대규모 고속 PEFT 서빙
작성자: Databricks AI 연구팀
매우 빠른 추론 런타임을 구축하는 것은 단순히 원시적인 속도에 관한 문제가 아니라, 실제 고객을 위한 올바른 문제를 해결하는 것입니다. Databricks는 데이터 인텔리전스에 중점을 두고 고객이 자체 데이터를 대규모 프로덕션 워크로드를 처리하는 AI 에이전트로 전환할 수 있도록 지원합니다. 추론 엔진은 요청 스케줄링부터 GPU 커��널 실행에 이르기까지 모든 것을 조율하며 이러한 과제의 핵심에 있습니다. 지난 1년 동안 저희는 자체 추론 엔진을 구축하여 일부 고객 워크로드에서 오픈 소스보다 2배 뛰어난 성능을 보였을 뿐만 아니라 일반적인 벤치마크에서 더 적은 오류를 기록했습니다.
엔터프라이즈 데이터에 대해 추론할 수 있는 AI를 구축하는 데이터 인텔리전스에 중점을 두면서 가장 중요한 워크로드 중 하나는 고객이 직접 학습시키거나 Agent Bricks에서 생성한 미세 조정 모델을 서빙하는 것입니다. 하지만 수십 가지의 전문적인 사용 사례에 걸쳐 단편적인 요청을 처리할 때 전체 파라미터 미세 조정 모델은 경제적으로 확장되지 않습니다. (Hu et al, 2021)의 LoRA(Low Rank Adapters)와 같은 미세 조정 기법은 미세 조정 시 메모리 효율이 높고 비용을 관리하기 쉬워 널리 사용되는 접근 방식입니다. Databricks Research 팀(Biderman et al, 2024)과 커뮤니티(Schulman et al, 2025)의 연구를 통해 PEFT는 학습 기법으로서 유리한 특성을 가지고 있음이 입증되었습니다.
하지만 여기서 저희가 다루는 과제는 성능이나 모델 품질을 저하시키지 않으면서 PEFT 추론 을 대규모로 작동시키는 방법입니다.
세계 최고 수준의 추론 런타임
Databricks의 Model Serving 제품은 방대한 �양의 실시간 및 배치 데이터를 처리하며, 저희는 고객 워크로드에서 성능을 제공하려면 오픈 소스에서 제공하는 것 이상의 혁신이 필요하다는 것을 발견했습니다. 이것이 바로 저희가 기본 모델만 실행하는 경우에도 일부 사례에서 오픈 소스 대안보다 최대 1.8배 뛰어난 성능을 발휘하는 독점적인 추론 런타임과 주변 시스템을 구축한 이유입니다.
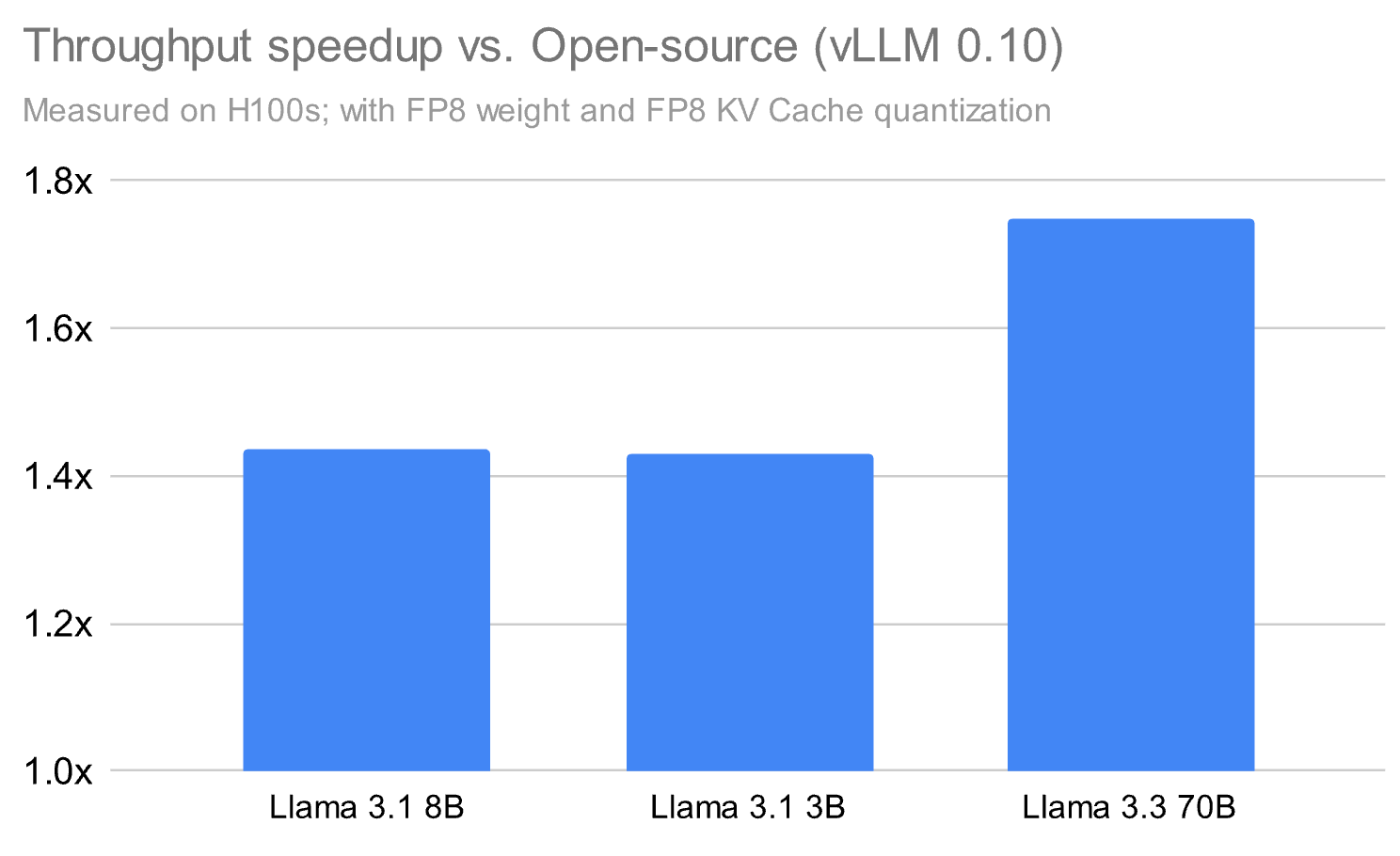
추론 런타임 자체를 넘어, 저희는 전체 프로덕션 스택을 해결하는 포괄적인 서빙 인프라를 구축했습니다: 확장성, 안정성 및 내결함성. 여기에는 자동 확장 및 로드 밸런싱, 다중 리전 배포, 상태 모니터링, 지능형 요청 라우팅 및 큐잉, 분산 상태 관리, 엔터프라이즈급 보안 제어 등 복잡한 분산 시스템 과제를 해결하는 것이 포함되었습니다.
