데이터 엔지니어링의 발전: 서버리스 컴퓨팅이 Notebook, Lakeflow 작업, Spark 선언적 파이프라인을 혁신하는 방법
Databricks 서버리스 컴퓨팅이 Notebook, Lakeflow Jobs 및 Spark Declarative Pipelines에 대해 최고의 단순성, 성능 및 안정성을 제공하는 방법을 알아보세요.
작성자: 아론 데이비슨, Ihor Leshko, Justin Breese, 피유시 싱, Vivek Narasimhan, 프라샨스 바부 벨라나티 벤카타, 롤랜드 페우스트린, Hemant Saxena , 모스타파 목타르
- Notebook, Lakeflow Jobs, 및 Spark Declarative Pipelines용 서버리스 컴퓨팅은 인프라 및 Spark 업그레이드를 관리할 필요가 없습니다.
- 서버리스 컴퓨팅은 워크로드를 자동으로 개선하고 있으며, 사용자 개입 없이 지난 한 해 동안 성능이 80% 향상되었고 비용 효율성이 최대 70% 향상되었습니다.
- 이제 서버리스 컴퓨팅은 Databricks의 가장 안정적인 컴퓨팅 제품이 되었으며, 증가하는 데이터 볼륨에 맞게 클러스터 크기를 자동으로 조정하고 클라우드 중단 및 재고 부족으로부터 워크로드를 보호하여 실행 성공률이 89% 더 높아졌습니다.
데이터 엔지니어링은 변곡점에 도달했습니다. 기업이 AI 및 머신러닝을 통해 비즈니스 의사 결정을 내리는 데 점점 더 의존함에 따라 컴퓨팅 인프라 관리가 중요한 병목 지점이 되었습니다. Databricks 서버리스 컴퓨팅의 발전으로 팀은 Databricks Runtime(DBR) 버전 업그레이드, 클러스터 설정 관리, 인프라 문제 해결과 같은 일상적인 작업 시간을 최대 20%까지 절약할 수 있습니다. 오늘, Databricks 서버리스 컴퓨팅의 최근 기능 출시와 이것이 Notebooks, Lakeflow Jobs, Spark Declarative Pipelines(SDP, 이전 명칭 DLT)에 대해 비교할 수 없는 간편성, 성능 및 안정성을 제공하여 패러다임을 근본적으로 어떻게 변화시켰는지 공유하게 되어 기쁩니다. 예를 들어 서버리스 컴퓨팅은 성능 최적화 워크로드에 비해 표준 성능 모드에서 70%의 비용 절감 효과를 제공하고, Spark가 아닌 워크로드의 경우 50% 이상의 비용 절감 효과를 제공합니다. 또한 성능 최적화 워크로드는 몇 초 만에 시작되고 일반적으로 두 배 더 빠르게 실행됩니다. 버전리스는 지난 한 해 동안 45억 개 이상의 워크로드에서 25회의 DBR 업그레이드를 실행했으며, 놀랍게도 99.998%의 성공률을 기록했습니다.
인프라 관리의 어려움은 현실입니다
모든 데이터 엔지니어링 플랫폼은 다음과 같이 기존 Apache Spark 클러스터를 유지 관리하기 위해 광범위한 운영 책임을 처리해야 합니다.
- 네트워크는 VPC, 게이트웨이, IP 주소 범위 및 프라이빗 엔드포인트로 설정해야 합니다.
- 보안 및 규정 준수를 위해서는 취약점 관리, 암호화 및 데이터 유출 방지에 세심한 주의가 필요합니다.
- 인스턴스 크기 조정, 활용률, 인스턴스 풀 및 Delta 최적화와 같은 효율성 고려 사항은 강력한 데이터 환경을 실행하는 데 필수적입니다.
- 최신 성능 개선 사항이 포함된 최신 런타임을 유지 관리하는 것도 플랫폼 운영의 또 다른 중요한 측면입니다. 매년 두 번의 장기 지원 DBR 릴리스가 제공되므로 팀은 안정성, 성능 및 워크로드와의 호환성을 보장하기 위해 업그레이드를 신중하게 평가하는 것이 일반적입니다.
서버리스 컴퓨팅은 네트워킹 및 IP 범위, 보안 강화, 라이프사이클 관리 및 런타임 업그레이드와 같은 기본 작업이 모두 자동으로 처리되고 지속적으로 최적화되는 다른 운영 모델을 제공합니다. 이를 통해 팀은 최신 최적화를 더 빨리 도입�하고 인프라 관리보다는 데이터 제품을 구축하고 비즈니스 가치를 제공하는 데 더 많은 시간을 할애할 수 있습니다.
서버리스 컴퓨팅: 간편하고, 성능이 뛰어나며, 유지 관리가 필요 없습니다
Databricks 서버리스 컴퓨팅은 Databricks에서 관리하는 자동 최적화 컴퓨팅으로, 세 가지 핵심 원칙을 통해 이러한 문제를 해결합니다.
- 간편함: 워크로드를 빠르게 실행할지(성능 최적화 모드) 또는 비용 효율적으로 실행할지(표준 모드)만 선택하면 됩니다. Databricks는 선택한 목표를 달성하기 위해 지속적으로 자동으로 미세 조정합니다. 노브, 인스턴스 유형 또는 스케일 팩터 선택이 필요하지 않습니다.
- 성능: Databricks의 최적화된 인프라와 새로운 자동 스케일러를 기반으로 하는 서버리스 컴퓨팅은 몇 초 만에 시작되고, 캐시에서 종속 라이브러리를 몇 초 만에 로드하며, 일반적으로 기존 클러스터보다 두 배 더 빠르게 실행됩니다.
- 유지 관리 불필요: Databricks 서버리스는 메모리 부족 문제를 방지하기 위해 컴퓨팅을 수평 및 수직으로 자동 확장하고, 클라우드 중단으로부터 보호하며, 사용 가능한 인스턴스 유형으로 장애 조치하여 높은 수준의 내결함성을 제공합니다. 또한 버전이 없으므로 완전한 이전 버전과의 호환성을 유지하면서 최신 성능 개선 사항으로 자동 업그레이드됩니다.
서버리스는 간편합니다
즉시 사용 가능한 성능 및 효율성
Notebooks, Spark Declarative Pipelines 및 Lakeflow Jobs용 서버리스 컴퓨팅을 사용하면 Databricks가 워크로드에 적합한 인프라를 자동으로 선택한 다음 과거 워크로드 정보를 기반으로 지속적으로 최적화합니다. 따라서 사용자는 더 이상 특정 인스턴스 유형, 자동 스케일러 설정 또는 Photon과 같은 최적화를 선택할 필요가 없습니다. 당사의 AI는 워크로드에 가장 적합한 인프라와 설정을 자동으로 감지하고 자동으로 활성화합니다. 예를 들어 Photon은 특정 워크로드가 Photon 가속의 이점을 얻는 경우에만 사용됩니다.
Spark가 필요하지 않은 워크로드의 경우, 당사의 자동 인프라 선택은 Spark가 필요하지 않은 경우 더 작은 VM이 즉석에서 프로비저닝되도록 합니다. 이 접근 방식은 실제로 필요한 리소스만 사용하여 기존 클러스터에 비해 50% 이상의 비용 절감 효과와 33% 더 빠른 시작을 제공할 수 있습니다.
Lakeflow Jobs 및 Spark Declarative Pipelines용 성능 모드의 도입은 사용자가 Databricks가 무엇을 최적화해야 하는지 표현할 수 있도록 해주므로 컴퓨팅 최적화의 중요한 발전을 나타냅니다. 성능 최적화 모드는 몇 초 만에 시작되고 일반적으로 기존 클러스터보다 두 배 더 빠르게 실행됩니다. 이 모드는 워밍 풀의 머신과 적극적인 리소스 확장을 활용하여 처리 시간을 최소화하므로 대화형 및 시간에 민감한 워크로드에 적합합니다.
