레이크베이스 아키텍처가 Postgres 쓰��기 속도를 5배 더 빠르게 만드는 방법
관리형 Postgres의 구조적 성능 병목 현상 해결
작성자: David Wein , Vlad Lazar
- Lakebase는 이제 쓰기 집약적인 OLTP 워크로드에 대해 최대 5배 더 빠른 처리량을 제공하며, 이는 고확장 Postgres 애플리케이션의 일반적인 문제점입니다.\r\n* Lakebase 아키텍처를 통해 중요한 크래시 복구 작업을 컴퓨팅 계층에서 분산 스토리지로 오프로드할 수 있습니다.\r\n* 프로덕션 샘플링 결과, 내구성을 위험에 빠뜨리지 않으면서 읽기 꼬리 지연 시간을 2배 줄이는 동시에, 32 vCPU 컴퓨팅에서 4.5배의 쓰기 처리량 개선과 WAL 트래픽 94% 감소가 나타났습니다.\r\n
lakebase에서는 컴퓨팅과 스토리지가 설계상 분리되어 있습니다. 이러한 분리는 원래 확장성, 브랜칭, 즉각적인 복구를 포함한 운영 유연성을 위해 구축되었지만, 막대한 성능의 지평을 열어주기도 합니다.
이러한 계층들을 분리함으로써, 기존의 모놀리식 Postgres 배포에서는 구조적으로 불가능했던 방식으로 Postgres 컴퓨팅의 작업을 분산 스토리지로 오프로드할 수 있습니다. 이 게시물에서는 이러한 아키텍처적 이점을 활용하여 10년 묵은 Postgres 병목 현상을 제거하고 Postgres 쓰기 처리량을 5배 향상시키면서 읽기 꼬리 지연 시간을 2배 줄이고 WAL 트래픽을 94% 감소시킨 방법을 살펴보겠습니다.
기존 Postgres 내구성의 숨겨진 비용
관리형 Postgres 성능에서 5배 향상을 달성한 방법을 이해하려면 기존 Postgres가 내구성을 처리하는 방식을 살펴봐야 합니다.
Postgres에서는 모든 데이터베이스 변경 사항이 충돌 시 데이터 손실을 방지하기 위해 먼저 순차 로그(WAL 또는 Write-Ahead Log)에 저장됩니다. 충돌 복구 시간을 빠르게 유지하기 위해 Postgres는 주기적으로 "�체크포인트"라는 백그라운드 정리 이벤트를 수행합니다. 스냅샷과 달리 체크포인트는 로그의 단순한 이정표 마커입니다. 체크포인트 동안 Postgres는 현재 메모리에 있는 모든 수정된 데이터("페이지"라고 불리는 8KB 청크로 관리됨)를 가져와 로그의 특정 지점까지 주 디스크에 플러시합니다. 충돌이 발생하면 Postgres는 해당 체크포인트 이정표에서 시작하여 최근 WAL 로그를 디스크에 다시 재생하여 데이터를 복원합니다.
그러나 위험이 있습니다. 서버가 8KB 페이지를 디스크에 저장하는 동안 정확히 충돌하면 페이지가 부분적으로만 기록되어 손상된 "찢어진 페이지(torn page)"가 발생할 수 있습니다. Postgres가 찢어진 페이지 위에 작은 로그 업데이트를 다시 재생하려고 하면 데이터가 영구적으로 손상됩니다. 이를 해결하기 위해 Postgres는 복구를 위해 손상된 디스크에 의존하지 않도록 해야 합니다.
