Agentic AI 보안: Databricks AI 보안 프레임워크(DASF v3.0)의 새로운 위험 및 제어
데이터에 액세스하고, 도구를 호출하고, 작업을 실행하는 에이전트를 위한 35개의 새로운 에이전트 AI 위험 및 6개의 완화 제어
작성자: 데이비드 뵈브, 오마르 카와자, Arun Pamulapati, Nishith Sinha , Caelin Kaplan
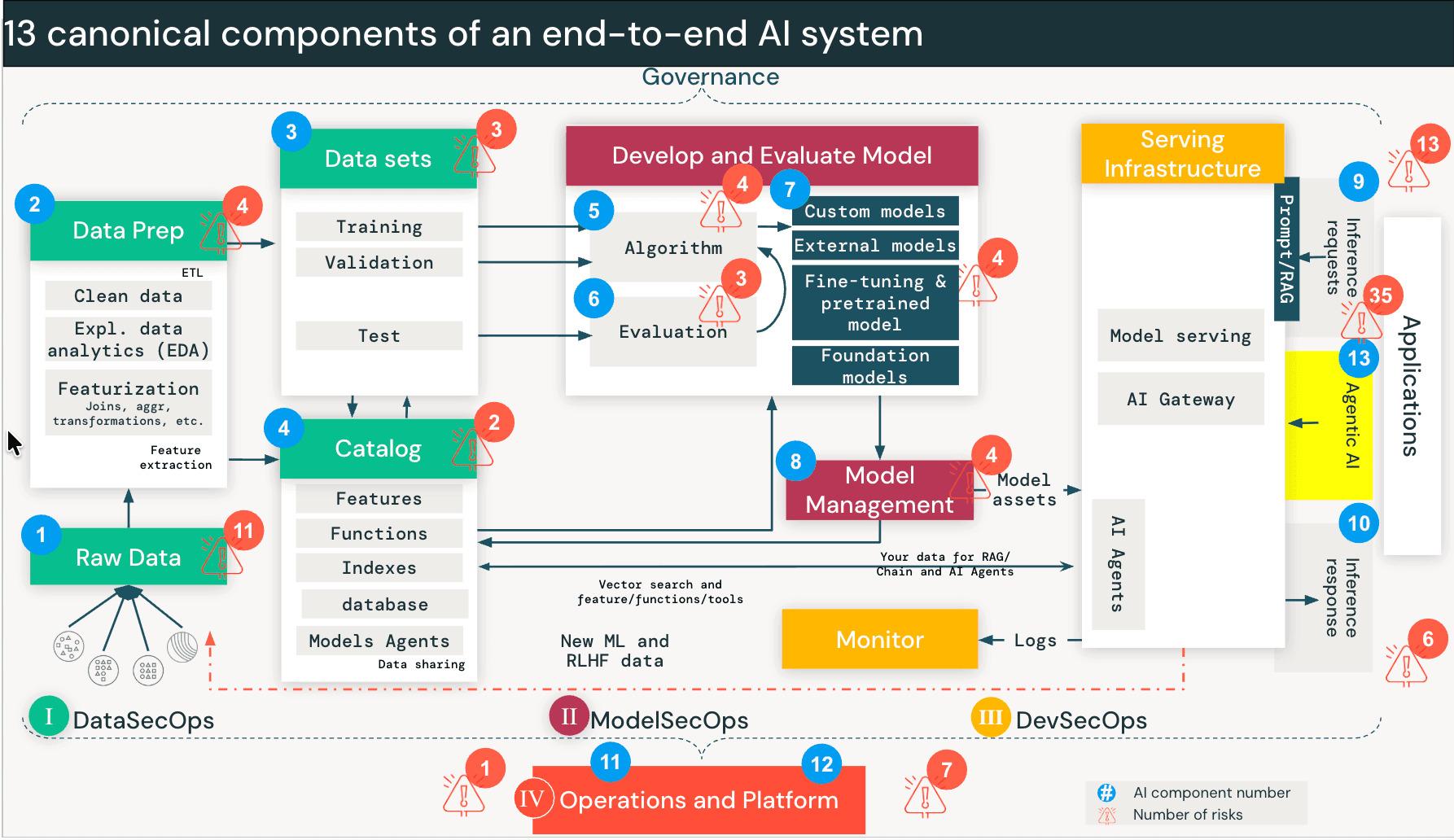
- Databricks AI Security Framework(DASF)에 이제 에이전트 AI가 13번째 시스템 구성 요소로 포함되어, 35개의 새로운 기술 보안 위험과 6개의 새로운 완화 제어가 추가되어 조직이 자율 에이전트를 자신 있게 배포할 수 있도록 지원합니다.
