Data Warehousing intelligent sur Databricks - Cloné
Cette architecture de référence montre comment la Databricks Data Intelligence Platform permet le data warehousing moderne et la BI en combinant l'ingestion streaming et batch, le stockage gouverné, le SQL analytique et l'AI sur un lakehouse unifié.
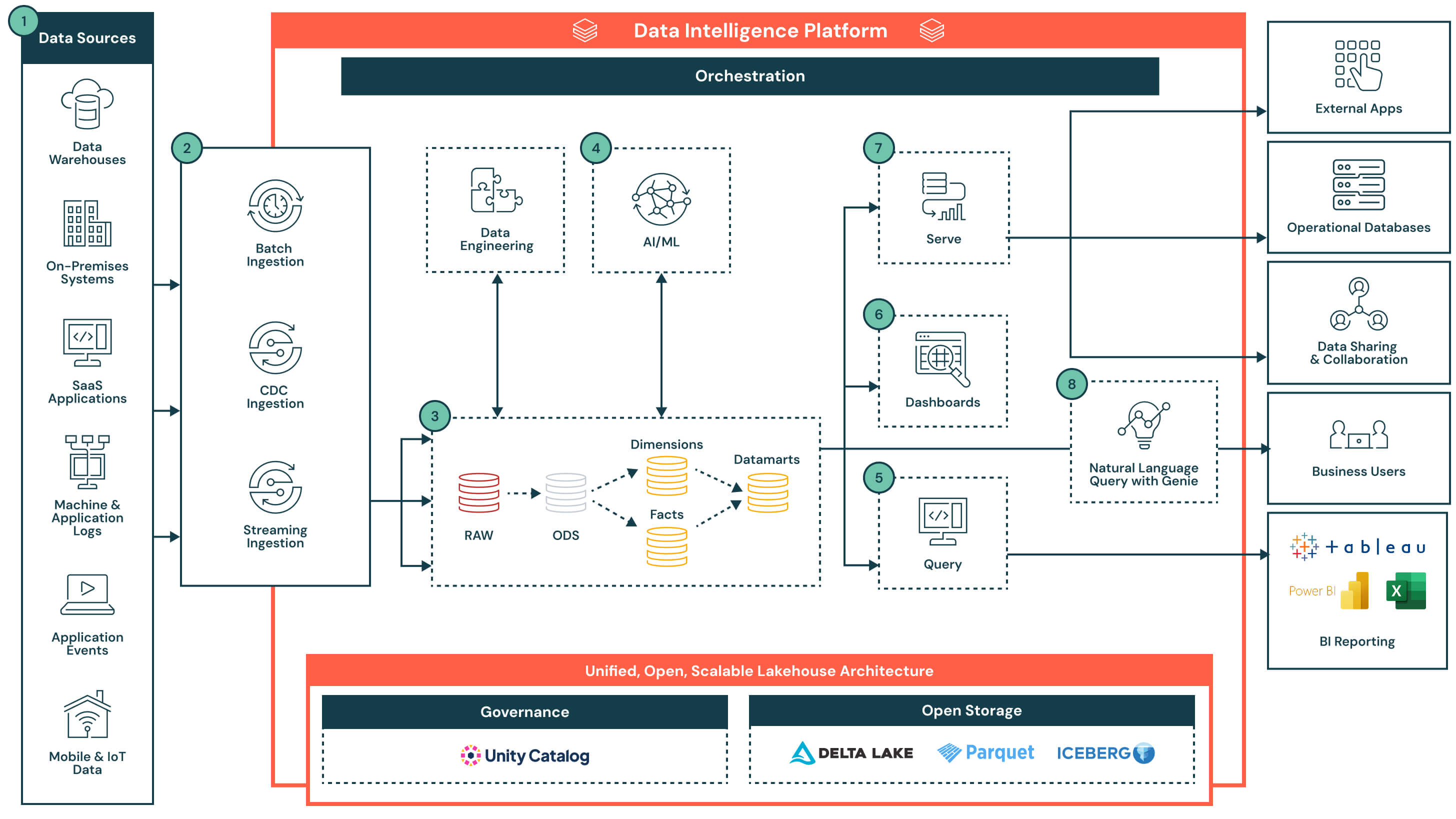
Synthèse de l'architecture
L'architecture prend en charge le reporting traditionnel, les tableaux de bord en temps réel, la modélisation prédictive et les analyses en libre-service — tout en respectant les normes de l'entreprise en matière de sécurité, de gouvernance et de performance.
Cette solution démontre comment la plateforme Databricks Data Intelligence, propulsée par le lakehouse Databricks, aide les entreprises à moderniser leur stratégie d'entreposage de données tout en répondant aux besoins des équipes de données et des parties prenantes métier.
