Databricks에서 PyTorch Lightning(파이토치 라이트닝)으로 딥 러닝 가속화
PyTorch Lightning은 PyTorch 코드를 간소화�하고 딥 러닝 워크로드를
부트스트랩할 수 있는 좋은 방법입니다. 그러나 레이크하우스의 모든
데이터를 사용하여 적시에 결과를 얻기 위해 워크로드를 확장하는 것은
그 자체로 문제가 있습니다. 이 기사에서는 이를 달성할 수 있는 방법과
Horovod를 사용하여 코드를 효율적으로 확장하는 방법을 설명합니다.
소개
점점 더 많은 기업들이 고급 머신 러닝 애플리케이션을 가속화하기 위해
딥 러닝으로 전환하고 있습니다. 예를 들어, 컴퓨터 비전 기술은 오늘날
제조를 위한 결함 검사를 개선하는 데 사용됩니다.
자연어 처리는 챗봇으로 비즈니스 프로세스를 강화하는데 활용되며
신경망 기반 추천 시스템은 고객 결과를 개선하는 데 사용됩니다.
딥 러닝 모델을 훈련하는 것은 잘 최적화된 코드를 사용하더라도
느린 프로세스이기 때문에 Data Science 팀이 Experiment를
빠르게 반복하고 결과를 제공하는 능력이 제한됩니다.
따라서 이를 확장하기 위해 compute 용량을
가장 잘 활용하는 방법을 아는 것이 중요합니다.
이 기사에서는 먼저 코드 재사용을 극대화하기 위해 코드베이스를
구조화한 다음 이를 작은 단일 노드 인스턴��스에서
전체 GPU clusters로 확장하는 방법을 보여줍니다.
또한 이 모든 것을 MLflow와 통합하여 전체
Experiment 추적 및 모델 로깅을 제공합니다.
1부 - 데이터 로드 및
PyTorch Lightning (파이토치 라이트닝) 채택
먼저 대상 아키텍처부터 시작하겠습니다.
clusters 설정
딥러닝을 확장할 때는 값비싼 GPU 리소스를 효율적으로 활용하기 위해
소규모로 시작하여 Experiment 점진적으로 확장하는 것이 중요합니다.
코드 복잡성을 줄이기 위해 여러 노드로 확장하기 전에 단일 노드 내의
여러 GPU에서 실행되도록 코드를 확장하십시오.
Databricks는 바로 이 사용 패턴을 지원하기 위해
단일 노드 clusters를 지원합니다.
참조
: Azure 단일 노드 clusters
: AWS 단일 노드 clusters
: GCP 단일 노드 clusters
인스턴스 선택 측면에서 Nvidia T4 GPU는 비용 효율적인
인스턴스 유형을 제공합니다. AWS에서는 G4 인스턴스에서
사용할 수 있습니다. Azure에서는 NCasT4_v3 인스턴스에서
사용할 수 있습니다. GCP에서는 A2 인스턴스로 사용할 수 있습니다.
노트북을 계속 진행하려면 RAM이 64GB 이상인 인스턴스 유형이 필요합니다.
모델링 프로세스는 메모리를 많이 사용하며 인스턴스가 작을수록 RAM이
부족하여 다음 오류가 발생할 수 있습니다.
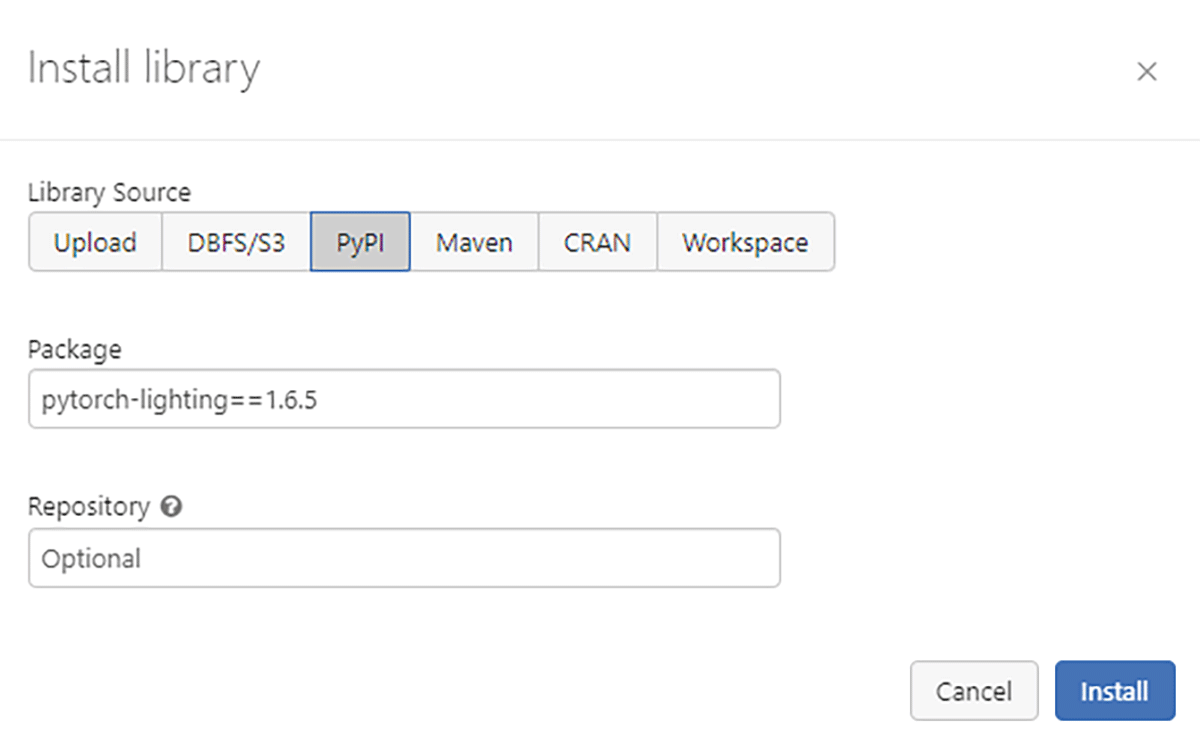
코드는 Databricks Machine Learning Runtimes 10.4 ML LTS 및
11.1 ML DBR 10.4 ML LTS에서만 빌드 및 테스트되었으며
PyTorch-lightning은 최대 1.6.5가 지원됩니다.
