PII 암호화 및 데이터 중복 방지
Fernet 암호화 라이브러리, UDF 및 Databricks 비밀을 사용하여 PII 데이터를 방해하지 않고 보호
작성자: Keyuri Shah , Fred Kimball
Northwestern Mutual의 선임 소프트웨어 엔지니어인 Keyuri Shah와 소프트웨어 엔지니어인 Fred Kimball이 작성한 게스트 게시물입니다.
매일 유출되는 데이터 침해 및 민감한 정보가 포함된 기록의 수가 증가함에 따라 PII(개인 식별 정보)를 보호하는 것은 매우 중요합니다. 다음 희생자가 되지 않고 사용자를 신원 도용 및 사기로부터 보호하기 위해 여러 계층의 데이터 및 정보 보안을 통합해야 합니다.
Databricks 플랫폼을 사용하는 동안 민감한 정보에 대한 액세스를 올바른 사람에게만 허용해야 합니다. Fernet 암호화 라이브러리, 사용자 정의 함수(UDF) 및 Databricks 비밀의 조합을 사용하여 Northwestern Mutual은 PII 정보를 암호화하고 비즈니스상의 필요가 있는 사람만 복호화할 수 있도록 하는 프로세스를 개발했으며, 데이터 판독기에게는 추가 단계가 필요하지 않습니다.
PII 보호의 필요성
오늘날 어떤 양의 고객 데이터든 관리하려면 PII를 보호해야 합니다. 간단한 구성 실수로 인해 수백만 건의 민감한 고객 기록이 도난당한 Capital One 데이터 침해와 같은 사례는 모든 규모의 조직에 큰 위험을 초래합니다. 스토리지 장치 암호화 및 테이블 수준에서의 열 마스킹은 효과적인 보안 조치이지만, 이러한 민감한 데이터에 대한 무단 내부 액세스는 여전히 주요 위협입니다. 따라서 Databricks에서 파일 또는 테이블 액세스 권한이 있는 일반 사용자가 민감한 정보를 검색하는 것을 제한하는 솔루션이 필요합니다.
하지만 비즈니스상의 필요가 있어 민감한 정보를 읽어야 하는 사용자도 그렇게 할 수 있어야 합니다. 각 유형의 사용자가 �테이블을 읽는 방식에 차이가 없기를 바랍니다. 일반 읽기와 복호화된 읽기 모두 동일한 Delta Lake 객체에서 발생하여 데이터 분석 및 보고서 작성을 위한 쿼리 구성을 단순화합니다.
열 수준 암호화 적용 프로세스 구축
이러한 보안 요구 사항을 고려하여 안전하고 방해가 되지 않으며 관리하기 쉬운 프로세스를 만들고자 했습니다. 아래 다이어그램은 이 프로세스에 필요한 구성 요소에 대한 개요를 제공합니다.
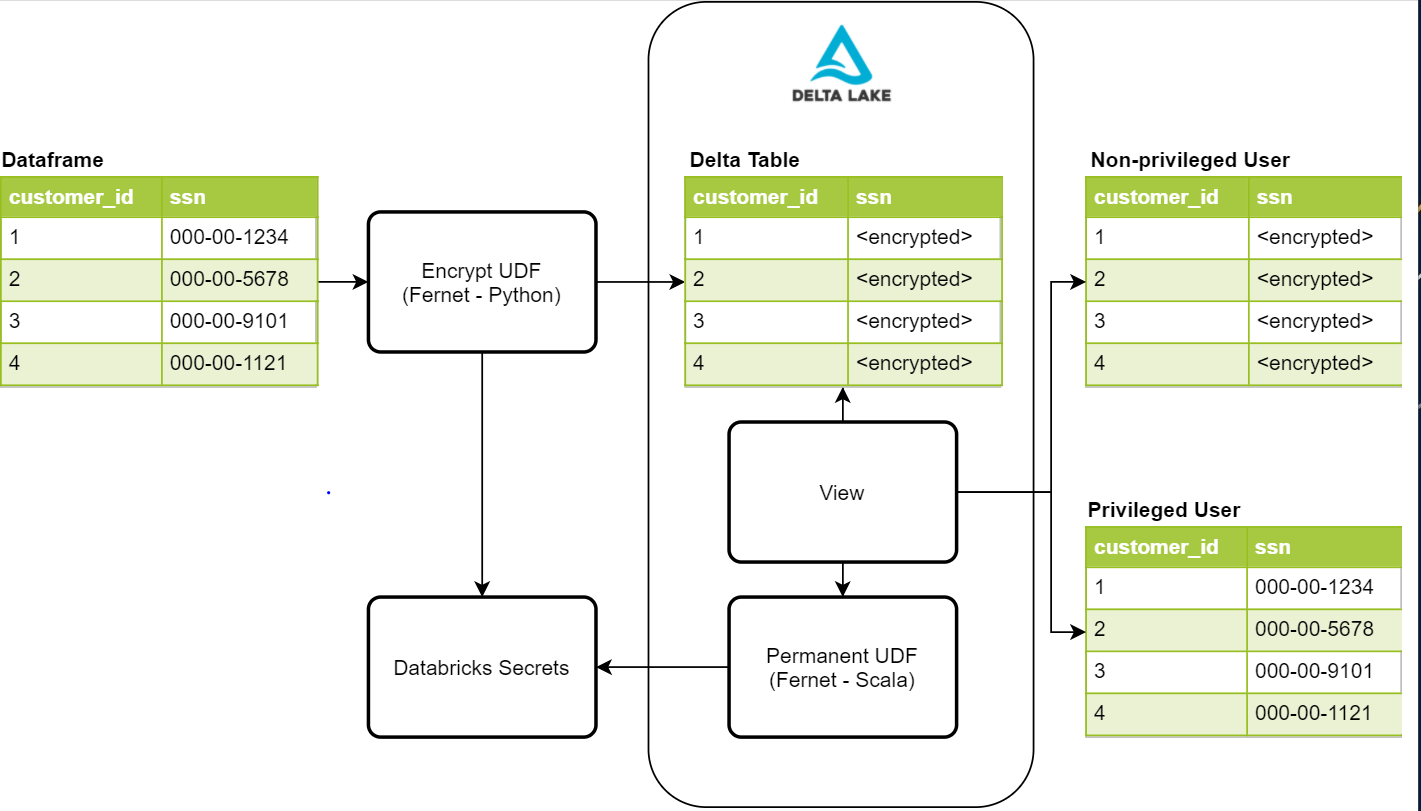
Fernet를 사용한 보호된 PII 작성
이 프로세스의 첫 번째 단계는 데이터를 암호화하여 보호하는 것입니다. 가능한 솔루션 중 하나는 Fernet Python 라이브러리입니다. Fernet은 여러 표준 암호화 기본 요소를 기반으로 구축된 대칭 암호화를 사용합니다. 이 라이브러리는 데이터프레임의 모든 열을 암호화할 수 있도록 하는 암호화 UDF 내에서 사용됩니다. 암호화 키를 저장하기 위해 Databricks 비밀을 사용하며, 액세스 제어를 통해 데이터 수집 프로세스만 액세스할 수 있도록 합니다. 데이터가 Delta Lake 테이블에 기록되면, 주민등록번호, 전화번호, 신용카드 번호 및 기타 식별자와 같은 값을 보유한 PII 열은 권한이 없는 사용자가 읽을 수 없게 됩니다.
