Databricks를 사용하여 MakeMyTrip이 대규모로 밀리초 단위 개인화를 달성한 방법
실시간 모드가 AI 에이전트에게 즉각적인 여행 �추천 및 컨텍스트를 제공하는 방법을 알아보세요
작성자: Sitesh Sharma, Aditya Kumar , Navneeth Nair
- 통합 스트리밍 아키텍처: MakeMyTrip은 Databricks 실시간 모드(RTM)를 채택하여 기존 ETL의 지연 시간 병목 현상을 해결하고, 별도의 특수 엔진 없이 통합된 Spark 아키텍처를 구축했습니다.
- 밀리초 단위 개인화: RTM은 대량의 여행자 검색을 지속적인 데이터 흐름으로 처리하여 50ms 미만의 P50 지연 시간을 가능하게 했으며, 이는 사용자 클릭률을 7% 직접적으로 향상시켰습니다.
- 통합 로직, 더 빠른 혁신: 통합 엔진을 사용함으로써 MakeMyTrip은 비즈니스 로직을 다시 작성할 필요 없이 일괄 처리에서 실시간 처리로 원활하게 전환할 수 있습니다. 이는 운영 복잡성을 제거할 뿐만 아니라 미래 혁신을 촉진하여, 생성형 AI 에이전트에게 정확한 의사 결정을 위해 필요한 실시간 컨텍스트를 쉽게 제공할 수 있도록 합니다.
대규모 실시간 개인화 제공
여행자가 호텔, 항공권 또는 경험을 검색할 때 매 순간이 중요합니다. 인도 최대 온라인 여행사인 MakeMyTrip은 실시간 속도와 관련성으로 경쟁합니다. 가장 중요한 기능 중 하나는 "최근 검색한" 호텔입니다. 사용자가 검색창을 탭하면 시스템과의 상호 작용을 기반으로 최근 관심사에 대한 실시간 개인화된 목록을 기대합니다.
MakeMyTrip의 규모에서 이러한 경험을 제공하려면 소비자 및 기업 여행 사업부 전반에 걸쳐 수백만 명의 일일 사용자를 지원하는 프로덕션 파이프라인에서 초당 밀리초 단위의 지연 시간이 필요합니다. Databricks의 Real-Time Mode (RTM)—Apache Spark™ Structured Streaming의 차세대 실행 엔진을 구현함으로써 MakeMyTrip은 비용 효율적인 인프라를 유지하고 엔지니어링 복잡성을 줄�이면서 밀리초 수준의 지연 시간을 성공적으로 달성했습니다.
과제: 아키텍처 분열 없이 초저지연 시간
MakeMyTrip의 데이터 팀은 모든 사업부에 걸쳐 "최근 검색한" 호텔 워크플로우에 대해 초당 밀리초 단위의 지연 시간이 필요했습니다. 그들의 규모에서는 몇백 밀리초의 지연만으로도 사용자 여정에 마찰을 일으켜 클릭률에 직접적인 영향을 미칩니다.
Apache Spark의 마이크로 배치 모드는 팀이 광범위한 튜닝에도 불구하고 돌파할 수 없는 내재된 지연 시간 제한을 도입했습니다. 일관되게 1~2초의 지연 시간을 제공했으며, 이는 요구 사항에 비해 너무 느렸습니다.
다음으로, 그들은 약 10개의 스트리밍 파이프라인에 걸쳐 Apache Flink를 평가했으며, 이는 지연 시간 요구 사항을 해결했습니다. 그러나 Apache Flink를 두 번째 엔진으로 채택하는 것은 장기적으로 상당한 문제를 야기했을 것입니다.
- 아키텍처 분열: 실시간 및 배치 처리를 위한 별도의 엔진 유지 관리
- 중복된 비즈니스 로직: 두 코드베이스에 걸쳐 비즈니스 규칙을 구현하고 유지 관리해야 함
- 높은 운영 오버헤드: 여러 파이프라인에 걸쳐 모니터링, 디버깅 및 거버넌스 노력을 두 배로 늘림
- 일관성 위험: 배치 및 실시간 처리 간 결과 불일치 위험
- 인프라 비용: 두 엔진을 실행하고 튜닝하면 컴퓨팅 비용 및 유지 관리 부담이 증가함
Real-Time Mode를 선택한 이유: 단일 Spark 스택에서의 밀리초 지연 시간
MakeMyTrip은 이중 엔진 아키텍처를 원하지 않았기 때문에 Apache Flink는 장기적인 옵션이 아니었습니다. 팀은 스택을 분열시키기보다는 Apache Spark가 더 빨라질 때까지 기다리기로 결정했습니다.
