accès démocratisé aux données de la réalité.
Les données en temps réel sont rendues disponibles grâce au streaming.
Chez Uber, nous avions la chance d'avoir un « système nerveux central » pour les flux de données : Kafka. De nombreux signaux en temps réel provenant des services et des applications mobiles sont diffusés via Kafka. C'est essentiel pour le ML opérationnel.
Vous ne pouvez pas détecter la fraude si vous savez seulement ce qui s'est passé hier. Vous devez savoir ce qui s'est passé au cours des 30 dernières secondes. Les data warehouses et les data lakes sont conçus pour le stockage à long terme des données historiques. Et au cours des dernières années, nous avons assisté à une adoption massive d'infrastructures de streaming, comme Kafka ou Kinesis, pour fournir aux applications des signaux en temps réel.
Le MLOps permet une itération rapide.
Chez Uber, chaque ingénieur a la possibilité d'apporter des modifications quotidiennes au système de production. Ce processus s'appuie sur le suivi et l'automatisation des principes DevOps. Avec Michelangelo, nous avons appliqué ces principes au ML opérationnel avant même que le processus ne soit appelé MLOps 🙂. Il était important pour nous que les data scientists puissent entraîner des modèles et les déployer en production en toute sécurité, et ce, littéralement en une seule journée.
En dehors d'Uber et bien au-delà de la Silicon Valley, nous avons constaté qu'un nombre croissant d'adopteurs précoces appliquent les principes du DevOps et l'automatisation non seulement à leur ingénierie logicielle, mais aussi à leurs équipes de Data Science via MLOps. Bien sûr, le ML est encore beaucoup plus difficile à mettre en œuvre que l'outil pour la plupart des entreprises, pour des raisons que j'ai exposées dans ce blog. Mais je suis convaincu que l'industrie se dirige progressivement vers un avenir dans lequel le data scientist typique d'une organisation Fortune 500 typique sera capable d'itérer sur un modèle de ML opérationnel plusieurs fois par jour.
Voici à quoi ressemble une architecture de données moderne qui permet le ML opérationnel :
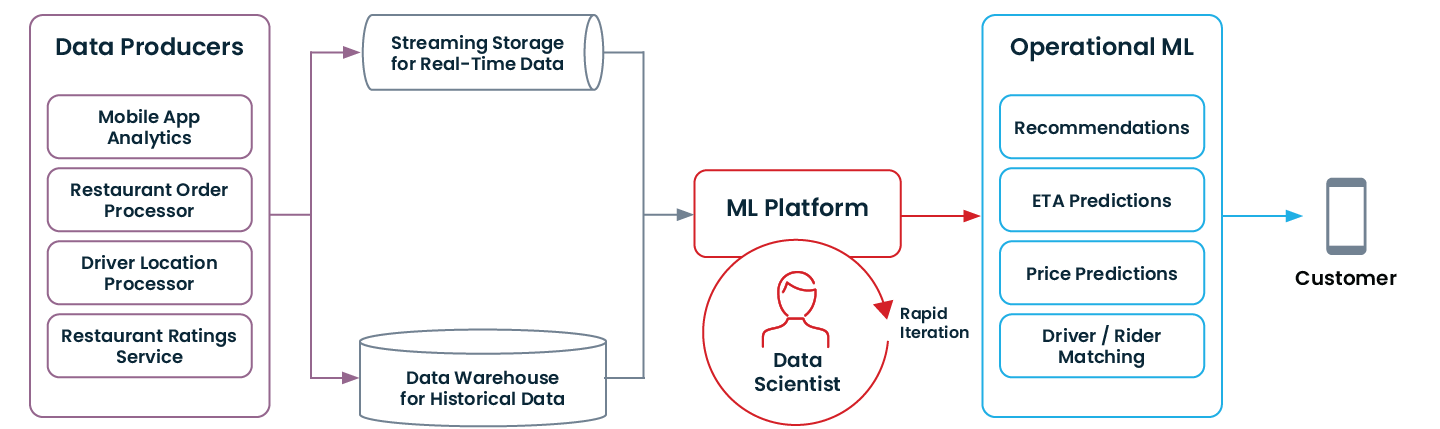
Si votre organisation a procédé à certaines des modernisations mentionnées ci-dessus (ou si elle est partie de zéro !), vous êtes peut-être prêt à vous lancer dans le ML opérationnel.
Démarrez avec le Machine Learning opérationnel
En 2013, Uber n'utilisait pas le machine learning en production. Aujourd'hui, des dizaines de milliers de modèles sont en production. Ce changement ne s'est pas fait du jour au lendemain.
Si vous cherchez à tirer parti du ML opérationnel au sein de votre organisation, je vous recommande de suivre les étapes suivantes :
Choisissez un cas d'utilisation adapté au machine learning
Tous les problèmes ne peuvent pas être résolus avec le ML. Critères pour un problème qui pourrait bien se prêter au ML :
- Votre système prend un grand nombre de décisions très similaires et répétées (au moins des dizaines de milliers).
- Prendre la bonne décision n'est pas trivial
- Quelque temps après que la décision a été prise, vous avez un moyen de déterminer si elle était bonne ou mauvaise.
Si ces éléments sont réunis, une application de machine learning peut prendre des décisions, apprendre de ces décisions et s'améliorer en continu.
Choisissez un cas d'utilisation qui compte vraiment
Comme mentionné précédemment, le chemin pour mettre le premier modèle en production est difficile. Si les bénéfices futurs de votre première application de machine learning ne sont pas très prometteurs, il sera trop facile d'abandonner face aux difficultés. Les priorités changeront, la direction pourrait s'impatienter et l'effort ne durera pas. Choisissez un cas d'usage à fort potentiel.
Responsabilisez une petite équipe et réduisez le nombre de parties prenantes pour votre premier modèle
La probabilité d'échec d'un projet augmente avec le nombre de transferts impliqués dans l'entraînement et le déploiement d'un modèle. Idéalement, startez avec une très petite équipe de 2 à 3 personnes qui a accès à toutes les données nécessaires, sait comment entraîner un modèle simple et est suffisamment familière avec votre stack de production pour mettre une application en production.
Les ingénieurs ML sont les mieux placés pour ouvrir la voie, étant donné qu'ils possèdent généralement une combinaison rare de compétences en Data Engineering, en génie logiciel et en Data Science. C'est aussi comment vous devriez monter en charge les équipes de machine learning, avec de petits groupes d'experts ML intégrés aux équipes produit.
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.