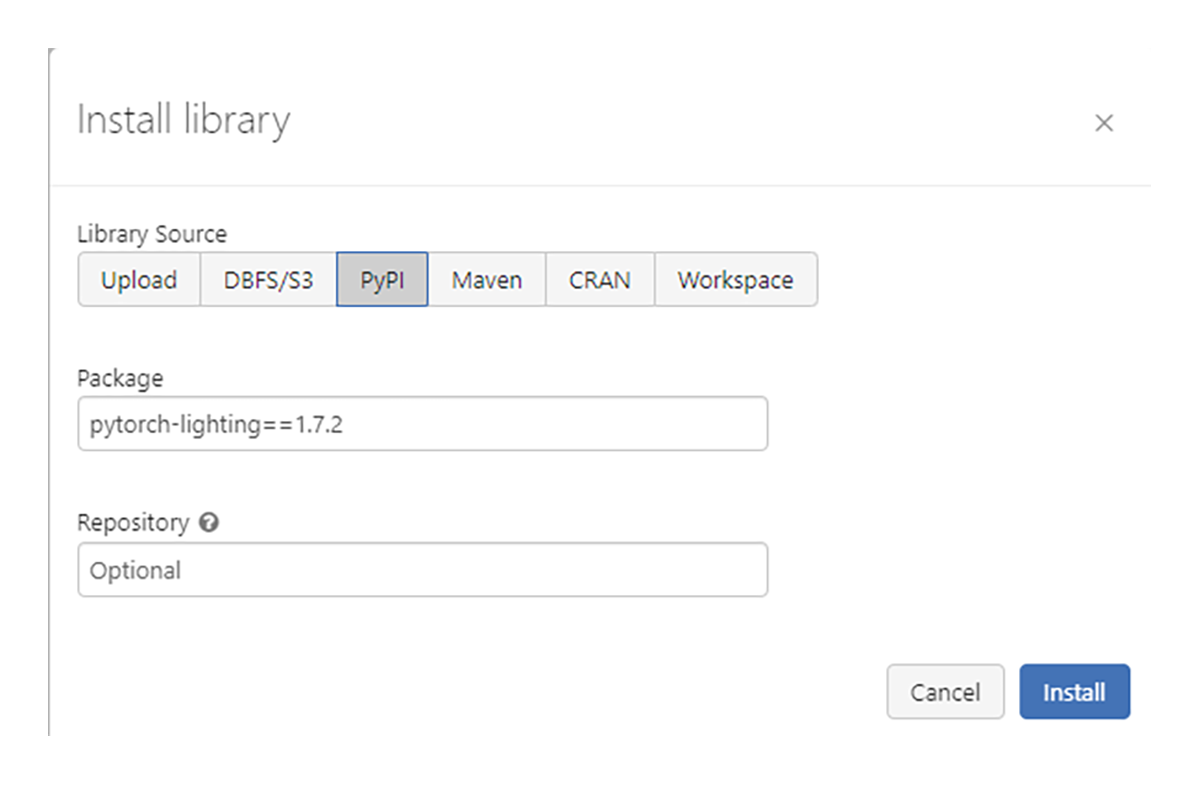
DBR 11.1 ML에서 PyTorch-lightning 1.7.2가 테스트되었습니다.
우리는 워크 스페이스 수준의 라이브러리로 라이브러리를 설치했습니다.
드라이버 노드의 활성 노트북에 대해서만 라이브러리를 설치하는 것과
%pip 달리 워크스페이스 라이브러리는 나중에 분산 학습에 필요한
모든 노드에 설치됩니다.
