Databricks의 Apache Iceberg v3로 Lakehouse 발전시키기
Databricks는 Apache Iceberg v3를 지원하여 고객에게 통합된 고성능의 상호 운용 가능한 데이터 레이어를 제공합니다.
작성자: Ryan Blue, Daniel Weeks, 제이슨 리드, Fred Liu , Aniruth Narayanan
• Databricks는 Apache Iceberg v3를 지원하므로 고객은 단일 데이터 복사본에서 상호 운용 가능하고 거버넌스가 적용된 워크로드를 실행할 수 있습니다
• Iceberg v3에서는 삭제 벡터, 행 수준 리니지, Variant 데이터 유형을 이제 모든 관리형 테이블에서 사용할 수 있습니다
• 이러한 기능을 통해 Databricks는 최고의 성능을 위해 모든 포맷에 데이터 인텔리전스 플랫폼을 제공합니다
Databricks는 데이터 인텔리전스 플랫폼에서 Apache Iceberg v3를 지원하여 고객에게 동급 최고의 성능, 상호 운용성, 거버넌스를 갖춘 통합되고 개방된 데이터 레이어를 제공합니다.
이번 릴리스를 통해 Iceberg 워크로드를 실행하는 Databricks 고객은 이제 deletion vectors, 행 수준 리니지, Variant 데이터 유형을 포함한 v3 기능을 활용할 수 있습니다. 이러한 기능을 통해 팀은 여러 플랫폼에서 최신 워크로드를 효율적이고 일관되게 실행할 수 있습니다. 이러한 기능은 Delta 및 Iceberg 테이블 모두에서 원활하게 작동하며, 데이터 재작성 없이 상호 운용성을 지원합니다.

이번 릴리스는 개방형 표준에 대한 Databricks의 약속을 더욱 강화하고, 고객이 완전한 거버넌스와 유연성을 갖춘 Delta Lake, Apache Iceberg, Apache Parquet, Apache Spark의 lakehouse 기반을 구축하는 데 도움이 됩니다.
이 블로그에서는 다음에 대해 살펴보겠습니다.
- Iceberg v3를 사용한 통합 데이터 레이어
- Databricks의 효율적인 Iceberg v3 워크로드
- 개방형 테이블 형식의 발전
Iceberg v3를 사용한 통합 데이터 레이어
Delta Lake와 Apache Iceberg는 최신 lakehouse의 기반이 되었으며, 각각 안정성, 거버넌스, 확장 가능한 데이터 관리를 위한 강력한 기능을 갖추고 있습니다. 두 형식 모두 메타데이터 파일을 사용하여 Parquet 데이터 파일 및 행 수준 삭제를 추적합니다. 하지만 이러한 데이터 및 삭제 파일의 포맷 간 사소한 차이로 인해 조직은 일반적으로 사용하던 데이터 플랫폼을 기준으로 특정 포맷과 그 기능을 선택해야만 했습니다. 페타바이트 규모의 데이터를 다시 작성하는 것은 비현실적이기 때문에 이러한 선택은 종종 되돌릴 수 없었습니다.
Iceberg v3 는 이러한 격차를 해소합니다. Delta 및 Parquet, Spark와 같은 광범위한 오픈 에코시스템과 긴밀하게 연계되는 기능을 도입하여 팀이 여러 포맷에서 일관된 동작과 성능으로 단일 데이터 복사본을 사용할 수 있도록 지원합니다.