L'architecture commence par un lakehouse ouvert et gouverné, géré par Unity Catalog. Les données sont ingérées à partir de divers systèmes — y compris des bases de données opérationnelles, des applications SaaS, des flux d'événements et des systèmes de fichiers — et arrivent dans une couche de stockage centrale. L'intelligence des données de la plateforme alimente tout, des analyses ETL et SQL aux tableaux de bord et aux cas d'usage de l'AI. En prenant en charge un accès flexible via SQL, des outils de BI et des requêtes en langage naturel, la plateforme accélère la livraison de produits de données et rend les informations accessibles dans toute l'organisation.
Cas d'usage
Cas d'usage techniques
- Ingestion de données structurées, non structurées, batch et en streaming provenant de diverses sources
- Construction de pipelines ETL déclaratifs et robustes
- Modélisation des faits, des dimensions et des data marts à l'aide d'une architecture médaillon
- Exécution de requêtes SQL à haute simultanéité pour le reporting et la création de tableaux de bord
- Intégration des résultats de ML directement dans l'entrepôt pour une utilisation en aval
Cas d'usage métier
- Fourniture de tableaux de bord en temps réel sur les ventes, les opérations ou les indicateurs clients
- Permettre l'exploration ad hoc via des interfaces en langage naturel comme Genie
- Prise en charge de cas d'usage prédictifs tels que la prévision de la demande et la modélisation du churn
- Partage de produits de données gouvernés entre les départements ou avec des partenaires
- Fourniture d'informations rapides et fiables pour les équipes de finance, de marketing et de produit
Fonctionnalités clés avec l'intelligence des données
Le composant d'intelligence des données de cette architecture rend la plateforme plus intelligente, plus adaptative et plus facile à utiliser pour tous les profils et toutes les charges de travail. Il applique l'AI et la sensibilité aux métadonnées dans tout le système pour simplifier les expériences et automatiser la prise de décision :
- Interface en langage naturel (Genie) : Comprend le contexte métier et permet aux utilisateurs de poser des questions sur les données en langage simple
- Sensibilité sémantique : Reconnaît les relations entre les tables, les colonnes et les modèles d'utilisation pour suggérer des jointures, des filtres ou des calculs
- Optimisation prédictive : Ajuste en continu les performances des requêtes et l'allocation des ressources de calcul en fonction de l'historique des charges de travail
- Gouvernance unifiée : Identifie, classifie et suit l'utilisation des actifs de données, rendant la découverte plus intuitive et sécurisée
- Fonctionnalité clé : Une plateforme auto-optimisante qui s'adapte à vos données et à vos utilisateurs
- Différenciateur : L'intelligence des données est intégrée à l'ingestion, aux requêtes, à la gouvernance et à la visualisation — elle n'est pas simplement ajoutée après coup
Flux de données avec fonctionnalités clés et différenciateurs
- Sources de données : Les données sont stockées dans une grande variété de systèmes, y compris des applications d'entreprise (par exemple, SAP, Salesforce), des bases de données, des appareils IoT, des journaux d'application et des API externes. Ces sources peuvent produire des données structurées, semi-structurées ou non structurées.
- Ingestion de données : Permet d'importer des données via des tâches batch, la capture de données modifiées (CDC) ou le streaming. Ces pipelines alimentent l'architecture lakehouse en quasi-temps réel ou à intervalles planifiés, selon le système source et le cas d'usage.
- Différenciateur clé : Ingestion unifiée pour toutes les modalités — batch, streaming et CDC — sans nécessiter d'infrastructure ou de pipelines distincts
- Transformation des données, ETL, pipelines déclaratifs : Une fois ingérées, les données sont transformées via l'architecture médaillon et progressivement affinées, passant de données brutes à des données préparées.
- De la zone Raw à la zone Bronze : Données ingérées à partir de systèmes sources externes où les structures de cette couche correspondent aux structures de table du système source « telles quelles », sans transformation ni mise à jour des données
- De la zone Bronze à la zone Silver : Standardiser et nettoyer les données entrantes
- De la zone Silver à la zone Gold : Appliquer la logique métier pour créer des modèles réutilisables
- Faits et dimensions → data marts : Agrégation et préparation des données pour les analyses en aval
- Différenciateur clé : Pipelines déclaratifs de niveau production avec lignage, observabilité et évolution de schéma intégrés
- Données préparées pour les cas d'usage de l'AI : Les données préparées issues des data marts peuvent être utilisées pour entraîner ou appliquer des modèles de machine learning. Ces modèles prennent en charge des cas d'usage tels que la prévision de la demande, la détection d'anomalies et le scoring client.
- Les résultats des modèles sont stockés aux côtés des données d'entrepôt traditionnelles pour un accès facile via SQL ou des tableaux de bord
- Les résultats peuvent être mis à jour selon un calendrier ou faire l'objet d'un scoring en temps réel, selon les besoins
- Différenciateur clé : Colocalisation des charges de travail d'analyse et d'AI sur la même plateforme — aucun mouvement de données requis. Les résultats des modèles sont traités comme des actifs gouvernés natifs et interrogeables.