- 이 확장은 에이전트 메모리, 계�획 및 도구 사용의 고유한 위험을 다루며, 에이전트를 엔터프라이즈 도구에 연결하기 위한 새로운 표준인 Model Context Protocol(MCP)에 의해 도입된 위협도 포함합니다.
- DASF Agentic AI Extension 백서와 업데이트된 요약본을 지금 다운로드하여 에이전트 아키텍처를 평가하고, 도구 생태계를 매핑하고, 자율성을 위해 특별히 제작된 심층 방어 제어를 구현하세요.
저희는 Databricks AI Security Framework (DASF) Agentic AI Extension 백서 출시를 발표하게 되어 기쁩니다! Databricks 고객들은 이미 데이터베이스를 쿼리하고, 외부 API를 호출하고, 코드를 실행하고, 다른 에이전트와 협력하는 AI 에이전트를 배포하고 있습니다. 저희는 이러한 배포를 책임지는 팀들이 어려운 질문을 계속해서 던지는 것을 듣습니다. AI가 단순히 무언가를 말하는 것이 아니라 할 수 있게 되면 어떻게 될까요? 그렇기 때문에 저희는 DASF를 확장했습니다.
이번 업데이트를 통해 자율 AI 에이전트 보안을 위한 새로운 지침을 소개합니다:
- 에이전트 추론, 메모리 및 도구 사용을 다루는 35가지 새로운 에이전트 AI 보안 위험
- 최소 권한, 샌드박싱, 인간 감독을 포함한 6가지 새로운 완화 제어
- 모델 컨텍스트 프로토콜(MCP) 도구 서버 및 클라이언트에 대한 보안 지침
- 다중 에이전트 시스템 위험 및 에이전트 통신 위협에 대한 적용 범위
이러한 추가 사항들은 조직이 거버넌스, 관찰 가능성 및 심층 방어 보안 제어를 유지하면서 AI 에이전트를 안전하게 배포하는 데 도움을 줍니다.
이를 통해 전체 프레임워크는 97가지 위험과 73가지 제어로 확장되었습니다. 저희는 이러한 새로운 위험과 제어를 포함하도록 DASF 컴펜디엄(Google 시트, Excel)을 업데이트하여 즉각적인 운영화를 촉진하기 위해 업계 표준에 매핑했습니다. 이러한 추가 사항은 "DASF 개정" 열 아래에서 DASF v3.0으로 분류됩니다.
{kind=link}
AI 에이전트가 조치를 취할 수 있을 때의 보안 위험
RAG와 같은 전통적인 AI 시스템은 주로 읽기 전용 모드로 작동합니다. 하지만 AI 에이전트는 데이터베이스 쿼리, API 호출, 코드 실행, 외부 도구와의 상호 작용과 같은 작업을 수행할 수 있습니다.
에이전트는 다르게 작동합니다. 사용자가 에이전트와 상호 작용하면 모델은 루프를 시작합니다. 요청을 하위 작업으로 분해하고, 도구(예: "Sales Database 쿼리")를 선택하고, 실행하고, 출력을 평가하고, 다음에 다른 도구를 호출할지 결정합니다. 작업이 완료될 때까지 계속됩니다. 에이전트는 어떤 데이터에 액세스하고 어떤 도구를 호출할지에 대한 실시간 결정을 내립니다. 이 결정은 과거에는 사람이 내리거나 애플리케이션 로직에 하드코딩되었던 것입니다.
이는 저희가 발견 및 탐색(Discovery and Traversal)이라고 부르는 새로운 유형의 위험을 만듭니다. 솔루션을 찾도록 설계된 에이전트는 요청한 사용자를 위해 의도되지 않았던 데이터 경로와 도구 인터페이스를 탐색합니다. 이는 버그를 악용하는 것이 아닙니다. 그것은 구축된 대로 정확히 작동하는 것입니다. 그러나 적절한 제어 없이는 사용자는 자신의 권한이 아닌 에이전트의 권한을 효과적으로 상속받게 됩니다.
