레이크하우스 중심 아키텍처에 최적화된 트랜잭션 엔진 — Databricks Lakebase x Backstage
개발 주기 분기 (1부)
작성자: Cameron Casher , Kevin Hartman
30년 동안 운영 데이터베이스와 분석 데이터베이스는 ETL 작업으로 연결된 두 개의 아티팩트, 두 개의 거버넌스 평면, 두 개의 예산, 그리고 보통 두 개의 온콜 로테이션이었습니다. 이 분할은 설계 선택이 아니라 물리적 제약이었습니다. OLTP와 OLAP는 실제로 다른 저장 레이아웃, 다른 컴퓨팅 프로필, 다른 실패 모드를 가지고 있었기 때문에 두 개의 플랫폼을 구축하고 나중에 연결했습니다.
이 제약이 사라지고 있습니다. 스토리지가 공유되고, 컴퓨팅이 서버리스이며 워크로드별로 격리되고, 거버넌스가 카탈로그 계층에 있을 때 "운영"과 "분석"은 더 이상 아키텍처 범주가 아니라 동일한 기반에 대한 액세스 패턴이 됩니다.
이것이 실제로 사실인지 확인하기 위해 Spotify의 악명 높은 상태 중심 내부 개발자 포털인 Backstage를 표준 Postgres 데이터베이스에서 분리하여 Databricks Lakebase에 연결했습니다. 이 3부작 시리즈에서는 배포 주기(1부), 거버넌스(2부), FinOps(3부)가 운영 앱과 데이터 플랫폼 간의 벽을 허물 때 어떻게 되는지 살펴봅니다.
설정: Backstage를 Lakebase에 연결
Lakebase는 Databricks 플랫폼 내부에 있는 서버리스 Postgres 표면(내부적으로 Neon의 아키텍처 활용)을 노출합니다. 와이어 프로토콜 Postgres를 사용하므로 Backstage는 RDS와 통신하지 않는다는 �것을 알거나 신경 쓰지 않습니다.
연결하려면 app-config.yaml을 Lakebase로 가리키고 Backstage의 기본 인메모리 검색을 PgSearchEngine으로 바꿔야 했습니다. 즉각적인 장애물 하나: Lakebase는 OAuth JWT를 예상하는 대신 기존 Databricks Personal Access Token을 거부합니다. CLI는 특정 엔드포인트에 대한 범위가 지정된 짧은 수명의 JWT를 생성하는 databricks postgres generate-database-credential을 제공하며, 이는 앱 및 CI에 대한 의도된 접근 방식입니다. 이 POC의 경우, 토큰 만료를 처리하기 위해 해당 명령을 경량 cron 스크립트로 래핑하여 50분마다 .env 파일의 DATABRICKS_TOKEN을 다시 작성했습니다.
인증이 해결되자 Knex 마이그레이션이 깔끔하게 실행되었고 포털이 라이브 상태가 되었습니다.
브랜칭은 데이터베이스 개발 주기를 변경합니다
기존 Postgres의 가장 과소평가된 점은 기능 세트가 아니라 이를 소유한 팀에 강요하는 템포입니다.
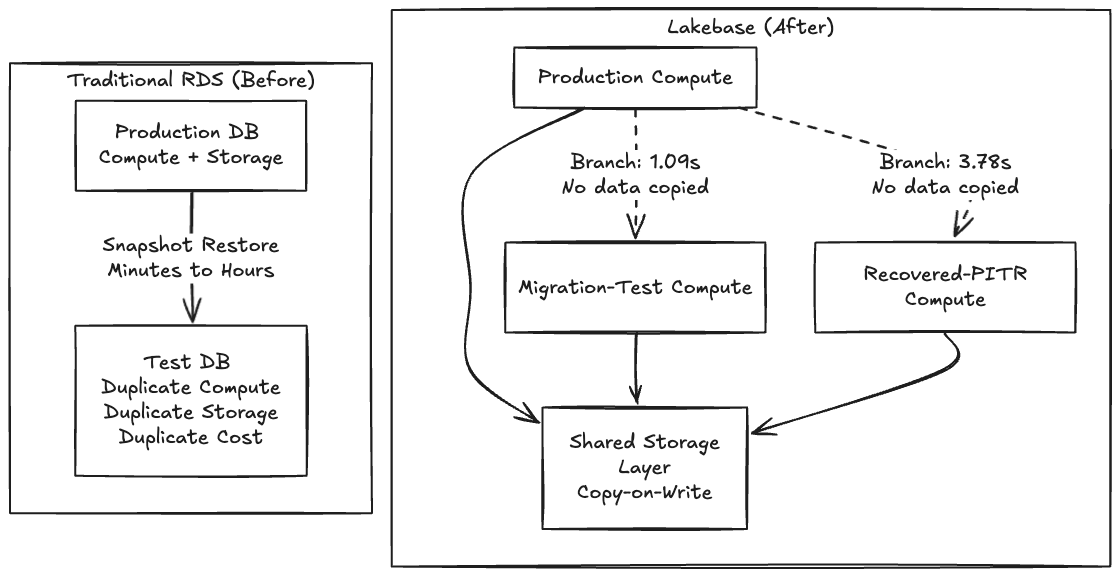
