Spark JDBC를 사용하여 Databricks로 실시간 SAP HANA 데이터를 통합하는 가장 빠른 방법
작성자: 크리슈나 사티아바라푸
Databricks와 SAP의 최근 전략적 파트너십 발표는 SAP 고객들 사이에서 큰 반향을 일으켰습니다. 데이터 및 AI 전문가인 Databricks는 SAP HANA를 Databricks와 통합하여 분석 및 ML/AI 기능을 활용할 수 있는 매력적인 기회를 제공합니다. 이 협업에 대한 엄청난 관심에 힘입어 심층적인 블로그 시리즈를 시작하게 되어 기쁩니다.
많은 고객 시나리오에서 SAP HANA 시스템은 SAP CRM, SAP ERP/ECC, SAP BW를 포함한 다양한 소스 시스템의 데이터 기반 역할을 합니다. 이제 이 강력한 SAP HANA 분석 사이드카 시스템을 Databricks와 원활하게 통합하여 조직의 데이터 기능을 더욱 향상시킬 수 있는 흥미로운 가능성이 열렸습니다. SAP HANA(HANA Enterprise Edition 라이선스 포함)를 Databricks와 연결함으로써 기업은 SAP HANA에 저장된 풍부하고 통합된 데이터를 활용하면서 Databricks의 고급 분석 및 머신러닝 기능(MLflow, AutoML, MLOps 등)을 활용할 수 있습니다. 이 통합은 조직이 귀중한 인사이트를 발굴하고 SAP 시스템 전반에 걸쳐 데이터 기반 의사결정을 내릴 수 있는 무한한 가능성을 열어줍니다.