7월부터 일반적으로 사용 가능한 표준 모드는 다른 접근 방식을 취합니다. 순수한 속도보다는 비용 효율성을 최적화하여 경쟁력 있는 성능을 유지하면서 성능 최적화 모드에 비해 최대 70%의 비용 절감 효과를 제공합니다. 이 모드는 상당한 비용 절감을 위해 4~6분 시작 대기 시간이 허용되는 일괄 처리 워크로드, 예약된 작업 및 파이프라인에 적합합니��다.
성능 모드를 통해 사용자는 인프라 관리보다는 사용 사례에 특정한 데이터 인사이트와 비즈니스 요구 사항에 집중할 수 있습니다. 이 간편성을 통해 사용자는 데이터에서 인사이트를 생성하는 데 더 많은 시간을 할애할 수 있습니다. 대화형 Notebooks의 서버리스는 항상 몇 초 만에 시작되고 사용자의 시간을 최대한 활용하기 위해 빠르게 실행된다는 점을 명심하십시오.
| 서버리스 컴퓨팅 모드 | 일반적인 성능 | 주요 이점 |
|---|---|---|
| Notebooks용 대화형 모드 데이터 과학에 가장 적합한 서버리스 환경, Databricks Notebooks용 완전 관리형 플랫폼 | < 10초 시작, 빠른 확장 |
|
| Lakeflow Jobs 및 SDP용 성능 최적화 모드 데이터 엔지니어링에 가장 적합한 서버리스 환경, 시간에 민감한 Lakeflow Jobs 및 SDP를 위한 빠른 시작 및 실행 | < 1분 시작, 빠른 확장 |
|
| Lakeflow Jobs 및 파이프라인용 표준 모드 더 낮은 비용의 서버리스 환경, Jobs 및 SDP를 실행하기 위한 완전 관리형 플랫폼 | 4~6분 시작, 보수적인 확장 |
|