치명적인 삼중주(The Lethal Trifecta). Meta의 “Agents Rule of Two” 및 Simon Willison의 “Lethal Trifecta”와 같은 유사한 모델을 포함한 최근 업계 연구는 이것이 위험해지는 조건을 강조합니다. 세 가지 조건이 동시에 존재할 때 위험 프로필이 급증합니다:
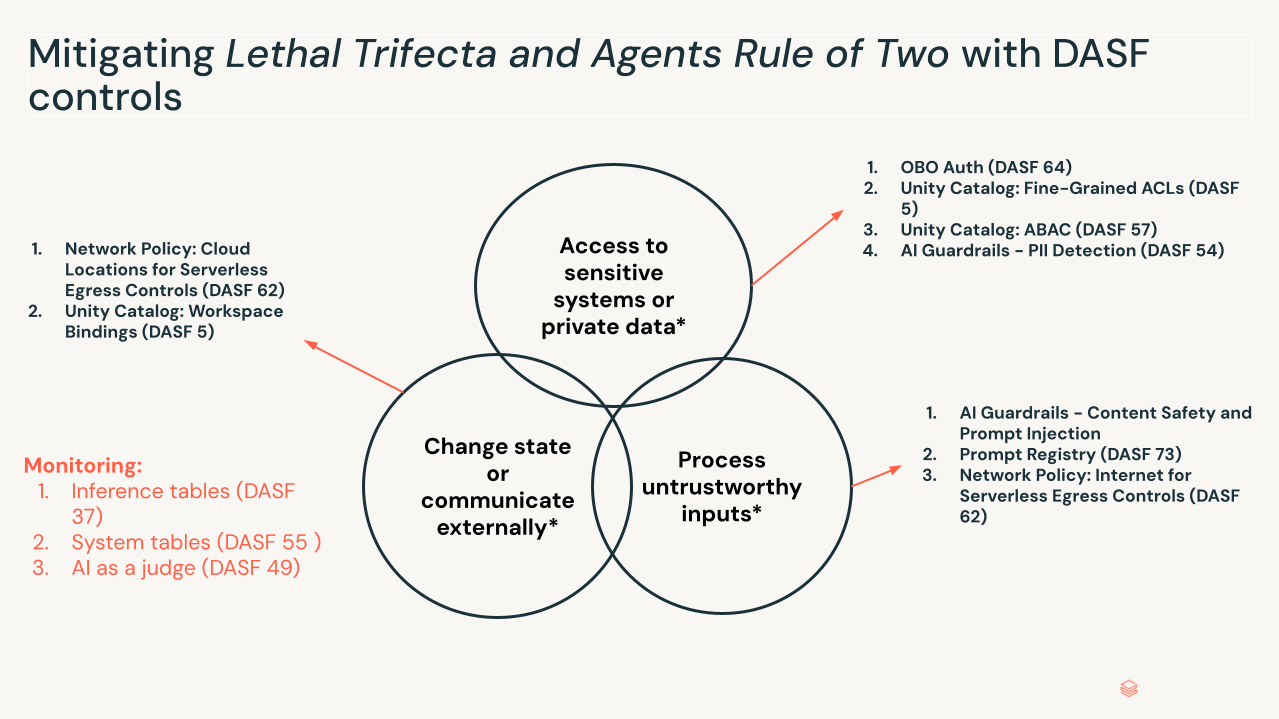
- 민감한 시�스템 또는 개인 데이터에 대한 액세스: 에이전트는 개인 또는 제한된 데이터에 액세스할 수 있습니다.
- 신뢰할 수 없는 입력 처리: 에이전트는 신뢰 경계 외부의 데이터(사용자 프롬프트, 외부 웹사이트, 수신 이메일)를 처리합니다.
- 상태 변경 또는 외부 통신: 에이전트는 도구 또는 MCP 연결을 통해 상태를 수정할 수 있습니다(이메일 보내기, SQL 실행, 코드 수정).
이 세 가지가 모두 충족되면 신뢰할 수 없는 데이터에 포함된 간접 프롬프트 주입은 에이전트의 전체 기능 세트를 납치하여, 승인된 작업을 악의적인 의도로 수행하는 "혼란스러운 대리인(confused deputy)"으로 만들 수 있습니다. 권한을 축소하거나, 인간 검토 단계를 추가하거나, 도구 선택 전에 의도를 검증하거나, 공격 체인을 끊음으로써 단일 요소를 제거하십시오.