이를 통해 고객은 빠른 추론 속도뿐만 아니라, 요구되는 안정성과 확장성으로 실제 엔터프라이즈 워크로드를 처리하는 프로덕션 지원 시스템을 구축할 수 있습니다. 저희는 커스텀 커널부터 최적화된 런타임에 이르기까지, 이러한 성능을 달성하기 위해 많은 혁신을 이루었습니다. 이번 블로그에서는 그중 한 가지 방법인 LoRA로 미세 조정한 모델을 빠르게 서빙하는 방법에 대해 집중적으로 다루겠습니다.
저희 작업의 기반이 된 핵심 원칙은 다음과 같습니다.
- 커널 우선이 아닌 프레임워크 우선으로 생각하기: 스택의 여러 계층에서 스케줄링, 메모리, 양자화가 어떻게 상호 작용하는지 이해하는 등 한발 물러서서 볼 때 가장 효과적인 최적화가 나타납니다.
- 양자화는 모델 품질을 존중해야 합니다: FP8을 활용하면 속도를 크게 높일 수 있지만, 정확도를 보존하는 하이브리드 형식 및 융합 커널과 결합될 때만 가능합니다.
- 중첩을 통한 처리량 극대화: 여러 스트림에 걸쳐 커널을 중첩하거나 SM 스로틀링을 사용해 단일 스트림 내에서 커널을 중첩하는 등, GPU 활용률을 극대화하는 것이 처리량 극대화의 핵심입니다.
- CPU 오버헤드는 종종 숨은 병목 현상을 유발합니다: 특히 소규모 모델의 경우, 추론 성능은 CPU가 GPU에 작업을 얼마나 빨리 준비하고 전달하는지에 따라 점점 더 제한됩니다. 또한 CPU 실행과 GPU 실행을 중첩하여 디코딩 단계 사이의 GPU 유휴 시간을 최소화하는 것도 중요합니다.
미세 조정 모델의 고속 서빙 심층 분석
다양한 매개변수 효율적 미세 조정(PEFT) 기법 중에서도 LoRA는 품질 보존과 계산 효율성 간의 균형 덕분에 가장 널리 채택된 PEFT 기법으로 자리 잡았습니다. Schulman 등의 종합적인 연구인 'LoRA Without Regret'과저희의 자체 연구 ' LoRA learnsless, forgets less'를 포함한 최근 연구에서는 효과적인 LoRA 사용을 위한 핵심 원칙을 입증했습니다. 즉, 모든 레이어(특히 MLP/MoE 레이어)에 LoRA를 적용하고 데이터 세트 크기에 맞춰 충분한 어댑터 용량을 확보하는 것입니다. 하지만 추론 시 우수한 컴퓨팅 효율성 을 달성하려면 단순히 이러한 원칙을 따르는 것만으로는 부족합니다. LoRA의 이론적인 FLOP 이점은 수많은 추론 시간 오버헤드로 인해 실제 성능 향상으로 자동적으로 이어지지 않습니다.
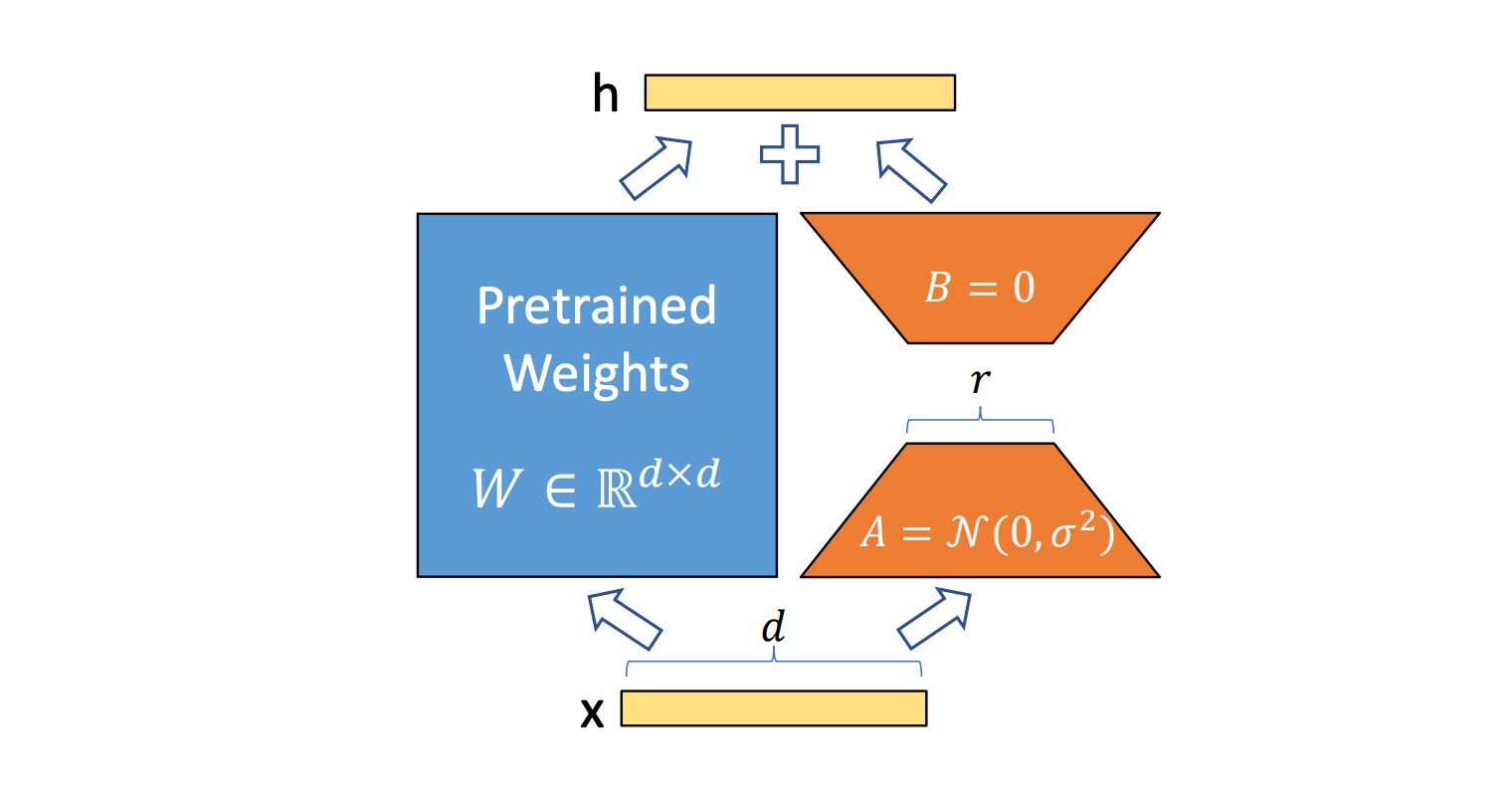
또한 최종 모델의 품질에 영향을 미치는 LoRA rank와 모델 추론 성능 사이에는 상충 관계가 있습니다. 저희 실험 결과, 대부분의 고객은 학습 중에 모델 품질이 저하되지 않도록 하려면 32 정도의 높은 rank가 필요했습니다. 하지만 이는 추론 시스템의 최적화에 부담을 줍니다.