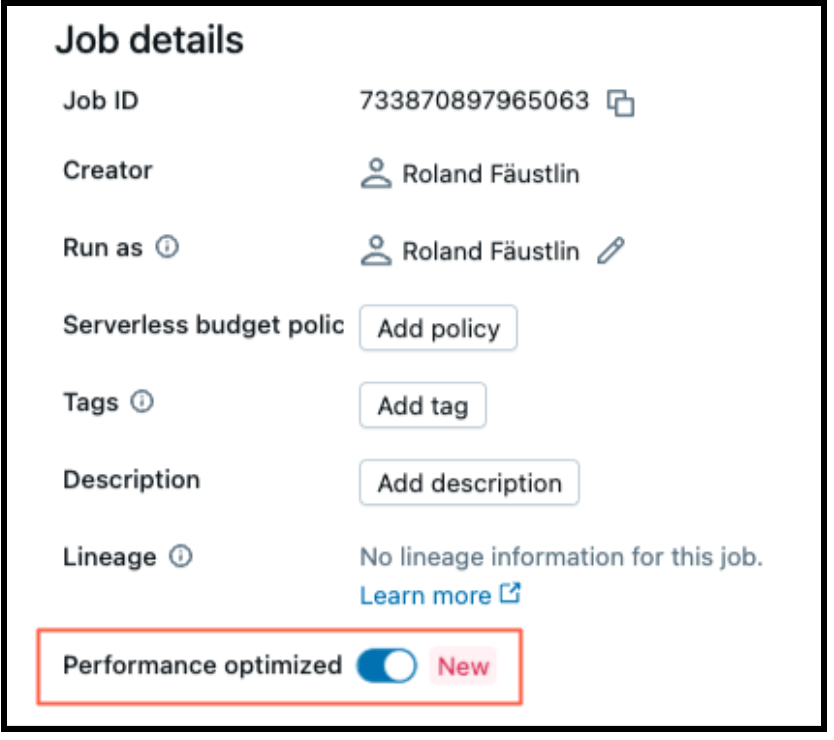
서버리스 컴퓨팅을 사용하면 토글을 전환하는 것만큼 쉽게 성능 또는 효율성을 조정할 수 있습니다. "성능 최적화"가 활성화되면 워크로드가 더 빠르게 시작되고 실행됩니다. 비활성화되면 워크로드가 "표준" 모드로 실행되어 효율성을 최적화합니다.
포괄적인 비용 관리 및 거버넌스
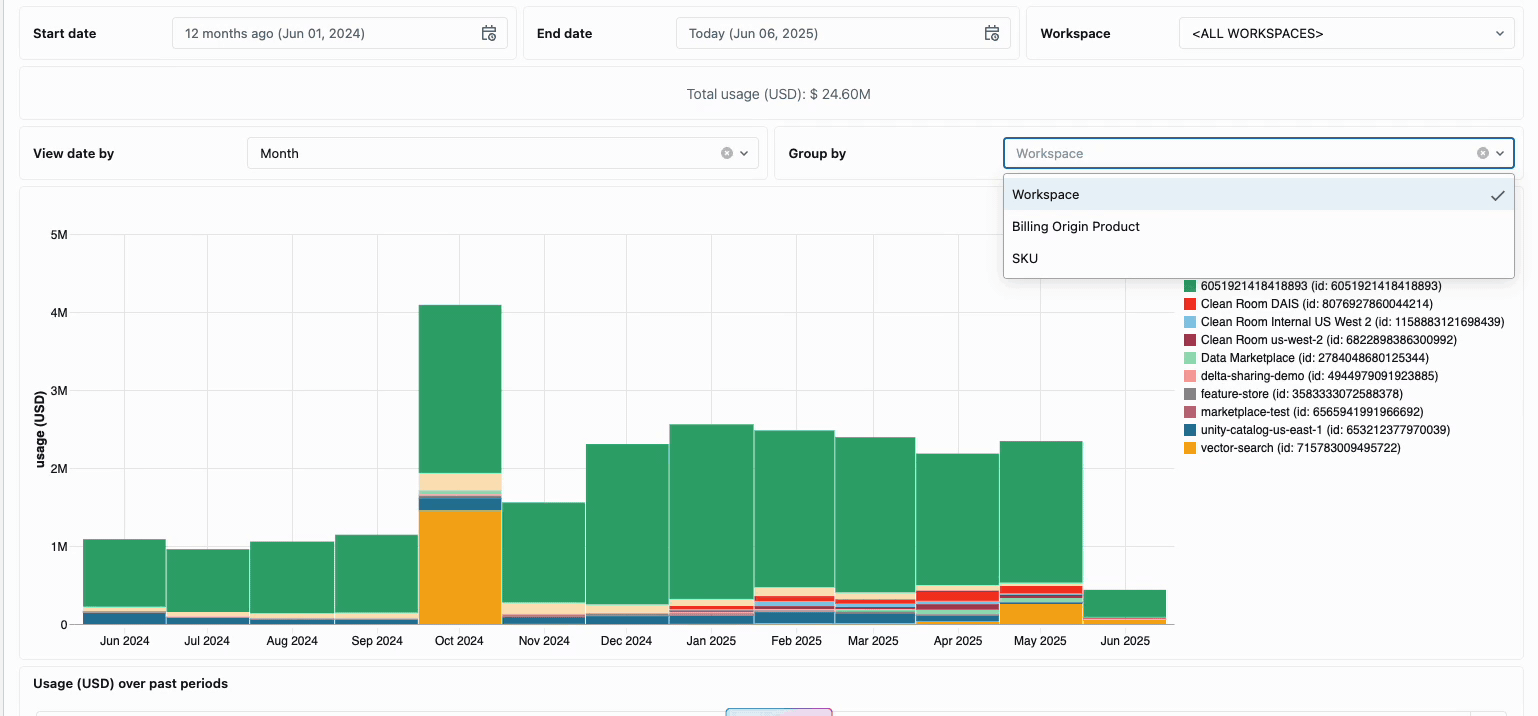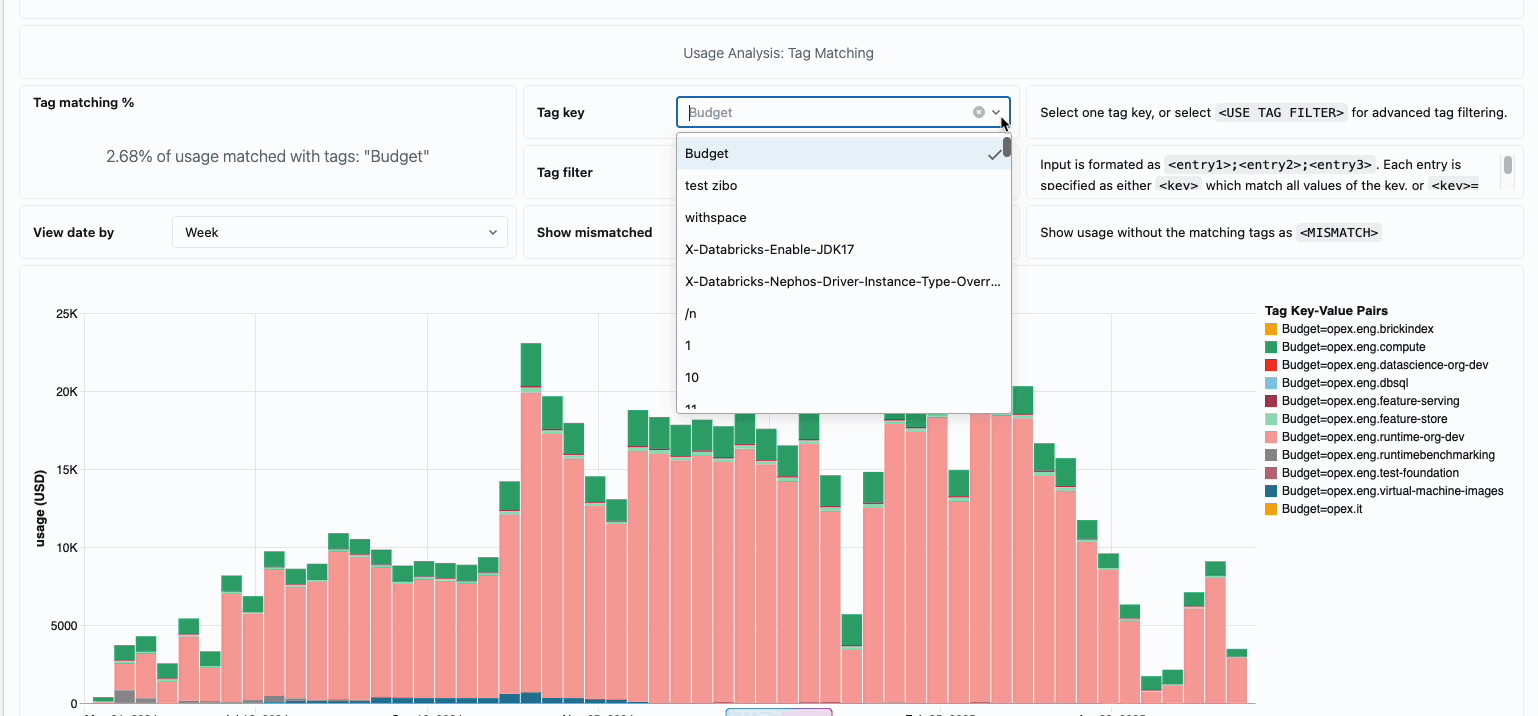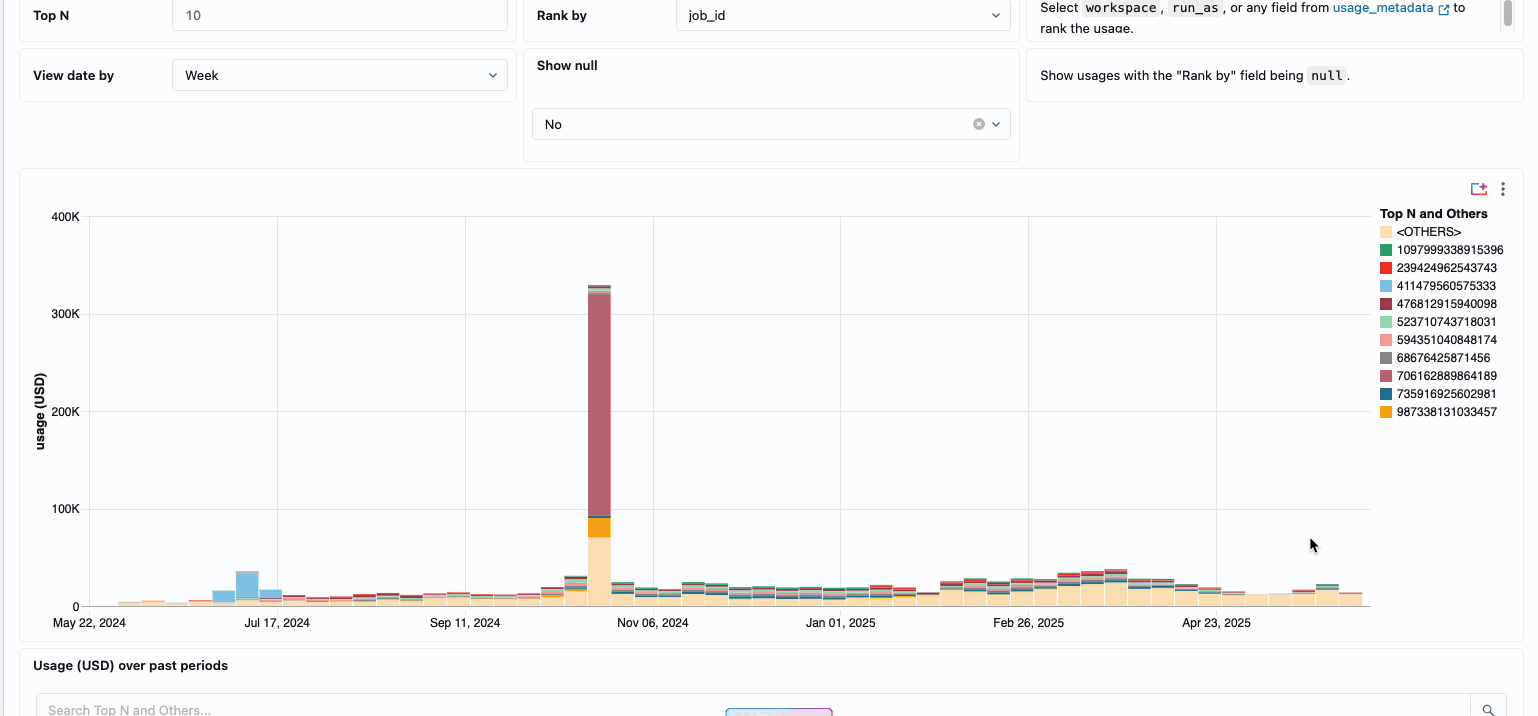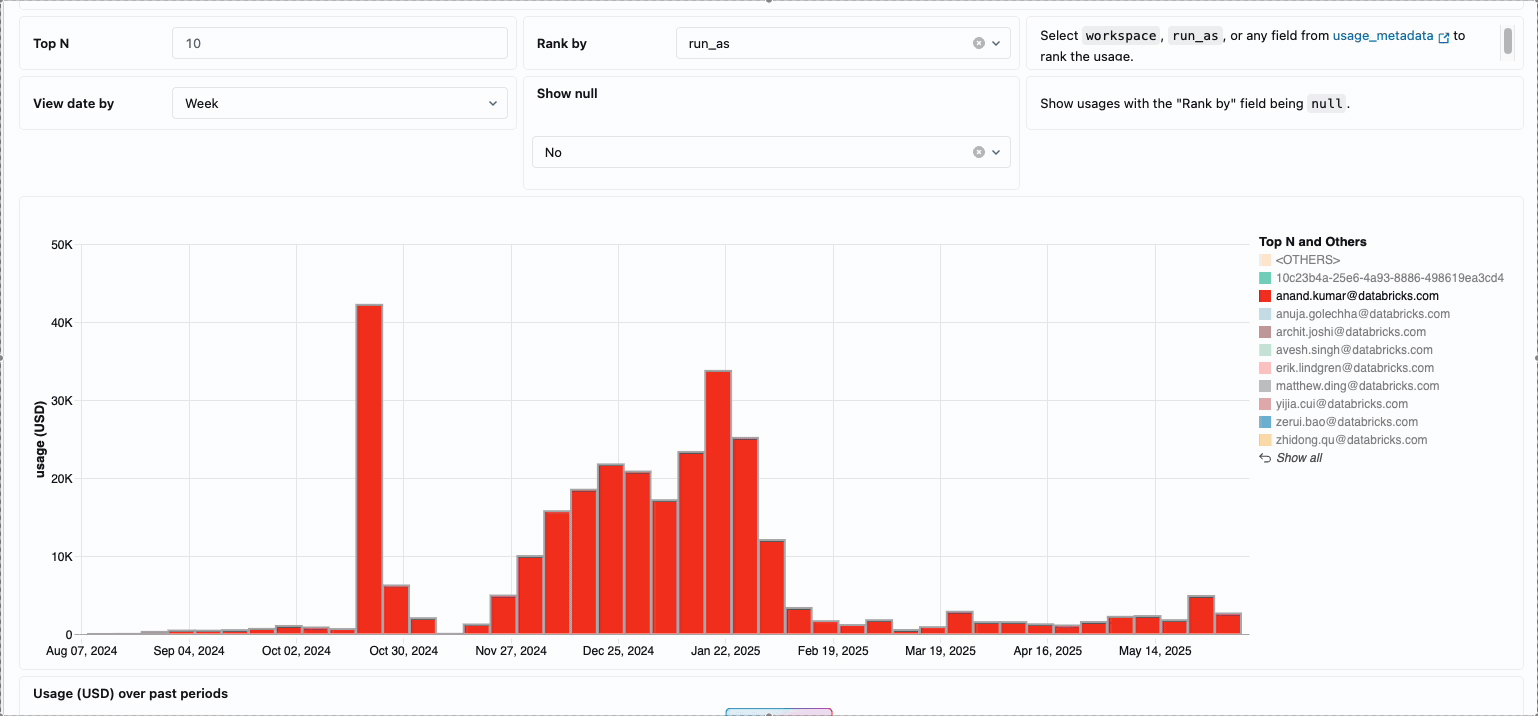
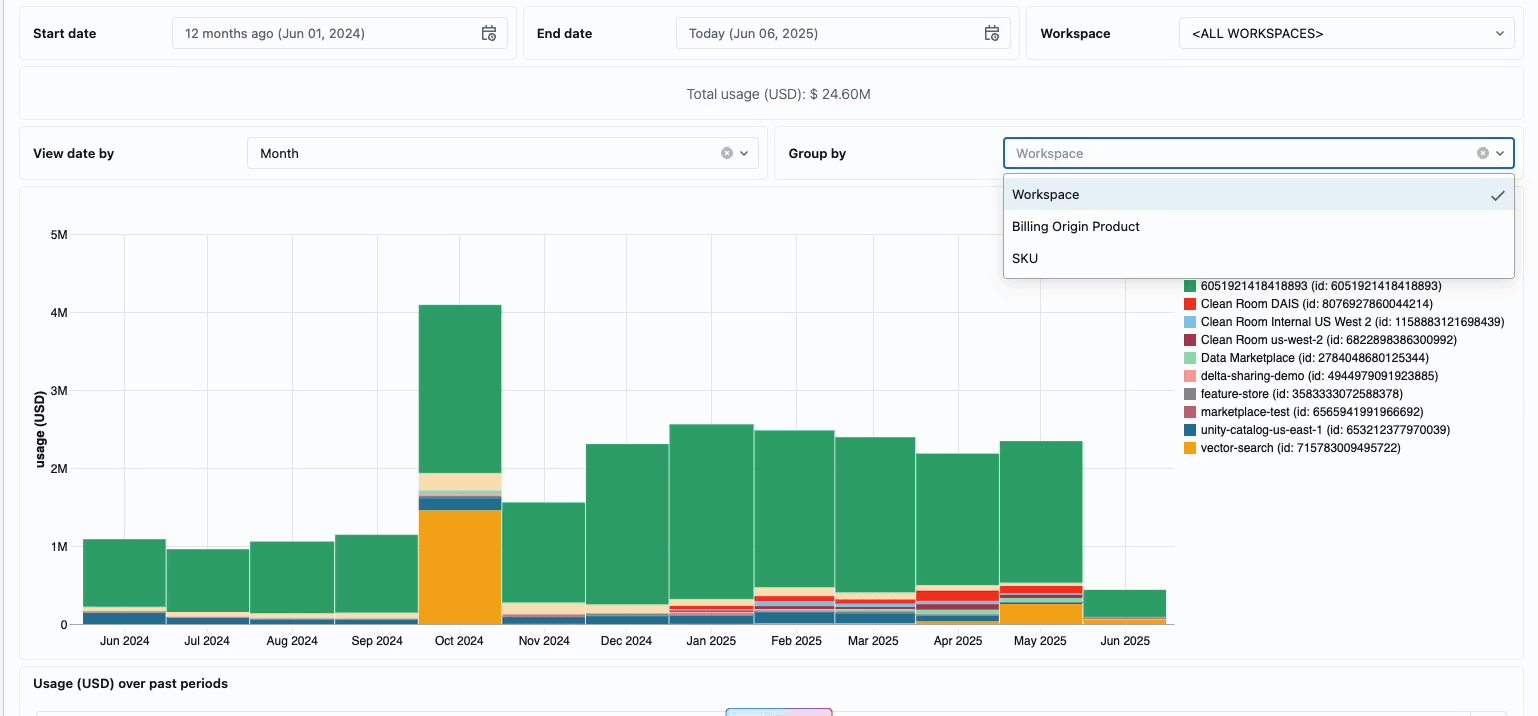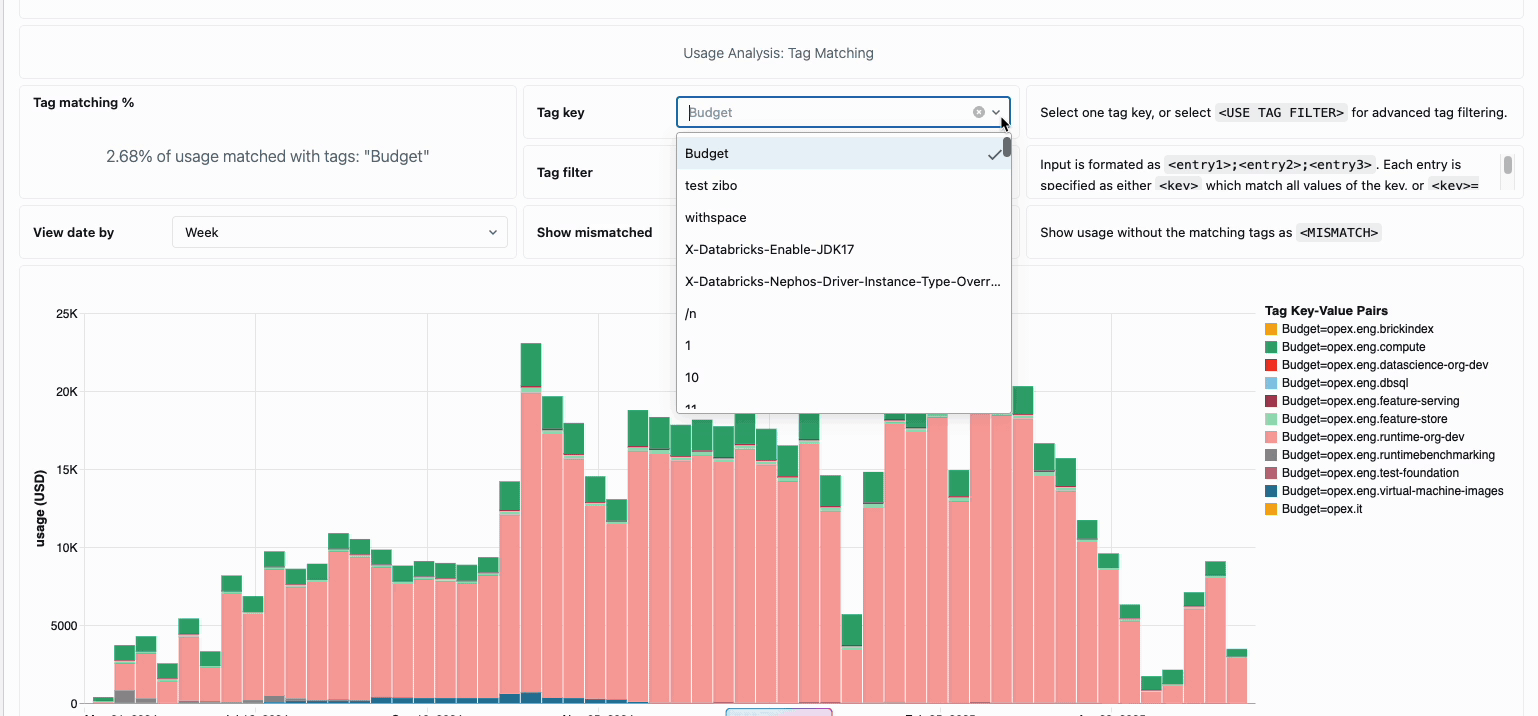