이는 "전체 페이지 쓰기(Full Page Write)"(FPW)를 사용하여 수행됩니다. 체크포인트 이정표 이후 페이지가 처음 수정될 때 Postgres는 작은 변경 사항만 기록하는 것이 아니라 전체 8KB 페이지를 WAL에 복사합니다. 충돌이 발생하여 디스크 페이지가 찢어진 경우, Postgres는 손상된 디스크를 무시하고 WAL에서 원본 8KB 백업을 가져와 나머지 로그를 다시 재생하는 완벽한 시작점으로 사용합니다. 이는 절대적인 안전을 보장하지만 비용이 많이 듭니다. 쓰기 작업이 많은 애플리케이션에서는 전체 8KB 페이지를 기록하면 로그 볼륨이 최대 15배까지 증가할 수 있으며, 종종 시스템의 가장 큰 성능 병목 현상이 됩니다.
lakebase 솔루션: 찢어진 페이지 위험 제거
lakebase 아키텍처에서 컴퓨팅은 상태 비저장(stateless)입니다. 로컬 데이터 디렉토리에 의존하지 않습니다. 대신 WAL을 Paxos 기반의 안전 관리자(safekeepers) 쿼럼으로 스트리밍합니다.
찢어질 로컬 디스크 페이지가 없으므로 FPW가 방지하도록 설계된 장애 모드는 단순히 존재하지 않습니다. 그러나 FPW를 순진하게 끄면 두 번째 문제인 읽기 성능이 발생합니다. 로그에 주기적인 전체 페이지 이미지가 없으면 스토리지 계층은 읽기 요청을 위해 페이지를 재구성하기 위해 무한히 긴 작은 델타 체인을 다시 재생해야 합니다. 한때 유한했던 O(체크포인트 빈도) 재생은 무한한 체인이 되어 읽기 지연 시간과 리소스 소비의 급증으로 이어집니다.
혁신: 분산 스토리지로의 이미지 생성 푸시다운
우리는 컴퓨팅 노드에서 스토리지 계층으로 인텔리전스를 이동하여 이 문제를 해결했습니다. 이를 이미지 생성 푸시다운이라고 부릅니다.
Postgres 컴퓨팅이 스토리지에서 페이지를 요청하면 pageserver(Lakebase 분산 스토리지 시스템의 구성 요소)는 해당 페이지의 가장 최근 구체화된 이미지를 찾아 그 위에 WAL 델타를 다시 재생하여 페이지를 재구성합니다. 컴퓨팅이 WAL에 포함했던 전체 페이지 이미지는 해당 델타 체인의 주기적인 재설정 지점 역할을 하여 체인을 합리적으로 제한하고 읽기 속도를 빠르게 유지했습니다. 이 메커니즘에 대한 자세한 내용은 Deep dive into Neon storage engine을 참조하십시오.
전체 페이지 쓰기가 비활성화되면 해당 재설정 지점이 사라집니다. 분산 스토리지 시스템에 추가적인 인텔리전스가 없으면 자주 업데이트되는 페이지는 중간 이미지가 없는 긴 작은 델타 체인을 축적할 수 있습니다. 그 결과 pageserver가 읽기 요청을 처리하기 위해 전체 체인을 다시 재생하면서 읽기 지연 시간과 리소스 소비가 바람직하지 않게 증가할 것입니다.
이 문제를 피하기 위해 우리는 컴퓨팅의 WAL 스트림에서 스토리지 계층으로 이미지 생성 책임을 푸시다운하여, 컴퓨팅의 WAL 오버헤드를 제거하면서도 스토리지의 유한한 읽기 동작을 유지했습니다. 이제 pageserver는 페이지가 중간 이미지 없이 구성된 임계값보다 더 많은 델타 레코드를 축적했을 때 전체 페이지 이미지를 생성합니다. 이는 새로운 이미지를 생성하는 결정이 관련 없는 Postgres 체크포인트 프로세스가 아닌 페이지에 대한 실제 변경 횟수를 기반으로 하기 때문에 자연스럽게 더 나은 접근 방식입니다.
성능에 훨씬 더 좋은 이유는 다음과 같습니다.
- 네트워크 효율성: 컴퓨팅은 실제 변경 사항인 압축된 델타만 전송하여 벤치마크에서 트래픽을 94% 감소시켰습니다.