프로덕션 시스템에서 서버는 다양한 수의 LoRA 요�청을 처리해야 하며, 이는 성능 최적화에 있어 어려운 과제입니다. 기존 접근 방식은 LoRA를 서빙할 때 상당한 오버헤드를 유발하며, 실제 시나리오에서는 추론 속도를 최대 60%까지 저하시키기도 합니다.
추론 중에 LoRA 어댑터는 기본 모델의 선형 레이어와 병렬로 각 개별 어댑터와 각 토큰에 대해 저계수 행렬 곱셈으로 적용됩니다. 이러한 행렬 곱셈은 일반적으로 오픈 소스 커뮤니티의 모델에서 관찰되는 차원보다 작은 내부 및 외부 차원을 포함합니다. 예를 들어, Llama 3.1 8B 모델 과 같은 오픈 소스 모델의 일반적인 은닉 차원은 8192인 반면, LoRA 행렬 곱셈의 순위 차원은 8까지 낮아질 수 있습니다. 따라서 오픈 소스 커뮤니티는 이러한 설정에 대한 커널 최적화와 이러한 시나리오에서 하드웨어 활용도를 극대화하는 기술에 상당한 노력을 투자하지 않았습니다.
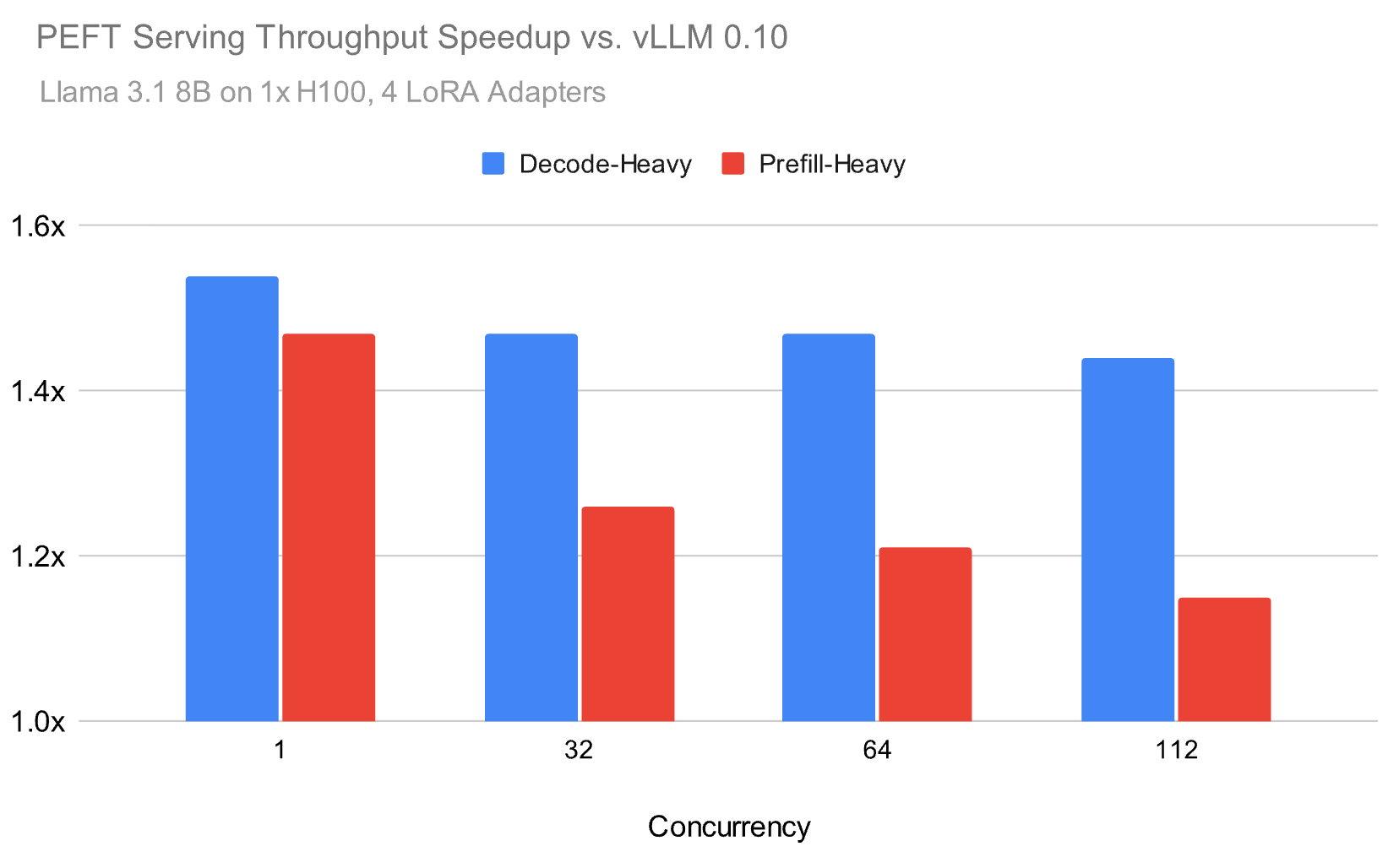
지난 1년 동안 저희는 이러한 문제를 해결하기 위해 추론 런타임을 개발했으며, 그림 1에서 볼 수 있듯이 실제 환경에서 LoRA를 서빙할 때 오픈 소스에 비해 최대 1.5배의 속도 향상을 달성할 수 있습니다. 예를 들어, 아래에서는 평균 4개의 어댑터를 가진 LoRA 어댑터에 대해 Zipf 분포를 사용하여 Meta Llama 3.1 8B 모델을 벤치마킹합니다.