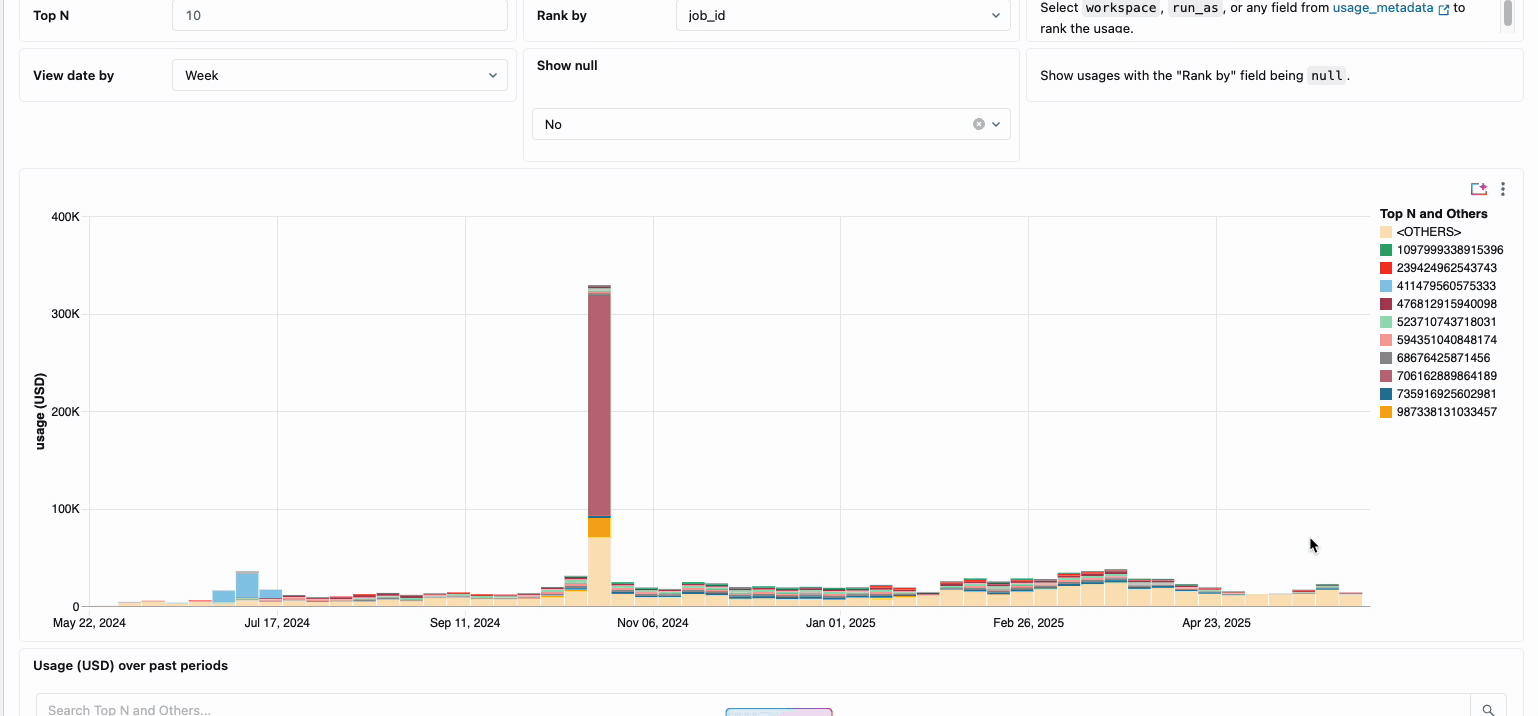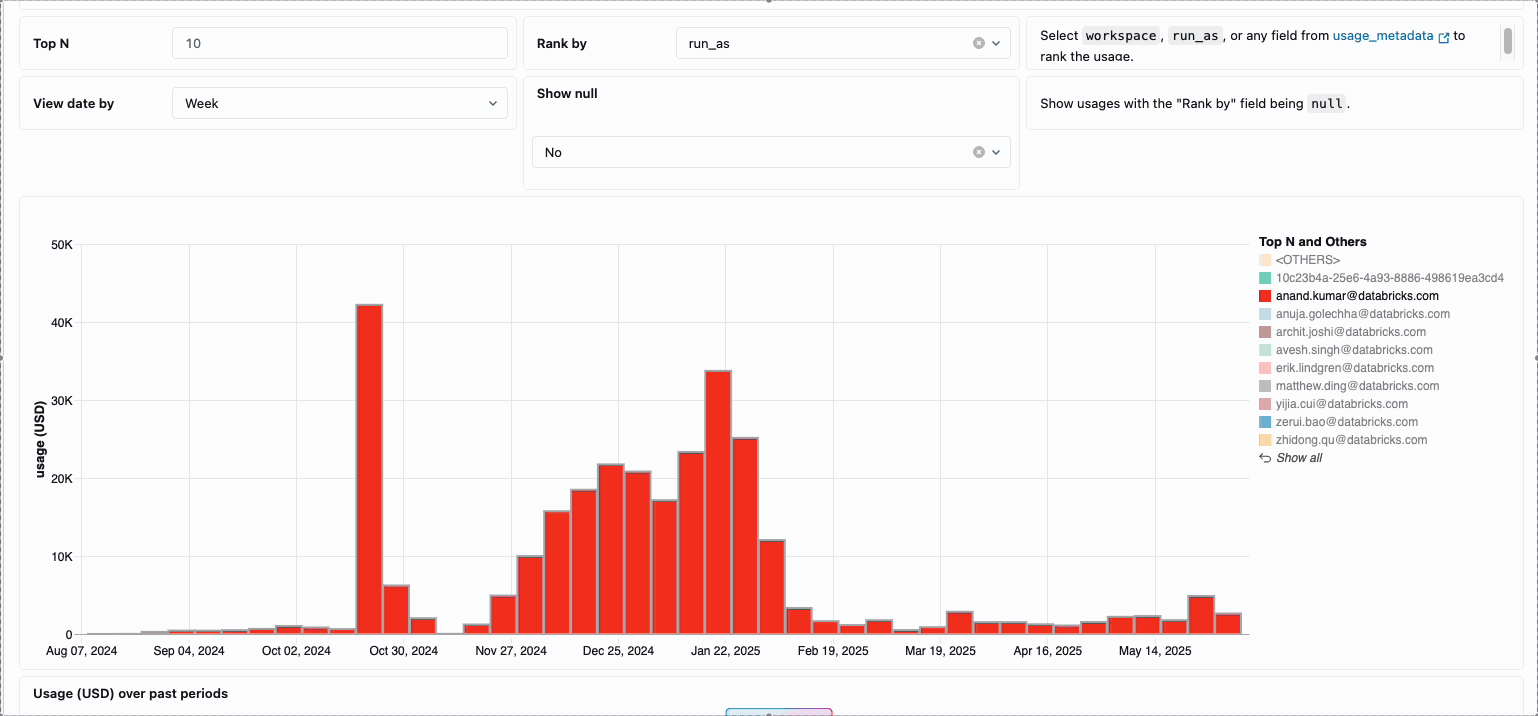
분산된 데이터 엔지니어링 팀의 컴퓨팅 비용을 관리하려면 기존에는 서로 다른 데이터 소스와 청구 구성 요소를 함께 연결해야 했습니다. 이는 소요 시간이 많이 걸리는 프로세스로, 총 소유 비용을 종종 가립니다. 서버리스 컴퓨팅은 통합 청구를 통해 이러한 복잡성을 명확성으로 전환하여 모든 비용 구성 요소를 단일하고 이해하기 쉬운 보기로 통합합니다. 관리자는 시스템 테이블에 구축된 사전 구축된 예산 대시보드와 사용자 지정 가능한 쿼리를 통해 즉시 가시성을 확보하므로 다양한 서비스 제공업체에서 수동 조정 작업을 수행할 필요가 없습니다.
