Qu'est-ce qu'une plateforme de fonctionnalités ?
Infrastructure pour la gestion du cycle de vie des fonctionnalités, incluant l'ingénierie, le stockage, la découverte, la surveillance et la gouvernance, avec des API pour la création et la diffusion.
- Les composants incluent des outils de création de fonctionnalités pour définir les transformations, des systèmes d'orchestration planifiant les pipelines de calcul, des couches de stockage pour les fonctionnalités hors ligne et en ligne, des API pour un accès en temps réel et des tableaux de bord de surveillance assurant le suivi de la qualité.
- Il prend en charge le calcul par lots des fonctionnalités pour l'entraînement des modèles, la mise à jour en continu des fonctionnalités pour les systèmes en temps réel, le calcul à la demande des fonctionnalités lors de l'inférence et le remplissage des données manquantes pour les expériences historiques.
- Ses fonctionnalités avancées comprennent la validation des fonctionnalités garantissant leur qualité, les tests automatisés pour les pipelines de fonctionnalités, une infrastructure de tests A/B pour les expériences sur les fonctionnalités et l'intégration avec les plateformes d'apprentissage automatique pour des flux de travail de développement de modèles fluides.
Jusqu’à il y a deux ans, seules les grandes entreprises technologiques disposaient des ressources et de l’expertise nécessaires pour développer des produits reposant entièrement sur des systèmes de machine learning. C'est le cas de Google avec les enchères publicitaires, de TikTok avec la recommandation de contenus ou d'Uber avec l’ajustement dynamique des prix. Pour alimenter leurs applications les plus critiques avec le machine learning, ces équipes ont développé une infrastructure personnalisée répondant aux besoins uniques du déploiement de systèmes de ML.
Quelques années plus tard, tout un écosystème d'outils MLOps a vu le jour pour démocratiser le machine learning en production. Mais avec des centaines d'outils différents, comprendre ce que chacun fait est désormais un travail à plein temps. Les plateformes de fonctionnalités et leurs proches parents, les magasins de fonctionnalités, constituent désormais des éléments courants de cet écosystème. En bref, une plateforme de fonctionnalités permet d'utiliser votre infrastructure de données existante (entrepôts de données, infrastructure de streaming comme Kafka, processeurs de données comme Spark/Flink, etc.) pour des applications de ML opérationnel. Cet article explique plus en détail ce que sont les plateformes de fonctionnalités et les problèmes qu'elles résolvent.
Développer le machine learning opérationnel est difficile.
Les plateformes de fonctionnalités permettent le machine learning opérationnel (ML). Cela se produit lorsqu'une application destinée aux clients utilise le ML pour prendre de manière autonome et continue des décisions ayant un impact sur l'entreprise en temps réel. Les exemples de Google, TikTok et Uber que j'ai partagés sont tous des applications de ML opérationnel. Tout projet de machine learning se compose toujours de quatre étapes :
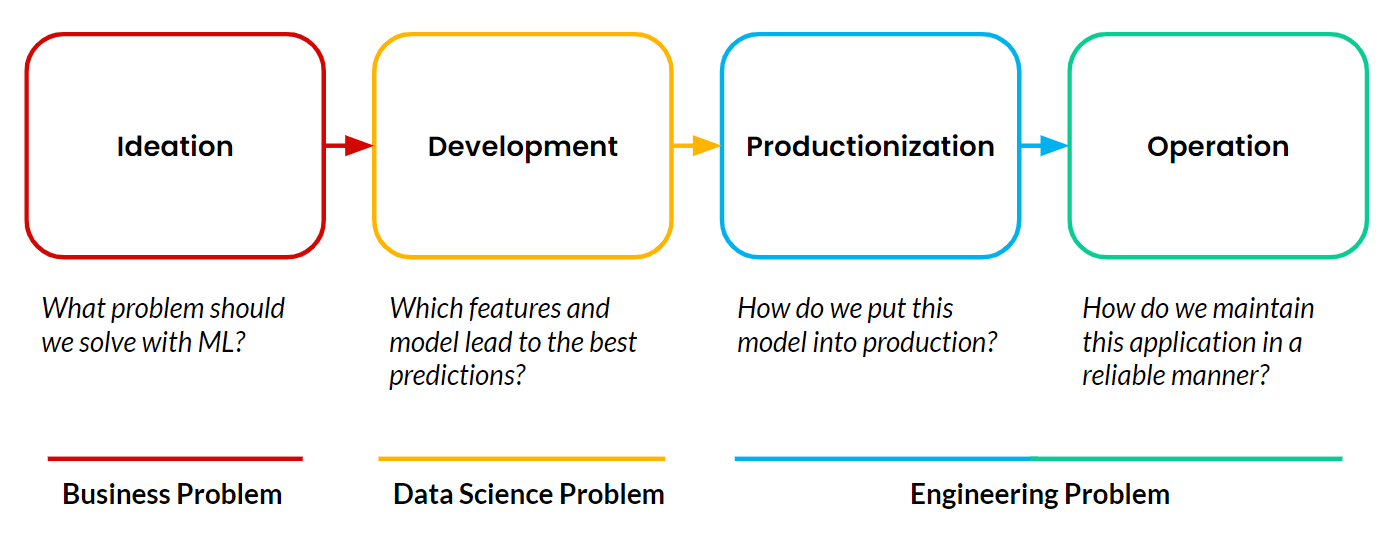
La plupart des projets ne dépassent jamais la phase de développement. La mise en production et l'exploitation des applications de machine learning restent le principal obstacle pour les équipes. Et la partie la plus difficile de la mise en production et de l'exploitation du ML est la gestion des pipelines de données alimentant en continu ces applications.