저희의 추론 런타임은 프리필 중심 및 디코드 중심 워크로드 모두에서 널리 사용되는 오픈 소스 대안보다 최대 1.5배 더 높은 처리량 을 달성하며, 부하가 높을수록 성능 격차는 좁혀지지만 여전히 상당한 수준을 유지합니다. 이러한 속도 향상을 달성하기 위해 저희는 이 블로그에서 설명하는 몇 가지 구성 요소에 집중했습니다.
- 품질은 성능 최적화만큼이나 중요합니다. 저희는 커스텀 Attention 및 GEMM 구현을 통해 주요 벤치마크에서 모델 품질을 유지하면서 성능을 극대화할 수 있었습니다.
- GEMM에서 작은 행렬 곱셈을 더 잘 처리하기 위해 멀티프로세서 간 및 내부에서 GPU 리소스를 분할합니다.
- 시스템의 병목 현상을 최소화하기 위해 커널 실행의 중첩을 최적화합니다.
기반 모델 품질을 보존하는 양자화
더 낮은 정밀도의 하드웨어 장치를 활용하기 위한 양자화는 성능의 핵심이지만 품질에 영향을 미칠 수 있습니다. 모델 제공업체는 일반적으로 추론 중에 모델을 fp8로 압축합니다. 반대로, 학습 은 품질에 더 민감하므로 LoRA 어댑터의 미세 조정은 일반적으로 모델의 기본 정밀도(bf16)에서 수행됩니다. 이러한 불일치는 PEFT 모델을 서빙하는 데 어려움을 초래하며, 학습 설정을 가장 잘 모방하기 위해 추론 중에 기본 모델의 품질이 보존되도록 보장하면서 하드웨어 리소스를 극대화해야 합니다.
성능을 최적화하면서 품질을 유지하기 위해 저희는 자체 런타임에 몇 가지 맞춤형 기술을 개발했습니다. 아래 표에서 볼 수 있듯이, 저희의 최적화는 전체 정밀도로 서빙하는 것과 비교하여 학습된 어댑터의 품질을 유지할 수 있습니다. 이것이 저희 런타임이 오픈 소스 런타임에 비해 벤치마크에서 더 빠를 뿐만 아니라 품질도 더 높은 이유 중 하나입니다.
아래 나열된 작업을 위해 미세 조정된 PEFT 어댑터 PEFT Llama 3.1 8B instruct | 전체 정밀도 (정확도 ± 표준 편차) % | Databricks 추론 런타임 | vLLM 0.10 |
Humaneval | 74.02 ± 0.16 | 73.66 ± 0.39 | 71.88 ± 0.44 |
수학 | 59.13 ± 0.14 | 59.13 ± 0.06 | 57.79 ± 0.36 |
그림 4, 저희의 맞춤형 변경을 통해 기본 모델이 BF16으로 서빙되는 기준선의 품질을 더 가깝게 유지할 수 있습니다. vLLM 0.10을 사용한 모든 측정은 FP8 텐서 단위 가중치, 동적 활성화, KV 캐시 양자화를 활성화한 상태에서 이루어졌습니다.
엄격한 품질 검증
양자화를 프로덕션에 �적용하면서 얻은 핵심 교훈은 엄격한 품질 검증의 필요성입니다. Databricks에서는 단순히 모델을 벤치마킹하는 데 그치지 않고, 감지할 수 있는 성능 저하가 발생하지 않도록 양자화된 출력과 전체 정밀도 출력 간의 상세한 통계적 비교를 실행합니다. 저희가 배포하는 모든 최적화는 그것이 제공하는 성능 향상에 관계없이 이 기준을 충족해야 합니다.
양자화는 또한 로컬 최적화가 아닌 프레임워크 수준의 문제로 다루어져야 합니다. 양자화 자체만으로도 오버헤드나 병목 현상이 발생할 수 있습니다. 하지만 커널 융합이나 워프 전문화와 같은 커널 내 처리 기술과 조화를 이루면 이러한 오버헤드를 완전히 숨길 수 있어 품질과 성능을 모두 얻을 수 있습니다. 아래 섹션에서는 이를 가능하게 한 구체적인 양자화 전략에 대해 자세히 알아보겠습니다.
FP8 가중치 양자화
모델의 가중치를 양자화하는 데는 여러 가지 접근 방식이 있으며, 각각 장단점이 있습니다. 일부 양자화 기법은 스케일 팩터(scale factor)의 배치가 더 세분화(granular)되어 있는 반면, 다른 기법들은 덜 세분화(coarse-grained)되어 있습니다. 덜 세분화된(coarse-grained) 이러한 접근 방식은 활성화 텐서를 양자화하는 동안 더 높은 오차를 유발하지만 오버헤드는 더 적습니다.