Databricks에서 SAP HANA 테이블, SQL 뷰, 계산 뷰를 통합하는 여러 가지 방법이 있습니다. 하지만 가장 빠른 방법은 SparkJDBC를 사용하는 것입니다. 가장 큰 장점은 SparkJDBC가 Spark 워커 노드에서 원격 HANA 엔드포인트로 병렬 JDBC 연결을 지원한다는 것입니다.
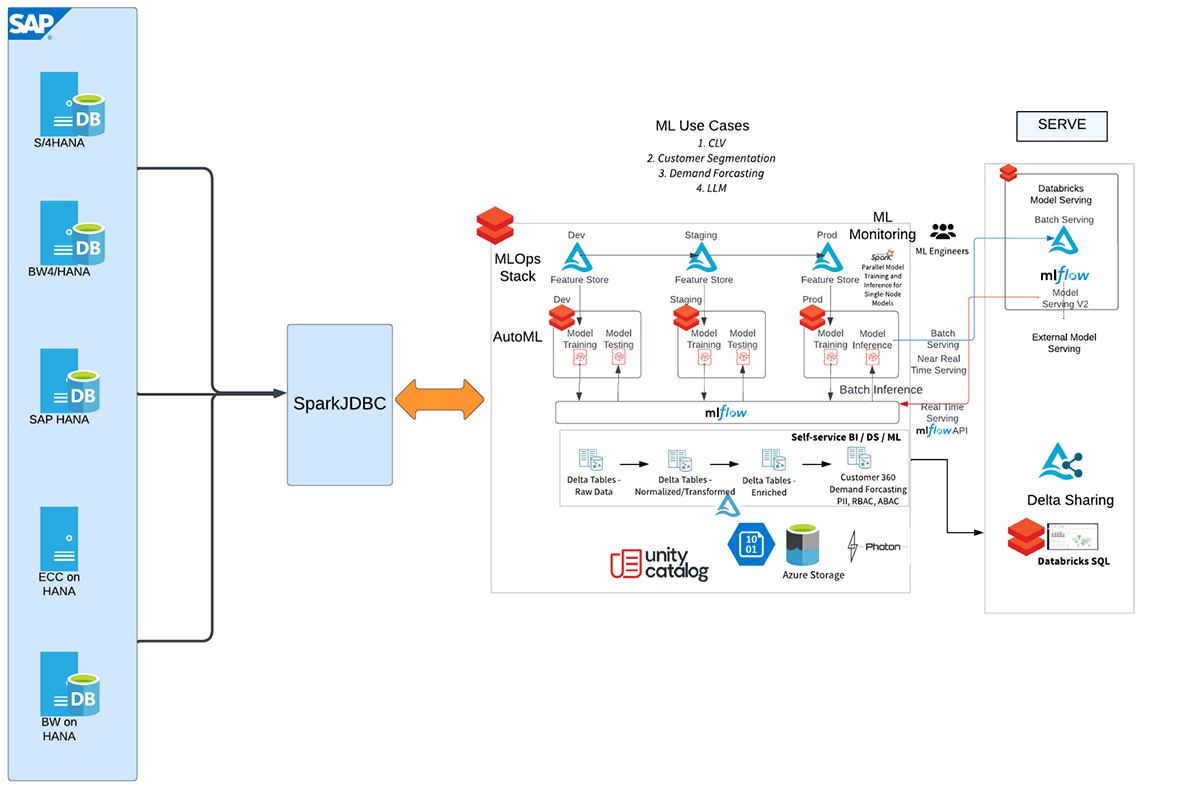
SAP HANA와 Databricks 통합 시작하기
먼저 Azure 클라우드에 SAP HANA 2.0을 설치하고 Databricks와의 통합을 테스트했습니다.
Azure에 설치된 SAP HANA 정보:
| 버전 | 2.00.061.00.1644229038 |
| 브랜치 | fa/hana2sp06 |
| 운영 체제 | SUSE Linux Enterprise Server 15 SP1 |
이 통합의 다양한 단계를 보여주는 개략적인 워크플로우는 다음과 같습니다.
SparkJDBC를 사용하여 SAP HANA의 계산 뷰 및 테이블에서 Databricks로 데�이터를 추출하는 방법에 대한 자세한 지침은 첨부된 노트북을 참조하십시오.

아래 이미지와 같이 SAP HANA JDBC jar(ngdbc.jar)를 구성하십시오.
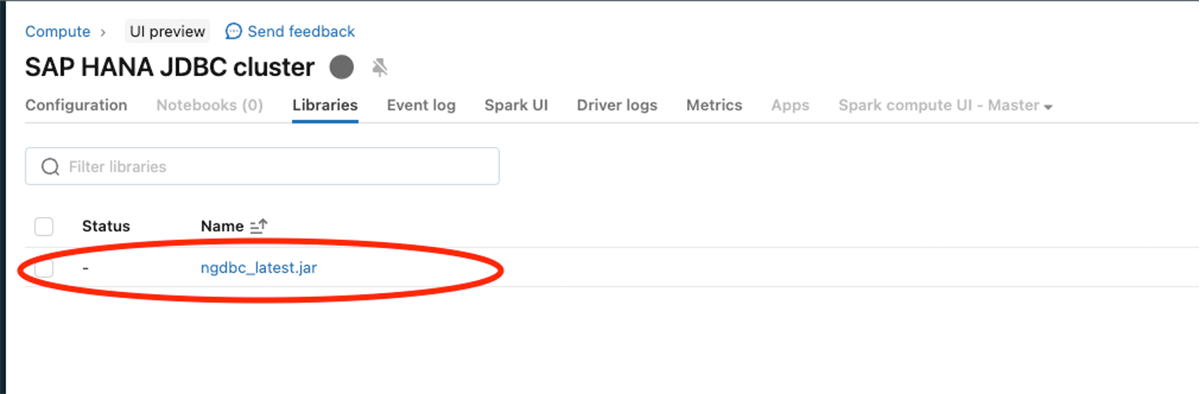
위 단계를 수행한 후 SAP HANA 서버 및 JDBC 포트를 사용하여 spark read를 수행합니다.