Une plateforme de fonctionnalités résout les défis liés aux données associés à la mise en production et aux opérations. Elle cr�ée un chemin vers la production. Nous expliquerons plus en détail ce que cela signifie, mais décrivons d'abord ce qu'est une fonctionnalité.
Qu'est-ce qu'une fonctionnalité de machine learning ?
En machine learning, une fonctionnalité (ou feature en anglais) est une donnée utilisée comme entrée pour les modèles de ML afin de faire des prédictions. Les données brutes sont rarement dans un format directement exploitable par un modèle de ML et doivent donc être transformées en fonctionnalités. Ce processus est appelé ingénierie des fonctionnalités.
Par exemple, si une société de cartes de crédit essaie de détecter des transactions frauduleuses, une transaction effectuée dans un pays étranger peut être un bon indicateur de fraude. Les fonctionnalités finissent par être des colonnes dans les données envoyées à un modèle.
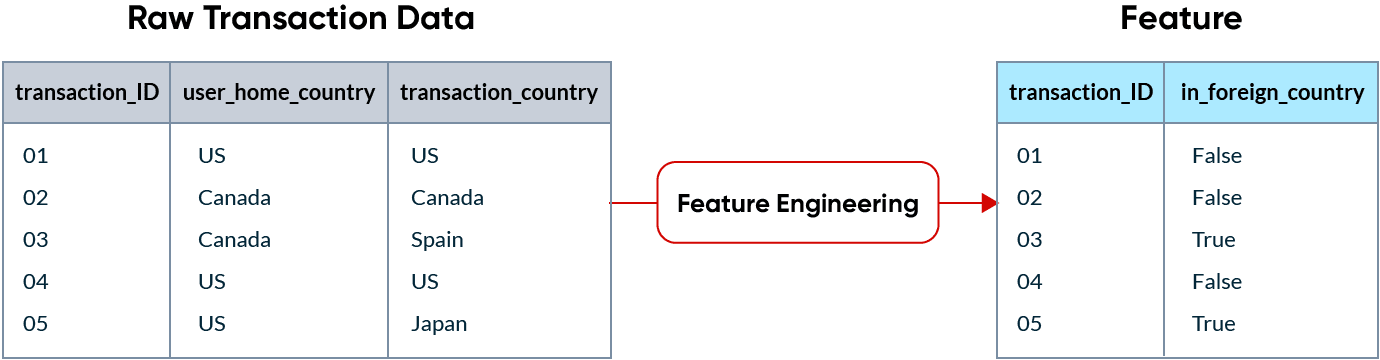
La particularité du ML, c'est que les fonctionnalités sont utilisées de deux manières différentes :
- Pour entraîner un modèle, nous avons besoin de grandes quantités de données historiques.
- Pour réaliser une prédiction en temps réel, nous devons fournir au modèle uniquement les fonctionnalités les plus récentes, et le faire en quelques millisecondes. Cela s'appelle aussi l'inférence en ligne. Dans cet exemple, le modèle a seulement besoin de savoir si la transaction actuelle a lieu dans un pays étranger ou non, et il doit traiter cette information pendant que la transaction se déroule.
Quels problèmes une plateforme de fonctionnalités résout-elle ?
