델타 유니폼: 레이크하우스 상호운용성을 위한 범용 포맷
Delta UniForm: a universal format for lakehouse interoperability
작성자: 빌랄 오베이다트, Sirui Sun, Adam Wasserman, 수잔 피어스, Fred Liu, Ryan Johnson , 히만슈 라자
오픈 데이터 레이크하우스를 도입할 때 데이터에 가장 적합한 포맷을 선택하는 문제에 부딛히게 됩니다. 선택 가능한 포맷에는 Linux Foundation Delta Lake, Apache Iceberg, 그리고 Apache Hudi 등이 있으며, 모두 데이터 민주화와 상호 운용성을 가능하게 하는 훌륭한 저장 포맷입니다. 이러한 포맷 중 어느 것이든 독점적인 형식에 데이터를 저장하는 것보다 낫습니다. 그러나 단일 스토리지 포맷을 표준으로 선택하는 것은 쉽지 않은 일이며, 돌이킬 수 없는 결과에 대한 두려움 때문에 매우 어려운 의사결정 입니다.
델타 유니폼(Delta Lake Universal Format의 약자)은 추가적인 데이터 사본이나 사일로를 만들지 않고도 테이블 형식을 원활하게 통합할 수 있는 쉬운 방법을 제공합니다. 이 블로그에서는 다음 내용을 다룹니다:
- 델타 유니폼과 그 장점에 대한 소개
- 다음을 사용하여 델타 유니폼을 Iceberg 테이블로 읽기
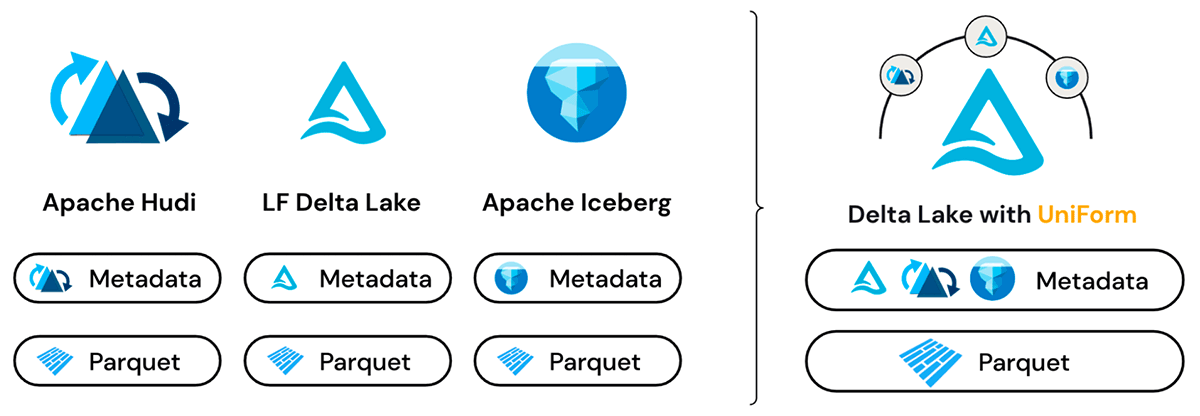
여러 포맷, 단일 데이터
델타 유니폼은 Delta Lake, Iceberg, Hudi가 모두 Apache Parquet 데이터 파일을 기반으로 구축되었다는 공통점을 이용합니다. 세 포맷의 주요 차이점은 메타데이터 레이어에 있으며, 그마저도 약간의 차이가 있을 뿐입니다. 세 가지 포맷의 메타데이터는 모두 동일한 용도로 사용되며 따라서 중복되는 정보 항목들이 많습니다.
델타 유니폼이 출시되기 전에는 오픈 테이블 포맷 간에 데이터 형식을 전환하려면 데이터를 복사 또는 변환해야 했으며, 따라서 데이터의 특정 시�점 뷰만 볼 수 있었습니다. 반면, 델타 유니폼은 포맷에 관계없이 모든 reader에게 데이터의 실시간 뷰를 제공함으로써 상호운용성 요구 사항을 해결하는 더 우아한 방법을 제공합니다.