Thoughtworks는 Technology Radar를 통해 Backstage를 IDP 기반으로 일관되게 지지해 왔으므로, 이 도구에 매우 익숙한 것 외에도 이 POC에 Backstage를 선택한 이유는 스키마 마이그레이션이 악명 높게 불안정하여 Lakebase 통합을 테스트할 완벽한 기회처럼 보였기 때문입니다. 기존 RDS에서는 위험한 마이그레이션을 테스트한다는 것은 스냅샷을 병렬 인스턴스로 복원하기 위해 몇 분 또는 몇 시간을 기다려야 함을 의미합니다. 복사본을 만드는 것은 느리고 비용이 많이 들기 때문에 팀은 단순히 테��스트하지 않습니다. 그들은 손가락을 교차하고 유지 관리 시간 동안 마이그레이션을 실행합니다.
복사본을 만드는 것이 무료가 되면 "이 변경 사항이 실행하기에 충분히 안전한가?"라고 묻는 것을 멈추고 "먼저 어느 프로덕션 포크를 시도해 볼까?"라고 묻기 시작합니다.
Lakebase는 쓰기 시 복사 아키텍처를 사용하여 스토리지와 컴퓨팅을 분리하므로, 브랜치를 생성하는 것은 데이터를 복사하는 것이 아니라 동일한 기본 페이지를 가리키는 포인터를 생성하고 쓰기 시에만 분기됩니다. 이것이 작업이 즉시 완료되는 이유입니다.
문서에서 명확하게 설명하지 않는 한 가지 문제점: 요청 본문은 모든 것을 spec 객체 안에 중첩해야 하며,ttl,expire_time, 또는no_expiry를 지정해야 합니다. 그렇지 않으면 API는 "만료를 지정해야 합니다."라고 반환합니다.
컨트롤 플레인은 즉시 이를 인식했습니다. 약 63MB의 Backstage 카탈로그의 실제 데이터 플레인 복사본이 1.09초 �만에 완료되었습니다.
시점 복구: 실행 취소 버튼
브랜칭과 시점 복구(PITR)는 본질적으로 동일한 기본 기능입니다. 브랜칭은source_branch_time = now을 사용한 PITR일 뿐입니다. 실제 삭제된 데이터에 대한 복구를 테스트하기 위해final_entities 테이블을 삭제하여 개수를 32에서 0으로 줄였습니다.
그런 다음 삭제 직전의 타임스탬프에서 복구 브랜치를 생성했습니다.
총 경과 시간은 3.78초였습니다.
데이터를 확인한 결과 복구된 브랜치에는 32개의 엔티티가 모두 복원되었음을 확인했습니다. 프로덕션은 여전히 0이었으며, 삭제가 실제였고 브랜치가 완전히 격리되었음을 확인했습니다. 주목할 점은 22:56:02Z를 요청했지만 Lakebase는 WAL 레코드에 가장 가까운 시점으로 12초 전인 22:55:50Z로 스냅했다는 것입니다. 이 WAL 수준의 세분성은 시간 민감한 복구 워크플로에 중요한 주의 사항이지만, 사고 주기는 여전히 1분 미만으로 실행되었습니다.
데이터베이스 상태가 2TB EBS 볼륨이 아닌 저렴하고 복제 가능한 아티팩트가 되면, 모든 위험한 작업에는 드라이 실행이 있고 모든 사고에는 실행 취소가 있습니다.
인프라 기능에서 개발자 워크플로로
위에서 보았듯이, 데이터베이스 브랜칭이 작동한다는 것을 증명합니다. 1초 복제, 4초 복구, 그리고 차이를 모르는 실제 애플리케이션. 하지만 "데이터베이스가 브랜칭할 수 있다"와 "내 팀이 코드를 브랜�칭하는 것처럼 자연스럽게 데이터베이스를 브랜칭한다" 사이에는 간극이 있습니다. 그 간극을 좁히는 곳에서 개발자 생산성에 대한 막대한 영향이 객관적인 이득으로 실현될 수 있습니다.