- 확장성: 작업이 단일 Postgres 작성자에서 분산되고 독립적으로 확장 가능한 스토리지 계층으로 이동됩니다. 프로젝트 브랜치에 대한 이미지 생성은 이제 백그라운드에서 여러 pageserver에 걸쳐 공유됩니다.
- 최적의 읽기: 이미지가 생성되는 시점은 이제 관련 없는 Postgres 체크포인트 프로세스가 아닌 페이지에 대한 실제 변경 사항을 기반으로 합니다.
영향 정량화: 실��험실에서 프로덕션까지
우리는 HammerDB TPROC-C(TPC-C에서 파생된 OLTP 벤치마크)를 사용하여 이 최적화를 벤치마킹하고 실제 프로덕션 워크로드에서 결과를 검증했습니다.
1. 서버리스 컴퓨팅 확장
처리량은 분당 신규 주문(NOPM)으로 측정됩니다. 컴퓨팅 인스턴스 크기에 따라 이득이 크게 확장됩니다.
컴퓨팅 크기 | 이전 (NOPM) | 이후 (NOPM) | 처리량 증가 |
4-vCPU | 78,876 | 94,891 | 20% |
16-vCPU | 95,832 | 269,189 | 2.8배 |
32-vCPU | 95,686 | 439,300 | 4.5배+ |

32 vCPU 컴퓨팅에서 개선율은 450%를 초과했습니다.
컴퓨팅에서 전체 페이지 이미지가 생성될 때 각 트랜잭션은 평균 58KB의 WAL을 생성합니다. 이미지 생성이 푸시다운되면 4KB 미만으로 떨어지며, 이는 94% 감소입니다. 처리량 개선은 직접적으로 이어집니다. WAL이 적다는 것은 쓰기 경로의 경합 감소, 네트워크 대역폭 소비 감소, 스토리지 계층이 수집해야 할 작업 감소를 의미합니다.

Postgres의 FPW 병목 현상을 제거함으로써 처리량이 컴퓨팅 리소스에 따라 선형적으로 확장되도록 했습니다. 이는 모놀리식 Postgres가 높은 쓰기 부하에서 어려움을 겪는 부분입니다.
2. 실제 프로덕션 검증
56 vCPU 규모의 중요한 프로젝트의 프로덕션 환경에서 이미지 푸시다운을 활성화하자 안정 상태의 WAL 생성량이 30MB/s에서 1MB/s로 감소했습니다.

이러한 볼륨 감소는 일일 피크 시간 동안 트랜잭션 처리량 증가와 직접적으로 관련이 있었습니다.
이는 쓰기 작업에만 도움이 된 것이 아닙니다. 델타 체인을 최적화함으로써, 읽기당 적용해야 하는 WAL 레코드 수가 크게 줄었습니다. p99 읽기 지연 시간은 30%에서 50%까지, p50 지연 시간은 약 30% 감소했습니다.

더 넓게 보면, 지역 수준에서 활성화 후 컴퓨팅에서 생성되는 WAL의 총량이 최대 4배 감소했습니다. 스토리지 엔진에서 읽기 작업의 P99 지연 시간은 최대 3배 개선되었고 훨씬 더 안정적이 되었습니다.