내부적으로 델타 유니폼은 단일 Parquet 데이터에 대해 Delta Lake와 함께 Iceberg 및 Hudi의 메타데이터를 자동으로 생성하는 방식으로 동작합니다. 따라서 각 데이터 워크로드에 가장 적합한 도구를 사용할 수 있으며, 단일 데이터 소스에서 세 가지 서로 다른 에코시스템이 완벽한 상호 운용성을 가지고 동작할 수 있습니다.
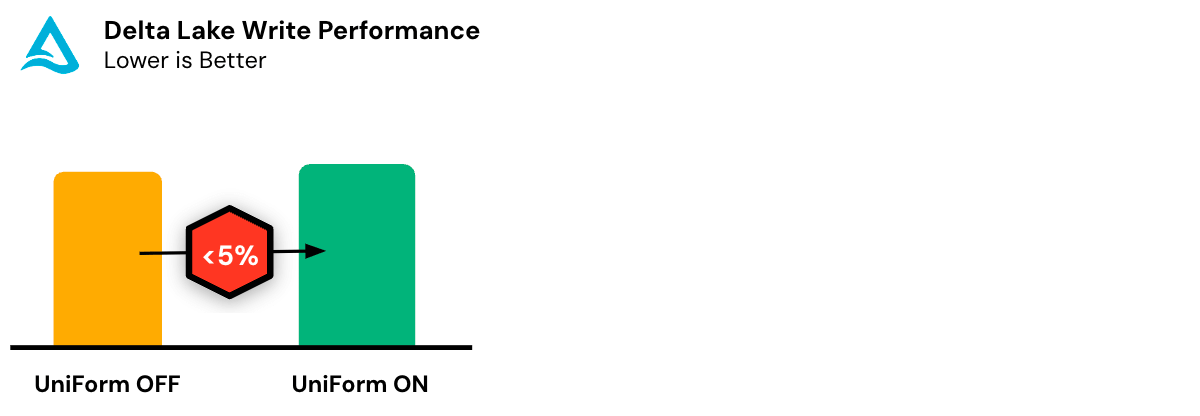
빠른 셋업, 최소 오버헤드
델타 유니폼은 설정이 매우 쉬우며, 일단 활성화되면 자동으로 매끄럽게 작동합니다.
먼저 Iceberg 메타데이터를 생성하기 위해 델타 유니폼 테이블을 만들어 보겠습니다:
델타 유니폼 테이블을 사용하면 테이블 생성 시 추가 포맷(위 경우 Iceberg)에 대한 메타데이터가 자동으로 생성되고 테이블이 수정될 때마다 업데이트됩니다. 즉, 테이블 형식을 변환하기 위해 수동으로 새로 고침 명령을 내리거나 불필요한 컴퓨팅 작업을 실행할 필요가 없습니다. 예를 들어 이 테이블에 행을 작성해 보겠습니다:
이 명령은 Delta Lake 커밋을 트리거하고, 이 커밋은 이 테이블에 대한 Iceberg 메타데이터를 자동으로 비동기 방식으로 생성합니다. 이렇게 함으로써 델타 유니폼은 데이터 파이프라인이 중단되지 않도록 보장하여 모��든 reader가 최신 정보에 원활하게 액세스할 수 있도록 지원합니다.
델타 유니폼은 성능과 리소스에 미치는 오버헤드가 미미하여 컴퓨팅 리소스을 최적으로 활용할 수 있습니다. 페타바이트 규모의 테이블에서도 일반적으로 메타데이터는 데이터 파일 크기의 극히 일부에 불과합니다. 또한, 델타 유니폼은 이전 커밋 이후의 변경 사항만 담도록 메타데이터를 증분 방식으로 생성할 수 있습니다.
