신용카드 거래를 사용하는 은행과 핀테크를 위한 초개인화 액셀러레이터
Lakehouse for Financial Services as the strategic platform to accelerate digital transformation in retail banking
작성자: Antoine Amend
넷플릭스와 테슬라가 미디어와 자동차 산업을 혁신했듯이, 많은 핀테크 기업들이 개인화된 서비스, 보안이 강화된 다양한 신용카드, 매끄러운 옴니채널 경험을 통해 ��디지털 활동 인구의 마음을 사로잡으며 금융 서비스 업계를 변화시키고 있습니다. 8년 된 스타트업인 NuBank가 라틴 아메리카에서 가장 가치 있는 은행이 된 성공 사례는 이 회사만의 특별한 경우가 아니며, 280개가 넘는 다른 핀테크 유니콘 기업들도 결제 산업 전체를 뒤흔들고 있습니다. 영국 금융감독청(FCA)의 연구에 따르면 "혁신, 디지털화, 소비자 행동 변화로 인해 대형 은행의 역사적 우위가 약화되기 시작했다"고 언급했습니다. 이에 대응하여 JP Morgan Chase와 같은 많은 전통 금융 서비스 기관은 최근 클라우드, 데이터 및 인공지능(AI) 기술을 기반으로 핀테크 기업과 경쟁하기 위한 상당한 전략적 투자를 발표했습니다.
고객 개인화에 필요한 데이터량, AI 운영의 복잡성(개념 증명에서 엔터프라이즈 규모의 데이터 파이프라인까지), 클라우드 인프라에서의 엄격한 데이터 및 개인정보 보호 규정 등을 고려할 때, 금융 레이크하우스는 많은 혁신 기업과 기존 기업 모두가 디지털 혁신을 가속화하고 수백만 고객에게 개인화된 인사이트와 향상된 금융 경험을 제공하기 위한 전략적 플랫폼으로 부상하고 있습니다(HSBC의 AI 기반 모바일뱅킹 혁신 사례를 참조하세요).
이전 솔루션 액셀러레이터에서는 신용카드 거래에서 브랜드와 가맹점을 식별하는 방법을 보여주었습니다. 새로운 솔루션 액셀러레이터에서는 이를 활용하여 소비자에 대한 전체적인 그림을 파악하고, 기존의 인구통계, 소득, 상품 및 서비스(고객이 누구인지) 정보 외에도 거래 행동 및 쇼핑 선호도(고객이 어떻게 은행을 이용하는지)까지 확장하는 최신 초개인화 데이터 자산 전략을 구축했습니다. 이러한 데이터 자산은 온라인 뱅킹 애플리케이션의 로열티 프로그램, 핵심 뱅킹 플랫폼의 사기 방지, '지금 구매 후 나중에 지불'(BNPL) 이니셔티브의 신용 리스크 등 다양한 다운스트림 사용 사례에도 동일하게 적용될 수 있습니다.
트랜잭션 컨텍스트 (Transactional context)
모든 세분화 사용 사례에 대한 일반적인 접근 방식은 단순한 클러스터링 모델이지만, 기존의 기법은 제한적입니다. 또한 원래의 데이터를 변환할 때 예상치 못한 결과를 도출하는 더 광범위한 기법을 사용할 수 있습니다. 이 솔루션에서는 원래의 카드 거래 데이터를 그래프 패러다임으로 변환하고 자연어 처리(NLP) 기술을 활용합니다.
단어의 의미가 주변 문맥에 의해 정의되는 NLP 기술과 유사하게, 판매자의 카테고리는 고객 기반과 소비자가 지지하는 다른 브랜드를 통해 학습할 수 있습니다. 이러한 맥락을 구축하기 위해 고객이 한 매장에서 다른 매장으로 이동하는 시뮬레이션을 통해 그래프 구조를 탐색하는 '쇼핑 여행'을 생성합니다. 목표는 네트워크에서 고객이 전달하는 컨텍스트 정보를 수학적으로 표현한 '임베딩'을 학습하는 것입니다. 이 예에서, 맥락적으로 서로 가까운 두 판매자는 수학적으로 서로 가까운 큰 벡터에 임베딩됩니다. 더 나아가, 동일한 쇼핑 행동을 보이는 두 고객은 수학적으로 서로 가까워지므로 보다 진보된 고객 세분화 전략을 위한 기반을 마련할 수 있습니다.