DBR 10.4 LTS ML 구성
DBR 11.1 ML 구성
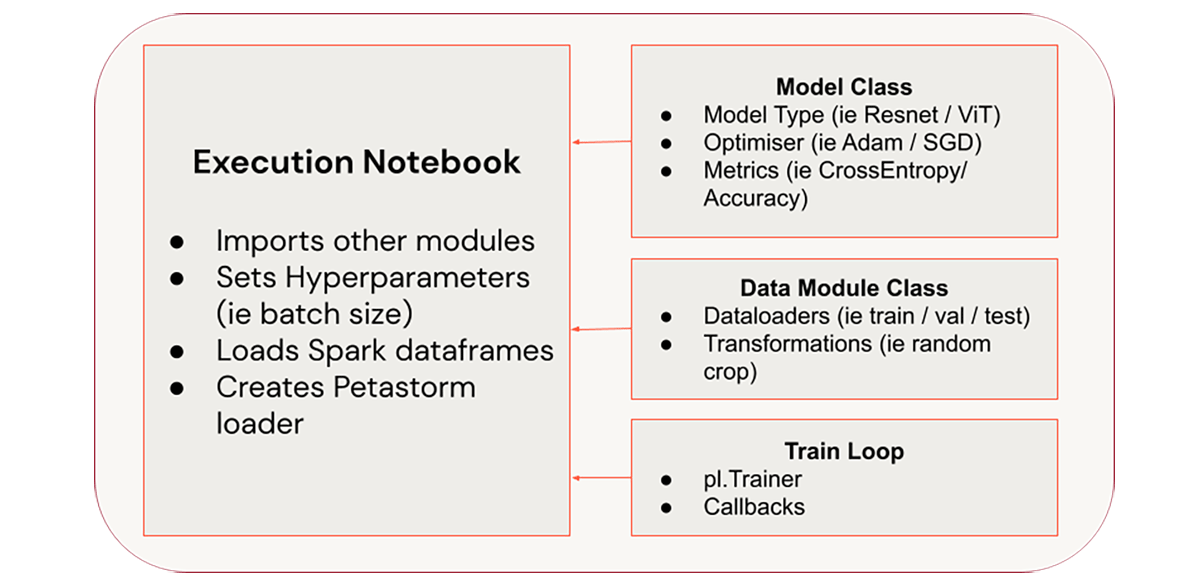
타겟 아키텍처

이 기사의 목표는 위와 같이 구조화된 코드베이스를 구축하는 것입니다.
오픈 소스 Linux Foundation 프로젝트 Delta Lake에 데이터 사용을 저장합니다.
내부적으로 Delta Lake는 가공되지 않은 데이터를 Parquet 형식으로 저장합니다.
Petastorm은 데이터 로딩 업무를 맡고 레이크하우스와 딥 러닝 모델 간의
인터페이스를 제공합니다. MLflow 는 Experiment 추적 도구를 제공하고
모델을 모델 레지스트리에 저장할 수 있습니다.
이 설정을 사용하면 불필요한 데이터 중복 비용을 피할 수 있을 뿐만 아니라
훈련 중인 모델을 제어하고 관리할 수 있습니다.
2부 - 예제 사용 사례 및 라이브러리
개요Part 2 - Example use case
and library overview
사용 사례 예시
이 사용 사례 예제에서는 tensorflow flowers 데이터 세트를 사용합니다.
이 데이터 세트는 어떤 종류의 꽃인지 식별하려는 분류 유형 문제에 사용됩니다.

Petastorm을 통한 딥 러닝을 위한 데이터 레이크 활용
역사적으로 레이크하우스 및 데이터 웨어 하우스 와 같은 데이터 관리 시스템은
기계 학습 프레임워크와 통합되기보다는 병렬로 개발되었습니다. 따라서
PyTorch 데이터 로더 모듈은 기본적으로 parquet 형식을 지원하지 않습니다.
또한 Hive metastore와 같은 레이크하우스 메타데이터 구조와 통합되지 않습니다.
Petastorm 프로젝트는 레이크하우스 테이블과 PyTorch 간의 인터페이스를
제공합니다. 또한 학습 노드 간 데이터 샤딩을 처리하고 캐싱 계층을 제공합니다.
Petastorm은 Databricks ML Runtime에 미리 패키지되어 제공됩니다.
먼저 데이터 세트와 작업 방법에 대해 알아보겠습니다.
주목할 점은 스파크 데이터 프레임을 petastorm 객체로 변환하기 위해
해야 할 일은 다음과 같은 코드라는 것입니다.
객체가 spark_converter 있으면 다음을 사용하여
PyTorch Dataloader로 변환 할 수 있습니다.
그런 다음 평소와 같이 PyTorch 코드에서 사용할 수 있는
DataLoader를 제공합니다 converted_dataset .
Exploring the flowers 데이터세트라는 제목의 노트북을 열고 팔로우합니다.
표준 ML 런타임 clusters 로 충분하며 GPU clusters에서 실행할 필요가 없습니다.
모델 단순화 및 구조화 - PyTorch Lightning 입력
defaultPyTorch 코드는 매우 장황해질 수 있습니다.