확장이 구성되는 방식
35가지 새로운 위험과 6가지 제어는 에이전트가 실제로 작동하는 방식을 매핑하는 세 가지 하위 구성 요소 주위에 구성됩니다:
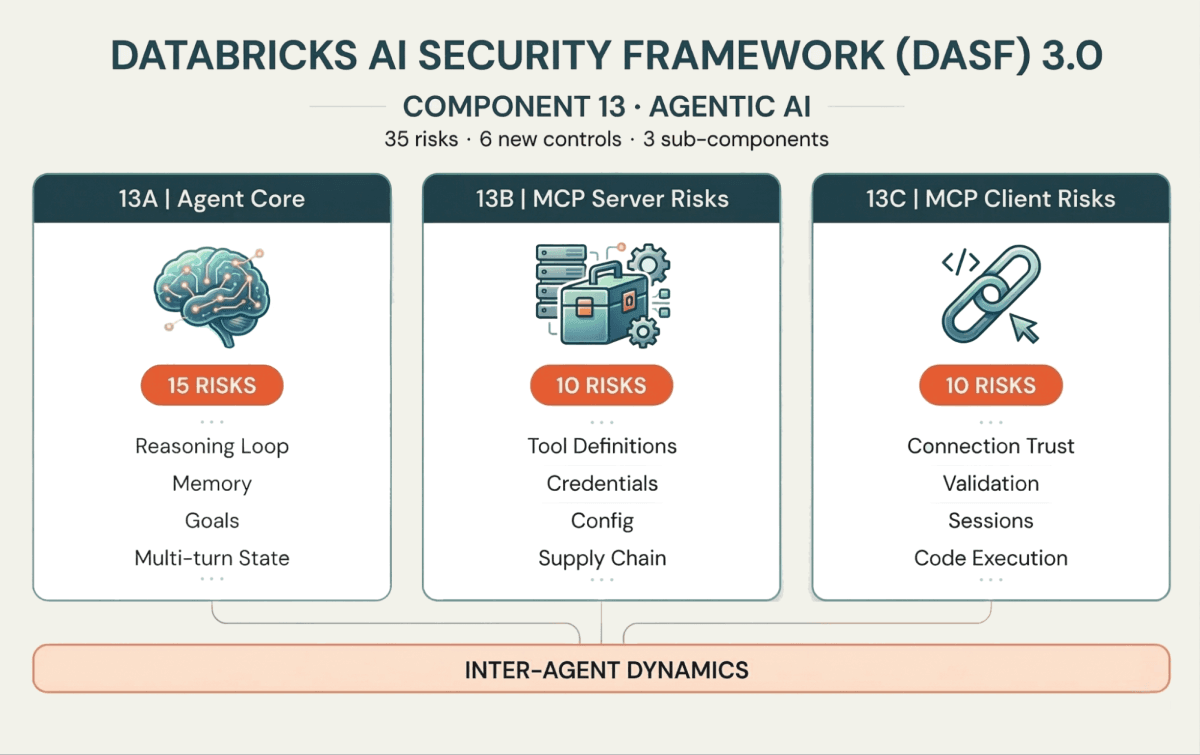
13A: 에이전트 코어 (두뇌 및 메모리)
이러한 위험은 에이전트의 추론 루프를 대상으로 합니다. 메모리 오염(Memory Poisoning, 위험 13.1)은 현재 또는 미래의 결정을 변경하는 잘못된 컨텍스트를 주입합니다. 의도 파괴 및 목표 조작(Intent Breaking & Goal Manipulation, 위험 13.6)은 에이전트가 목표에서 벗어나도록 강요합니다. 에이전트는 다중 �턴 루프에서 작동하므로, 연쇄 환각 공격(Cascading Hallucination Attacks, 위험 13.5)은 반복 과정에서 사소한 오류를 파괴적인 행동으로 누적시킬 수 있습니다.
13B: MCP 서버 위험 (도구 인터페이스)
에이전트는 도구를 통해 외부 시스템과 상호 작용하며, 이는 모델 컨텍스트 프로토콜(MCP)을 통해 점점 더 표준화되고 있습니다. 서버 측에서는 공격자가 도구 오염(Tool Poisoning, 위험 13.18)을 배포하거나(도구 정의에 악성 동작 주입) 도구 설명 내에서 프롬프트 주입(Prompt Injection, 위험 13.16)을 악용하여 보안 제어를 우회할 수 있습니다.
13C: MCP 클라이언트 위험 (연결 계층)
클라이언트 측에서 에이전트가 악성 서버(Malicious Server, 위험 13.26)에 연결하거나 서버 응답을 검증하지 못하면 클라이언트 측 코드 실행(Client-Side Code Execution, 위험 13.32) 또는 데이터 유출(Data Leakage, 위험 13.30)의 위험이 있습니다. MCP 채택이 증가함에 따라 클라이언트-서버 경계를 보호하는 것은 에이전트의 추론을 보호하는 것만큼 중요합니다.
에이전트 간 역학
에이전트는 점점 더 다른 에이전트와 통신하게 될 것입니다. 이는 에이전트 통신 오염(Agent Communication Poisoning, 위험 13.12) 및 다중 에이전트 시스템에서의 악성 에이전트(Rogue Agents in Multi-Agent Systems, 위험 13.13)와 같은 위험을 초래합니다. 이러한 에이전트는 모니터링 경계를 벗어나 작동하며, 이는 규모가 커질수록 문제가 증폭됩니다.
