Databricks에서의 DSPy
RAG 및 기타 복합 AI 시스템 프로그래밍을 위한 프레임워크
작성자: Arnav Singhvi, Michael Carbin , Matei Zaharia
거대 언어 모델(LLM)은 프롬프트 기법을 최적화하여 효과적인 인간-AI 상호작용에 대한 관심을 불러일으켰습니다. “프롬프트 엔지니어링”은 모델 출력을 맞춤화하는 성장하는 방법론이며, 검색 증강 생성(RAG)과 같은 고급 기법은 관련 정보를 가져오고 응답함으로써 LLM의 생성 능력을 향상시킵니다.
스탠포드 NLP 그룹에서 개발한 DSPy는 “파운데이션 모델을 프롬프트하는 것이 아니라 프로그래밍하는 것”을 통해 복합 AI 시스템을 구축하기 위한 프레임워크로 등장했습니다. DSPy는 이제 Databricks 개발자 엔드포인트와 통합을 지원하여 Model Serving 및 AI Search를 위한 것입니다.
복합 AI 엔지니어링
이러한 프롬프트 기법은 AI 개발자가 LLM, 검색 모델(RM) 및 기타 구성 요소를 통합하여 복합 AI 시스템을 개발하는 복잡한 “프롬프트 파이프라인”으로의 전환을 나타냅니다.
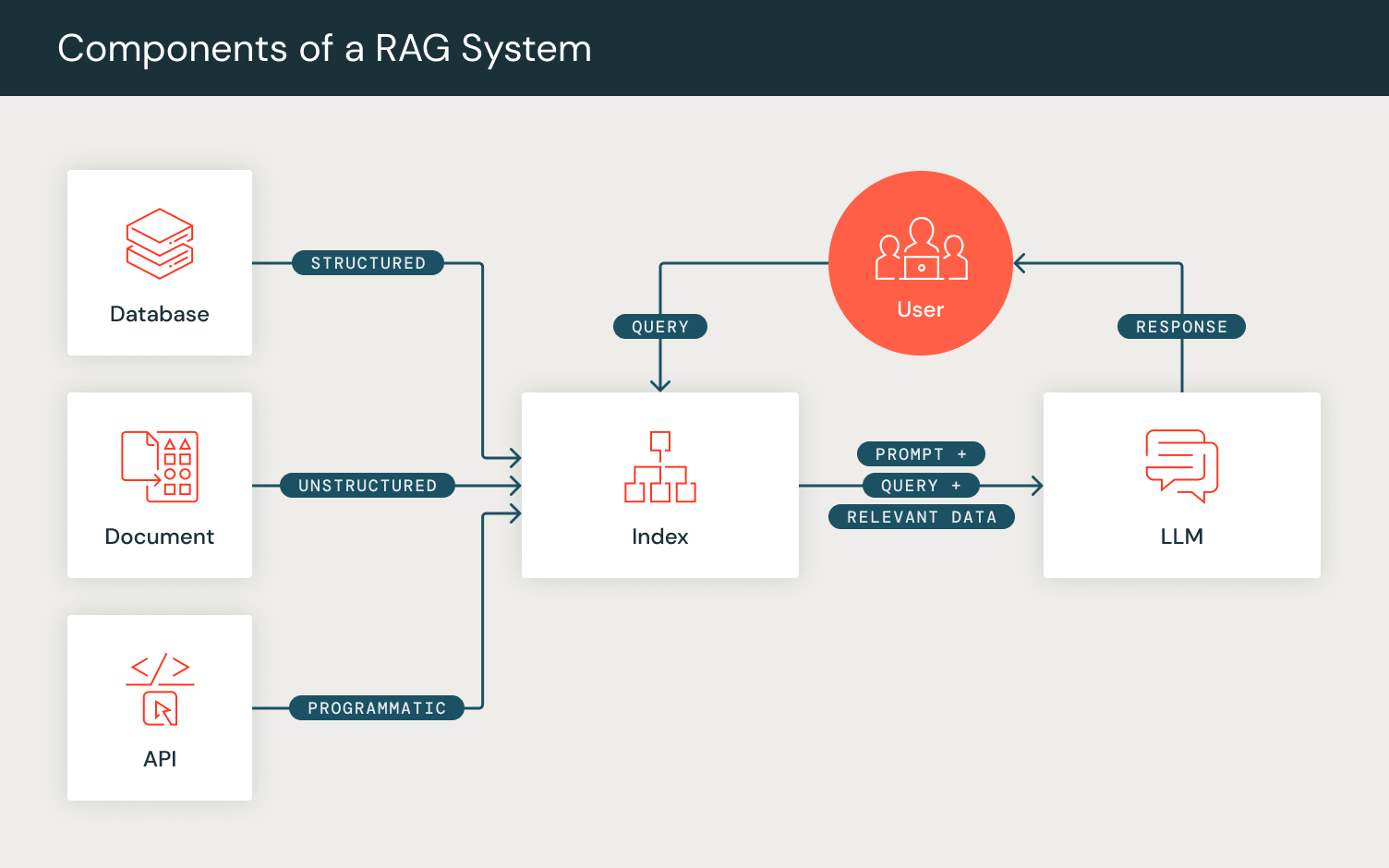
프롬프트가 아닌 프로그래밍: DSPy
DSPy는 LLM 호출을 다른 계산 도구와 함께 다운스트림 작업 메트릭을 위해 구성하여 AI 기반 시스템 성능을 최적화합니다. 기존의 “프롬프트 엔지니어링”과 달리 DSPy는 사용자가 정의한 자연어 서명을 완전한 지침과 몇 가지 예제로 변환하여 프롬프트 튜닝을 자동화합니다. PyTorch의 엔드투엔드 파이프라인 최적화와 유사하게, DSPy를 사용하면 사용자가 원하는 목표를 위해 최적화하면서 AI 시스템을 계층별로 정의하고 구성할 수 있습니다.