Lors de la phase de développement d'un projet de ML, les data scientists effectuent de nombreuses opérations d'engineering pour trouver les fonctionnalités permettant d'obtenir la meilleure précision de prédiction. Une fois ce processus terminé, ils transmettent généralement le projet à un collègue ingénieur qui mettra ces pipelines d'engineering de fonctionnalités en production.
En tant que data scientist, l’objectif n’est pas de se préoccuper de la manière dont les données sont rendues disponibles, ni de la façon dont elles sont calculées. Vous savez quelles fonctionnalités vous souhaitez utiliser et vous voulez qu’elles soient disponibles pour que le modèle puisse produire des prédictions en temps réel. Les ingénieurs, en revanche, doivent réimplémenter ces pipelines de données dans un environnement de production. Cela devient rapidement très complexe dès que des données en temps réel ou quasi temps réel sont impliquées. Pour alimenter les applications de ML opérationnelles, ces pipelines doivent fonctionner en continu, ne pas tomber en panne, être extrêmement rapides et monter en charge avec l'activité.
La réimplémentation des pipelines de données dans un environnement de production est le principal obstacle pour les projets de ML opérationnel. Pour en revenir à l'exemple de la détection de fraude, les caractéristiques réalistes que les entreprises mettront en œuvre sont :
- Distance entre le domicile d'un utilisateur et le lieu où la transaction se déroule, calculée au moment même de la transaction.
- Si le montant d’une transaction en cours dépasse de plus d’un écart type la moyenne historique observée chez ce commerçant.
- Nombre de transactions d'un utilisateur au cours des 30 dernières minutes, mis à jour chaque seconde.
Ces pipelines d'ingénierie des fonctionnalités sont difficiles à mettre en œuvre. Ils ne peuvent pas être calculés directement sur un data warehouse et nécessitent la mise en place d'une infrastructure de streaming pour traiter les données en temps réel. Une plateforme de fonctionnalités résout les défis d'ingénierie liés à la mise en production de ces variables et, ce faisant, crée une voie simplifiée vers le déploiement opérationnel. Concrètement, une plateforme de fonctionnalités :
- Orchestre et exécute en continu des pipelines de données afin de calculer les fonctionnalités et les rendre disponibles à la fois pour l’entraînement hors ligne et l’inférence en ligne
- Gère les fonctionnalités en tant que code, ce qui permet aux équipes d'effectuer des revues de code, d'utiliser un contrôle de version et d'intégrer les modifications dans les pipelines CI/CD.
- Crée une bibliothèque de fonctionnalités, en standardisant leurs définitions et en permettant aux data scientists de les partager à toutes les équipes.
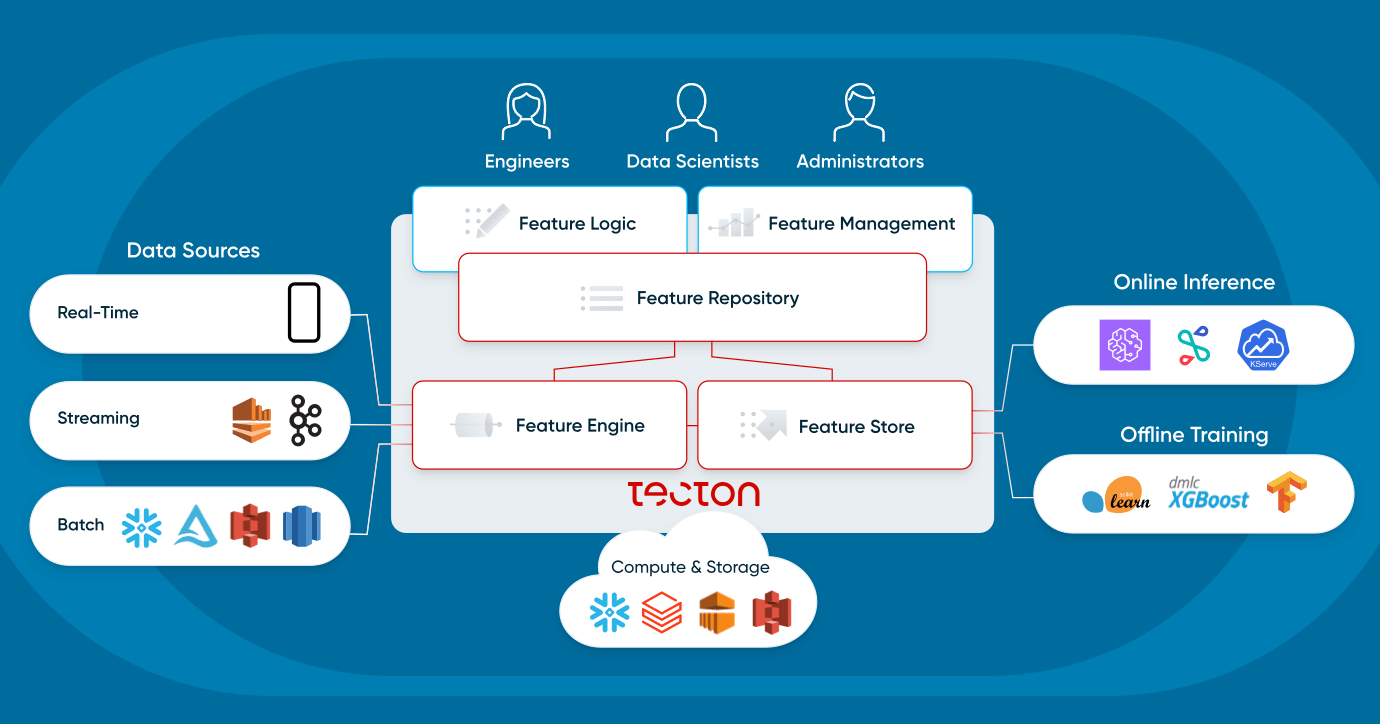
Examinons plus en détail comment les utilisateurs interagissent avec une plateforme de fonctionnalités et quels sont ses composants.