모델 정의, 훈련 루프 및 데이터 로더 설정이 있습니다.
default 이 모든 코드가 함께 혼합되어 빠른 실험의
핵심이 될 수 있는 데이터 세트와 모델을 안팎으로 교환하기가 어렵습니다.
PyTorch Lightning은 실험 모델과 기본 학습 루프를 설정하는데 필요한
상용구를 크게 줄여 이를 더 간단하게 만드는 데 도움이 됩니다.
PyTorch 코드를 구조화하는 독단적인 접근 방식으로,
더 읽기 쉽고 유지 관리 가능한 코드를 허용합니다.
이 프로젝트에서는 코드를 세 가지 주요 모듈로 나눕니다.
- PyTorch 모델
- 데이터 로더 및 변환
- 메인 트레이닝 루프
이렇게 하면 코드의 이식성을 높이고 구성을 개선하는 데 도움이 됩니다.
이러한 클래스와 함수는 모두 를 통해 %run기본 실행 노트북으로 가져오며,
여기서 학습 하이퍼파라미터가 정의되고 코드가 실제로 실행됩니다.
모델 정의:
이 모듈에는 모델 아키텍처 자체에 대한 코드가 포함되어 있습니다.
LightningModule. 모델 아키텍처가 있는 곳입니다.
참고로 이것은 timm, HuggingFace 등과 같은 인기 있는
모델 프레임워크를 활용하기 위해 업데이트가 필요한 모듈입니다.
이 모듈에는 옵티마이저에 대한 정의도 포함됩니다.
이 경우 SGD만 사용하지만 다른 유형의 옵티마이저를
테스트하기 위해 매개변수화할 수 있습니다.
DataLoader 클래스:
데이터 로더 코드가 모델 코드와 혼합되는
네이티브 PyTorch와 달리 PyTorch Lightning을
사용하면 별도의 LightningDataModule 클래스로
분할할 수 있습니다. 이렇게 하면 데이터 세트를 더 쉽게
관리하고 데이터 세트의 다양한 상호 작용을 빠르게 테스트할 수 있습니다.
Petastorm 데이터 로더로 빌드 할 LightningDataModule 때
원시 spark dataframes가 아닌 spark_converter 객체를 제공합니다.
Spark Dataframe은 이미 배포된 기본 Spark clusters에 의해
관리되는 반면 PyTorch Dataloader는 나중에 다른 수단을 통해 배포됩니다.
주요 훈련 루프:
이것이 주요 훈련 기능입니다. 모델을 클래스에 Trainer 공급하기 전에 모델을
정의하는 것이 필요합니다.LightningDataModule LightningModule
여기에서 PyTorch Lightning Trainer를 인스턴스화하고 필요한 모든 콜백을 정의합니다.
나중에 학습 프로세스를 확장할 때 모든 처리 노드에서 MLflow 로깅과 같은
일부 프로세스를 실행할 필요가 없습니다. 따라서 첫 번째 GPU에서만 실행되도록 제한합니다.
훈련 중에 모델을 체크포인트하는 것은 진행 상황을 유지하는 데 중요하지만
PyTorch Lighting은 default 이를 처리하므로 코드를 추가할 필요가 없습니다.
PyTorch Lightning 모듈 빌드 노트북을 따라 합니다.
3부 - 학습 작업 크기 조정
단일 GPU 훈련은 CPU 훈련보다 훨씬 빠르지만 충분하지 않은 경우가 많습니다.
적절한 프로덕션 모델은 클 수 있으며 이를 올바르게 학습하는 데 필요한 데이터
세트도 클 수 있습니다. 따라서 여러 GPU에서 훈련을 확장할 수 있는 방법을
살펴봐야 합니다.
딥 러닝 모델을 배포하는 주요 접근 방식은 데이터 병렬 처리를 통해
모델 복사본을 각 GPU로 보내고 각 GPU에 서로 다른 데이터
샤드를 공급하는 것입니다. 이를 통해 배치 크기를 늘리고 더 높은
학습률을 활용하여 이 기사에서 설명한 대로 학습 시간을 개선할 수 있습니다.
GPU에 학습 작업을 배포하는 데 도움이 되도록 Horovod를 활용할 수 있습니다.
Horovod 는 여러 노드에서 분산 PyTorch 프로세스를 수동으로 트리거하는
대안을 제공하는 또 다른 Linux Foundation 프로젝트입니다.
Databricks ML Runtime에는 default 단일 노드 및 다중 노드 학습 모드에서
크기를 조정하는 데 도움이 되는 HorovodRunner 클래스가 포함되어 있습니다.
Horovod활용하려면 새로운 "슈퍼" 기차 루프를 만들어야 합니다.
이 함수는 Horovod hvd.init() 시작하고 DataModule 및
train 함수가 올바른 노드 번호와 hvd.rank()
총 장치 hvd.size()수로 트리거되도록 합니다.
이 Horovod 기사에서 설명한 대로 GPU 수에 따라 학습률을 확장합니다.