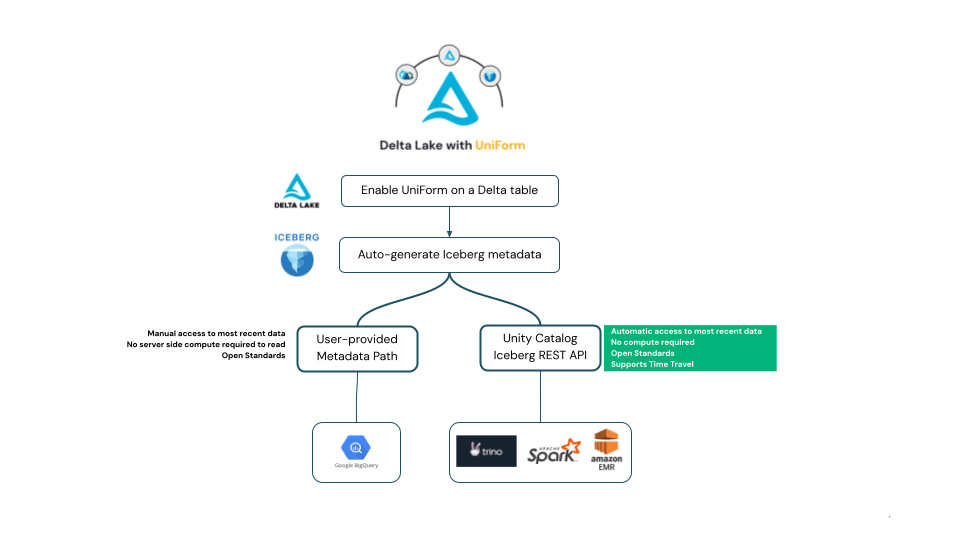
델타 유니폼 데이터를 Iceberg처럼 읽기
델타 유니폼은 Apache Iceberg 스펙에 따라 Iceberg 메타데이터를 생성하므로, 데이터가 델타 유니폼 테이블에 기록되면 오픈소스 Iceberg 스펙을 따르는 모든 Iceberg 에코시스템 클라이언트에서 해당 테이블을 Iceberg로 읽을 수 있습니다.
Iceberg 스펙에 따르면, reader 클라이언트는 어떤 Iceberg 메타데이터가 가장 최신의 최신 버전의 Iceberg 테이블을 나타내는지 파악해야 합니다. Iceberg 에코시스템에서 클라이언트들은 이 문제에 대해 두 가지 다른 접근 방식을 취하고 있는데, 델타 유니폼은 이 두 가지 접근 방식을 모두 지원합니다. 두 방식의 차이점을 먼저 알아본 후, 다음 섹션에서 사용 예제를 살펴 보겠습니다.
일부 Iceberg reader에서는 Iceberg 테이블의 최신 스냅샷을 담은 메타데이터 파일의 경로를 사용자가 제공해야 합니다. 이 방식은 테이블이 변경될 때마다 사용자가 업데이트된 메타데이터 파일 경로를 제공해야 하므로 번거로울 수 있습니다.
이에 대한 대안으로, Iceberg 커뮤니티에서는 REST catalog API 사용을 권장하고 있습니다. 클라이언트는 카탈로그와 통신하여 테이블의 최신 상태를 가져오므로 사용자는 수동으로 갱신하거나 메타데이터 경로에 대해 걱정할 필요 없이 Iceberg 테이블의 최신 상태를 읽을 수 있습니다.
이제 Unity Catalog는 Apache Iceberg 스펙을 따르는 개방형 Iceberg Catalog REST API를 제공합니다. 이는 개방형 API를 지원하려는 Unity Catalog의 노력의 일환으로, Unity Catalog의 HMS API 지원을 기반으로 합니다. Unity Catalog 의 Iceberg REST API는 데이터브릭스 컴퓨팅 비용 없이 Iceberg 포맷의 델타 유니폼 테이블에 대한 개방형 액세스를 제공하며, 최신 데이터에 액세스할 수 있도록 상호 운용성과 자동 새로 고침을 제공합니다. 부수적으로, 다른 카탈로그들이 Unity Catalog에 페더레이션하여 델타 유니폼 테이블을 지원할 수 있게 됩니다.
