Agent Bricks 소개: 데이터를 활용한 자동 최적화 에이전트
작성자: 샹루이 멍, Kasey Uhlenhuth, Hanlin Tang, Patrick Wendell , Matei Zaharia
- 자동 최적화된 에이전트: 작업을 설명하기만 하면 에이전트 브릭스가 평가 및 조정을 처리하여 고품질의 도메인별 에이전트를 구축합니다.
- 빠르고 비용 효율적인 결과: Databricks 연구에 의해 구동되는 자동 최적화를 통해 더 낮은 비용으로 더 높은 품질을 달성합니다.
- 프로덕션에서 신뢰: Flo Health, AstraZeneca 등에서 사용하여 며칠이 아닌 몇 주 만에 안전하고 정확한 AI를 확장합니다.
작년에 데이터 인텔리전스, 즉 데이터를 기반으로 추론하는 AI 구축의 가능성이 Databricks와 함께 현실화되었습니다. Databricks는 AI 시스템을 구축, 평가, 모니터링 및 보호하는 포괄적인 플랫폼입니다. 그 이후로 수천 명의 고객이 도메인별 에이전트를 구축하여 엔터프라이즈 데이터로 운영 환경에 배포했습니다.
- Mastercard는 고객 온보딩을 가속화하기 위해 디지털 어시스턴트를 출시했습니다.
- AT&T는 사기 및 피해로부터 무선 고객을 보호합니다.
- Crisis Text Line은 차세대 위기 상담사를 양성하기 위해 정신 건강에 특화된 AI 에이전트를 구축했습니다.
- Block은 엔터프라이즈 컨텍스트에 기반한 AI 코딩 어시스턴트인 goose를 출시했습니다.
하지만 생성형 기술의 미성숙함으로 인해 운영 환경 배포까지의 여정은 여전히 어려웠습니다. 고품질 에이전트 구축은 여러 가지 이유로 종종 너무 복잡했습니다.
- 평가가 어렵습니다: 많은 엔터프라이즈 AI 작업은 사람과 자동화된 LLM 심사관 모두에게 평가하기 어렵습니다. 수학 시험과 같은 학술적 벤치마크는 실제 사용 사례에 적용되지 않았습니다. 미묘한 평가를 구축하려면 종종 값비싼 수동 레이블링이 필요했습니다. 결과적으로 유망한 프로젝트는 끝없는 튜닝 주기에 머물렀고, 명확한 진행 상황 부족으로 이해관계자들은 신뢰를 잃었습니다.
- 너무 많은 설정값: 에이전트는 여러 구성 요소로 이루어진 복잡한 AI 시스템이며, 각 구성 요소에는 자체 설정값이 있습니다. 프롬프트 튜닝부터 인덱스 청킹 전략, 모델 선택 및 파인튜닝 파라미터에 이르기까지 각 조정은 시스템 전체에 예측 불가능한 영향을 미칩니다. 신속한 반복 개선이 되어야 할 과정이 비용이 많이 들고 지루한 수동 시행착오가 되어 운영 환경 배포 속도를 늦춥니다.
- 비용과 품질: 팀이 위의 문제를 해결하고 고품질 에이전트를 구축한 후에도, 에이전트가 운영 환경에서 확장하기에는 너무 비싸다는 사실에 놀라는 경우가 많습니다. 따라서 팀은 긴 비용 최적화 프로세스에 머물거나 비용과 품질 간의 절충을 강요받게 됩니다.
Agent Bricks: 도메인 작업에 대한 자동 최적화 에이전트
위에서 고객과 협력하여 AI를 운영 환경에 배포한 경험을 바탕으로, 지난 한 해 동안 에이전트 구축 방식을 재고했습니다. 오늘, 저희는 엔터프라이즈가 도메인별 에이전트를 개발하는 방식을 바꾸는 새로운 제품인 Agent Bricks를 소개합니다. 에이전트 개발의 압도적인 복잡성을 관리하는 대신, 팀은 가장 중요한 것, 즉 에이전트의 목적을 정의하고 자연어 피드백을 통해 품질에 대한 전략적 지침을 제공하는 데 집중할 수 있습니다. Agent Bricks는 평가 스위트를 자동으로 생성하고 품질을 자동 최적화하여 나머지를 처리합니다.
작동 방식은 다음과 같습니다.
- 작업 선언. 작업을 선택하고, 에이전트가 달성해야 하는 것에 대한 높은 수준의 설명을 자연어로 정의하고, 데이터 소스를 연결합니다.