그런 다음 Horovod가 병렬 처리를 처리할 때
GPU 수가 1로 설정된 일반 기차 루프를 반환합니다.
Main Execution 노트북 을 따라가면서 싱글GPU에서
멀티GPU로 전환하는 방법을 살펴보겠습니다.
1단계 - 한 노드에서 크기 조정
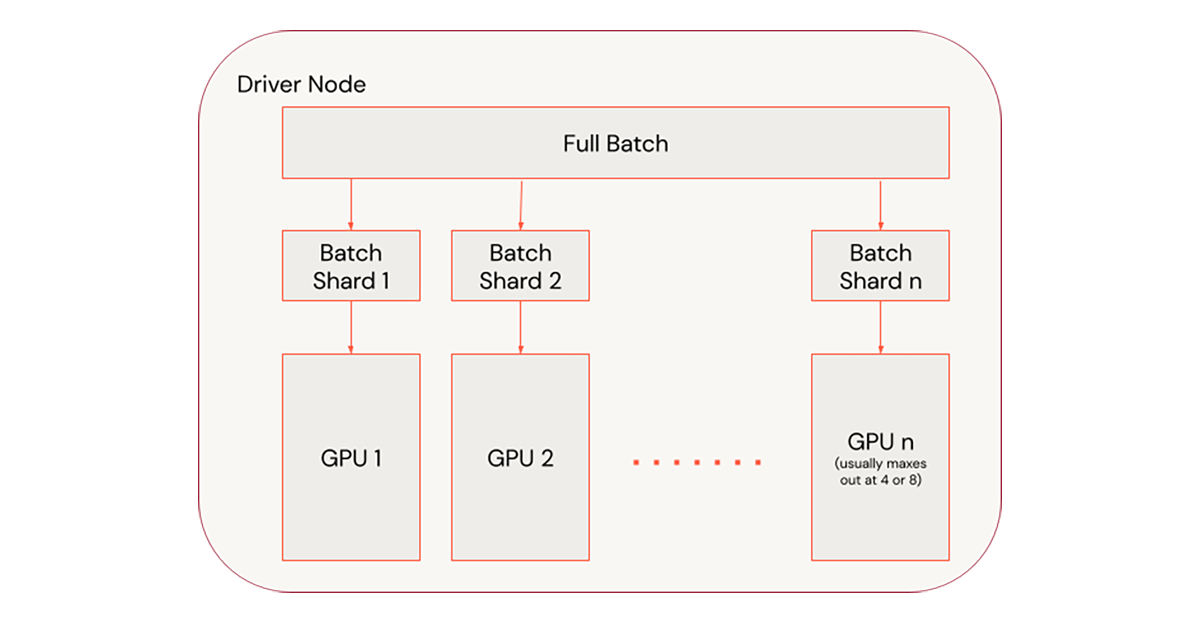
한 노드에서 크기를 조정하는 것이 가장 쉬운 크기 조정 방법입니다.
또한 다중 노드 학습에 필요한 네트워크 트래픽을 방지하므로 성능이 매우 뛰어납니다.
Spark 네이티브 ML 라이브러리와 달리 대부분의 딥 러닝 학습 프로세스는 노드 오류에서
자동으로 복구되지 않습니다. 그러나 PyTorch Lightning은 훈련 epoch를 복구하기 위해
체크포인트를 자동으로 저장합니다.
코드에서는 를 default parameter train 함수의 dbfs 위치로 설정합니다 .
여기에서 PyTorch Lightning이 체크포인트를 저장합니다.
ckpt를 ckpt_restore 가리키는 경로를 설정하면
train 함수는 해당 체크포인트에서 훈련을 재개합니다.
train 함수를 한 노드의 여러 GPU로 확장하려면 다음을 사용합니다 HorovodRunner.
음수로 설정하면 np 단일 노드, 이 예제의 드라이버 노드에서 4개의 GPU
또는 양수인 경우 np 작업자 노드에서 실행됩니다.