Le guide pratique de l'IA agentique pour l'entreprise

Qu'est-ce qu'une plateforme de fonctionnalités ?
Une plateforme de fonctionnalités est un système qui orchestre l'infrastructure de données existante pour transformer, stocker et servir des données en continu pour les applications de ML opérationnelles.
Il existe deux manières principales pour les utilisateurs d'interagir avec une plateforme de fonctionnalités :
- Création et découverte de fonctionnalités
- Les utilisateurs définissent de nouvelles fonctionnalités en tant que code dans des fichiers Python à l'aide d'un framework déclaratif. Les définitions de fonctionnalités sont gérées dans un dépôt git.
- Les utilisateurs découvrent les fonctionnalités existantes que d'autres équipes ont définies.
- Récupération de fonctionnalités
- Au moment de l'entraînement, les utilisateurs peuvent appeler la plateforme de fonctionnalités dans un notebook pour obtenir toutes les données historiques nécessaires à l'entraînement d'un modèle. Cela peut être fait avec un appel tel que get_historical_features(fraud_model). La plateforme de fonctionnalités gère la complexité du rétroremplissage des fonctionnalités et de la réalisation de jointures respectant la chronologie. Le jeu de données qui en résulte peut être ingéré par n'importe quel outil d'entraînement de modèle, tel que XGBoost, Scikit-learn, etc.
- Au moment de l'inférence, la plateforme de fonctionnalités expose un point de terminaison REST qui peut être appelé par une application en direct. Cela renvoie en quelques millisecondes le dernier vecteur de fonctionnalités pour un ID d'entité donné, que le modèle utilisera pour effectuer une prédiction.
Les plateformes de fonctionnalités ne remplacent pas l'infrastructure existante. Au contraire, elles permettent de l'utiliser pour les applications de ML opérationnel —elles se connectent (1) aux sources de données par lots telles que les data lakes et les data warehouses, et (2) aux sources de streaming comme Kafka. Elles utilisent (3) l'infrastructure de calcul existante, telle qu'un data warehouse ou Spark, et (4) l'infrastructure de stockage existante, telle que S3, DynamoDB ou Redis. Une plateforme de fonctionnalités moderne se connecte de manière flexible à l'infrastructure de données existante d'une organisation.