DSPy의 프로그램에는 두 가지 주요 메서드가 있습니다.
- 초기화: 사용자는 DSPy 계층으로 프롬프트 파이프라인의 구성 요소를 정의할 수 있습니다. 예를 들어, RAG에 관련된 단계를 고려하기 위해 검색 계층과 생성 계층을 정의합니다.
- 사용자 구성 RM을 사용하여 입력된 검색 쿼리에 대한 관련 구절/문서 세트를 검색하는 검색 계층 `dspy.Retrieve`를 정의합니다.
- 그런 다음 생성 계층을 초기화합니다. 이 계층의 경우 `dspy.Predict` 모듈을 사용하며, 이는 내부적으로 생성을 위한 프롬프트를 준비합니다. 이 생성 계층을 구성하기 위해 입력 필드(“context, query”)와 예상 출력 필드(“answer”)로 지정된 자연어 서식으로 RAG 작업을 정의합니다. 이 모듈은 내부적으로 프롬프트를 이 정의된 서식에 맞게 지정하고 사용자 구성 LM에서 생성을 반환합니다.
- Forward: PyTorch의 forward pass와 유사하게, DSPy 프로그램의 forward 함수는 프롬프트 파이프라인 로직의 사용자 구성을 허용합니다. 초기화된 계층을 사용하여 쿼리가 주어졌을 때 구절 세트를 검색한 다음, 이 구절을 쿼리와 함께 컨텍스트로 사용하여 답변을 생성하고 DSPy 사전 객체에서 예상 출력을 출력함으로써 RAG의 계산 흐름을 설정합니다.
DSPy 프로그램과 DBRX의 생성을 사용하여 RAG를 살펴보겠습니다.
이 예에서는 HotPotQA 데이터셋의 샘플 질문을 사용합니다. 이 데이터셋에는 올바른 답변을 추론하기 위해 여러 단계가 필요한 질문이 포함되어 있습니다.