2단계 - 노드 간 크기 조정
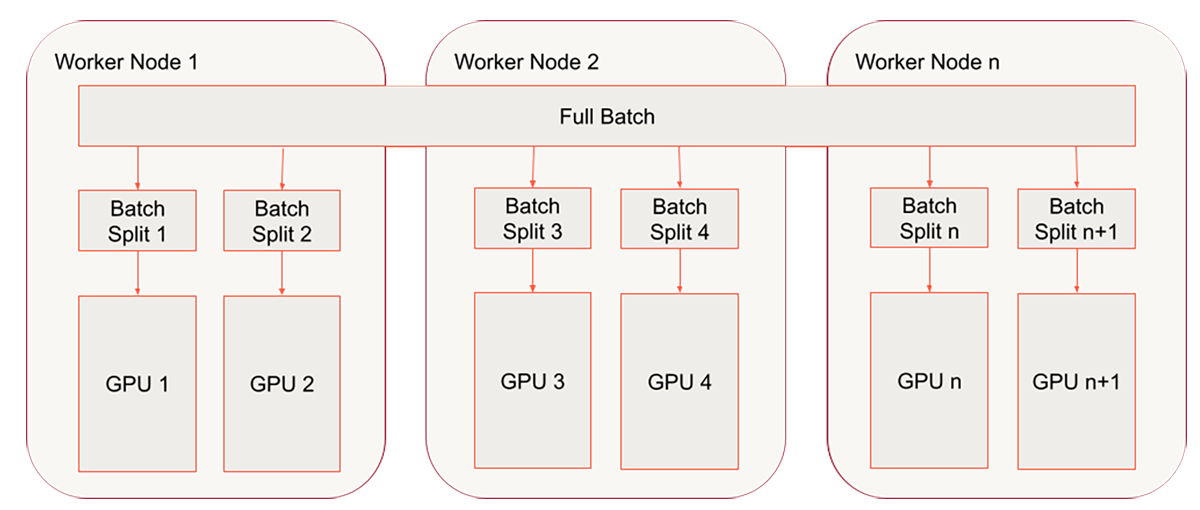
우리는 이미 Horovod 래퍼로 훈련 함수를 래핑했으며 단일 노드 다중
GPU 처리를 위해 HorovodRunner를 성공적으로 활용했습니다.
마지막 단계는 다중 노드/다중 GPU 설정으로 이동하는 것입니다.
단일 노드 clusters�따라 해왔다면 다중 노드 clusters.
다음 코드의 경우 아래와 같은 clusters 구성을 사용합니다.
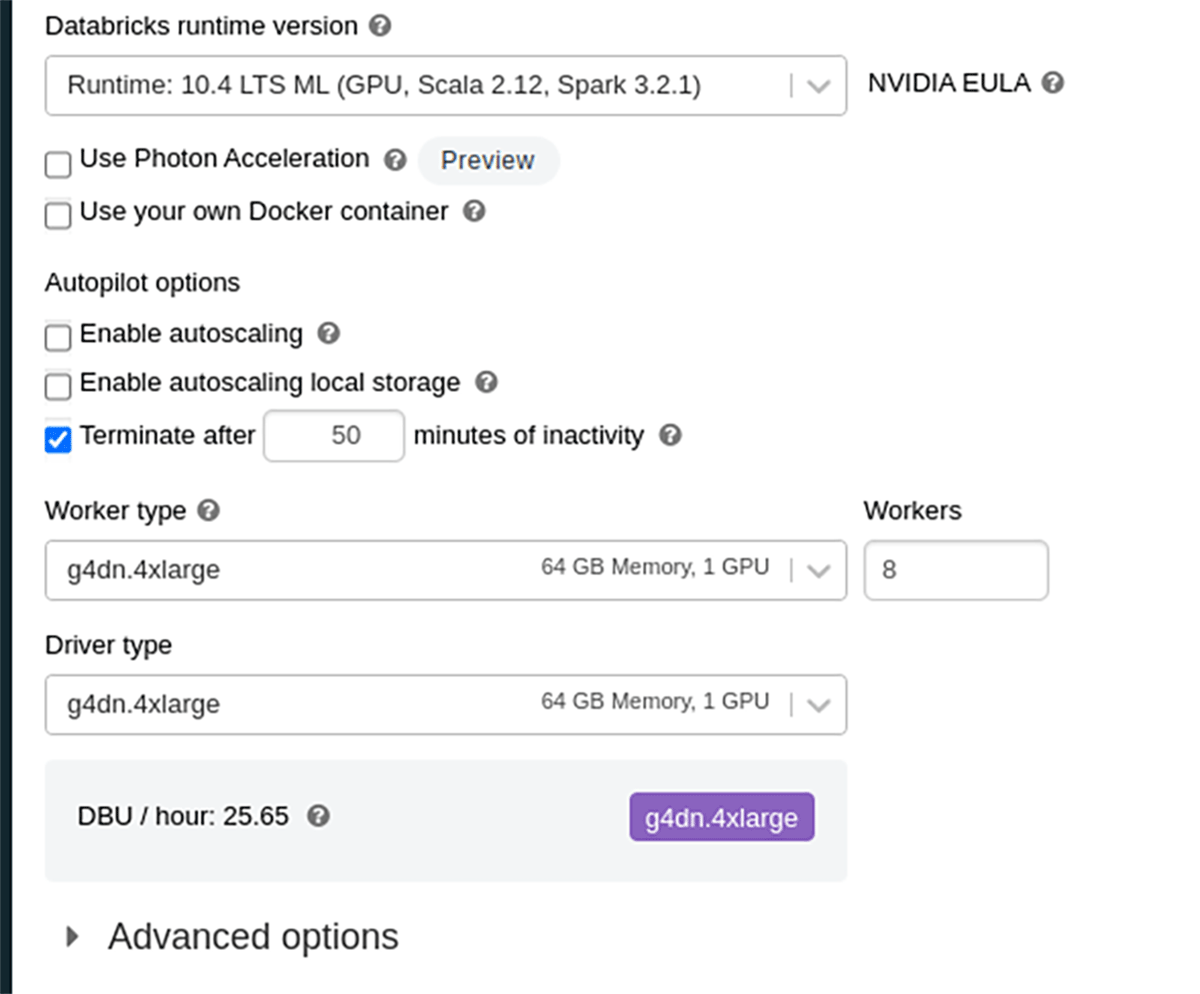
Databricks에서 분산 학습을 실행할 때 자동 크기 조정은 현재 지원되지
않으므로 작업자를 미리 고정된 수로 설정합니다.