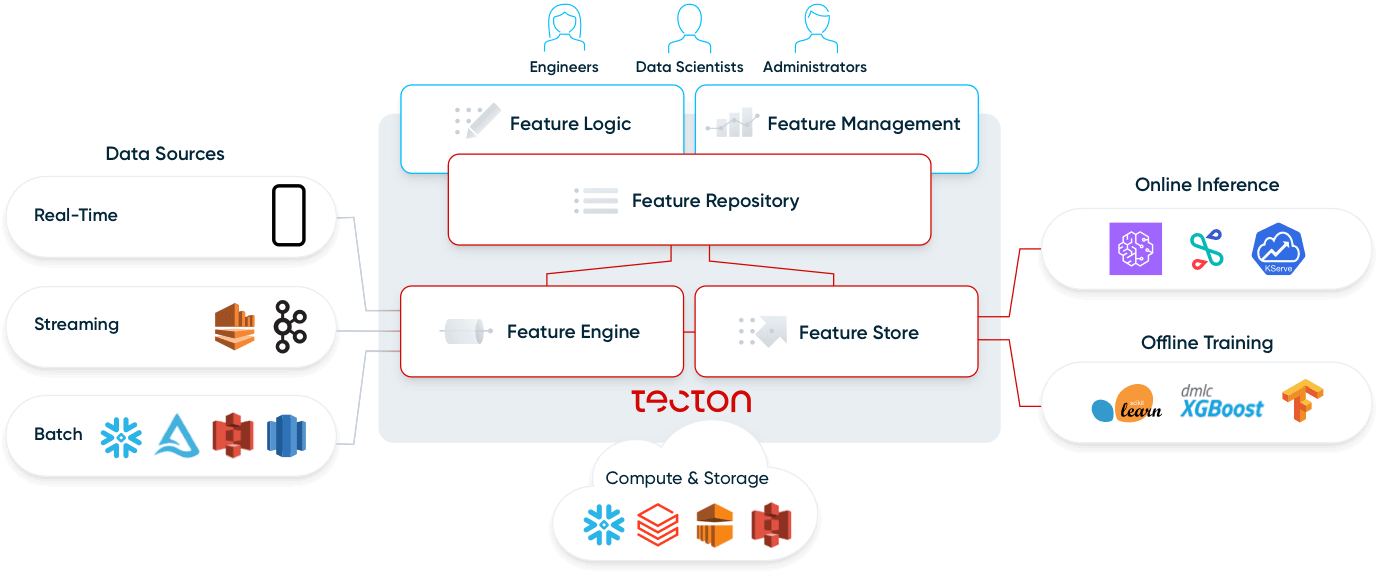
Examinons de plus près les quatre composants d'une plateforme de fonctionnalités : le référentiel, les pipelines, le magasin et le monitoring.
Référentiel de fonctionnalités
De nombreux data scientists réalisent leur ingénierie de fonctionnalités dans des notebooks. Ils sont interactifs, faciles à utiliser et permettent des cycles de développement rapides. Les difficultés commencent lorsque ces fonctionnalités doivent être mises en production ; il est impossible de les intégrer dans des pipelines CI/CD et de disposer des contrôles que nous utilisons avec les logiciels traditionnels.
Les équipes qui déploient avec succès des applications de ML opérationnel gèrent leurs fonctionnalités en tant qu'actifs de code. Tous les avantages du DevOps sont réunis : revues de code, suivi de la traçabilité, intégration aux pipelines CI/CD... Cela permet aux équipes d'effectuer les modifications plus rapidement et de manière plus fiable. Un symptôme courant des équipes qui ne gèrent pas les fonctionnalités en tant que code est qu'elles sont souvent incapables d'itérer au-delà de la première version d'un modèle.
Dans une plateforme de fonctionnalités, les utilisateurs définissent les fonctionnalités sous forme de code à l'aide d'une interface déclarative qui contient trois éléments :
- Configuration sur la fréquence à laquelle la fonctionnalité doit être calculée.
- Des métadonnées, telles que le nom et la description de la fonctionnalité, pour permettre le partage et la découvrabilité.
- Logique de transformation, définie en SQL ou en Python.
