Databricks 자산 번들에 대한 Python 지원 발표, 배포 간소화
Python에서 파이프라인 개발의 전체 수명주기를 정의하고 배포하십시오
작성자: Gleb Kanterov, Lennart Kats, Julia Crawford , Saad Ansari
- 더 큰 유연성, 재사용성, 개발자 친화적인 워크플로우를 위해 Python에서 Databricks Asset Bundles를 정의합니다.
- Python 함수를 사용하여 태그, 알림, 또는 기본 클러스터와 같은 설정을 자동으로 추가하는 작업 및 파이프라인 정의를 사용자 정의하세요.
- 새로운 "코드로 보기" 기능을 사용하여 기존 작업을 Python 또는 YAML로 보고, 작업 정의를 쉽게 검사, 편집, 재사용할 수 있습니다.
Databricks Asset Bundles의 Python 지원 이 공개 미리보기에서 이제 사용 가능하다는 것을 기쁘게 발표합니다! Databricks 사용자들은 오래 전부터 Python에서 파이프라인 로직을 작성할 수 있었습니다. 이번 릴리스를 통해 파이프라인 개발의 전체 수명 주기-오케스트레이션 및 스케줄링을 포함하여-이제 Python에서 완전히 정의하고 배포할 수 있습니다. Databricks 자산 번들(또는 "번들")은 파이프라인을 정의하고, 버전을 관리하고, 환경 간에 배포하는 구조화된 코드 중심 접근 방식을 제공합니다. 기본 Python 지원은 유연성을 향상시키고, 재사용성을 촉진하며, Python을 선호하거나 여러 환경에서 동적 구성이 필요한 팀의 개발 경험을 향상시킵니다.
대규모로 작업 및 파이프라인 배포 표준화
수십 개 또는 수백 개의 파이프라인을 관리하는 데이터 엔지니어링 팀들은 일관된 배포 방식을 유지하는 데 종종 어려움을 겪습니다. 운영 확장은 버전 제어, 사전 생산 검증, 프로젝트 간 반복적인 구성 제거의 필요성을 야기합니다. 전통적으로 이 워크플로우는 큰 YAML 파일을 유지하거나 Databricks UI를 통해 수동 업데이트를 수행하는 것을 필요로 했습니다.
Python은 작업 및 파이프라인의 프로그래밍 구성을 가능하게 함으로써 이 과정을 개선합니다. 팀들은 수동으로 정적인 YAML 파일을 편집하는 대신 Python에서 한 번 로직을 정의하여, 예를 들어 기본 클러스터를 설정하거나 태그를 적용하거나 명명 규칙을 강제하고, 이를 여러 배포에 동적으로 적용할 수 있습니다. 이로 인해 중복이 줄어들고, 유지 관리성이 향상되며, 개발자들이 배포 정의를 기존 Python 기반 워크플로우 및 CI/CD 파이프라인에 더 자연스럽게 통합할 수 있습니다.
"선언적 설정과 기본 Databricks 통합은 배포를 간단하고 신뢰할 수 있게 만듭니다. Mutators는 눈에 띄는 기능으로, 자동 태깅이나 기본값 설정과 같이 프로그래밍 방식으로 작업을 사용자 정의할 수 있게 해줍니다. DABs가 배포의 표준이 되는 것을 기대하고 있습니다." —톰 포타시, DoubleVerify의 소프트웨어 엔지니어링 매니저
Python을 이용한 Databricks Asset Bundles 배포
Python 지원의 추가로 Databricks Asset Bundles 의 배포 과정이 간소화되었습니다. 이제 작업과 파이프라인은 Python에서 완전히 정의, 사용자 정의 및 관리할 수 있습니다. Bundles와의 CI/CD 통합은 항상 가능했지만, Python을 사용하면 복잡한 구성을 작성하는 것을 단순화하고, 중복을 줄이며, 팀이 다른 환경에서 프로그래밍 방식으로 최상의 관행을 표준화할 수 있게 해줍니다.