AI 에이전트 및 자율 시스템 보안을 위한 제어
DASF는 항상 심층 방어에 관한 것이었습니다. 하지만 AI 시스템이 조치를 취할 수 있을 때, 읽기 전용 액�세스 제어만으로는 충분하지 않습니다. 새로운 제어는 이를 직접적으로 다룹니다:
- 도구에 대한 최소 권한(DASF 5, DASF 57, DASF 64): 에이전트는 즉각적인 작업에 맞춰진 세분화된 권한이 필요하며, RBAC 및 ABAC가 인간의 권한을 제한하는 것과 동일한 방식으로 잠재적 피해 범위를 제한합니다. 에이전트가 HR Metrics Tool을 호출할 수 있다고 해서 판매 쿼리에 응답할 때도 그래야 하는 것은 아닙니다.
- 인간 참여 감독(Human-in-the-loop oversight, DASF 66): 중요한 작업의 경우, 도구 실행 전에 인간의 검증이 필요합니다. 이 제어 설계는 승인 피로를 고려합니다. 검토자를 압도하면 새로운 취약점을 만든 것이지 해결한 것이 아닙니다.
- 샌드박싱 및 격리(Sandboxing and isolation, DASF 34, DASF 62): 에이전트 생성 코드는 임시적이고 격리된 환경에서 실행됩니다. 에이전트가 스크립트를 작성하고 실행하기로 결정하더라도, 해당 실행은 광범위한 시스템 및 알 수 없는 대상에 대한 아웃바운드 연결에 액세스해서는 안 됩니다.
- AI 게이트웨이 및 가드레일(AI Gateway and Guardrails, DASF 54): 에이전트는 에이전트가 부적절한 데이터를 노출하도록 조작되는 시나리오로부터 보호받아야 합니다. 게이트웨이 및 가드레일을 통한 에이전트의 상호 작용(모니터링, 안전 필터링, PII 감지와 같은)은 적용되어야 합니다. 이러한 가드레일은 에이전트의 입력 또는 출력(또는 둘 다)에 적용될 수 있습니다. 또한 에이전트가 실제로 반환하는 내용을 모니터링하는 것도 똑같이 중요합니다.
- 사고의 관찰 가능성(Observability of thought, DASF 65): 표준 로깅은 무슨 일이 일어났는지 알려줍니다. 에이전트 추적은 왜 그랬는지, 즉 계획 단계, 도구 선택 추론, 행동으로 이어진 사고 과정을 캡처합니다. 이것 없이는 에이전트의 결정을 감사하거나 추론이 손상되었는지 감지할 수 없습니다.
Databricks 고객의 경우, 이 요약본은 에이전트 데이터 액세스를 위한 Unity Catalog 거버넌스, Agent Bricks Framework, AI Gateway 가드레일, AI Search 보안 설정을 포함한 플랫폼 기능에 이러한 제어를 매핑합니다.
커뮤니티와 함께 구축
이 확장은 Atlassian, Experian, ComplyLeft의 팀을 포함하여 Databricks 및 보안 커뮤니티 전반의 검토자 및 기여자의 피드백을 반영합니다. 또한 MITRE ATLAS, OWASP, NIST 및 Cloud Security Alliance의 작업에 크게 의존했습니다. 업데이트된 요약본은 97가지 위험과 73가지 제어를 이러한 산업 표준에 매핑합니다.
시작하기
35가지 새로운 에이전트 AI 위험 및 6가지 새로운 제어에 대한 전체 내용을 보려면 DASF Agentic AI Extension 백서를 다운로드하고, 이제 원래 DASF와 함께 에이전트 AI 위험 및 제어를 매핑하는 업데이트된 요약본(Google Sheet, Excel)을 받으세요. 이러한 리소스를 사용하여 다음을 수행하세요:
- 에이전트 AI 위험 모델에 대한 현재 에이전트 아키텍처를 평가합니다.
- MCP 서버 및 클라이언트를 포함한 도구 생태계를 식별된 위협 벡터에 매핑합니다.
- 에이전트가 안전하고 관리되는 경계 내에서 작동하도록 권장 제어를 구현합니다.
더 깊은 맥락을 보려면 전체 DASF 백서를 읽고 플랫폼에서 이러한 제어가 어떻게 작동하는지 알아보려면 Agent Bricks Framework 설명서를 살펴보세요.
피드백이 있으면 Databricks 계정 팀에 문의하거나 dasf@databricks.com으로 이메일을 보내주세요. 이 프레임워크는 우리만큼 커뮤니티에 속합니다.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.