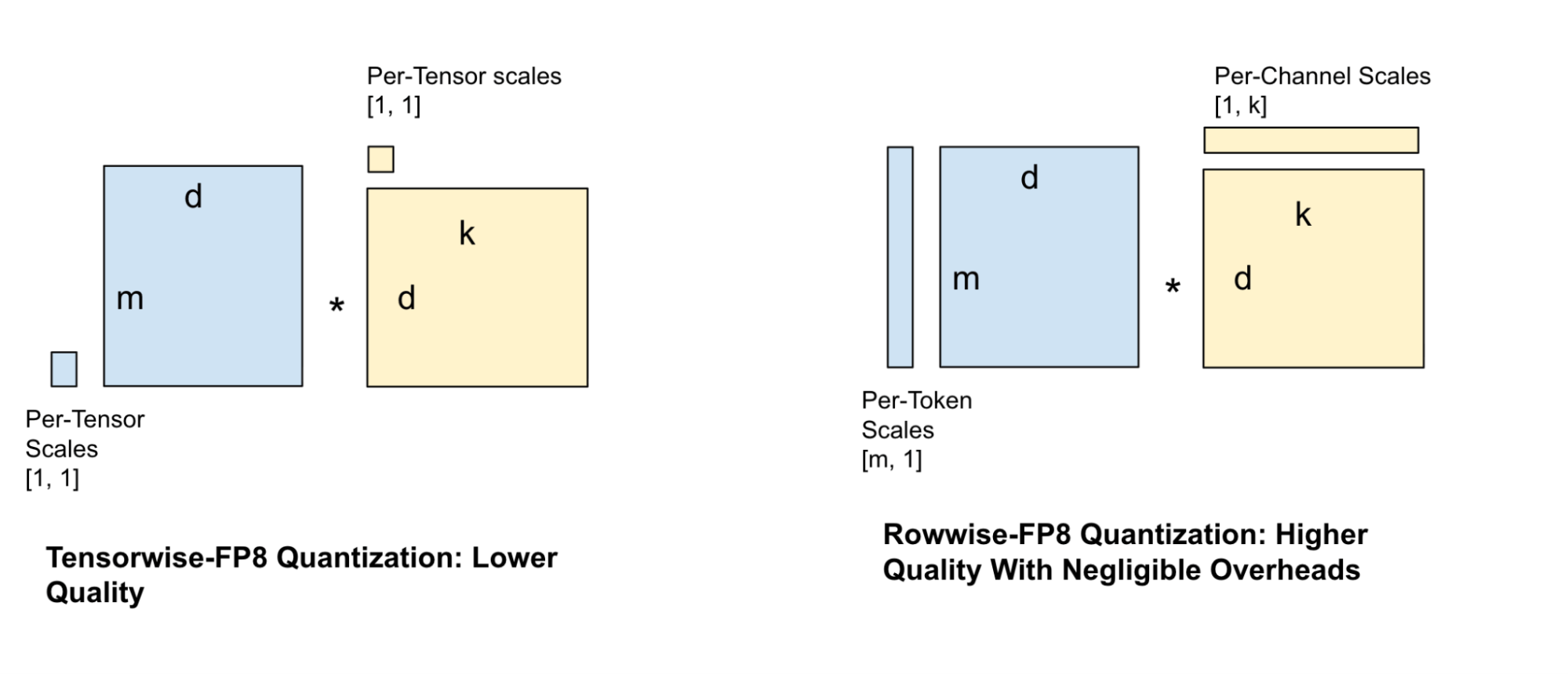
모델 서빙을 위한 인��기 있는 양자화 기법은 텐서 단위 FP8 양자화로, 전체 텐서에 하나의 스케일 팩터가 할당됩니다. 하지만 이 기법은 손실이 많고 특히 작은 모델의 경우 상당한 품질 저하를 초래합니다. 이로 인해 더 세분화된 스케일 팩터가 필요하게 되었고, 저희는 채널별 및 블록별 스케일과 같은 가중치 및 활성화를 위한 다양한 스케일 팩터 구성을 시도하게 되었습니다. GEMM 속도와 품질 손실의 균형을 맞추기 위해, 저희는 그림 4와 같이 행 단위 스케일 팩터 구성을 선택했습니다.
활성화에 대한 더 세분화된 스케일 팩터를 계산하는 성능 오버헤드를 극복하기 위해, 저희는 추가 컴퓨팅의 오버헤드를 숨기기 위해 이전의 대역폭 제한 작업과 몇 가지 중요한 커널 융합을 수행합니다.
하이브리드 어텐션
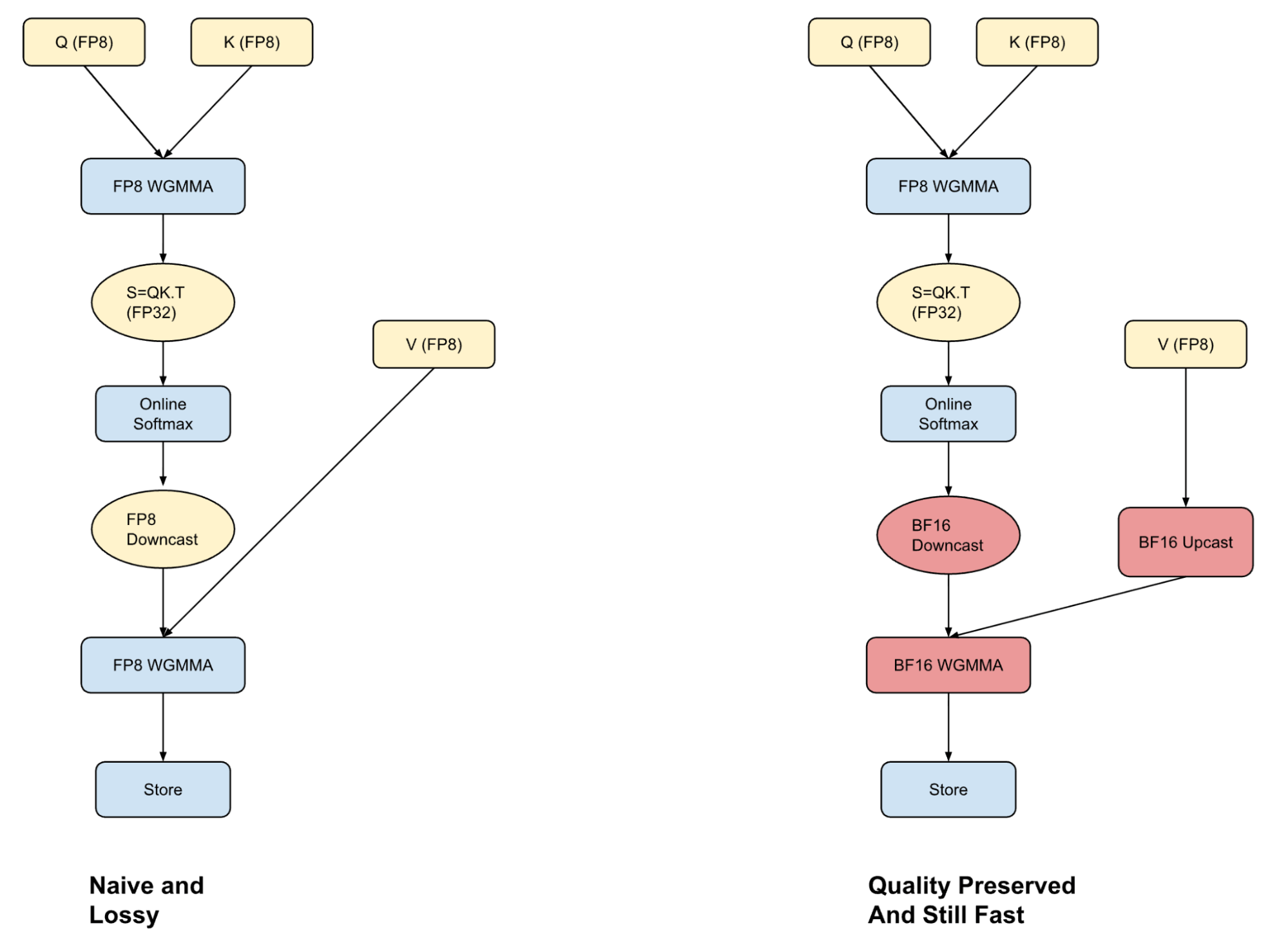
컨텍스트 길이가 긴 소규모 모델의 경우, 전체 계산 시간의 최대 50%를 차지할 수 있는 Attention 연산은 Transformer 기반 추론의 핵심적인 부분입니다. 추론 중 디코딩 속도를 높이는 일반적인 방법 중 하나는 프리필(prefill) �단계의 Key 값 출력을 캐싱하는 것입니다.