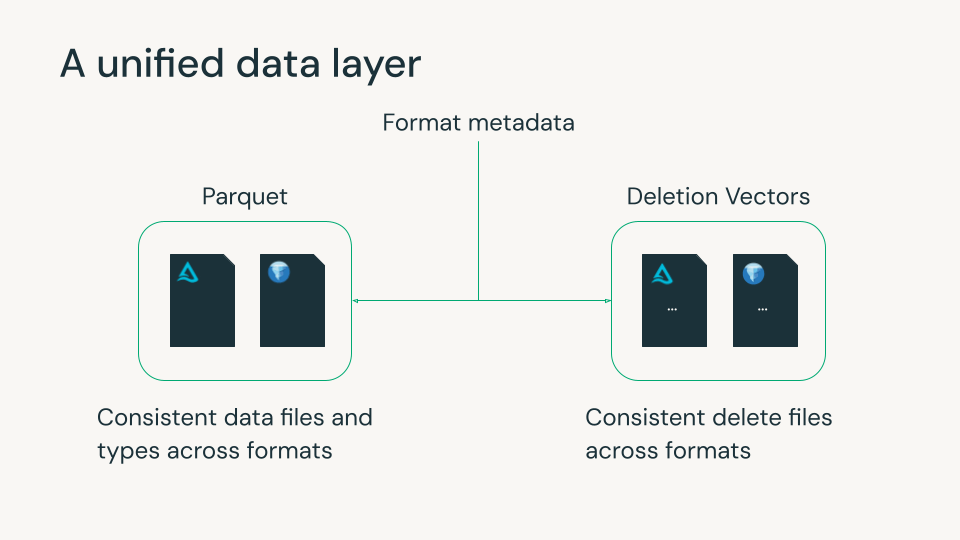
Databricks는 오랫동안 lakehouse의 미래가 파편화 없는 선택성에 있다고 믿어 왔습니다. Iceberg v3에 대한 저희의 기여는 이러한 약속을 반영합니다. 즉, 핵심 테이블 동작을 통합하여 고객이 Unity Catalog로 모든 것을 일관되게 관리하면서 선호하는 엔진과 도구를 사용할 수 있도록 돕습니다.
Databricks의 효율적인 Iceberg v3 워크로드
Iceberg v3를 통해 Databricks는 Data Intelligence Platform의 기능을 모든 Unity Catalog 관리 테이블에 제공합니다.
더 빠른 업데이트를 위한 삭제 벡터
Deletion vectors를 사용하면 Parquet 파일을 다시 작성하지 않고도 행을 삭제하거나 업데이트할 수 있습니다. 대신 삭제는 별도의 파일로 저장되고 읽기 작업 중에 Merge됩니다. 대부분의 데이터 엔지니어링 워크로드는 한 번에 몇 개의 행만 수정하므로, 이는 효율적인 쓰기를 위한 중요한 기능입니다.

이제 Databricks의 동급 최고 ETL 가격 대비 성능을 활용하여 삭��제 벡터(deletion vector)를 사용하여 Iceberg 워크로드를 실행할 수 있습니다. 일반적인 MERGE 문에 비해 삭제 벡터는 업데이트 속도를 최대 10배까지 높일 수 있습니다. Iceberg 엔진은 Unity Catalog의 Iceberg REST Catalog APIs를 사용하여 관리형 Iceberg 테이블에 읽기 및 쓰기 작업을 수행할 수 있습니다. Geodis가 언급했듯이:
“Iceberg에 Deletion Vectors가 도입되었으므로 이제 Unity Catalog에서 Iceberg 데이터 자산을 중앙 집중화하는 동시에, 원하는 엔진을 활용하면서 동급 최고의 성능을 유지할 수 있습니다.” —Delio Amato, Geodis 최고 아키텍트 겸 데이터 책임자
행 수준 동시성을 위한 행 리니지
행 리니지(Row lineage)는 각 행에 고유 ID를 부여하여 시간 경과에 따른 변경 사항을 쉽게 추적할 수 있도록 합니다. 모든 Iceberg v3 테이블에는 행 리니지가 필요합니다.
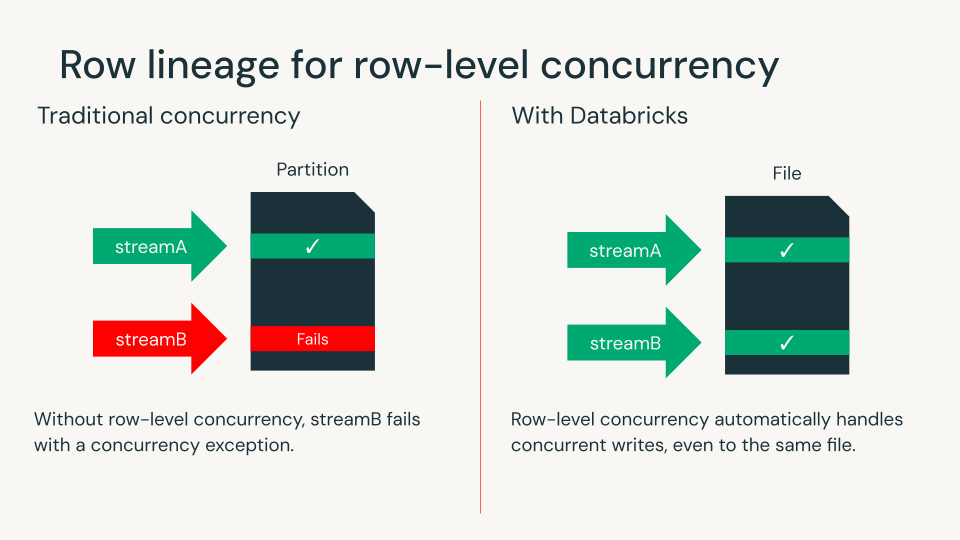
삭제 벡터(deletion vector)와 행 리니지(row lineage)를 통해 Databricks 고객은 이제 행 수준 동시성(row-level concurrency) 을 사용하여 행 수준에서 쓰기 충돌을 감지할 수 있습니다. 이를 통해 복잡한 데이터 Layout을 ��설계하거나 동시성을 보장하기 위해 워크로드를 조정할 필요가 없어집니다. Databricks는 개방형 테이블 포맷에 이 기능을 제공하는 유일한 lakehouse 엔진입니다.