사용자 정의 UDF를 사용하여 뷰에서 보호된 데이터 읽기
민감한 데이터가 기록되고 보호되면, 권한 있는 사용자가 민감한 데이터를 읽을 수 있는 방법이 필요합니다. 가장 먼저 해야 할 일은 Databricks에서 실행되는 Hive 인스턴스에 영구 UDF를 추가하는 것입니다. UDF가 영구적이려면 Scala로 작성해야 합니다. 다행히 Fernet에는 복호화된 읽기에 활용할 수 있는 Scala 구현도 있습니다. 이 UDF는 암호화된 쓰기에서 사용한 것과 동일한 비밀에 액세스하여 복호화를 수행하며, 이 경우 클러스터의 Spark 구성에 추가됩니다. 이를 위해서는 권한 있는 사용자와 권한 없는 사용자에 대한 클러스터 액세스 제어를 추가하여 키 액세스를 제어해야 합니다. UDF가 생성되면, 권한 있는 사용자가 복호화된 데이터를 볼 수 있도록 뷰 정의 내에서 사용할 수 있습니다.
현재 단일 데이터 세트에 대해 각각 권한 있는 사용자와 권한 없는 사용자를 위한 두 개의 뷰 객체가 있습니다. 권한 없는 사용자를 위한 뷰에는 UDF가 없으므로 암호화된 값으로 PII 값을 보게 됩니다. 권한 있는 사용자를 위한 다른 뷰에는 UDF가 있으므로 비즈니스상의 필요에 따라 일반 텍스트로 복호화된 값을 볼 수 있습니다. 이러한 뷰에 대한 액세스도 Databricks에서 제공하는 테이블 액세스 제어로 제어됩니다.
가까운 미래에는 동적 뷰 함수라는 새로운 Databricks 기능을 활용하고자 합니다. 이러한 동적 뷰 함수를 사용하면 단일 뷰만 사용하고 Databricks 그룹의 멤버인지 여부에 따라 암호화된 값 또는 복호화된 값을 쉽게 반환할 수 있습니다. 이렇게 하면 Delta Lake에서 생성하는 객체의 양이 줄어들고 테이블 액세스 제어 규칙이 단순화됩니다.
어떤 구현이든 사용자는 뷰에서 읽은 값을 복호화해야 하는지 여부에 대해 걱정할 필요 없이 개발 또는 분석을 수행할 수 있으며, 비즈니스상의 필요가 있는 사용자만 액세스할 수 있습니다.
열 수준 암호화 방식의 장점
요약하자면, 이 프로세스를 사용하는 것의 장점은 다음과 같습니다.
- 기존 Python 또는 Scala 라이브러리를 사용하여 암호화를 수행할 수 있습니다.
- 민감한 PII 데이터는 Delta Lake에 저장될 때 추가적인 보안 계층을 갖습니다.
- 해당 객체에 대한 모든 액세스 수준의 사용자가 동일한 Delta Lake 객체를 사용합니다.
- 분석가는 PII를 읽을 권한이 있는지 여부에 관계없이 방해받지 않습니다.
이것이 어떻게 보일지에 대한 예시로, 다음 노트북이 일부 지침을 제공할 수 있습니다.
추가 리소스:
Fernet 라이브러리
영구 UDF 생성
동적 뷰 함수
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.