내부 비용 회계가 필요한 조직의 경우 서버리스 사용 정책을 통해 팀 또는 프로젝트별로 비용을 자동으로 집계하는 태�그 적용이 가능하므로 사업부 전체에서 정확한 귀속 및 책임을 보장합니다. 또한 이 플랫폼은 우발적인 지출로부터 보호하는 여러 계층을 제공합니다. 지능형 시간 제한은 예산을 고갈시키는 실행 중인 쿼리를 방지하고, 세분화된 사용 정책은 관리자에게 누가 서버리스 컴퓨팅에 액세스할 수 있는지, 어떤 속도로 리소스를 소비할 수 있는지에 대한 정확한 제어 권한을 제공하여 혁신과 재정적 책임을 균형 있게 유지하는 포괄적인 거버넌스 프레임워크를 만듭니다.
{kind=link}
서버리스: 성능을 위해 설계됨
환경 캐싱으로 종속성 설치 오버헤드 제거
기존 컴퓨팅 설정은 특히 팀에 다양한 라이브러리 요구 사항이 있는 경우 각 실행에 적합한 환경을 준비하기 위해 설치 단계에 의존하는 경우가 많습니다. 서버리스 컴퓨팅은 지능형 환경 캐싱을 사용하여 이를 변경합니다. ��사용자는 환경을 한 번 정의하면 Databricks가 필요한 라이브러리를 자동으로 분석, 다운로드 및 설치한 다음 스냅샷을 만들어 캐시합니다. 향후 실행은 몇 초 만에 캐시에서 환경을 로드합니다. 다운로드나 설치가 필요하지 않습니다. 이는 특히 작은 워크로드에 유용하며 평균적으로 2배 더 빠릅니다. 새로운 기본 기본 환경을 통해 관리자는 다양한 팀을 위해 미리 구성된 환경을 중앙에서 관리하여 분석가, 데이터 과학자 및 ML 엔지니어의 워크플로를 간소화할 수 있습니다.
시작은 우리에게 우선 순위이며 서버리스 Notebooks 및 워크플로가 큰 변화를 가져왔습니다. Notebooks용 서버리스 컴퓨팅은 단 한 번의 클릭으로 간편하게 만들 수 있습니다. —Airbus의 데이터 엔지니어 Chiranjeevi Katta
서버리스 Spark Declarative Pipelines는 비용을 절감하지 않고 실행 시간을 절반으로 줄이고, 엔지니어링 효율성을 높이고, 복잡한 데이터 운영을 간소화하여 팀이 프로덕션 및 개발 환경 모두에서 인프라가 아닌 혁신에 집중할 수 있도록 합니다. —Qorvo의 Sr. 데이터 및 AI 엔지니어 Cory Perkins
실제로 Databricks의 모든 워크로드에서 서버리스 컴퓨팅은 평균적으로 기존의 유사한 클러스터 워크로드보다 20% 더 비용 효율적이며 고객이 기존 클러스터 시작에 대해 클라우드 공급자에게 비용을 지불하는 동안 Databricks는 시작에 대해 요금을 부과하지 않습니다.
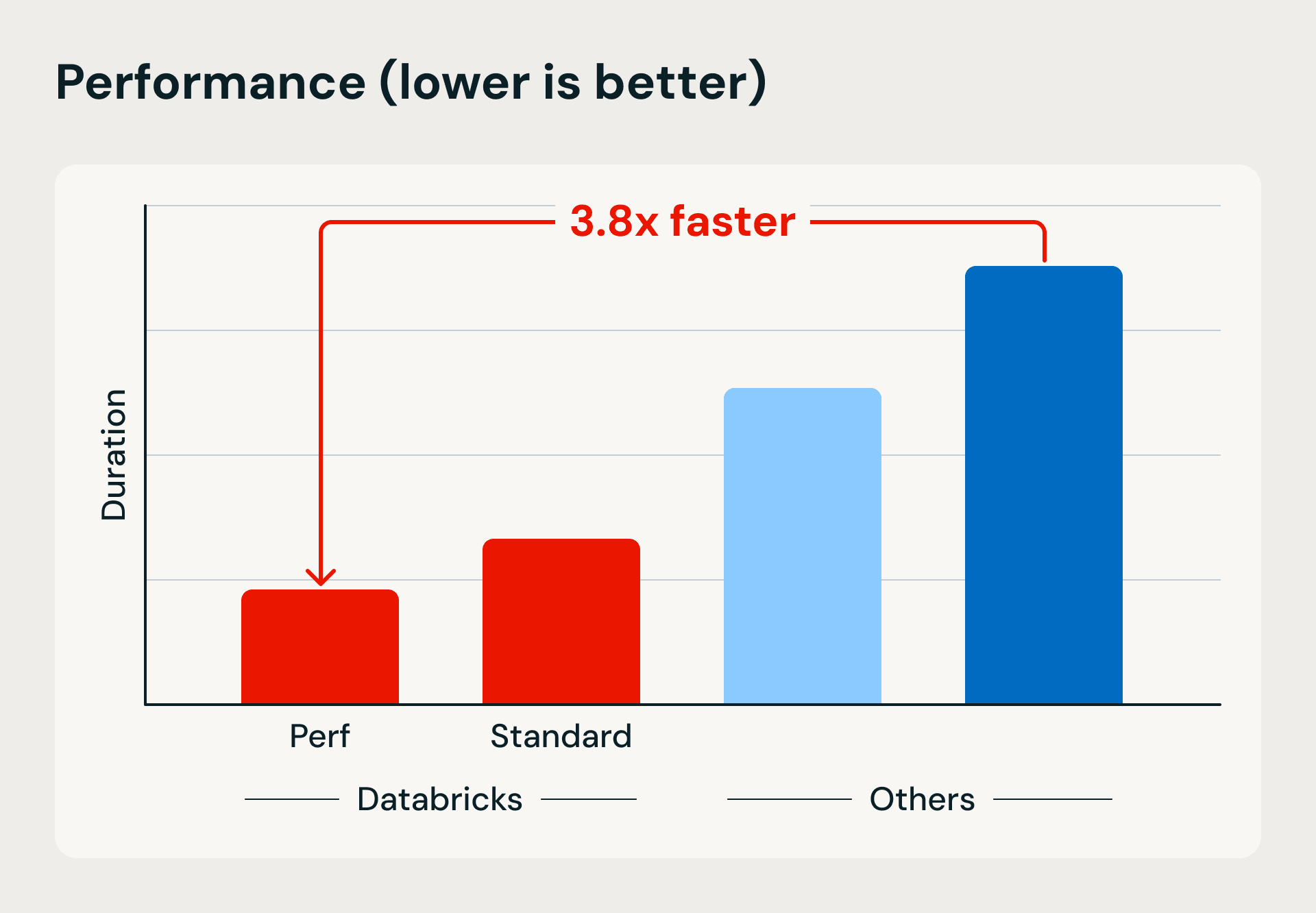
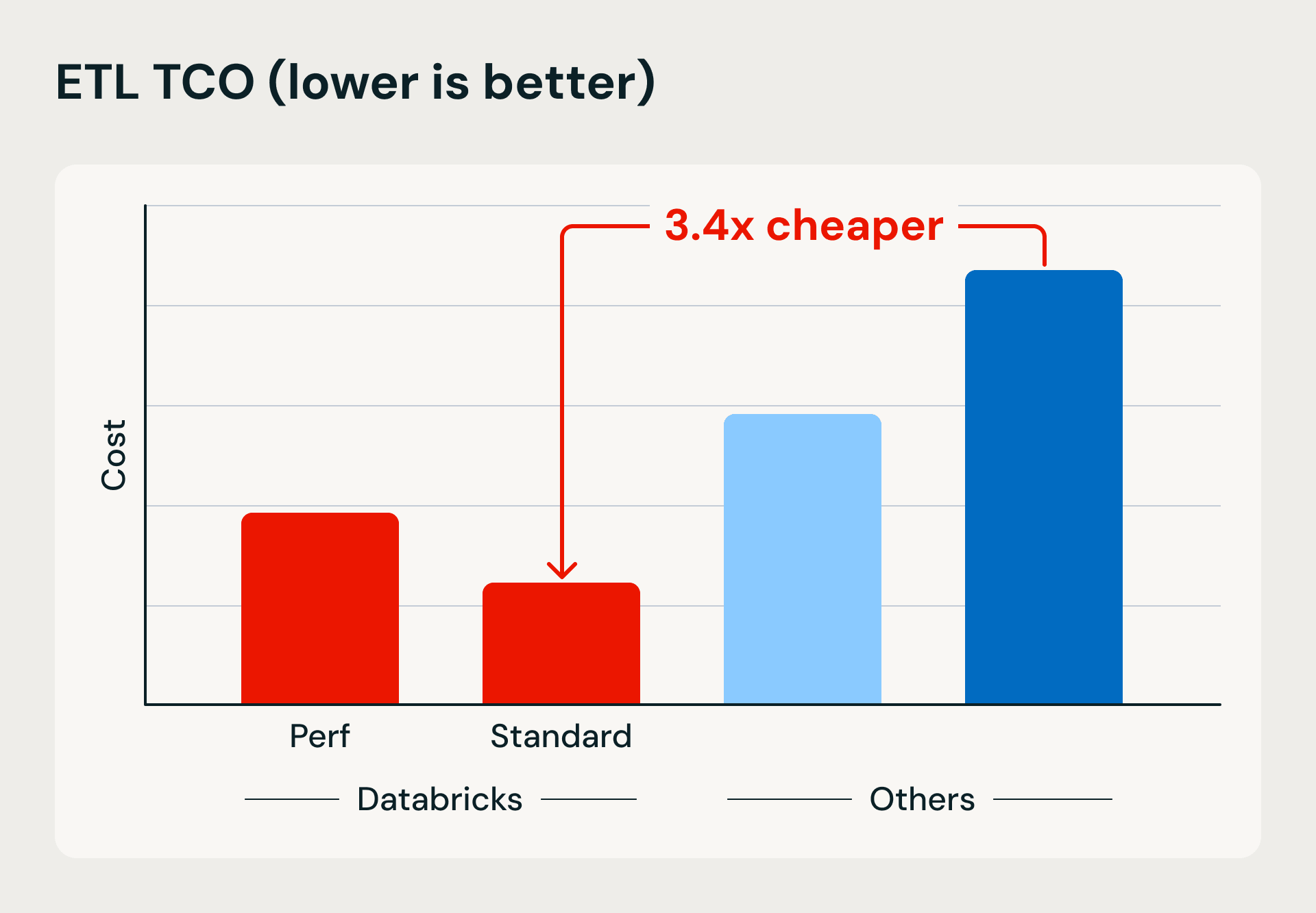