판매자 임베딩
Word2Vec 임베딩의 신경망 학습을 보다 효율적으로 하기 위해 Google의 Tomas Mikolov 등이 개발한 것으로, 이후 사전 학습된 단어 임베딩 알고리즘 개발을 위한 사실상의 표준이 되었습니다. 이 솔루션에서는 앞서 정의한 쇼핑 여행에 대해 학습하는 Apache Spark™ ML API의 기본 wordVec 모델을 사용합니다.
우리의 접근 방식을 빠르게 검증하는 가장 확실한 방법은 결과를 주시하고 도메인 전문 지식을 적용하는 것입니다. "폴 스미스"와 같은 브랜드의 예에서, 우리 모델은 폴 스미스의 가장 가까운 경쟁자가 "휴고 보스", "랄프 로렌" 또는 "타미 힐피거"라는 것을 찾을 수 있습니다.
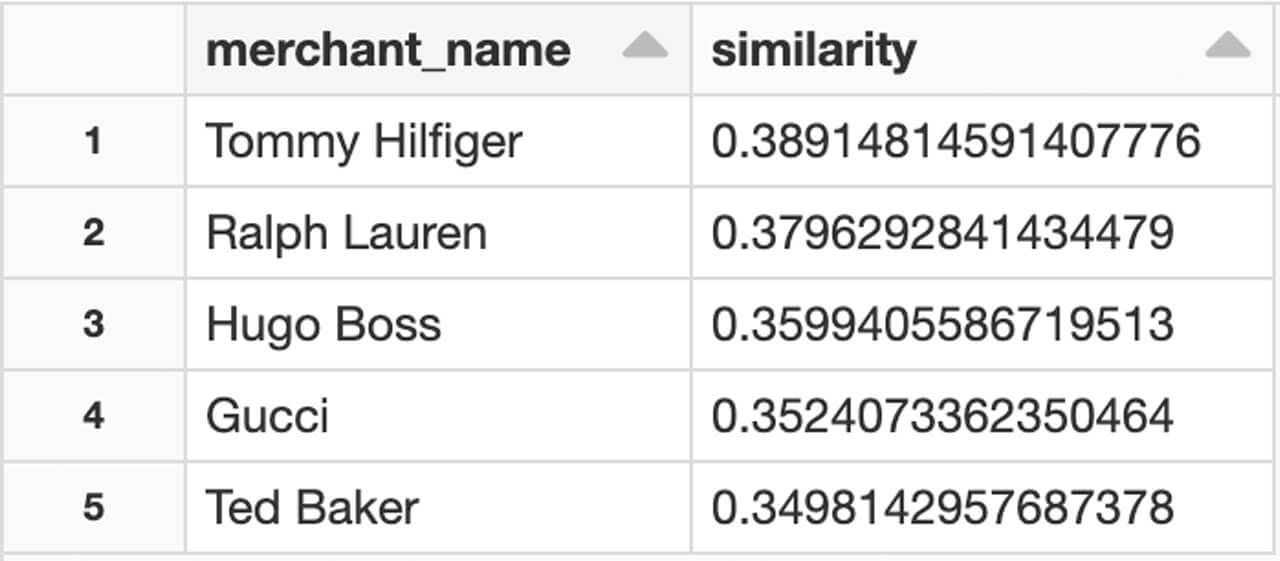
단순히 같은 카테고리(예: 패션 업계) 내의 브랜드를 감지한 것이 아니라, 비슷한 가격대의 브랜드를 감지했습니다. 고객 행동 데이터를 사용하여 다양한 업종을 분류�할 수 있었을 뿐만 아니라, 고객이 구매하는 상품의 품질에 따라 고객 세분화가 이루어질 수도 있었습니다. 이는 Bruss 등의 연구 결과를 뒷받침합니다.
판매자 클러스터링
예비 결과에는 문제가 있었지만, 다른 판매자 그룹과 다소 유사한 판매자 그룹이 있을 수 있으며, 이를 추가로 식별하고 싶을 수도 있습니다. 이러한 중요한 판매자/브랜드 그룹을 찾는 가장 쉬운 방법은 임베디드 벡터 공간을 3D 플롯으로 시각화하는 것입니다. 이를 위해 주성분 분석(PCA)과 같은 머신러닝 기법을 적용하여 임베디드 벡터를 3차원으로 축소할 수 있습니다.