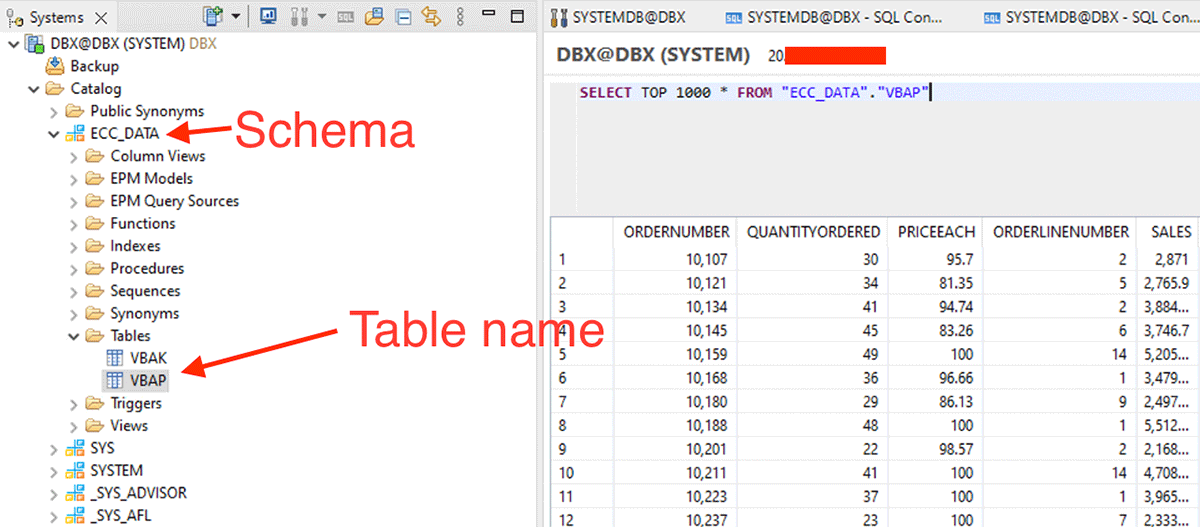
아래와 같이 스키마, 테이블 이름을 사용하여 데이터프레임을 생성하기 시작합니다.
또한 dbtable 옵션에 SQL 문을 전달하여 필터 푸시다운을 수행할 수 있습니다.
계산 뷰에서 데이터를 가져오려면 다음을 수행해야 합니다.
예를 들어, 이 XS-classic 계산 뷰는 내부 스키마 "_SYS_BIC"에 생성되었습니다.