KV 캐시를 FP8 형식으로 저장하면 처리량을 향상시킬 수 있지만, 모든 이점을 얻으려면 FP8 입력을 정확하고 빠르게 처리할 수 있는 어텐션 커널이 필요합니다. 대부분의 프레임워크는 어텐션을 전적으로 FP8(빠르지만 손실이 많음)으로 수행하거나 BF16(업캐스팅으로 인해 더 정확하지만 느림)을 사용합니다. 저희는 하이브리드 어텐션으로 중간 경로를 택했습니다. 즉, 두 형식의 강점을 혼합하여 성능과 품질 간의 더 나은 균형을 달성합니다.
FP8 어텐션 계산의 양자화 오류가 softmax 계산을 더 낮은 비트 표현으로 다운캐스팅하는 데서 비롯된다는 것을 발견한 후 이 형식으로 수렴했습니다. 계산의 첫 부분을 FP8로 수행하고 Hopper GPU에서 워프 전문화 전략을 활용함으로써, V-벡터의 업캐스트를 Q-K 계산과 중첩시킬 수 있습니다. 이를 통해 성능 저하 없이 P-V 계산을 BF16으로 실행할 수 있습니다. 이는 모든 계산을 FP8로 수행하는 것보다 여전히 느리지만, 더 중요한 것은 하이브리드 접근 방식이 모델 품질을 저하시키지 않는다는 것입니다.
저희의 연구는 Zhang et al.의 SageAttention 및 SageAttention2 와 같은 학계에서 제안된 유사한 접근 방식과 CharacterAI의 블로그를 기반으로 합니다.
RoPE 이후의 퓨전 고속 아다마르 변환
주어진 토큰에 대한 쿼리와 키는 어텐션 모듈의 시작 부분에서 임베딩 x로부터 다음과 같이 계산된다는 점을 상기해 봅시다:
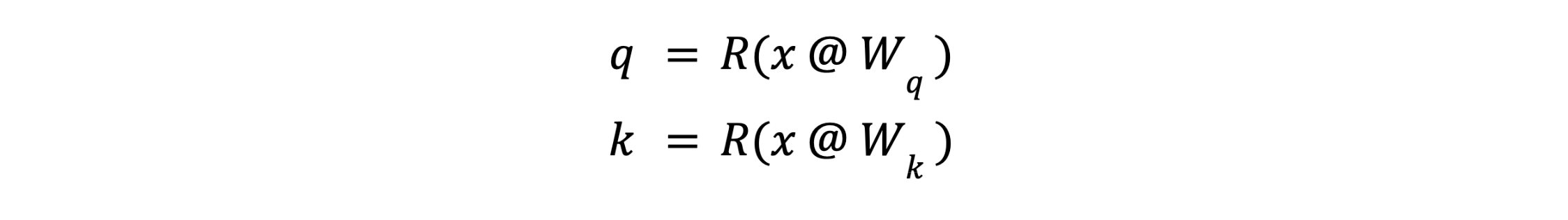
여기서 R()은 RoPE 임베딩 연산자입니다. RoPE 후에는 q나 k의 정확한 값을 보존할 필요는 없으며, 모든 쿼리 q와 키 k에 대한 내적 q.T @ k만 보존하면 됩니다. 이를 통해 q와 k에 선형 변환 U를 적용할 수 있습니다.
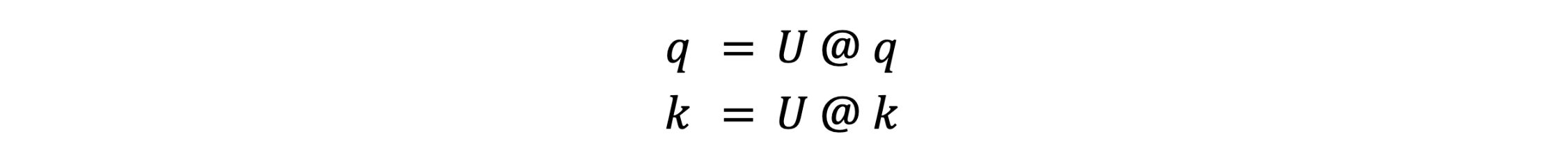
여기서 U.T @ U = I는 항등 행렬입니다. 이로 인해 어텐션 계산 중에 U가 상쇄됩니다:
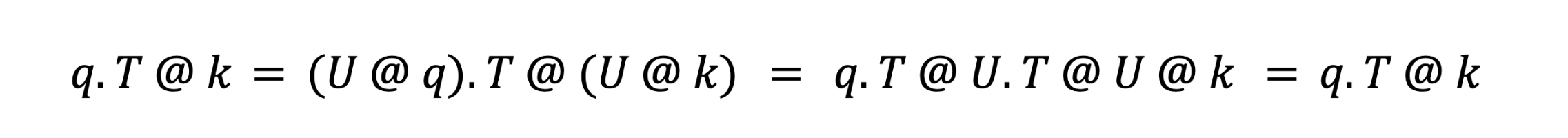
이를 통해 attention 계산을 (수학적으로) 변경하지 않으면서 양자화에 최적화되도록 q와 k 벡터를 조정할 수 있습니다. 저희가 사용하는 구체적인 변환은 고속 아다마르 변환(Fast Hadamard Transform, FHT)으로, O(log2(D)) 연산만으로 D개의 채널에 분산을 고르게 분배할 수 있습니다. 이렇게 분산을 분배하면 이상치가 제거되고 더 작은 FP8스케일을 사용할 수 있습니다. 이는 더 나은 해상도를 위해 '확대'하는 것과 같다고 �생각할 수 있습니다. 이 연구는 학계에서 제안된 Dao 등의 ' FlashAttention3'나 Ashkboos 등의 ' QuaRot'과 같은 유사한 접근 방식을 기반으로 합니다.
