Python Data Source API를 이용한 의료 영상 데이터 처리 속도 7배 향상
산업 표준 라이브러리인 pydicom과 zipfile��을 Python Data Source API와 함께 사용하여 DICOM 데이터 수집 파이프라인을 가속화하세요
작성자: 더글라스 무어 , Allison Wang
- 헬스케어 및 생명 과학 조직들은 DICOM 이미징, 실험실 기기, 유전체 출력, 생물 의학 파일과 같은 구조화된 데이터를 넘어서 다양한 데이터 형식을 처리하며, 이는 종종 압축된 형식으로 저장되어 전통적인 플랫폼에 대한 도전을 제기합니다.
- Python Data Source API는 헬스케어 Python 라이브러리를 Spark에 통합하여 압축 파일의 복잡한 ETL 파이프라인을 단계별로 처리하는 대신 한 단계 처리를 허용합니다.
- Python Data Source API를 사용하면 메모리 내 작업과 I/O 작업을 최소화하여 임시 파일을 제거함으로써 7배 빠른 처리를 달성합니다 (57배의 절약).
헬스케어 데이터 도전: 표준 형식을 넘어서
의료 및 생명 과학 조직은 전통적인 구조화된 데이터를 훨씬 넘어서는 다양한 데이터 형식을 다룹니다. DICOM과 같은 의료 영상 표준, 독점적인 실험실 기기, 유전체 시퀀싱 출력, 특수한 생물의학 파일 형식은 전통적인 데이터 플랫폼에 중대한 도전을 제시합니다. Apache Spark™는 대략 10가지 표준 데이터 소스 유형에 대해 강력한 지원을 제공하는 반면, 의료 분야는 수백 가지의 특수한 형식과 프로토콜에 대한 접근이 필요합니다.
CT, X-레이, PET, 초음파, MRI 등 다양한 방식의 의료 이미지는 정형외과부터 종양학, 산부인과에 이르기까지 건강관리의 많은 진단 및 치료 과정에서 필수적입니다. 이러한 의료 이미지가 압축되거나, 보관되거나, 특수한 파이썬 라이브러리가 필요한 독점 형식으로 저장될 때 문제는 더욱 복잡해집니다.
DICOM 파일에는 풍부한 메타데이터가 포함된 헤더 섹션이 있습니다. DICOM 태그에는 4200개 이상의 표준이 정의되어 있습니다. 일부 고객은 사용자 정의 메타데이터 태그를 구현합니다. “zipdcm” 데이터 소스는 이러한 메타데이터 태그의 추출 속도를 높이기 위해 구축되었습니다.
문제점: 의료 이미지 처리 속도가 ��느림
헬스케어 조직들은 종종 의료 이미지를 수천 개의 DICOM 파일이 포함된 압축 ZIP 아카이브에 저장합니다. 이러한 아카이브를 대규모로 처리하는 것은 일반적으로 여러 단계를 필요로 합니다:
- ZIP 파일을 임시 저장소로 추출하세요
- pydicom과 같은 Python 라이브러리를 사용하여 개별 DICOM 파일을 처리합니다
- Delta Lake에 결과를 로드하여 분석하십시오
Databricks는 수백 가지 이미지 형식을 대규모로 쉽게 통합할 수 있게 하는 솔루션 가속기, dbx.pixels를 출시했습니다. 그러나 디스크 I/O 작업과 임시 파일 처리로 인해 프로세스가 여전히 느릴 수 있습니다.
해결책: Python Data Source API
새로운 Python Data Source API 는 건강 관리 특화 Python 라이브러리를 Spark의 분산 처리 프레임워크에 직접 통합함으로써 이 문제를 해결합니다. 먼저 파일을 압축 해제한 다음 사용자 정의 함수 (UDFs)로 처리하는 복잡한 ETL 파이프라인을 구축하는 대신, 압축된 의료 이미지를 한 단계에서 처리할 수 있습니다.
Python Data Source API를 사용하여 ZIP 파일 추출과 DICOM 처리를 결합한 사용자 정의 데이터 소스는 전통적인 접근 방식에 비해 7배 빠른 처리 를 보여줍니다.