Apache Iceberg 클라이언트 라이브러리에는 Iceberg REST API 카탈로그와 인터페이스할 수 있는 기능이 기본 탑재되어 있으므로 Apache Iceberg 표준을 완벽하게 구현하고 카탈로그 엔드포인트 구성을 지원하는 모든 클라이언트는 Unity Catalog의 Iceberg REST API 카탈로그에 쉽게 액세스하여 테이블에 대한 최신 메타데이터를 �검색할 수 있습니다. 이렇게 하면 테이블 메타데이터를 따로 관리할 필요가 없습니다.
다음 섹션에서는 메타데이터 경로 방식과 Iceberg REST Catalog API 접근 방식 두가지에 대해 델타 유니폼이 어떻게 지원하는지 예시를 살펴보겠습니다.
사용 예: 메타데이터 경로 방식으로 BigQuery에서 Delta Lake를 Iceberg로 읽기
기존 카탈로그에서 Iceberg 데이터를 읽을 때, BigQuery에서는 다음과 같이 최신 Iceberg 스냅샷(BigQuery 문서)을 담은 JSON 파일 경로를 제공해야 합니다:
In BigQuery:
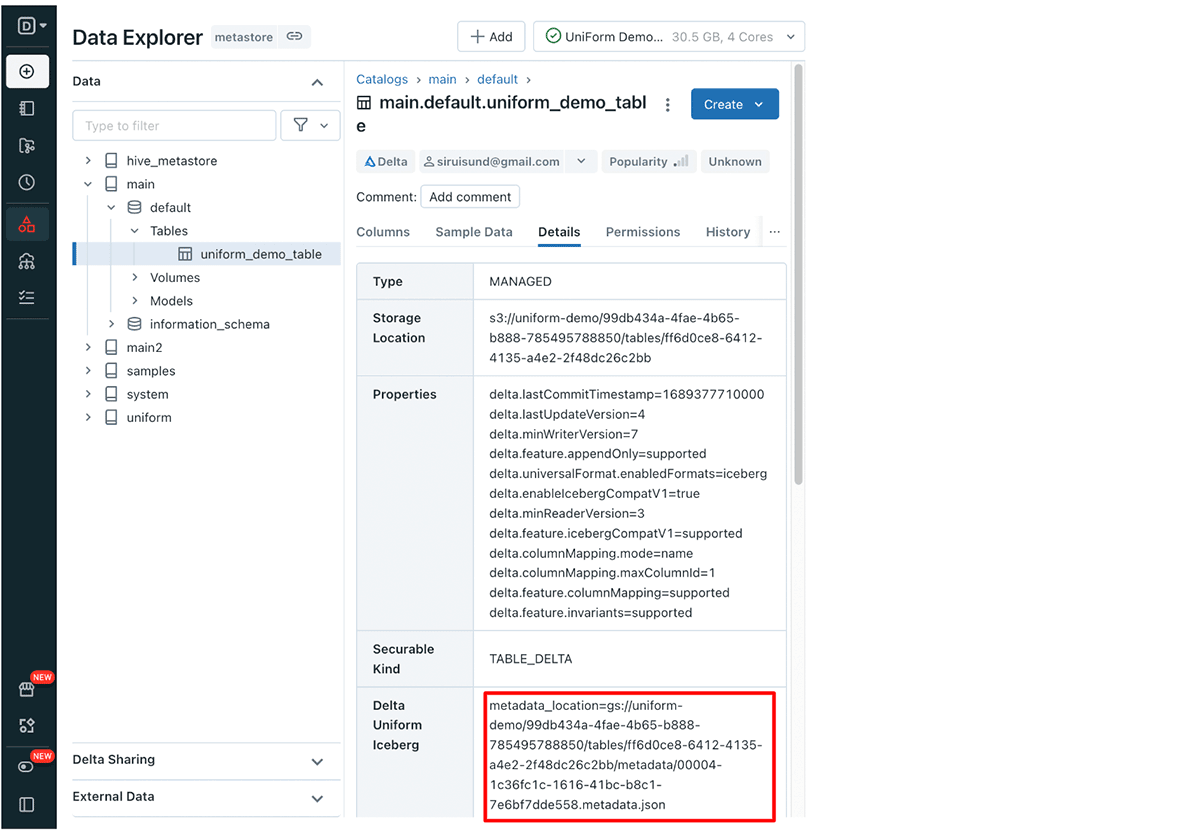
Unity Catalog와 함께 델타 유니폼을 사용하면 필요한 Iceberg 메타데이터 파일 경로를 쉽게 찾을 수 있습니다. Unity Catalog는 이 경로를 포함하여 다양한 델타 레이크 테이블 속성를 제공합니다. UI 또는 API를 통해 델타 유니폼 테이블의 메타데이터 위치를 검색할 수 있습니다.
UI를 통해 델타 유니폼 Iceberg 메타데이터를 가져오기:
데이터브릭스 데이터 탐색기에서 델타 유니폼 테이블로 이동한 다음 세부 정보(Details) 탭을 클릭합니다. 여기에서 메타데이터 경로가 포함된 델타 유니폼 Iceberg 행을 찾을 수 있습니다.
In Databricks:
API를 통해 델타 유니폼 Iceberg 메타데이터 경로를 가져오기:
다음 GET 요청을 통해 델타 유니폼 테이��블의 Iceberg 메타데이터 경로를 검색합니다.
응답의 delta_uniform_iceberg.metadata_location 필드에 최신 Iceberg 스냅샷에 대한 메타데이터 위치가 담겨 있습니다.