- Alimentation des outils de reporting BI par requêtes : Databricks Lakehouse prend en charge les requêtes à haute simultanéité et à faible latence grâce au calcul serverless, et se connecte facilement aux outils BI populaires.
- Éditeur de requêtes intégré et historique des requêtes
- Les requêtes renvoient des résultats gouvernés et à jour provenant de data marts ou de sorties de modèles enrichis
- Différenciateur clé : Databricks Lakehouse permet aux outils BI d'interroger directement les données — sans réplication — ce qui réduit la complexité, évite les coûts de licence supplémentaires et abaisse le TCO global. Associé au calcul serverless et à l'optimisation intelligente, il offre des performances de niveau data warehouse avec un minimum de configuration.
- Tableaux de bord : Ils peuvent être créés directement dans Databricks ou dans des outils BI externes comme Power BI ou Tableau. Les utilisateurs peuvent décrire les visuels en langage naturel, et Databricks Assistant générera les graphiques correspondants, qui pourront ensuite être affinés à l'aide d'une interface pointer-cliquer.
- Créer des visualisations à l'aide d'une saisie en langage naturel
- Modifier et explorer les tableaux de bord de manière interactive grâce à des filtres et des analyses détaillées
- Publier et partager en toute sécurité des tableaux de bord dans toute l'organisation, y compris avec des utilisateurs extérieurs à l'espace de travail Databricks
- Différenciateur clé : Offre une expérience low-code et assistée par l'AI pour créer et explorer des tableaux de bord sur des données gouvernées et en temps réel
- Mise à disposition de données organisées : Une fois affinées, les données peuvent être diffusées au-delà des tableaux de bord :
- Partagées avec des applications en aval ou des bases de données opérationnelles pour la prise de décision transactionnelle
- Utilisées dans des notebooks collaboratifs pour l'analyse
- Distribuées via Delta Sharing aux partenaires, équipes ou consommateurs externes avec une gouvernance unifiée
- Requête en langage naturel (NLQ) : Les utilisateurs métier peuvent accéder à des données gouvernées en utilisant le langage naturel. Cette expérience conversationnelle, alimentée par l'AI générative, permet aux équipes de dépasser les tableaux de bord statiques et d'obtenir des informations en temps réel et en libre-service. Le NLQ traduit l'intention de l'utilisateur en SQL en s'appuyant sur la sémantique de l'organisation et les métadonnées de Unity Catalog.
- Prend en charge les questions ad hoc, interactives et en temps réel qui ne sont pas intégrées d'avance dans les tableaux de bord
- S'adapte intelligemment à l'évolution de la terminologie et du contexte métier au fil du temps
- S'appuie sur la gouvernance des données et les contrôles d'accès existants via Unity Catalog
- Fournit l'auditabilité et la traçabilité des requêtes en langage naturel pour la conformité et la transparence
- Différenciateur clé : S'adapte en permanence à l'évolution des concepts métier, fournissant des réponses précises et adaptées au contexte sans nécessiter d'expertise en SQL
- Fonctionnalités de la plateforme : gouvernance, performance, orchestration et stockage ouvert : L'architecture repose sur un ensemble de fonctionnalités natives de la plateforme qui prennent en charge la sécurité, l'optimisation, l'automatisation et l'interopérabilité tout au long du cycle de vie des données. Fonctionnalités clés :
- Gouvernance : Unity Catalog fournit un contrôle d'accès centralisé, le lignage, l'audit et la classification des données pour toutes les charges de travail
- Performance : Le moteur Photon, la mise en cache intelligente et l'optimisation tenant compte des charges de travail permettent d'obtenir des requêtes rapides sans configuration manuelle
- Orchestration : L'orchestration intégrée gère les pipelines de données, les flux de travail AI et les tâches planifiées pour les charges de travail batch et streaming, avec une prise en charge native de la gestion des dépendances et du traitement des erreurs
- Stockage ouvert : Les données sont stockées dans des formats ouverts (Delta Lake, Parquet, Iceberg), ce qui permet l'interopérabilité entre les outils, la portabilité entre les plateformes et la durabilité à long terme sans dépendance vis-à-vis d'un fournisseur
- Surveillance et auditabilité : Visibilité de bout en bout sur les performances des requêtes, l'exécution des pipelines et l'accès des utilisateurs pour un meilleur contrôle et une gestion optimisée des coûts
- Différenciateur clé : Les services au niveau de la plateforme sont intégrés — et non superposés — garantissant que la gouvernance, l'automatisation et les performances sont cohérentes pour l'ensemble des flux de travail de données, des clouds et des équipes
Recommandé

Architecture de référence

Architecture de référence

Architecture par Secteur d'activité