유연한 수집을 위한 Variant 데이터 유형
최신 데이터는 행과 열에 깔끔하게 들어맞는 경우가 거의 없습니다. Logs, 이벤트, 애플리케이션 데이터는 종종 JSON 형식으로 들어옵니다. Variant 데이터 유형은 반정형 데이터를 직접 저장하여 복잡한 스키마나 불안정한 파이프라인 없이도 뛰어난 성능을 제공합니다.

Databricks의 Variant 데이터 유형을 사용하면 수집 함수를 사용하여 가공되지 않은 데이터를 lakehouse 테이블에 직접 저장할 수 있습니다. 이 함수는 JSON, CSV, XML 데이터 로드를 지원합니다. Variant는 shredding을 지원하는데, 이는 공통 필드를 별도의 청크로 추출하여 컬럼형과 유사한 성능을 제공합니다. 이를 통해 지연 시간이 짧은 BI, 대시보드, 알림 파이프라인의 query 속도를 높일 수 있습니다.
Variant는 Delta와 Iceberg 모두에서 작동합니다. 다른 엔진을 사용하는 팀은 데이터 중복 없이 Variant 열을 포함한 동일한 테이블을 query할 수 있습니다:
“특히 보안 및 애플리케이션 logs가 필요한 사용 사례의 경우, 단순한 스칼라 데이터의 시대는 지났습니다. Unity Catalog와 Iceberg v3는 Variant를 통해 반정형 데이터의 강력한 기능을 활용할 수 있게 해줍니다. 이를 통해 상호 운용성과 비용 효율적인 페타바이트 규모의 logs 수집이 가능합니다.” —Russell Leighton, Panther 최고 아키텍트
개방형 테이블 형식의 발전
Iceberg v3는 데이터 레이어 전반의 개방형 테이블 형식을 통합하는 데 있어 중요한 단계입니다. 다음 과제는 대규모 환경에서 포맷이 메타데이터를 관리하고 동기화하는 방식을 개선하는 것입니다. Iceberg Summit에서 처음 소개된 적응형 메타데이터 트리와 같은 커뮤니티의 노력은 메타데이터 오버헤드를 줄이고 대규모 테이블 운영을 가속화하는 데 도움이 될 수 있습니다.
이러한 아이디어들이 성숙해짐에 따라, Delta 및 Iceberg 커뮤니티는 더 빠른 commit, 효율적인 메타데이터 관리, 확장 가능한 다중 테이블 운영이라는 공동의 목표를 가지고 더욱 긴밀해지고 있습니다. Databricks는 이러한 발전에 지속적으로 기여하며, 고객이 포맷 수준의 차이에 제약을 받지 않고 최상의 성능과 상호 운용성을 얻을 수 있도록 지원합니다.
지금 Databricks에서 Iceberg v3를 사용해 보세요
이제 Databricks에서 Iceberg v3 기능을 사용할 수 있게 되어 고객은 Unity Catalog의 거버넌스로 뒷�받침되는 가장 미래 지향적인 표준 구현을 이용할 수 있습니다. Iceberg v3를 통해 Databricks 고객은 Delta 및 Iceberg 테이블의 최고의 기능을 활용할 수 있습니다. Iceberg v3로 Unity Catalog 관리형 테이블을 만드는 방법은 간단합니다.
Unity Catalog 및 Iceberg v3 를 시작하고, 다가오는 Open Lakehouse + AI 이벤트에 참여하여 개방형 에코시스템에 대한 저희의 노력을 자세히 알아보세요.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.