분산 딥 러닝 작업을 확장할 때 발생하는 일반적인 문제는
모든 GPU가 배치 분할을 받을 수 있을 만큼 페타스톰 테이블이
잘 분할되지 않았다는 것입니다.
최소한 GPU만큼 많은 데이터 파티션이 있는지 확인해야 합니다
코드에서 변수를 사용하여 함수의 prepare_data GPU 수를 설정하여
이 문제를 해결합니다 num_devices .
이는 단순히 표준 spark repartition 명령을 호출합니다.
파티션 수를 GPU 수의 배수 num_devices로 설정하여
데이터 세트에 학습 프로세스에 할당한 모든 GPU에 대해
충분한 파티션이 있는지 확인합니다.
파티션 부족은 GPU를 유휴 상태로 만드는 일반적인 원인입니다.
분석
심층 신경망을 훈련할 때 신경망을 과적합하지 않도록 하는 것이 중요합니다.
이를 관리하는 표준 방법은 Early Stopping을 활용하는 것입니다.
이 프로세스는 각 Epoch에서 모니터링하도록 설정한 메트릭이
계속 개선되고 있는지 확인합니다. 이 경우 val_loss.
Experiment의 경우 0.01로 설정 min_delta 되었으므로 각 Epoch에서
val_loss 최소 0.01 개선이 예상됩니다.
우리는 10으로 설정 patience 했기 때문에 기차 루프는 훈련이
중지되기 전에 개선 없이 최대 10epoch까지 계속 실행됩니다.
우리는 성능의 마지막 한 방울을 끌어낼 수 있도록 이것을 설정했습니다.
실험 기간을 더 짧게 유지하기 위해 a stopping_threshold를 0.55로
설정하여 이 수준 아래로 떨어지면 val_loss 학습 프로세스를 중지합니다.
이러한 parameter 염두에 두고 확장 Experiment 의 결과는 다음과 같습니다.
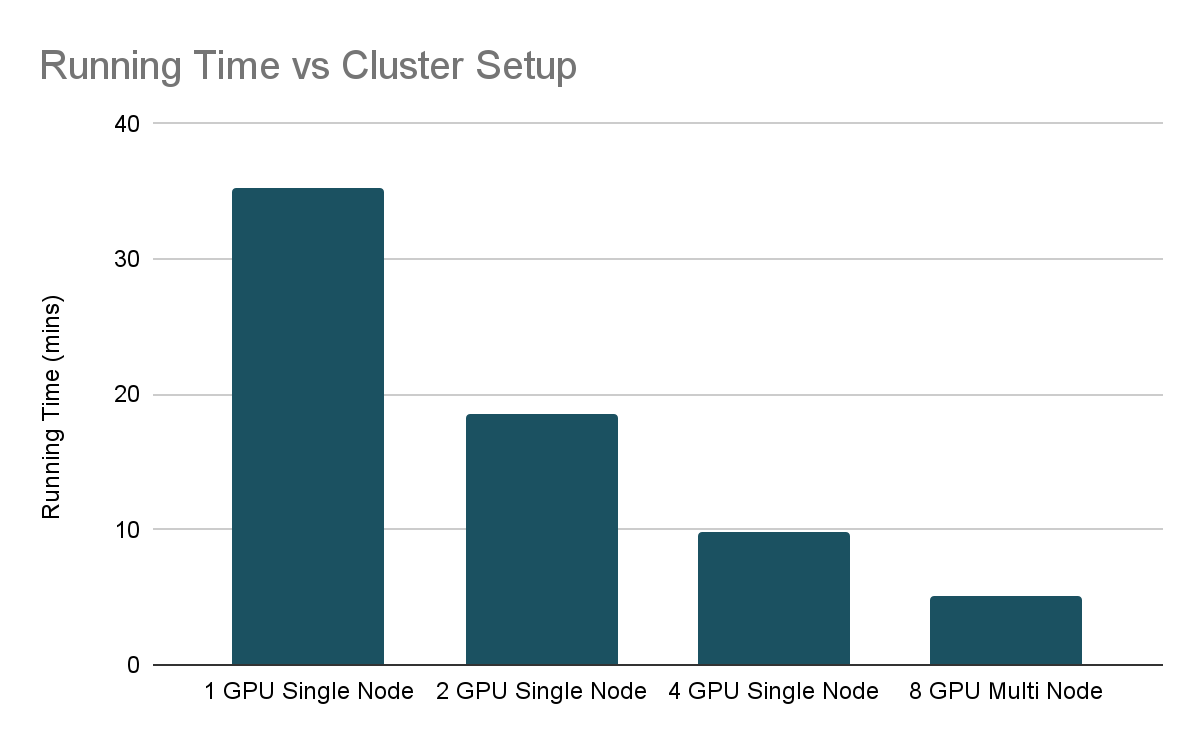
보시다시피 실행 시간 대 clusters 설정 차트에서 시스템 리소스를 늘리면서
학습 시간을 거의 절반으로 줄였습니다. 스케일링은 선형적이지 않으며,
이는 서로 다른 GPU에서 훈련 프로세스를 조정하는 오버헤드 때문입니다.