오버헤드를 피하기 위해 저희는 RoPE, FHT, 양자화 및 KV 캐시에 추가하는 작업을 융합하는 커널을 작성했습니다.
PEFT 오버헤드를 최소화하기 위한 커널 중첩
LoRA를 사용한 추론 중에 어댑터 랭크는 행렬 곱셈의 차원 중 하나를 나타냅니다. 랭크는 일반적으로 작을 수 있으므로(예: 8 또는 32), 이는 비대칭 차원의 행렬 곱셈으로 이어져 추론 중에 추가적인 오버헤드를 발생시킵니다(그림 1).
따라서 Zhu et al.의 Nanoflow 연구 에서 영감을 받아, 저희는 LoRA 커널을 기본 모델 및 커널 자체와 중첩시켜 이 오버헤드를 숨기는 다양한 전략을 탐색해 왔습니다.
그림 1에서 설명한 것처럼 LoRA 추론은 'Shrink' 커널로 정의되는 하향 프로젝션 커널과 'Expand' 커널로 정의되는 상향 프로젝션 커널, 이렇게 두 가지 주요 커널로 구성됩니다. 일반적으로 여러 LoRA 어댑터를 동시에 서빙하기 때문에, 이 커널들은 주로 Grouped GEMM(각 GEMM이 서로 다른 어댑터에서 작동) 형태를 띱니다. 이를 통해 아래 그림 6에서 설명하는 것처럼, 이러한 Grouped GEMM을 기본 모델의 계산과 중첩하고, Shrink 커널과 Expand 커널을 서로 중첩시킬 수 있습니다.
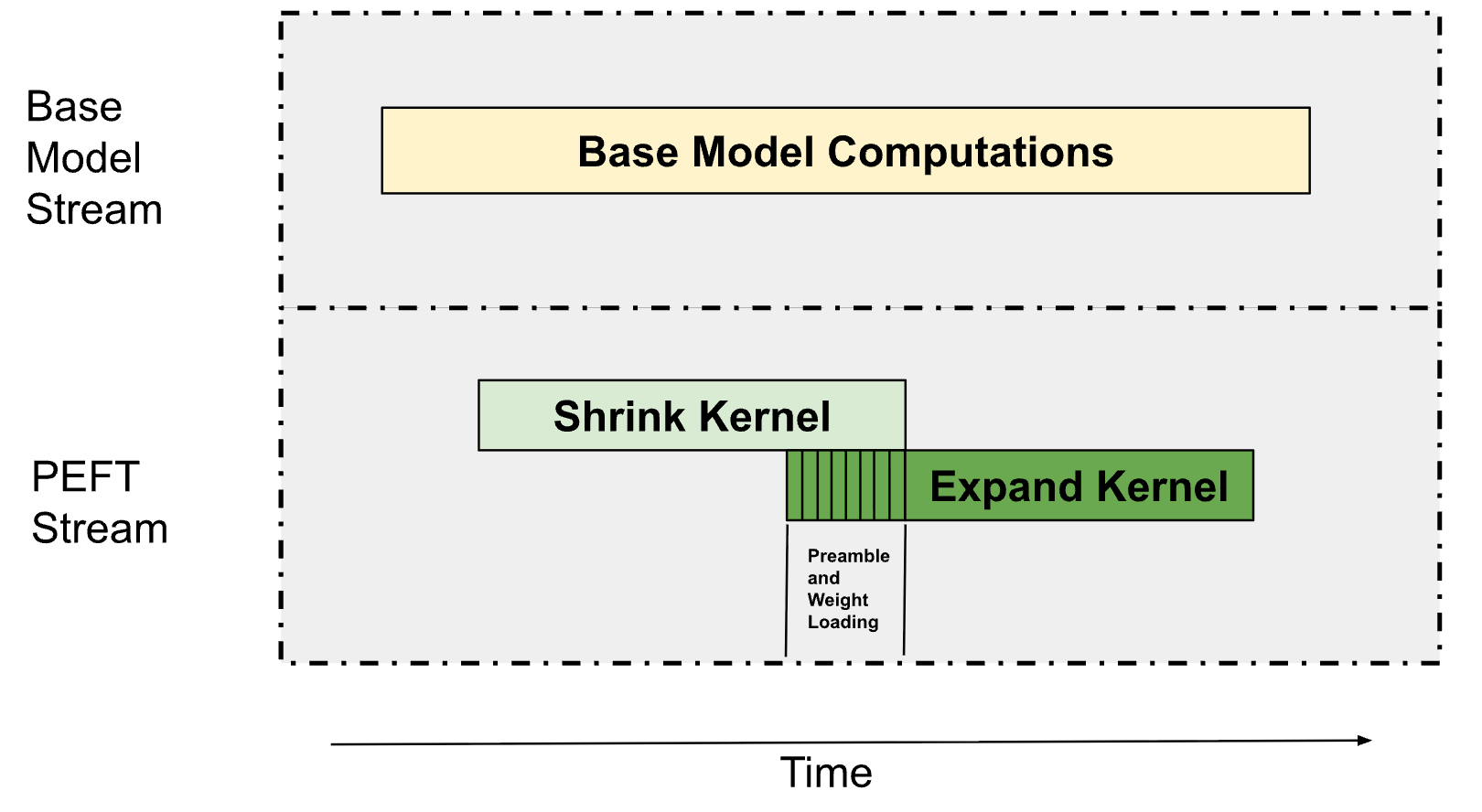
멀티프로세서 분할을 사용한 병렬 스트림
표면적으로는, 서로 다른 데이터에 의존하는 커널 실행을 별도의 스트림에서 시작하여 간단하게 중첩시킬 수 있습니다. 이 접근 방식은 본질적으로 컴퓨팅 작업 분배기가 다양한 커널 실행 블록을 스케줄링하는 방식에 의존합니다. 하지만 이 방법은 사용되지 않는 컴퓨팅 용량이 충분할 때만 효과가 있습니다. 일반적으로 GPU를 포화시키는 대규모 워크로드의 경우, 더 정교한 접근 방식이 필요합니다.