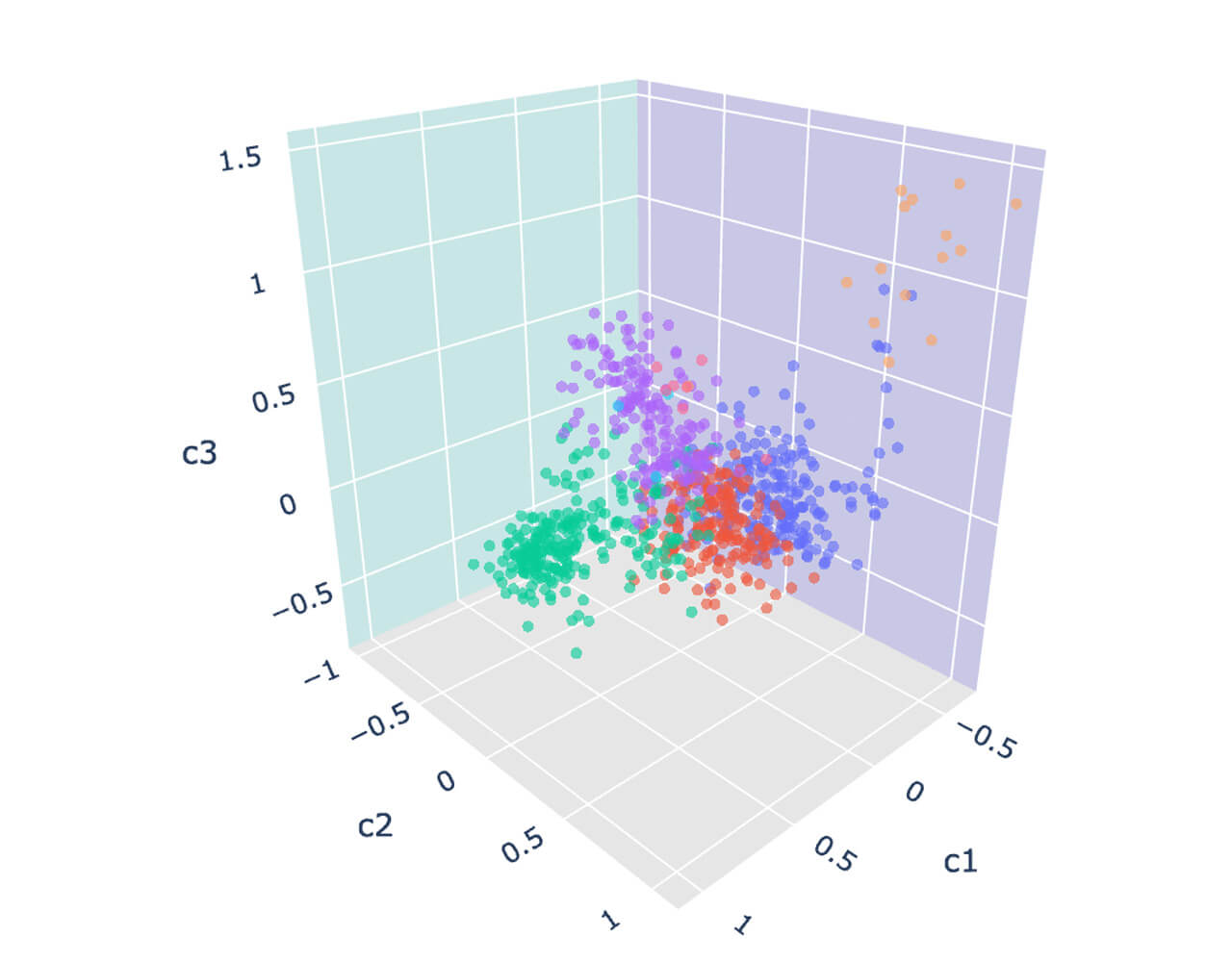
단순한 플롯을 사용하여 뚜렷한 판매자 그룹을 식별할 수 있습니다. 이 판매자들은 서로 다른 사업 분야를 가지고 있고 표면적으로는 서로 다른 것처럼 보일 수 있지만, 모두 비슷한 고객층을 유치한다는 한 가지 공통점이 있습니다. 클러스터링 모델(KMeans)을 통해 이 가설을 더 잘 확인할 수 있습니다.