따라서 Apache Spark Structured Streaming이 RTM을 도입했을 때 MakeMyTrip은 이를 채택한 첫 번째 고객이 되었습니다. RTM을 통해 Apache Spark에서 밀리초 수준의 지연 시간을 달성하여 다른 엔진을 도입하거나 플랫폼을 분할하지 않고도 실시간 요구 사항을 충족할 수 있었습니다.
두 개의 엔진을 유지하는 것은 복잡성을 두 배로 늘리고 배치 및 실시간 계산 간의 로직 드리프트 위험을 증가시키는 것을 의미합니다. 우리는 두 개의 엔진을 유지하는 대신 하나의 Spark 기반 파이프라인, 즉 단일 진실 공급원을 원했습니다. Real-Time Mode는 우리가 원했던 단순성으로 필요한 성능을 제공했습니다." —Aditya Kumar, MakeMyTrip 엔지니어링 부사장
RTM은 마이크로 배치 실행에 내재된 지연 시간 소스를 제거하기 위해 함께 작동하는 세 가지 주요 기술 혁신을 통해 지속적이고 낮은 지연 시간의 처리를 제공합니다.
- 연속 데이터 흐름: 데이터가 주기적인 청크로 분할되는 대신 도착하는 대로 처리됩니다.
- 파이프라인 스케줄링: 스테이지가 차단 없이 동시에 실행되어 다운스트림 작업이 업스트림 스테이지가 완료될 때까지 기다리지 않고 즉시 데이터를 처리할 수 있습니다.
- 스트리밍 셔플: 데이터가 작업 간에 즉시 전달되어 기존 디스크 기반 셔플의 지연 시간 병목 현상을 우회합니다.
이러한 혁신은 함께 Apache Spark가 이전에 특수 엔진으로만 가능했던 밀리초 규모의 파이프라인을 달성할 수 있도록 합니다. RTM의 기술적 기반에 대해 자세히 알아보려면 이 블로그, “마이크로 배치 장벽 돌파: Apache Spark Real-Time Mode의 아키텍처”를 읽어보세요.