먼저 DSPy에서 LM과 RM을 구성해 보겠습니다. DSPy는 다양한 언어 및 검색 모델 통합을 제공하며, 사용자는 이러한 매개변수를 설정하여 DSPy로 정의된 프로그램이 이러한 구성을 통해 실행되도록 할 수 있습니다.
이제 정의된 DSPy RAG 프로그램을 선언하고 질문을 입력으로 전달하기만 하면 됩니다.
검색 단계 동안 query는 self.retrieve 계층으로 전달��되어 상위 3개의 관련 구절을 출력하며, 이는 내부적으로 다음과 같이 형식화됩니다.
이 검색된 구절을 사용하여 쿼리와 함께 dspy.Predict 모듈 self.generate_answer로 전달할 수 있습니다. 이는 자연어 서명 입력 필드 “context, query”와 일치합니다. 이는 내부적으로 몇 가지 기본 형식 지정 및 구문 분석을 적용하고, LM에 대한 프롬프트 엔지니어링 없이 정확한 작업 설명으로 모델을 지시할 수 있도록 합니다.
형식이 선언되면 입력 필드 “context”와 “query”가 채워지고 최종 프롬프트가 DBRX로 전송됩니다.
DBRX가 답변을 생성하여 'Answer:' 필드에 채워집니다. 다음을 호출하여 이 프롬프트 생성을 확인할 수 있습니다:
이것은 생성된 답변인 “Steve Yzerman”과 함께 마지막 프롬프트 생성을 출력하며, 이것이 올바른 답변입니다!
DSPy는 다음과 같은 다양한 언어 모델 작업에 널리 사용되었습니다. 미세 조정, 인컨텍스트 학습, 정보 추출, 자가 개선 및 기타 수많은 작업에 사용되었습니다. 이 자동화된 접근 방식은 멀티홉 RAG 및 GSM8K과 같은 수학 벤치마크와 같은 자연어 작업에서 GPT-3.5의 경우 최대 46%, Llama2-13b-chat의 경우 최대 65%까지 인간이 작성한 데모를 사용한 표준 퓨샷 프롬프팅을 능가합니다.
Databricks의 DSPy
DSPy는 이제 모델 서빙 및 벡터 검색을 위한 Databricks 개발자 엔드포인트와의 통합을 지원합니다. 사용자는 dspy.Databricks를 통해 OpenAI SDK 아래에서 Databricks 호스팅 기반 모델 API를 구성할 수 있습니다. 이를 통해 사용자는 Databricks 호스팅 모델에서 엔드투엔드 DSPy 파이프라인을 평가할 수 있습니다. 현재 이는 모델 서빙 엔드포인트의 모델을 지원합니다: 채팅(DBRX Instruct, Mixtral-8x7B Instruct, Llama 2 70B Chat), 완료(MPT 7B Instruct) 및 임베딩(BGE Large (En)) 모델입니다.
채팅 모델
완료 모델
임베딩 모델
검색기 모델/벡터 검색
또한 사용자는 Databricks 벡터 검색을 통해 검색기 모델을 구성할 수 있습니다. 벡터 검색 인덱스 및 엔드포인트를 생성한 후 사용자는 dspy.DatabricksRM을 통해 해당 RM 매개변수를 지정할 수 있습니다:
사용자는 LM과 RM을 해당 Databricks 엔드포인트로 구성하고 DSPy 프로그램을 실행하여 이를 전역적으로 구성할 수 있습니다.
이 통합을 통해 사용자는 Databricks 엔드포인트를 사용하여 RAG와 같은 엔드투엔드 DSPy 애플리케이션을 구축하고 평가할 수 있습니다!
공식 DSPy GitHub 리포지토리, 문서 및 Discord를 확인하여 Databricks를 사용하여 생성 AI 작업을 다목적 DSPy 파이프라인으로 변환하는 방법에 대해 자세히 알아보세요!
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.