Databricks의 서버리스 컴퓨팅의 실행 속도 및 효율성 이점을 보여주는 성능 및 비용 비교. 벤치마크는 Lakeflow Jobs를 사용하여 1TB를 Bronze에 로드하고 병합 기반 업서트를 사용한 다음 데이터를 Silver 및 Gold 테이블로 구체화하고 중복 제거합니다.
Databricks 파이프라인을 '서버리스' 컴퓨팅으로 전환한 후 HP는 클라우드 비용을 32% 이상 절감하고 작업의 결합된 런타임을 36% 단축했습니다. '서버리스'에서 제공하는 간편한 인프라 관리로 인해 이 결정은 명백하고 전략적인 선택이 되었습니다. —HP Marketing의 데이터 전략 및 엔지니어링 책임자 Luis Alonso
Google Cloud의 서버리스 Spark Declarative Pipelines는 Uplight��에서 우리의 접근 방식을 재정의하여 비용을 절감하면서 ETL 워크로드를 두 배 이상 빠르게 실행할 수 있게 해줍니다. 서버리스 컴퓨팅의 사용 편의성, 자동 최적화 및 효율성으로 인해 확장이 더 쉬워지고 고객에게 가치를 제공하는 데 우선 순위를 둘 수 있습니다. —Uplight의 데이터 과학 및 엔지니어링 이사 Micaela Christopher
과거에는 원시 데이터에서 실버 레이어로 이동하는 데 약 16분이 걸렸지만 서버리스로 전환한 후에는 약 7분밖에 걸리지 않습니다. —Jet Linx Aviation의 IT 운영 이사 Aaron Jepsen
[데이터 운영 구성 및 유지 관리 감소와 결합된] 시작 시간의 상당한 개선은 생산성과 효율성을 크게 향상시킵니다. —AnyClip의 데이터 책임자 Gal Doron
서버리스는 유지 관리가 필요 없습니다
자동 인프라 선택: 수동 클러스터 관리 제거
기존 클러스터 관리 방식은 사용자에게 가능한 많은 구성 조합 중 하나를 선택하고 메모리 부족 오류 또는 성능 병목 현상 방지를 포함하여 시간 경과에 따른 변화하는 데이터 및 비즈니스 요구 사항을 충족하도록 구성을 조정하는 데 가장 큰 자유를 제공합니다. 서버리스 컴퓨팅은 AI 인프라 선택을 통해 게임을 근본적으로 변화시킵니다. 이 시스템은 워크로드 패�턴과 리소스 활용률을 지속적으로 모니터링하고 메모리 제약 조건이 감지되면 자동으로 더 큰 인스턴스로 확장하고 클라우드 공급자 중단 시 호환 가능한 인스턴스 유형으로 원활하게 장애 조치합니다. 포괄적인 워크로드 기록 및 실시간 성능 데이터를 활용하여 서버리스 컴퓨팅은 사람의 개입 없이 최적의 인프라 결정을 내리므로 기존 컴퓨팅 환경에 비해 중단이 89% 적습니다. 이 자동화된 접근 방식은 클라우드 공급자 제한으로부터 사용자를 보호할 뿐만 아니라 일반적인 인프라 문제의 자동 수정을 가능하게 하여 서버리스 컴퓨팅을 Databricks의 가장 안정적이고 안정적인 컴퓨팅 제품으로 만듭니다.