트랜잭션 흔적
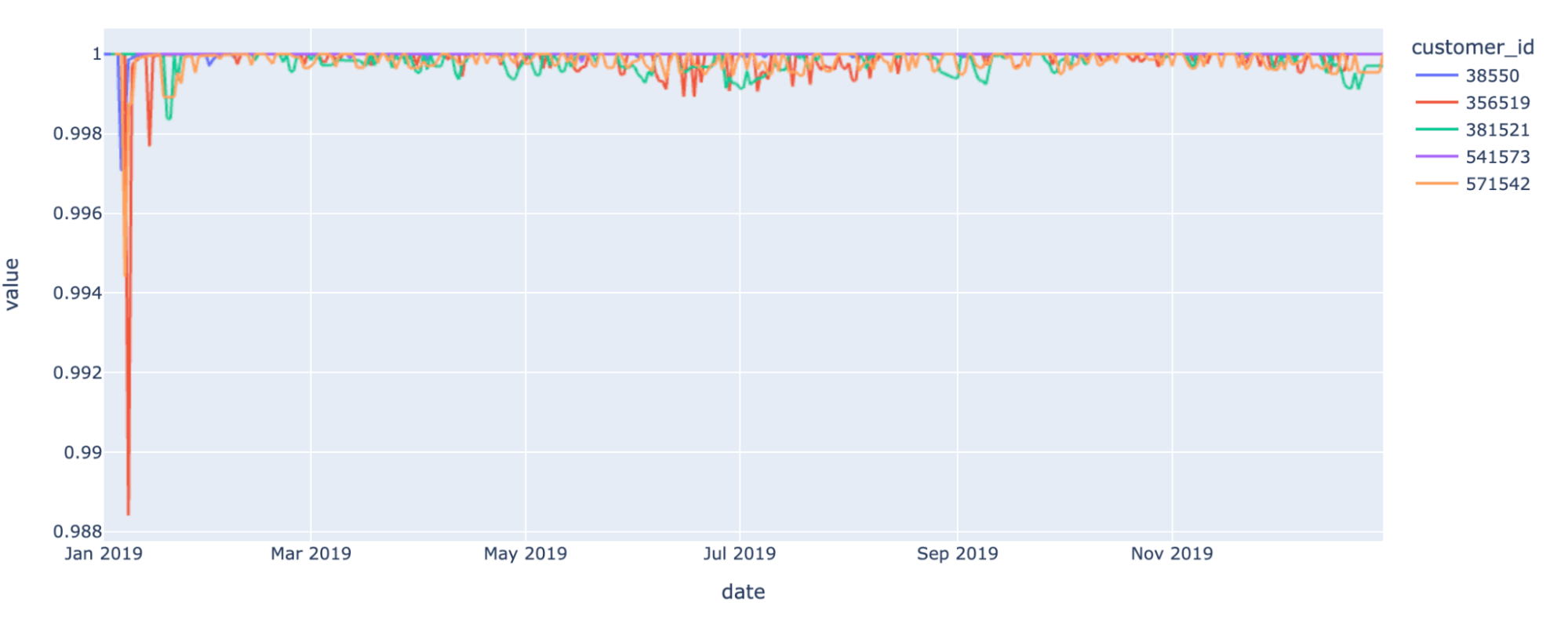
word2vec 모델의 특이한 특징 중 하나는 높은 예측값을 유지하면서도 충분히 큰 벡터를 집계할 수 있다는 것입니다. 다시 말해, 문서의 중요도는 각 단어 구성 요소의 벡터를 평균화하여 학습할 수 있습니다(Mikolov 등의 백서 참조). 마찬가지로, 고객이 선호하는 각 브랜드의 벡터를 집계하여 고객의 소비 선호도를 학습할 수 있습니다. 명품 브랜드, 고급 자동차, 고급 주류에 대한 취향이 비슷한 두 고객�은 이론적으로 서로 가깝기 때문에 같은 세그먼트에 속할 수 있습니다.