위와 같이 UI 또는 API 방법으로 찾아낸 경로를 앞서 설명한 BigQuery 명령에 붙여넣으면, BigQuery가 스냅샷을 Iceberg로 읽습니다.
테이블이 업데이트되는 경우, 최신 데이터를 읽으려면 업데이트된 메타데이터 위치를 BigQuery에 제공해야 합니다. 프로덕션 환경에서는 델타 유니폼 테이블에 쓸 때마다 최신 Iceberg 메타데이터 경로를 BigQuery에 업데이트하는 단계를 수집 파이프라인에 추가해야 합니다. 이 같이 메타데이터 경로 업데이트가 필요한 것은 이 접근 방식의 일반적인 제한 사항으로, 델타 유니폼에 국한된 문제는 아닙니다.
사용 예: REST Catalog API를 통해 Trino에서 Delta Lake를 Iceberg로 읽기
이제 앞서 만든 델타 유니폼 테이블을 Unity Catalog의 Iceberg REST Catalog API를 사용하여 Trino에서 읽어 보겠습니다.
참고: Trino는 델타 테이블을 직접 지원하므로 Trino로 델타 테이블을 읽는 데 유니폼이 필요한 것은 아닙니다. 이 예제는 유니폼이 오픈소스 생태계에서 상호 운용성을 더욱 확장하는 방법을 설명하기 위한 것입니다.
Trino를 셋업한 후 Trino가 Unity Catalog의 Iceberg REST API 카탈로그 엔드포인트를 사용하도록 etc/catalog/iceberg.properties 파일에 Iceberg 속성을 지정할 수 있습니다:
설명:
- UNITY_CATALOG_ICEBERG_URL - Unity 카탈로그의 Iceberg REST API 엔드포인트에 대한 URL로, 다음과 같은 형식입니다: https://{DATABRICKS_WORKSPACE_URL}/api/2.1/unity-catalog/iceberg
- DATABRICKS_WORKSPACE_URL - 웹 브라우저에서 접속하는 데이터브릭스 워크스페이스의 URL로, 다음과 같은 형식입니다: mydatabricksworkspace.cloud.databricks.com/?o=1231231231231231
- PERSONAL_ACCESS_TOKEN - 데이터브릭스 워크스페이스에서 생성할 수 있는 데이터브릭스 개인 액세스 토큰으로, 이 가이드에 따라 생성할 수 있습니다.