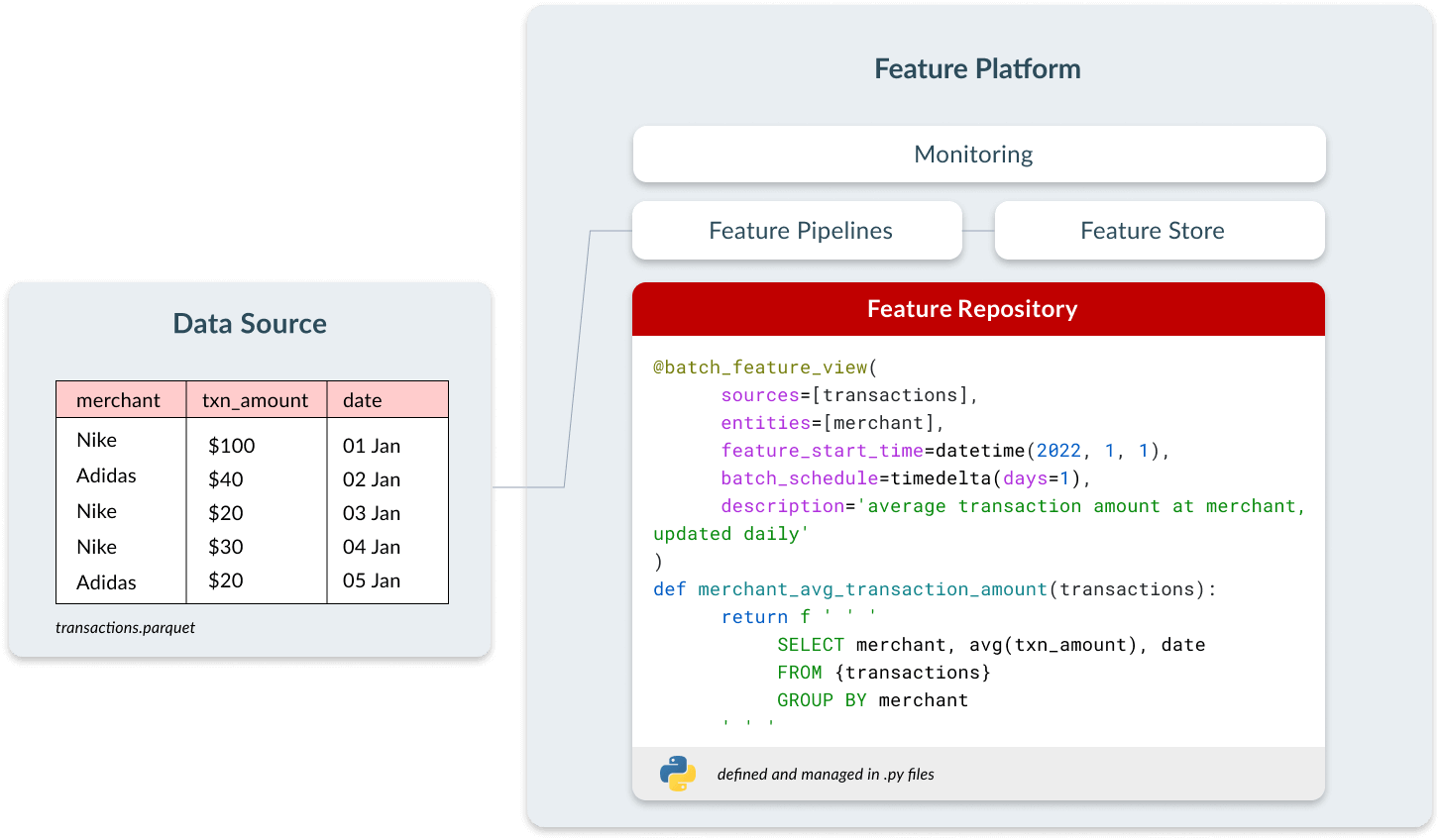
Ces fonctionnalités sont alors disponibles de manière centralisée pour que toutes les équipes puissent les découvrir et les utiliser dans leurs propres modèles. Cela permet de gagner du temps de développement, d'assurer la cohérence entre les équipes et de réduire les coûts de calcul. Les fonctionnalités n'ont ainsi pas besoin d'être calculées plusieurs fois pour différents cas d'usage.
Pipelines de fonctionnalités
Les applications de machine learning opérationnel nécessitent un traitement continu de nouvelles données afin que les modèles puissent faire des prédictions en utilisant des données à jour. Une fois qu'un utilisateur a défini la fonctionnalité dans le référentiel, la plateforme traite automatiquement les pipelines de données pour calculer cette fonctionnalité.
Il existe trois types de transformations de données qu'une plateforme de fonctionnalités doit prendre en charge :
| Transformation | Définition | Source de données | Exemple |
|---|---|---|---|
| Batch | Transformations appliquées uniquement aux données au repos | data warehouse, data lake, base de données | Montant moyen des transactions par commerçant, mis à jour quotidiennement |
| Streaming | Transformations appliquées aux sources de streaming | Kafka, Kinesis, PubSub, Flink | Nombre de transactions de l'utilisateur sur les 30 dernières minutes, mis à jour toutes les secondes |
| À la demande | Transformations utilisées pour produire des fonctionnalités basées sur des données qui ne sont disponibles qu'au moment de la prédiction. Ces fonctionnalités ne peuvent pas être pré-calculées. | Application destinée à l'utilisateur, APIs pour les services RPC, Données en mémoire | Le montant de la transaction actuelle est-il supérieur de plus de deux écarts-types au montant moyen des transactions de l'utilisateur, calculé au moment même de la transaction ? |
Ces transformations sont exécutées sur des moteurs de traitement de données (Spark, Snowflake, Python) auxquels la plateforme de fonctionnalités est connectée. La plateforme de fonctionnalités transmet à l’identique le code de transformation défini par l’utilisateur au moteur de traitement de données sous-jacent. Cela signifie que la plateforme de fonctionnalités ne doit pas imposer son propre dialecte SQL ni son propre langage dédié (DSL) en Python. Cela simplifie à la fois l'expérience d'intégration à la plateforme de fonctionnalités et l'expérience de debugging.