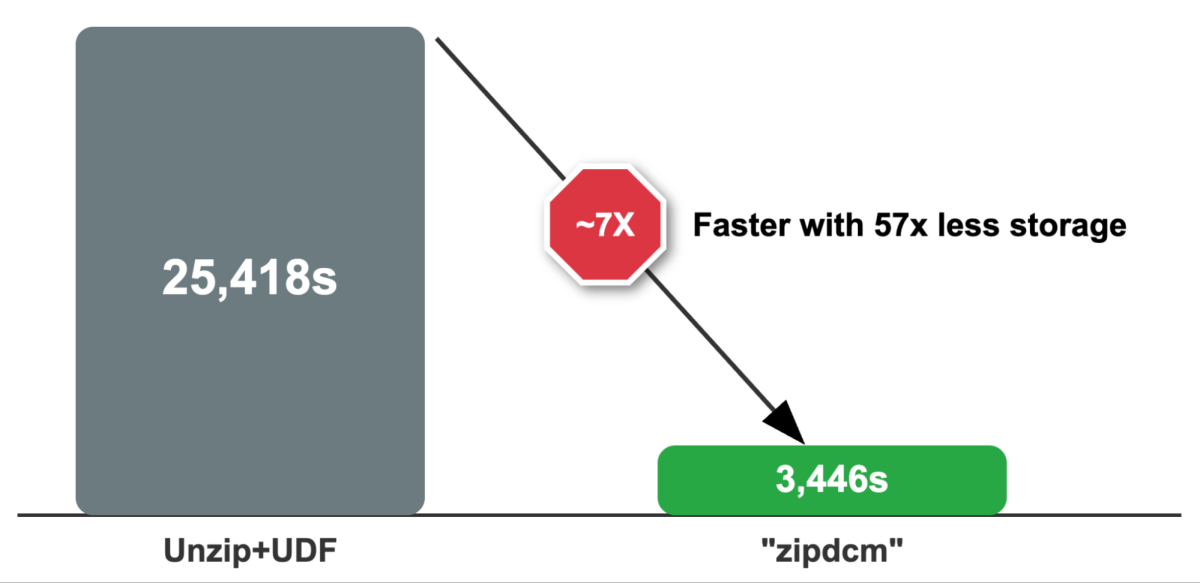
”zipdcm” 리더는 1,416개의 zipfile 아카이브를 처리하였고, 이는 총 107,000개 이상의 DICOM 파일을 포함하고 있으며, DICOM 파일 당 2.43초의 코어 시간이 소요되었습니다. 독립적인 테스터들은 10배 빠른 성능을 보고했습니다. 사용된 클러스터는 각각 8개의 v-cores를 가진 두 개의 작업 노드를 가지고 있었습니다. ”zipdcm” 리더를 실행하는 데 걸린 실제 시간은 단 3.5분이었습니다.
소스 데이터를 압축된 상태로 두고, 소스 zip 아카이브를 확장하지 않음으로써, 우리는 놀라운 (4TB 압축 해제 vs 70GB 압축) 57배 낮은 클라우드 저장 비용을 실현했습니다.
Zipped DICOM 데이터 소스 구현
여기에는 github에서 찾을 수 있는 DICOM 이미지가 포함된 ZIP 파일을 처리하는 사용자 정의 데이터 소스를 구축하는 방법이 있습니다.
Zip 파일에서 DICOM 파일을 읽는 핵심 (원본 소스):
이 루프를 변경하여 zip 아카이브 내부에 중첩된 다른 유형의 파일을 처리하십시오, zip_fp 는 zip 아카이브 내부의 파일 핸들입니다. 위의 코드 스니펫을 사용하면 개별 zip 아카이브 멤버가 개별적으로 어떻게 처리되는지 확인할 수 있습니다.
이 코드 설계의 몇 가지 중요한 측면:
- DICOM 메타데이터는
yield를 통해 반환되�며, 이는 메타데이터 전체를 메모리에 축적하지 않기 때문에 메모리 효율적인 기법입니다. 단일 DICOM 파일의 메타데이터는 몇 킬로바이트에 불과합니다. - 이 데이터 소스의 메모리 사용량을 더욱 줄이기 위해 픽셀 데이터를 버립니다.
추가적인 수정을 통해 partitions() 메소드 를 사용하여 동일한 zipfile에서 여러 Spark 작업을 수행할 수 있습니다. DICOM의 경우, 일반적으로 zip 아카이브는 3D 스캔에서 개별 슬라이스 또는 프레임을 하나의 파일에 모두 보관하는 데 사용됩니다.
전반적으로, 고수준에서, <name_of_data_source>) 아래의 코드 스니펫에서 보여지는 것처럼:
데이터 폴더가 어떻게 보이는지 (데이터 소스는 벗겨진 및 압축된 dcm 파일을 읽을 수 있습니다):
왜 7배 빠른가요?
Python Data Source API를 사용하여 사용자 정의 데이터 소스를 구현함으로써 7배 빠른 개선에 기여하는 여러 요인이 있습니다. 다음을 포함합니다:
- 임시 파일 없음: 전통적인 방법은 압축 해제된 DICOM 파일을 디스크에 씁니다. 사용자 정의 데이터 소스는 메모리에서 모든 것을 처리합니다.