이러한 통합된 관점은 각 최종 소비자마다 고유한 거래 패턴을 생성한다는 점을 언급할 가치가 있습니다. 두 개의 패턴이 유사한 특성(동일한 쇼핑 선호도)을 공유할 수 있지만, 이러한 고유한 특성을 사용하여 시간이 지남에 따라 개별 고객 행동을 추적할 수 있습니다.
고객 특성이 이전 관찰 결과와 크게 다를 경우, 이는 사기 행위의 징후일 수 있습니다(예: 도박 업체에 대한 갑작스러운 관심). 시간이 지남에 따라 특성이 달라지는 경우, 이는 인생의 주요 사건(예: 신생아 출산)을 나타낼 수 있습니다. 이러한 접근 방식은 소매 금융에서 고객 맞춤화를 추진하는 데 핵심적인 역할을 합니다. 실시간 데이터에 대한 고객 선호도를 추적하는 기능은 은행이 긍정적이든 부정적이든 다양한 생활 이벤트에 대해 맞춤형 마케팅과 제안을 제공하는 데 도움이 될 것입니다.
고객 세분화
고객 행동 분석에 큰 예측 가치를 제공하는 몇 가지 신호를 생성할 수 있었지만, 실제 세분화 문제를 해결하지는 못했습니다. 세분화, 이탈 방지 또는 고객 생애 가치 등 고객 360 사용 사례와 관련하여 더 발전된 기술을 보유한 리테일 업계의 사례를 참고하여, 업계 최고의 리테일 조직에서 사용하는 다양한 세분화 기술을 안내하는 리테일용 레이크하우스 솔루션 액셀러레이터를 사용할 수 있습니다.
��리테일 업계의 모범 사례에 따라 전체 고객층을 서로 다른 쇼핑 특성을 보이는 5가지 그룹으로 세분화할 수 있었습니다.
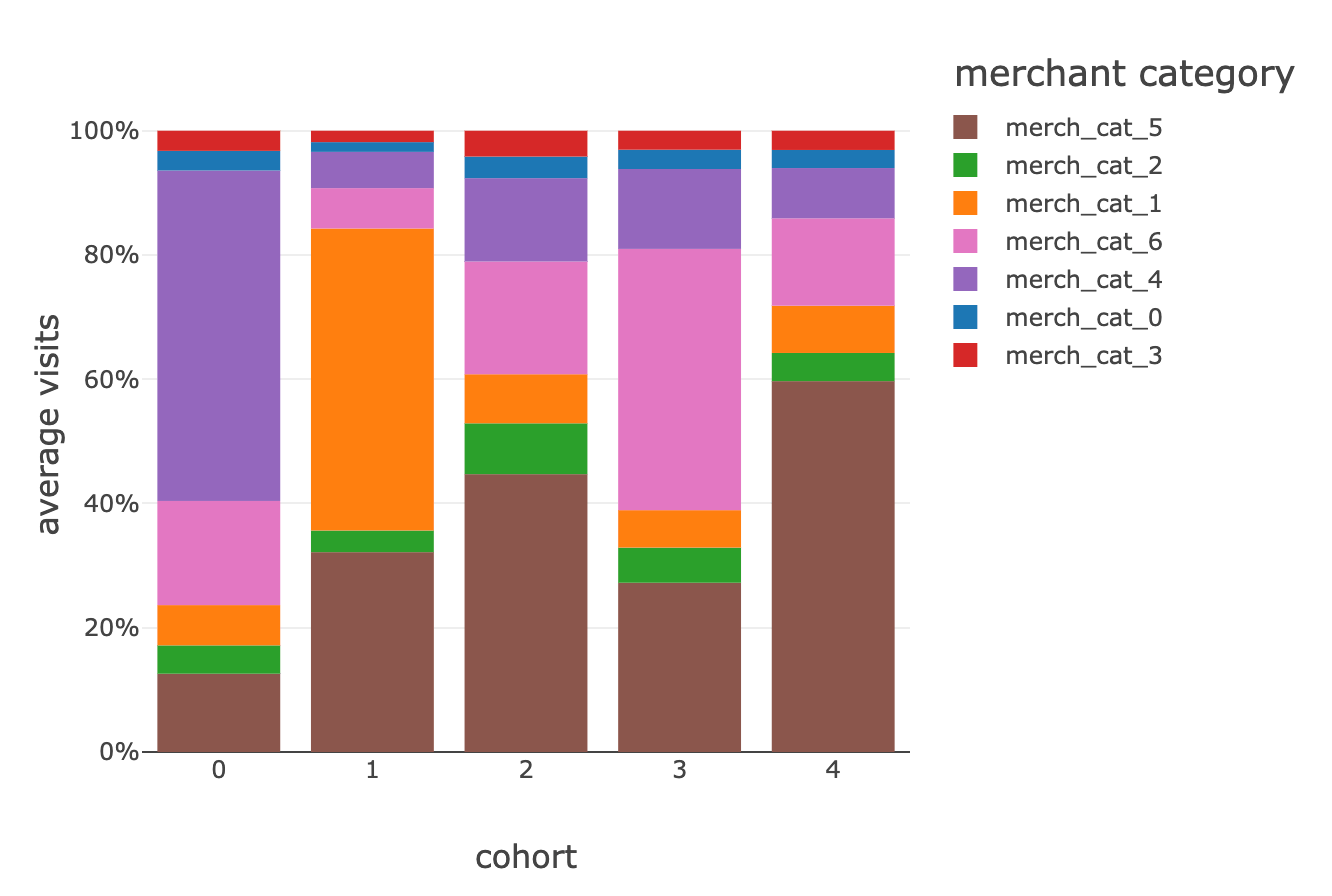
0번 클러스터는 도박 활동(위 그래프에서 판매자 카테고리 4)에 편중되어 있는 반면, 다른 그룹은 온라인 비즈니스와 구독 기반 서비스(판매자 카테고리 6)에 더 집중되어 있어 젊은 세대의 고객을 나타낼 수 있습니다. 이러한 행동 중심 세그먼트와 신용 결정, 차선책, 개인화된 서비스, 고객 만족도, 채권 추심 또는 마케팅 분석에 미치는 영향을 더 잘 이해하기 위해 고객에 대해 이미 알고 있는 추가 데이터 포인트(기존 세그먼트, 상품 및 서비스, 평균 소득, 인구통계 등)로 이 관점을 보완해 주시기 바랍니다.