아키텍처: 통합 실시간 파이프라인
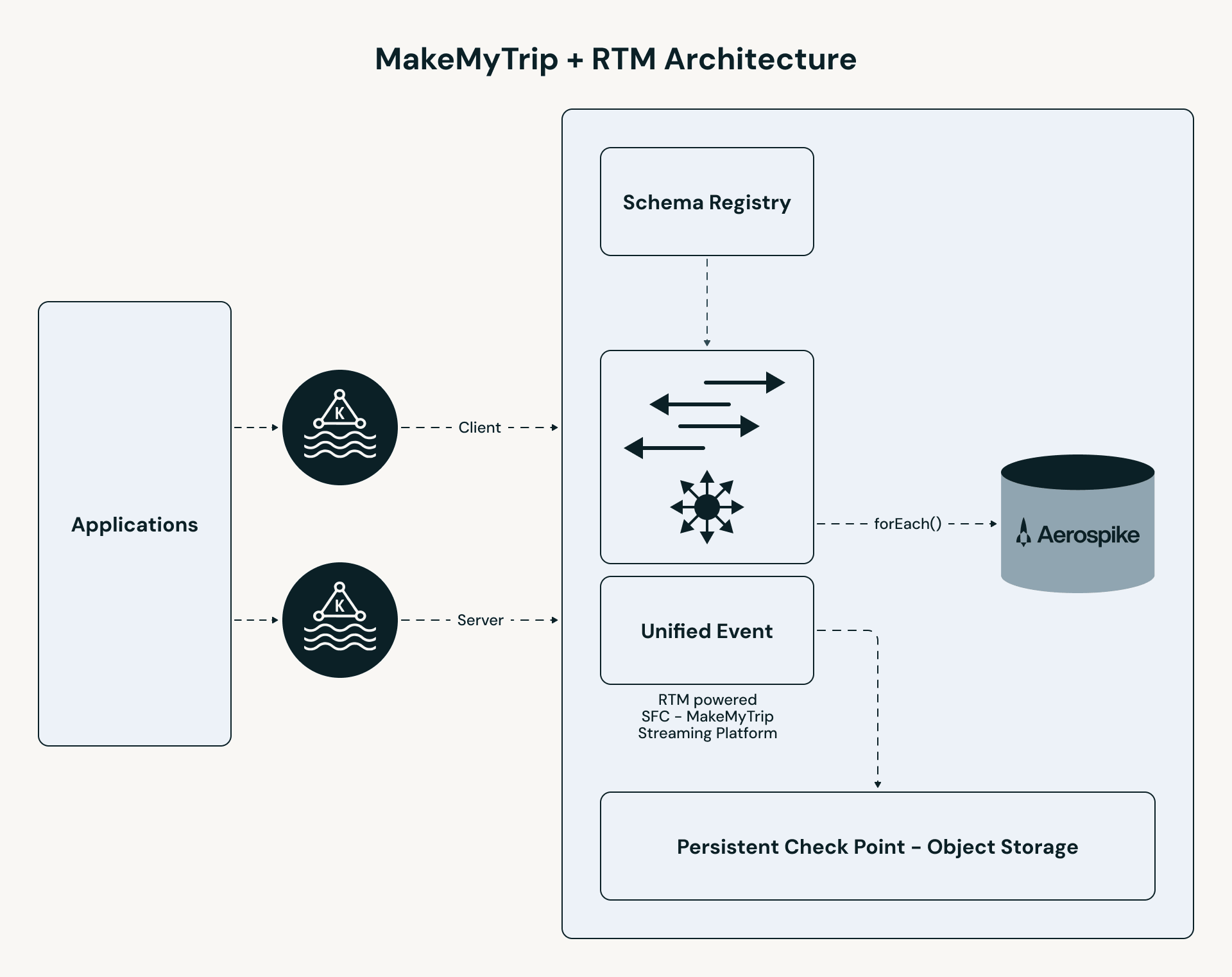
MakeMyTrip의 파이프라인은 고성능 경로를 따릅니다.
- 통합 수집: B2C 및 B2B 클릭스트림 주제가 단일 스트림으로 병합됩니다. 모든 개인화 로직—강화, 상태 저장 조회 및 이벤트 처리—는 두 사용자 세그먼트에 걸쳐 일관되게 적용됩니다.
- RTM 처리: Apache Spark 엔진은 동시 스케줄링 및 스트리밍 셔플을 사용하여 밀리초 단위로 이벤트를 처리합니다.
- 상태 저장 강화: 파이프라인은 Aerospike에서 저지연 시간 조회를 수행하여 각 사용자에 대한 "최근 N개" 호텔을 검색합니다.
- 즉시 제공: 결과는 UI 캐시(Redis)에 푸시되어 앱이 50ms 미만으로 개인화된 결과를 제공할 수 있습니다.
RTM 구성: 한 줄의 코드 변경
스트리밍 쿼리에서 RTM을 사용하는 것은 비즈니스 로직을 다시 작성하거나 파이프라인을 재구성할 필요가 없습니다. 필요한 유일한 코드 변경은 다음 코드 스니펫에 표시된 대로 트리거 유형을 RealTimeTrigger로 설정하는 것입니다.
한 가지 인프라 고려 사항: 클러스터 작업 슬롯은 소스 및 셔플 스테이지의 총 활성 작업 수보다 크거나 같아야 합니다. MakeMyTrip 팀은 프로덕션에 들어가기 전에 충분한 동시성을 보장하기 위해 Kafka 파티션, 셔플 파티션 및 파이프라인 복잡성을 사전에 분석했습니다.