서버리스 [...]를 통해 대기 시간이 3~5배 향상되었습니다. 이전에는 10분이 걸리던 것이 이제 2~3분밖에 걸리지 않습니다. —Cincinnati Reds의 데이터 엔지니어링 관리자 Bryce Dugar
서버리스 옵션을 사용하면 엔지니어링 유지 관리 및 비용 최적화에 대한 오버헤드가 줄어듭니다. 이러한 움직임은 Databricks 내에서 모든 파이프라인을 서버리스 환경으로 마이그레이션하려는 전반적인 전략과 원활하게 일치합니다. —Compass의 수석 데이터 엔지니어링 관리자 Bala Moorthy
자동 성능 및 보안 개선을 위한 버전리스 업그레이드
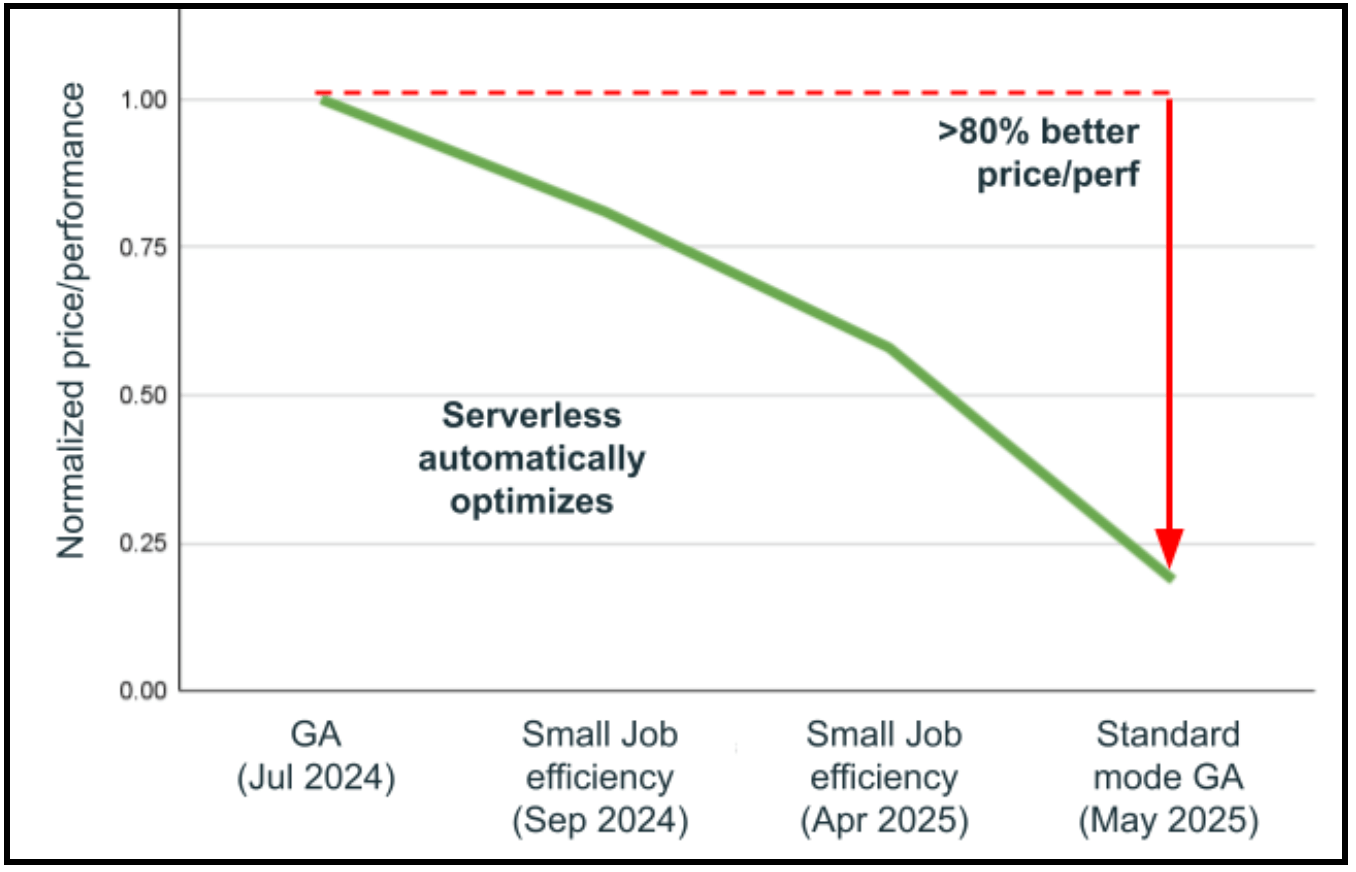
아마도 서버리스 컴퓨팅의 가장 혁신적인 기능은 수동 런타임(DBR) 업그레이드가 필요 없는 버전리스 아키텍처일 것입니다. 최신 런타임을 유지하면 상당한 성능 향상을 가져올 수 있습니다. 서버리스 컴퓨팅은 호환성이 손상되는 변경 없이 원활한 DBR 교체를 가능하게 하는 혁신적인 아키텍처를 통해 이 프로세스를 근본적으로 재구상합니다. 지난 한 해 동안만 Databricks는 45억 개 이상의 워크로드에서 25회의 DBR 업그레이드를 자동으로 수행했으며 놀랍게도 99.998%의 성공률을 기록했습니다. 문제가 감지되는 드문 경우에도 문제가 백그라운드에서 해결되는 동안 워크로드가 이전의 안정적인 버전으로 자동 롤백되어 중단 없는 운영을 보장합니다. 결과는 스스로 말해줍니다. 자동 인프라 선택 개선 및 버전리스 업그레이드의 조합으로 인해 사용자가 워크로드를 건드리지 않고도 1년 이내에 80% 이상의 가격 대비 성능 향상이 이루어졌습니다. 이 버전리스 접근 방식은 서버리스 컴퓨팅이 지속적으로 개선되어 데이터 엔지니어링 팀이 인프라 업그레이드 관리보다는 비즈니스 가치 구축에 전적으로 집중하는 동안 최신 Spark 최적화, 보안 패치 및 성능 향상을 자동으로 제공함을 의미합니다.
더 많은 서버리스 기능
서버리스 컴퓨팅은 이제 다음과 같은 포괄적인 고급 기능 세트를 제공합니다.
- 작업 영역 기반 환경을 통해 관리자는 빠른 시작을 위해 자동 캐싱을 통해 사용자 환경을 중앙에서 관리할 수 있습니다.
- Scala �작업 지원은 팻 JAR 배포 기능으로 로컬 IDE 개발을 제공합니다.
- A10 및 H100을 포함한 GPU 지원과 SparkML 지원은 서버리스를 머신러닝 및 GenAI 워크로드에 개방합니다.
- 일시 중단 및 재개는 현재 컴퓨팅 상태의 스냅샷을 찍고 작업 손실 없이 클러스터 비용을 지불하지 않고 나중에 작업을 재개할 수 있으므로 개발 및 디버깅이 훨씬 쉬워집니다.
- 향상된 비용 관리 기능에는 속도 제한(곧 제공 예정), 경고가 포함된 예측 쿼리 기간, 자세한 비용 분석을 위한 확장된 시스템 테이블이 포함됩니다.
이러한 추가 기능은 데이터 엔지니어링을 위한 가장 유능하고 지능적인 컴퓨팅 플랫폼으로서 서버리스 컴퓨팅의 위치를 강화합니다. 그리고 우리는 이제 막 시작했습니다.
지금 서버리스 여정을 시작하세요
증거는 설득력이 있습니다. 서버리스 컴퓨팅은 전례 없는 간편성, 안정성 및 성능 최적화를 제공하는 데이터 인프라의 확실한 진화를 나타냅니다. 일반적으로 사용 가능하고 최대 70%의 비용 절감 효과를 제공하는 표준 모드를 통해 복잡한 클러스터 관리에서 지능형 자동화 컴퓨팅으로 전환할 수 있는 더 좋은 시기는 없었습니다. 성능 최적화 모드의 초고속 실행이 필요하든 표준 모드의 비용 효율성이 필요하든 서버리스 컴퓨팅은 자동 DBR 업그레이드 및 성능 향상을 통해 워크로드를 지속적으로 개선하면서 인프라 복잡성을 제거합니다.
- 서버리스 Databricks 계정에 가입하세요
- Notebooks, Lakeflow Jobs 및 Spark Declarative Pipelines용 서버리스 컴퓨팅
- 서버리스 컴퓨팅에 대한 실무자 가이드
- SDP 소개
- SDP 데모
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.