마무리하며
이 솔루션 액셀러레이터에서는 소매 은행의 고객 세분화를 위해 카드 거래 데이터에 자연어 처리(NLP) 기술을 성공적으로 적용했습니다. 또한 그래프 분석, 행렬 계산, NLP, 클러스터링 기술을 모두 하나의 플랫폼에 결합하고 보안과 확장성을 갖춰야 하는 이 과제를 해결하기 위해 금융 서비스용 데이터레이크하우스의 적합성을 입증했습니다. SQL을 통해 쉽게 해결할 수 있는 기존의 세분화 방식에 비해, 데이터와 AI를 활용한 세분화 방식은 고객에 대한 보다 완전한 정보를 제공하며 대규모로 실시간 처리가 가능합니다.
기존 모델과 데이터를 활용하여 가능한 것의 표면만 긁어모았지만, 고객의 소비 패턴이 인구통계학적 요인보다 더 효과적으로 개인화를 추진할 수 있음을 증명했습니다. 이를 통해 교차 판매/업셀, 가격 책정/타겟팅, 고객 충성도 및 사기 탐지 전략 등 다양한 새로운 기회를 창출할 수 있습니다.
무엇보다도 이 기술을 통해 은행 계좌가 없거나 신용 기록이 없는 소외된 소비자에 대한 정보를 활용하여 학습할 수 있었습니다. 세계경제포럼에 따르면 은행 계좌가 없는 성인 인구가 전 세계적으로 17억 명에 달하고, 미국 연방준비제도이사회에 따르면 2018년 미국에서만 5500만 명이 은행 서비스를 이용하지 못하고 있는 상황에서 이러한 접근 방식은 소매 금융의 고객 중심적이고 포용적인 미래를 향한 길을 열어줄 수 있습니다.
지금 바로 데이터브릭스에서 액셀러레이터 노트북을 사용해 귀사의 고객 360 데이터 자산 전략을 테스트하고, 비슷한 사용 사례를 가진 고객을 어떻게 지원했는지 자세히 알아보려면 데이터브릭스에 문의하세요.
Translated by HaUn Kim - Original Blog Post
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.