여기서 더 나아가 저희는 대역폭 제한 커널에 필요한 스트리밍 멀티프로세서(SM)의 수를 성능에 큰 영향을 주지 않으면서 분할할 수 있다는 것을 깨달았습니다. 대부분의 시나리오에서 저희는 대역폭 제한 커널이 GPU의 전체 메모리 대역폭에 액세스하기 위해 모든 가능한 SM을 필요로 하지 않는다는 것을 발견했습니다. 따라서 저희는 이러한 커널에서 사용하는 SM의 수를 제한한 다음, 나머지 멀티프로세서를 사용하여 다른 계산을 수행할 수 있습니다.
PEFT의 경우, 기본 모델용 스트림과 PEFT 경로용 스트림, 두 개의 스트림을 실행합니다. 기본 모델은 GPU에서 SM의 최대 75%를 받고 나머지는 PEFT 경로로 갑니다. 이러한 분할을 통해 기본 모델 경로는 크게 느려지지 않는 반면, PEFT 경로는 백그라운드에서 실행되어 대부분의 경우 PEFT의 오버헤드를 숨길 수 있다는 것을 발견했습니다.
종속 실행을 사용한 동일 스트림
서로 다른 데이터에 의존하는 커널 실행은 여러 스트림에 걸쳐 쉽게 중첩할 수 있지만, 동일한 스트림 내에서 종속 관계에 있는 커널 실행은 각 커널이 이전 커널이 완료될 때까지 기다려야 하므로 중첩하기가 더 어렵습니다. 이 문제를 해결하기 위해 저희는 PDL(Programmatic Dependent Launch)을 사용합니다. 이를 통해 현재 커널이 실행되는 동안 다음 커널의 가중치를 미리 가져올 수 있습니다.
PDL은 동일한 스트림의 기본 커널 실행이 완료되기 전에 종속 커널을 시작할 수 있게 해주는 고급 CUDA 런타임 기능입니다. 이는 아래 그림 8에 설명되어 있습니다.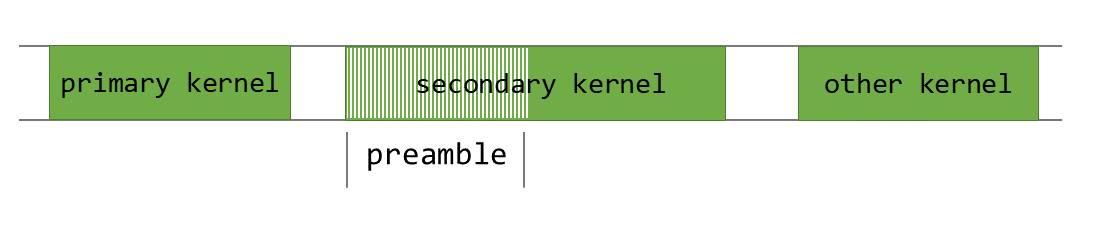
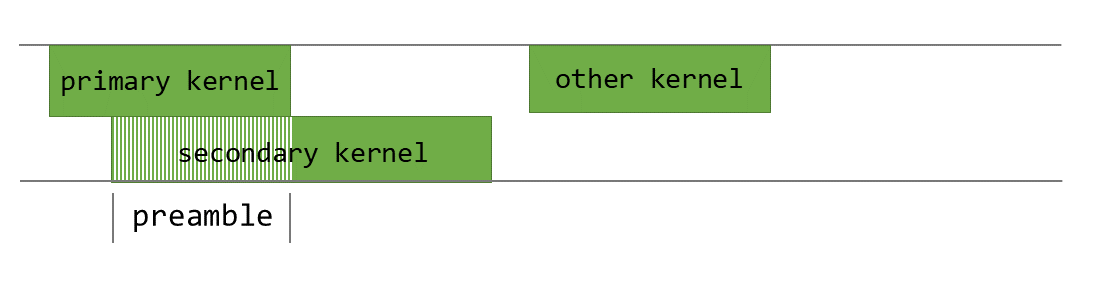
PEFT 커널의 경우, 저희는 PDL을 사용하여 축소 및 확장 작업을 중첩시킵니다. 축소 커널이 실행되는 동안, 저희는 확장 커널에 필요한 가중치를 공유 메모리와 L2 캐시로 미리 가져옵니다. 저희는 확장 커널이 실행될 수 있는 충분한 리소스가 있도록 축소 커널의 공유 메모리와 레지스터 리소스를 조절합니다. 이를 통해 축소 커널이 계산을 완료하는 동안 확장 커널이 가중치 처리를 시작할 수 있습니다. 축소 커널이 완료되면 확장 커널은 활성화를 로드하고 행렬 곱셈 계산을 수행하기 시작합니다.
결론
고객이 데이터를 활용하여 고유한 인사이트를 도출할 수 있도록 지원하는 것은 여기 Databricks 전략의 핵심 부분입니다. 이것의 핵심 부분은 추론 런타임에서 LoRA 요청을 성공적으로 처리할 수 있는 것입니다. 저희가 공유한 기술들, 즉 양자화 형식에서 커널 융합, SM 수준 스케줄링에서 CPU-GPU 중첩에 이르기까지 모두 이 프레임워크 우선 철학에서 비롯되었습니다. 각 최적화는 속도를 위해 정확성을 희생하지 않도록 엄격한 품질 벤치마크에 대해 검증되었습니다.
앞으로 저희는 더 많은 메가커널 전략과 더 스마트한 스케줄링 메커니즘으로 더욱 발전해 나갈 것을 기대하고 있습니다.
LLM 추론을 시작하려면 저희 플랫폼에서 Databricks Model Serving 을 사용해 보세요.
저자: Nihal Potdar, Megha Agarwal, Hanlin Tang, Asfandyar Qureshi, Qi Zheng, Daya Khudia
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.