RTM 공동 개발: 프로덕션용
RTM의 첫 번째 채택자로서 MakeMyTrip은 Databricks 엔지니어링과 직접 협력하여 파이프라인을 프로덕션 준비 상태로 만들었습니다. 여러 기능은 빌드, 튜닝 및 검증을 위해 두 팀 간의 적극적인 협업이 필요했습니다.
- 스트림 통합: B2C 및 B2B를 단일 파이프라인으로 병합
MakeMyTrip은 두 개의 별도 Kafka 주제 스트림—B2C 소비자 클릭스트림 및 B2B 기업 여행—을 단일 RTM 파이프라인으로 통합해야 했으므로 동일한 개인화 로직을 두 사용자 세그먼트에 걸쳐 일관되게 적용할 수 있었습니다. Databricks 엔지니어링과의 한 달간의 긴밀한 협력 후 기능이 구축되고 출시되었습니다. 결과는 모든 비즈니스 로직이 한 곳에 있고 사용자 세그먼트 간의 불일치 위험이 없는 단일 파이프라인이었습니다. - 작업 다중화: 더 많은 파티션, 더 적은 코어
RTM의 기본 모델은 파티션당 하나의 슬롯/코어를 할당합니다. MakeMyTrip의 프로덕션 설정에서 64개의 파티션이 있으면 64개의 슬롯/코어가 됩니다. 이는 규모에서 비용이 많이 듭니다. 이를 해결하기 위해 Databricks 팀은 Kafka에 MaxPartitions 옵션을 도입했습니다. 이를 통해 여러 파티션을 단일 코어에서 처리할 수 있습니다. 이를 통해 MakeMyTrip은 처리량을 희생하지 않고 인프라 비용을 절감할 수 있었습니다. - 파이프라인 강화: 체크포인팅, 백프레셔 및 내결함성
팀은 고처리량, 저지연 시간 워크로드에 특정한 운영 과제 세트를 해결했습니다. 체크포인트 빈도 및 보존 튜닝, 시간 초과 처리, 클릭스트림 볼륨 급증 시 백프레셔 관리. 64개의 Kafka 파티션으로 확장하고, 백프레셔를 활성화하고, MaxRatePerPartition을 파티션당 500개 이벤트로 제한함으로써 팀은 처리량과 안정성을 최적화했습니다. 배치 구성, 파티셔닝 및 재시도 동작을 반복적으로 튜닝함으로써 매일 수백만 명의 사용자를 지원하는 안정적인 프로덕션 등급 파이프라인에 도달했습니다.
결과
RTM은 즉각적인 개인화와 향상된 응답성, 클릭률을 통한 참여도 향상, 단일 통합 엔진의 운영 단순화를 가능하게 했습니다. 주요 지표는 아래와 같습니다.
Apache Spark를 실시간 엔진으로
MakeMyTrip의 배포 사례는 RTM on Spark가 실시간 애플리케이션에 필요한 매우 낮은 지연 시간을 제공함을 증명합니다. RTM은 익숙한 Spark API를 기반으로 구축되었기 때문에 배치 및 실시간 파이프라인 전반에 걸쳐 동일한 비즈니스 로직을 사용할 수 있습니다. 더 이상 실시간 처리를 위한 두 번째 플랫폼이나 별도의 코드베이스를 유지 관리하는 오버헤드가 필요 없으며, 단 한 줄의 코드로 Spark에서 RTM을 활성화할 수 있습니다.
Real-Time Mode를 통해 여러 스트리밍 엔진을 관리하지 않고도 인프라를 압축하고 실시간 경험을 제공할 수 있었습니다. AI 에이전트 시대를 맞이하여 효과적으로 제어하려면 데이터 스트림에서 실시간 컨텍스트를 구축해야 합니다. Spark RTM을 사용하여 에이전트가 최상의 결정을 내리는 데 필요한 가장 풍부하고 최신 컨텍스트를 제공하는 실험을 하고 있습니다.” —Aditya Kumar, MakeMyTrip 엔지니어링 총괄 부사장
Real-Time Mode 시작하기
Real-Time Mode에 대해 자세히 알아보려면 시작하는 방법에 대한 온디맨드 동영상을 시청하거나 설명서를 검토하세요.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.