속성 파일을 설정한 후 Trino CLI를 실행하여 델타 유니폼 테이블에 Iceberg 쿼리를 실행할 수 있습니다:
Trino는 Apache Iceberg REST Catalog API를 구현하므로 외부 테이블을 만들지 않았고 최신 Iceberg 메타데이터 파일 경로를 제공할 필요도 없었습니다. Trino는 Unity Catalog에서 최신 Iceberg 메타데이터를 자동으로 가져온 다음, 델타 유니폼 테이블에서 최신 데이터를 읽습니다.
Trino의 관점에서 볼 때 여기에서는 델타 유니폼과 관련된 어떠한 작업도 수행되지 않았다는 점을 주목하세요. 스펙에 따라 메타데이터가 생성된 Iceberg 테이블을 읽고, 표준 REST API 호출을 �통해 Iceberg 카탈로그를 호출하여 해당 메타데이터를 검색하는 것입니다.
이것이 바로 델타 유니폼이 제공하는 간결성입니다. 델타 레이크 writer와 reader에게 델타 유니폼 테이블은 델타 레이크 테이블입니다. Iceberg reader에게 델타 유니폼 테이블은 곧 Iceberg 테이블입니다. 이 모두가 단일 데이터 파일들을 기반으로 하며, 불필요한 데이터 및 테이블 복사본을 만들 필요가 없습니다.
델타 유니폼의 영향
프리뷰 기간 동안 많은 고객들이 델타 유니폼을 이용하여 오픈 데이터 레이크하우스 상호운용성을 가속화할 수 있었습니다. 델타 레이크에 한 번만 쓰면 어떤 방식으로든 이 데이터에 액세스할 수 있으므로, 기업들은 고비용의 복잡한 마이그레이션에 대한 부담 없이 ETL, BI, AI와 같은 다양한 워크로드에서 최적의 성능, 비용 효율성, 데이터 유연성을 달성할 수 있습니다.
"Instacart의 비전은 모든 컴퓨팅 플랫폼에서 상호 운용 가능한 단일 데이터셋으로 개방형 데이터 레이크하우스를 구축하는 것입니다. 델타 유니폼은 이러한 목표를 달성하는 데 중요한 역할을 합니다. 델타 유니폼을 사용하면 Delta Lake 또는 Iceberg로 읽을 수 있는 테이블을 빠르고 쉽게 생성하여 에코시스템의 모든 도구와 상호 운용성을 확보할 수 있습니다." - Instacart의 선임 소프트웨어 엔지니어 더그 하이드가 공유한 델타 유니폼에 대한 경험
데이터브릭스의 사명은 데이터 사용자들로 하여금 세계에서 가장 어려운 문제를 해결하도록 돕는 것이며, 이는 데이터를 복사할 필요 없이 적합한 도구를 적합한 업무에 사용할 수 있도록 하는 것에서 시작됩니다. 델타 유니폼이 제공하는 상호운용성 개선에 큰 기대를 걸면서, 앞으로도 이 분야에 지속적으로 투자할 것입니다.
델타 유니폼은 Delta Lake 3.0 프리뷰 릴리즈에서 사용할 수 있습니다. 또한, 데이터브릭스 고객들은 데이터브릭스 런타임 버전 13.2 또는 데이터브릭스 SQL 2023.35 프리뷰 채널을 통해 델타 유니폼을 미리 사용해볼 수 있습니다.
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.