작업에서 코드로 보기 기능을 사용하면 프로젝트에 직접 복사-붙여넣기 할 수도 있습니다(자세한 내용은 여기에서 확인하세요):
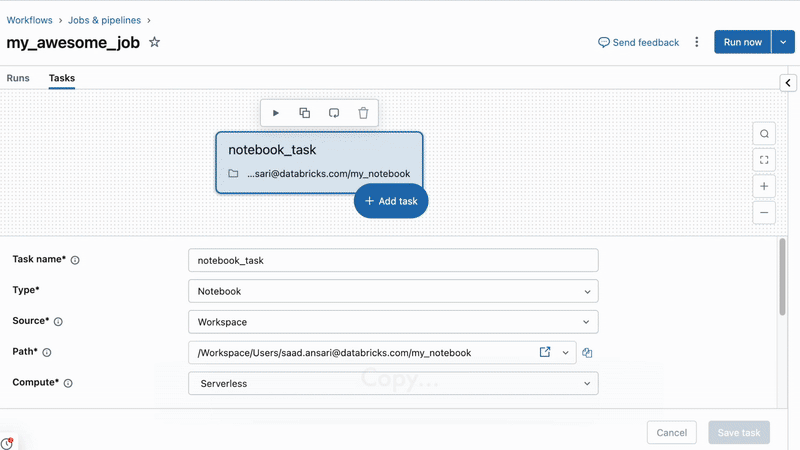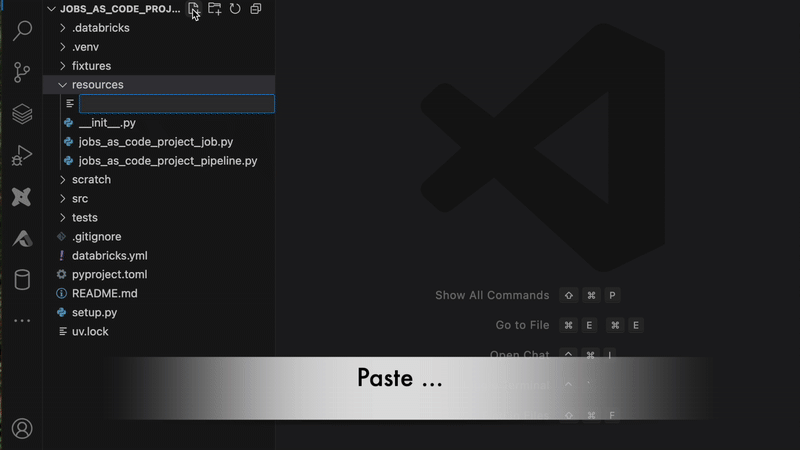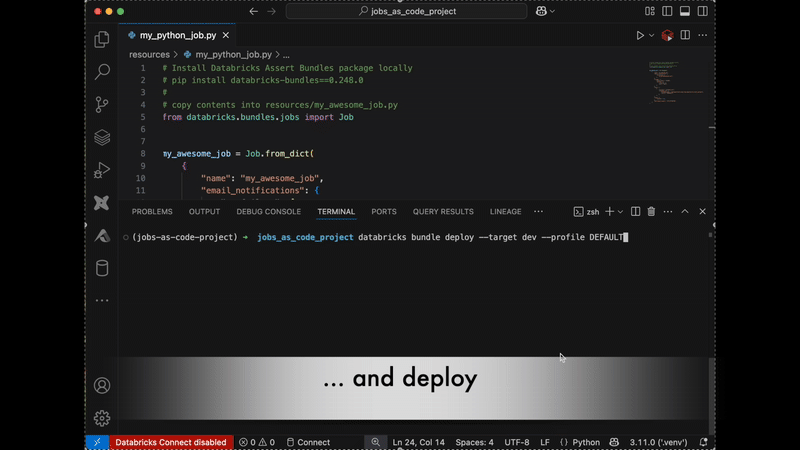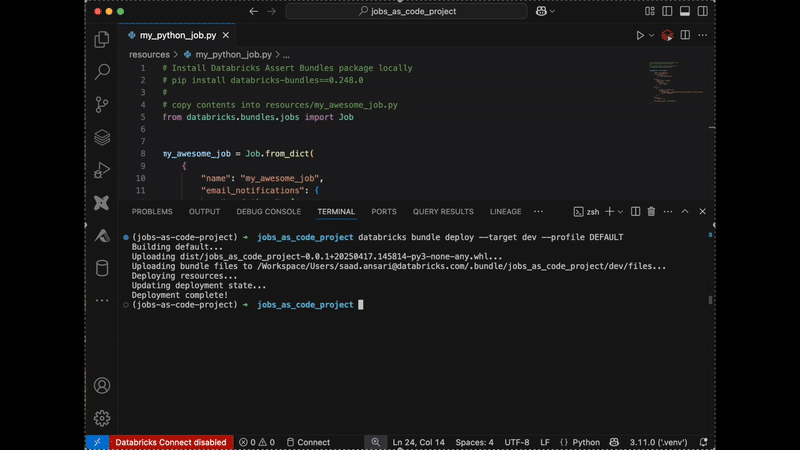
고급 기능: 프로그래밍 작업 생성 및 사용자 정의
이 릴리스의 일부로, 메타데이터를 사용하여 프로그래밍 방식으로 작업을 생성하는 데 사용되는 load_resources 함수를 소개합니다. Databricks CLI는 배포 중에 이 Python 함수를 호출하여 추가 작업 및 파이프라인을 로드합니다(자세한 내용은 여기에서 확인하세요).
또 다른 유용한 기능은 mutator 패턴으로, 파이프라인 구성을 검증하고 작업 정의를 동적으로 업데이트할 수 있습니다. mutators를 사용하면 반복적인 YAML 또는 Python 정의 없이 기본 알림이나 클러스터 구성과 같은 공통 설정을 적용할 수 있습니다:
mutators에 대해 더 알아보려면 여기를 클릭하세요.
시작하기
오늘날 Databricks Asset Bundles에 대한 Python 지원을 살펴보세요! Databricks Asset Bundles 및 Databricks Asset Bundles에 대한 Python 지원에 대한 문서를 탐색하세요. 이 강력한 새로운 기능으로 어떤 것을 만들어낼지 기대가 됩니다. 우리는 여러분의 피드백을 중요하게 생각하므로, 경험과 제안을 공유해주세요!
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최��신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.