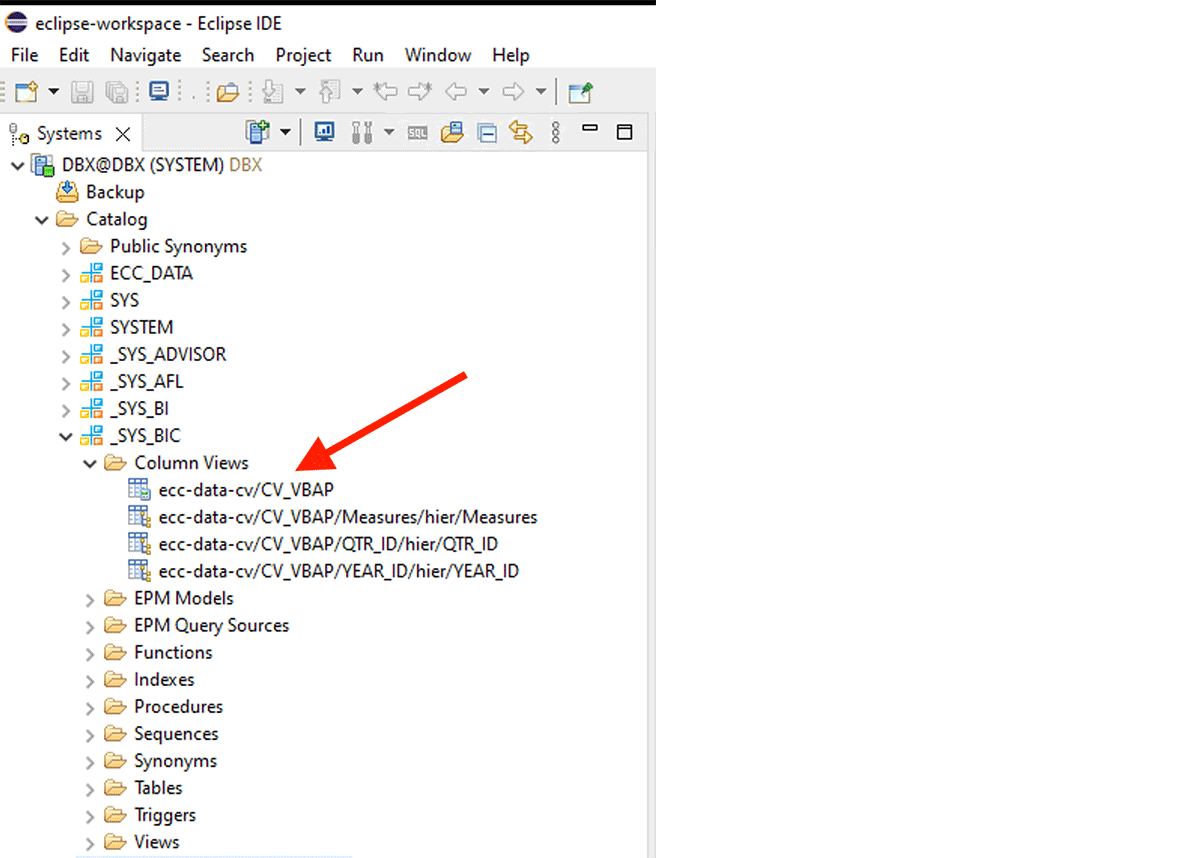
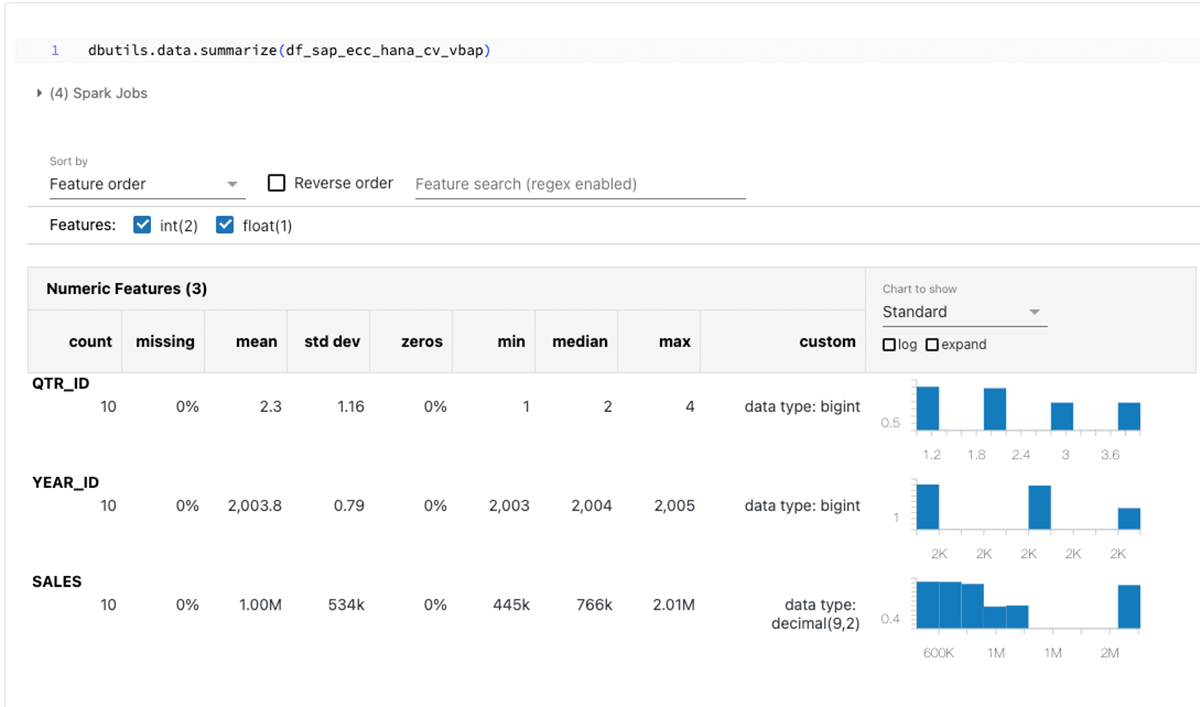
이 코드 조각은 PySpark 데이터프레임 "df_sap_ecc_hana_cv_vbap"을 생성하고 SAP HANA 시스템(이 경우 CV_VBAP)의 계산 뷰에서 이 데이터프레임을 채웁니다.