우리는 지난 몇 달 동안 개발팀과 협력하여 특정 질문에 답해 왔습니다. 데이터베이스 브랜칭이 투명해지면 팀의 속도에 어떤 영향을 미칠까요? 즉, 실행하는 CLI 명령이 아니라 편집기에서 이미 작업하는 방식의 일부로 자동으로 발생하는 것입니다. 이를 증명하기 위해 VS Code/Cursor 확장 프로그램을 개발 중이며, git 및 데이터베이스 브랜치를 자동으로 동기화합니다. 하지만 도구는 이를 가능하게 하는 것보다 부차적입니다.
브랜칭이 가능하게 하는 것
우리가 경험한 팀들 전반에 걸쳐, 데이터베이스 브랜칭이 없는 스프린트 주기는 다음과 같습니다.
- 기능 개발을 위한 git 브랜치 생성
- 테스트 목적으로 모든 데이터베이스 인터페이스에 대한 모의 객체 작성 (MockUserRepository, MockOrderService...)
- 모의 또는 인메모리 데이터베이스(H2, SQLite)를 사용하여 단위 테스트 작성
- PR 제출, 검토 및 코드 병합
- 공유 스테이징 환경에 배포
- 스키마 마이그레이션이 실제 데이터에서 작동하지 않거나 데이터 크기가 문제가 되는 것을 발견
- 스키마 마이그레이션 수정, 재배포, 반복
데이터베이스 브랜칭 기능을 사용하면 개발자의 기능 개발 주기가 다음과 같이 변경됩니다.
- Git 브랜치 생�성 – Lakebase 데이터베이스 브랜치는 1초 이내에 자동으로 생성될 수 있습니다.
- IDE가 실제 브랜치 데이터베이스에 즉시 연결됩니다.
- 첫 줄의 코드부터 실제 라이브 데이터베이스를 대상으로 코드를 작성하고 마이그레이션을 실행합니다.
- 실제 데이터베이스를 대상으로 통합 테스트를 작성합니다. 데이터베이스 모의 객체가 아닙니다.
- 데이터베이스 변경 사항을 롤백하는 것이 간단하므로 여러 솔루션을 실험할 수 있습니다.
- Push 및 PR 열기 – CI는 자체 데이터베이스 브랜치를 생성하고 코드와 스키마를 모두 검증하며 스키마 차이를 게시합니다.
- QA 팀원은 파괴적인 테스트를 위해 자체 데이터베이스 브랜치를 얻을 수 있습니다. 몇 초 안에 재설정할 수 있습니다.
- 병합 – 병합되면 CD 파이프라인은 UAT 및 프로덕션과 같은 상위 환경을 마이그레이션하고 모든 브랜치(코드 및 데이터)를 정리할 수 있습니다.
모의 객체가 사라집니다. 스테이징 충돌이 사라집니다. "내 컴퓨터에서는 작동하지만 스테이징에서는 실패하는" 문제가 사라지고 개발자는 여러 솔루션을 시도할 수 있는 라이브 데이터베이스를 얻게 됩니다. 배포 시 발견되던 데이터베이스 변경 사항은 이제 개발 중에 발견되므로 수정 비용이 저렴합니다. 성능 테스트를 위한 즉각적인 브랜치, 기능 테스트를 위한 일회용 및 격리된 브랜치, UAT 이해 관계자를 위한 실행 브랜치가 간단해집니다.
저희 경험에 따르면 여러 파트너 팀에서 이 워크플로를 평가한 결과, 모��의 객체는 테스트 코드의 20-30%를 차지합니다. 이는 테스트 커버리지가 아니라 테스트 인프라스트럭처입니다. 시간이 지남에 따라 프로덕션 동작과 달라져 잘못된 자신감을 생성하는 인프라스트럭처입니다. 프로덕션에 동등한 데이터베이스를 브랜칭하는 데 비용이 들지 않으면 모의 객체 사용이 비싼 선택이 됩니다.
이제 질문은 스프린트의 얼마만큼을 더 이상 존재하지 않는 제약 조건에 대한 해결책을 찾는 데 소비하고 있느냐는 것입니다.
이 시리즈의 파트 2에서는 이 운영 데이터베이스가 Databricks의 통합 거버넌스 계층인 Unity Catalog에 직접 통합될 때 보안 및 규정 준수에 어떤 영향을 미치는지 살펴보겠습니다.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.