Les transformations batch sont simples à exécuter — elles peuvent être exécutées via une requête SQL sur un data warehouse ou en exécutant un job Spark. Cependant, les applications de ML opérationnel tirent le plus grand profit des informations fraîches qui ne sont accessibles que par le biais de transformations en streaming et à la demande. Dans l'exemple de la détection de fraude, les fonctionnalités qui permettront au modèle de réaliser la meilleure prédiction contiendront des informations sur la transaction en cours (le montant, le commerçant et le lieu), ou des informations sur les transactions qui ont eu lieu au cours des dernières minutes.
Toutes les équipes avec lesquelles nous discutons s’accordent à dire que l’accès à des données récentes améliorerait les performances de la majorité de leurs modèles. La plupart des organisations n'utilisent encore que des transformations batch, car la gestion des transformations en streaming et à la demande est complexe. Une plateforme de fonctionnalités fait abstraction de cette complexité, permettant à un utilisateur de définir la logique de transformation et de choisir si elle doit être exécutée en tant que transformation par batch, en streaming ou à la demande.
Lors de l'itération sur de nouvelles fonctionnalités en phase de développement, les données doivent être remplies rétroactivement pour générer des jeux de données d'entraînement. Par exemple, nous pouvons développer aujourd'hui une nouvelle fonctionnalité merchant_fraud_rate, qui devra être remplie rétroactivement pour l'ensemble de la fenêtre temporelle sur laquelle nous voulons entraîner le modèle. Les plateformes exécutent ces transformations automatiquement lors de la définition de nouvelles fonctionnalités, ce qui permet des cycles d'itération rapides dans le processus de développement.

Magasin de fonctionnalités
Les magasins de fonctionnalités sont devenus de plus en plus populaires depuis que nous avons introduit le concept pour la première fois avec Uber Michelangelo en 2017. Ils ont un double objectif : stocker et servir des fonctionnalités de manière cohérente entre les environnements d'entraînement hors ligne et d'inférence en ligne.
Lorsque les fonctionnalités ne sont pas stockées de manière cohérente dans les deux environnements, les fonctionnalités sur lesquelles le modèle est entraîné peuvent présenter des différences subtiles par rapport à celles qu'il utilise pour l'inférence en ligne. Ce phénomène, appelé "décalage entraînement-service", peut ruiner les performances d'un modèle de manière silencieuse et catastrophique, tout en étant extrêmement difficile à déboguer. En disposant de données cohérentes dans les deux environnements, un magasin de fonctionnalités résout ce problème.
Pour l'entraînement hors ligne, les magasins de fonctionnalités doivent contenir des mois ou des années de données. Ces données sont stockées dans des data warehouses ou des data lakes comme S3, BigQuery, Snowflake ou Redshift. Ces sources de données sont optimisées pour l'extraction à grande échelle.
Pour l'inférence en ligne, les applications doivent avoir un accès ultra-rapide à de petites quantités de données. Pour permettre des recherches à faible latence, ces données sont conservées dans un magasin en ligne comme DynamoDB, Redis ou Cassandra. Seules les dernières valeurs de fonctionnalités pour chaque entité sont conservées dans le magasin en ligne.

Pour récupérer les données hors ligne, les valeurs des fonctionnalités sont généralement accessibles via un SDK compatible avec les notebooks. Pour l'inférence en ligne, un magasin de fonctionnalités fournit un vecteur unique de fonctionnalités contenant les données les plus récentes. Bien que la quantité de données dans chacune de ces requêtes soit faible, un magasin de fonctionnalités doit pouvoir monter en charge à des milliers de requêtes par seconde. Ces réponses sont servies en quelques millisecondes aux applications en production via un point de terminaison REST. Les magasins de fonctionnalités performants doivent fournir des SLA sur la disponibilité et la latence.