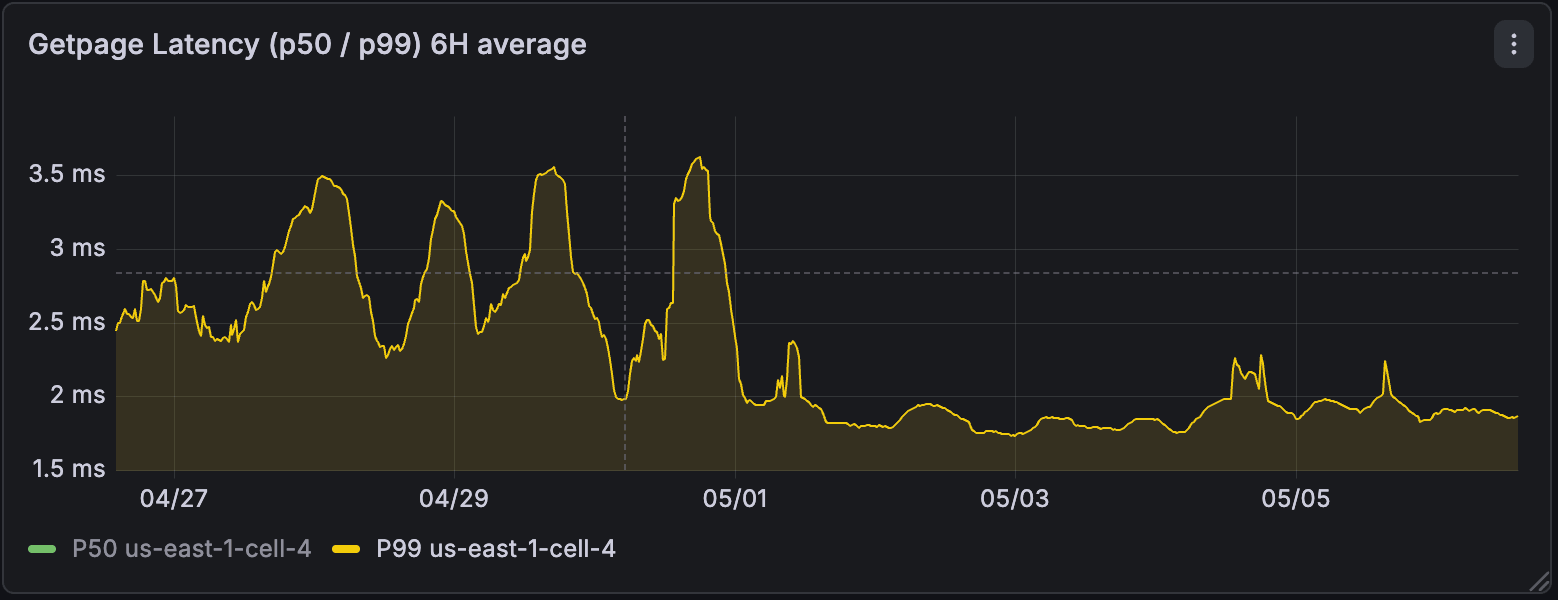
3. Lakebase 동기화된 테이블
데이터 집약적인 동기화된 테이블의 경우, 그 영향은 즉각적이었습니다. 한 고객은 이미지 푸시다운을 활성화하는 것만으로 초당 17,000행에서 초당 62,000행으로 수집 처리량이 3배 증가하는 것을 확인했습니다.
원활한 출시: 중단 없는 성능
3월 말부터 저희는 이 기능을 전체 시스템에 배포했습니다. 이제 전 세계의 모든 Lakebase Serverless 및 Neon 데이터베이스에서 활성화되어 있습니다.
이 변경 사항은 저희 제어 플레인과 스토리지 시스템을 통해 실행 중인 컴퓨팅에 적용되었으며, 이는 전환을 자��동으로 조정했습니다. 이는 기존 Postgres XLOG_FPW_CHANGE WAL 레코드 메커니즘을 사용하여 달성되었으며, 이는 고객에게 재시작이나 중단이 필요 없었음을 의미합니다.
관리형 Postgres 성능의 다음 단계는 무엇인가요?
Lakebase 아키텍처는 유연성을 위해 구축되었지만, 성능을 위해 설계되었습니다. 전체 페이지 쓰기를 푸시다운하는 것은 스토리지와 컴퓨팅 분리의 이점을 활용하기 위한 체계적인 노력의 일환입니다.
저희가 제로 다운타임 패치를 위한 캐시 사전 워밍을 도입했던 것처럼, 저희는 무거운 작업을 트랜잭션에서 분리하여 확장 가능한 백그라운드 스토리지 스택으로 계속 이동시키고 있습니다. Postgres 쓰기 부담은 이제 공식적으로 과거의 일이 되었습니다.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.