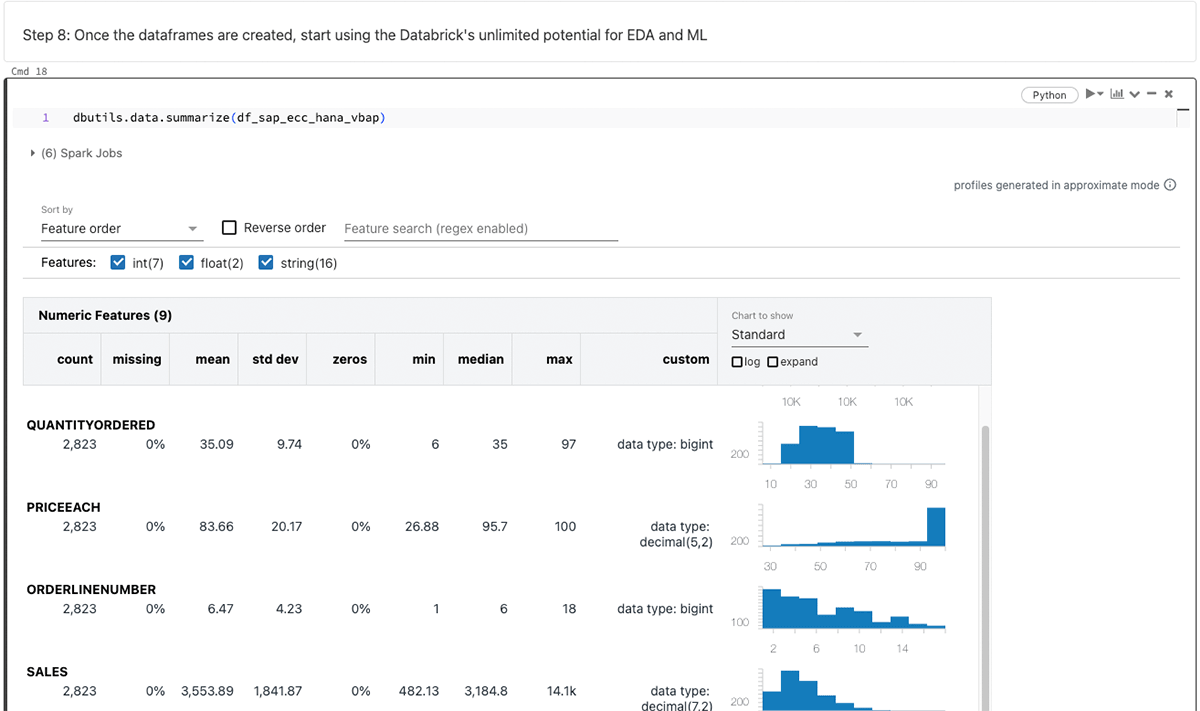
PySpark 데이터프레임을 생성한 후 Databricks의 무한한 기능을 활용하여 탐색적 데이터 분석(EDA) 및 머신러닝/인공지능(ML/AI)을 수행합니다.
위의 데이터프레임을 요약합니다.
이 블로그는 SAP HANA용 SparkJDBC에 중점을 두지만, 유사한 목적으로 FedML, hdbcli, hana_ml과 같은 대체 방법을 사용할 수 있다는 점에 주목할 가치가 있습니다.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.