- 열어야 하는 파일 수 감소: 우리의 데이터셋 [DOI: 10.7937/cf2p-aw56]1 에서 The Cancer Imaging Archive (TCIA)에서, 우리는 107,000개의 개별 DICOM 및 라이선스 텍스트 파일을 포함하는 1,412개의 zip 파일을 찾았습니다. 이는 열고 처리해야 하는 파일 수가 100배 증가한 것입니다.
- 부분 읽기: 우리의 DICOM 메타데이터 zipdcm 데이터 소스는 더 큰 이미지 데이터 관련 태그
"60003000,7FE00010,00283010,00283006")를 버립니다 - 저장소와의 IO 감소: 이전에는 압축 해제를 통해 총 4TB의 저장소에 107,000개의 파일을 작성해야 했습니다. TCIA에서 다운로드한 압축 데이터는 단지 71 GB였습니다.
zipdcm리더를 사용하면 210,000개 이상의 개별 파일 IO를 절약할 수 있습니다. - 파티션 인식 병렬성: 반복자가 최상위 ZIP과 각 아카이브 내부의 멤버를 모두 노출하기 때문에, 데이터 소스는 단일 ZIP 파일에 대해 여러 논리적 파티션을 생성할 수 있습니다. 따라서 Spark는 아카이브를 공유 디스크에 먼저 풀지 않고도 작업 부하를 많은 실행기 코어에 분산시킵니다.
이러한 최적화를 통합하면, 디스크와 네트워크 I/O의 병목 현상이 순수한 CPU 파싱으로 이동하며, 참조 데이터셋에서 종단간 런타임을 7배 줄이면서 메모리 사용량을 예측 가능하고 제한된 상태로 유지합니다.
의료 영상 이상: 헬스케어 Python 생태계
Python Data Source API는 건강 관리 및 생명 과학 Python 패키지의 풍부한 생태계에 접근을 엽니다:
- 의료 영상: pydicom, SimpleITK, scikit-image는 다양한 의료 영상 형식을 처리합니다
- 유전체학: BioPython, pysam, genomics-python은 유전체 시퀀싱 데이터를 처리합니다
- 실험실 데이터: 플로우 사이토메트리, 질량 분광법, 임상 실험실 기기를 위한 전문 파서
- 제약: 화학 정보학과 약물 발견 워크플로우를 위한 RDKit
- 임상 데이터: 의료 상호 운용성 표준을 위한 HL7 처리 라이브러리
이러한 각 도메인에는 이제 확장 가능한 Spark 파이프라인에 통합될 수 있는 성숙하고 실전에서 검증된 Python 라이브러리가 있습니다. Python의 헬스케어 데이터 과학에서의 우세가 마침내 생산 규모의 데이터 엔지니어링으로 번역됩니다.
시작하기
이 블로그 게시물은 Python Data Source API와 Apache Spark를 결합하여 의료 이미지 취득을 크게 향상시키는 방법에 대해 논의합니다. DICOM 파일 인덱싱 및 해싱에서 7배 가속화를 강조하며, 4분 이내에 100,000개 이상의 DICOM 파일을 처리하고 저장소를 57배 줄입니다. 방사선학 이미지 분석 시장은 연간 400억 달러 이상으로 평가되며, 이러한 성능 향상은 워크플로우의 자동화를 가속화하면서 비용을 낮추는 기회를 제공합니다. 저자들은 그들의 연구에서 사용된 벤치마크 데이터셋의 제작자에게 감사의 말을 전합니다.
Rutherford, M. W., Nolan, T., Pei, L., Wagner, U., Pan, Q., Farmer, P., Smith, K., Kopchick, B., Laura Opsahl-Ong, Sutton, G., Clunie, D. A., Farahani, K., & Prior, F. (2025). Data in Support of the MIDI-B Challenge (MIDI-B-Synthetic-Validation, MIDI-B-Curated-Validation, MIDI-B-Synthetic-Test, MIDI-B-Curated-Test) (Version 1) [Dataset]. The Cancer Imaging Archive. https://doi.org/10.7937/CF2P-AW56
제공된 샘플 데이터와 함께 데이터 소스 (“fake”, “zipcsv” 및 “zipdcm”)를 시도해 보세요, 모두 여기에서 찾을 수 있습니다: https://github.com/databricks-industry-solutions/python-data-sources
Databricks 계정 팀에 연락하여 사용 사례를 공유하고 분석 사용 사례를 위한 좋아하는 데이터 소스의 수집을 확장하는 방법에 대해 전략을 수립하세요.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.