Surveillance
Lorsqu’un système de machine learning en production dysfonctionne, la cause est le plus souvent liée aux données. Puisque les plateformes de fonctionnalités gèrent le processus de bout en bout, des données brutes jusqu'aux modèles, elles sont idéalement positionnées pour détecter les anomalies de données. Il existe deux types de monitoring que les plateformes de fonctionnalités prennent en charge :
Contrôle qualité des données
Les plateformes de fonctionnalités peuvent suivre la distribution et la qualité des données entrantes. Y a-t-il des changements significatifs dans la distribution des données depuis le dernier entraînement du modèle ? Observons-nous soudainement plus de valeurs manquantes ? Cela a-t-il un impact sur les performances du modèle ?
Monitoring opérationnel
Lors de l'exécution de systèmes de production, il est également important de surveiller les métriques opérationnelles. Les plateformes de fonctionnalités suivent l’obsolescence des variables afin de détecter lorsque les données ne sont pas mises à jour au rythme attendu. Elles mesurent aussi des indicateurs liés au stockage (disponibilité, capacité, utilisation) ainsi qu’au service (débit, latence, requêtes par seconde, taux d’erreur). Une plateforme de fonctionnalités surveille également que les pipelines exécutent les tâches comme prévu, détecte les échecs de traitement et résout automatiquement les incidents.
Les plateformes de fonctionnalités mettent ces métriques à la disposition de l'infrastructure de monitoring existante. Les applications de ML opérationnel doivent être suivies comme n'importe quelle autre application de production, et sont gérées avec les outils d'observabilité existants.
Synthèse
Une partie de la magie d'une plateforme est de faciliter la mise en production rapide de nouvelles fonctionnalités par les équipes de machine learning. Mais la création de valeur s’accélère lorsque la plateforme de fonctionnalités est utilisée par plusieurs équipes et alimente plusieurs cas d'usage.

Une plateforme de fonctionnalités permet aux data engineers de prendre en charge un plus grand nombre de data scientists qu'ils ne le pourraient autrement. Nous avons échangé avec de nombreuses équipes qui, en l'absence de plateforme de fonctionnalités, avaient besoin de deux data engineers pour soutenir un seul data scientist. Une plateforme de fonctionnalités leur a permis de largement inverser ce ratio. Une fois qu'une plateforme est largement adoptée, les data scientists peuvent facilement ajouter à leurs modèles des fonctionnalités qui sont déjà calculées. Nous observons un schéma récurrent : les équipes mettent plusieurs mois à déployer leur premier cas d’usage, quelques semaines pour le second, puis seulement quelques jours pour en déployer de nouveaux ou itérer sur les existants.
Quand adopter (ou non) une plateforme de fonctionnalités
J'ai commencé cet article en décrivant à quel point il est difficile de se tenir au courant de l'ensemble de l'écosystème des outils MLOps ayant émergé ces dernières années. En réalité, vous devriez garder votre stack aussi simple que possible et n'adopter des outils que lorsqu'ils sont vraiment nécessaires.
Nous constatons que les équipes tirent profit d'une plateforme de fonctionnalités lorsqu'elles :
- Ont fait l'expérience du processus de transfert entre les data scientists et les data engineers et de la difficulté associée à la réimplémentation des pipelines de données pour la production.
- Déploient des applications de machine learning en production qui doivent respecter des niveaux de SLA stricts, passer à l’échelle et rester fiables en conditions réelles.
- Disposent de plusieurs équipes qui souhaitent standardiser les définitions de fonctionnalités et les réutiliser d’un modèle à l’autre.
Les équipes devraient éviter d'adopter une plateforme de fonctionnalités lorsqu'elles :
- Sont en phase d'idéation ou de développement, et ne sont pas prêtes à être mises en production.
- Ne disposent que d'une seule équipe travaillant uniquement avec des données batch.
Bien démarrer
Plusieurs options s'offrent à vous pour commencer :
- Tecton est une plateforme de fonctionnalités managée. Elle inclut tous les composants décrits ci-dessus. Nos clients choisissent Tecton, car ils ont besoin de SLA de production et de fonctionnalités d'entreprise, sans avoir à gérer eux-mêmes une solution. Tecton est utilisé par des équipes de ML allant des startups technologiques à plusieurs entreprises du classement Fortune 500.
- Feast est le magasin de fonctionnalités open source le plus populaire. Il s’agit d’une option pertinente si vous disposez déjà de pipelines de transformation pour calculer vos fonctionnalités et souhaitez les stocker puis les servir en production. Au fil du temps, Feast continuera d'ajouter des pipelines de fonctionnalités et des capacités de monitoring qui en feront une plateforme complète.
J'ai écrit cet article de blog afin de fournir une définition commune des plateformes de fonctionnalités, car elles sont désormais consolidées en tant que composant central de la pile technologique pour les applications de ML opérationnel.
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.