딥러닝을 확장할 때 수익이 감소하는 것이 일반적이므로 GPU를
추가하기 전에 학습 루프가 효율적인지 확인하는 것이 중요합니다.
그러나 이것이 전체 그림은 아니지만 이전 블로그 기사인
How (Not) To Scale Deep Learning in 6 Easy Steps
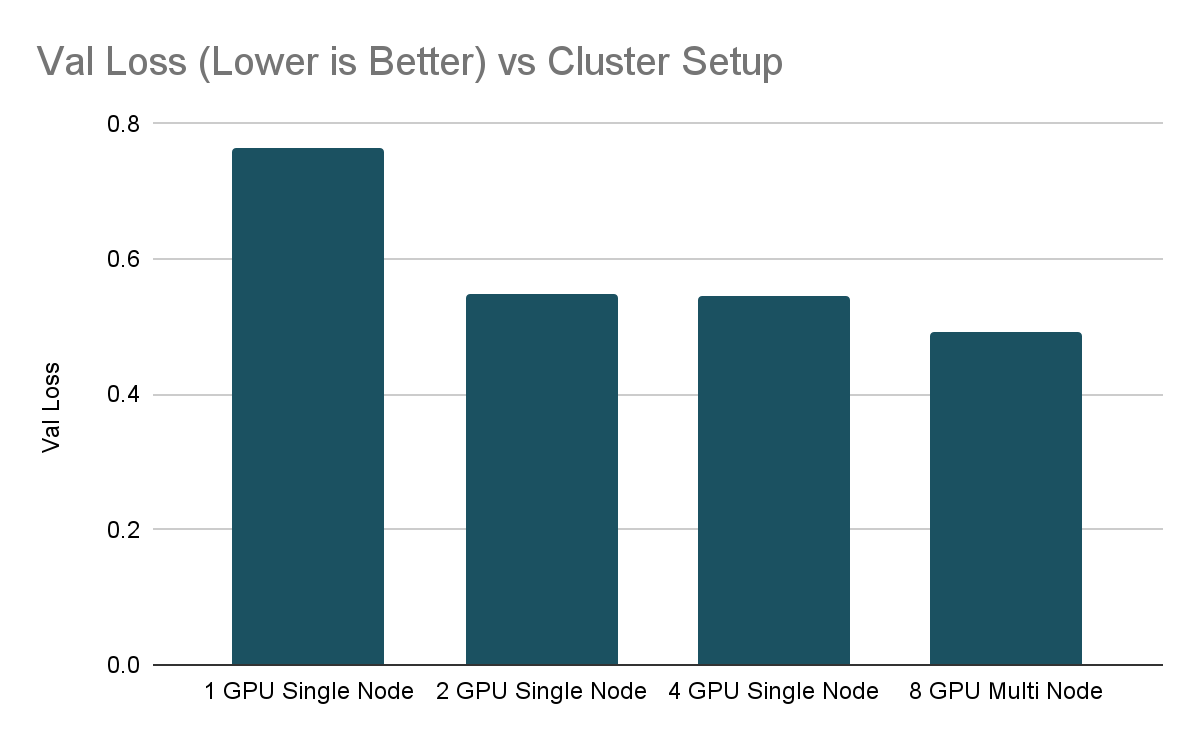
EarlyStopping 에서 조언한 모범 사례에 따라
다양한 학습 실행에 의해 달성된 최종 검증 손실도
확인하는 것이 중요합니다.
이 경우 0.55로 stopping_threshold 설정합니다.
흥미롭게도 단일 GPU 설정은 다중 GPU 설정보다
더 나쁜 검증 손실에서 멈췄습니다. 단일 GPU 훈련 val_loss은 .
시작하기
Databricks 내에서 PyTorch Lightning을 활용하는 방법을 보여주었고
여러 노드로 HorovodRunner 확장하기 위해 래핑하고 활용하는
EarlyStopping방법에 대한 몇 가지 지침을 제공했습니다.
이제 시도해 볼 차례입니다.
노트북:
Exploring the flowers 데이터세트
PyTorch Lightning 모듈 빌드
메인 실행 노트북
참조 항목:
호로보드러너
Petastorm
Deep Learning Best Practices
How (Not to Scale Deep Learning) 딥러닝을 확장하는 방법
공평한 경쟁의 장: 분산 딥 러닝 훈련을 위한 HorovodRunner
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.