자동 평가: Agent Bricks는 작업에 특화된 평가 벤치마크를 자동으로 생성하며, 여기에는 합성 데이터를 생성하거나 사용자 정의 LLM 심사관을 구축하는 것이 포함될 수 있습니다.
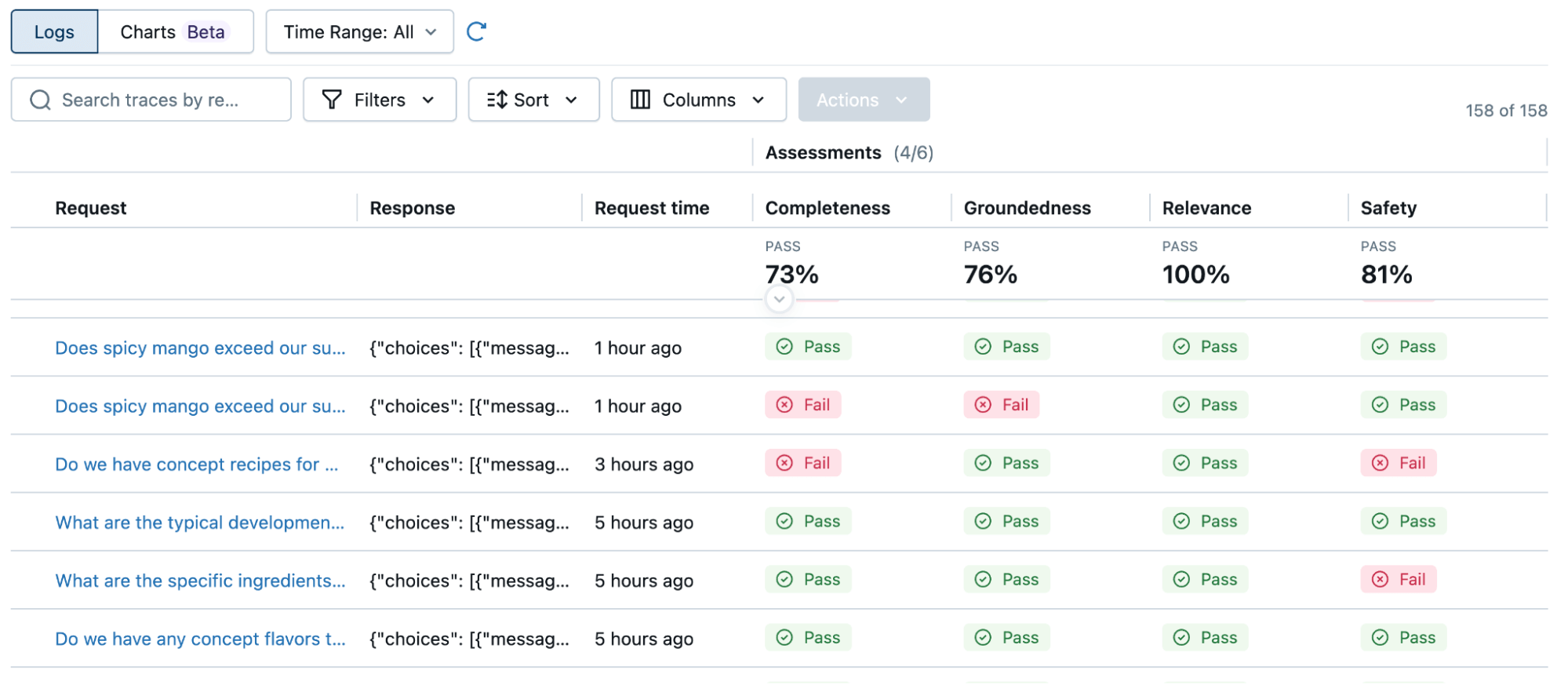
MLflow 3 기반으로, Agent Bricks는 작업에 맞춰 평가 데이터셋과 사용자 정의 심사관을 자동으로 생성합니다. - 자동 최적화: Agent Bricks는 프롬프트 엔지니어링, 모델 파인튜닝, 보상 모델 또는 테스트 적응 최적화(TAO)와 같은 다양한 최적화 기술을 지능적으로 검색하고 결합하여 높은 품질을 달성합니다.
- 비용 및 품질: Agent Bricks는 에이전트가 효과적일 뿐만 아니라 비용 효율적임을 보장합니다. 사용자는 비용 최적화 또는 품질 최적화 모델 중에서 선택할 수 있습니다. 많은 경우, 최종 솔루션은 다른 DIY 접근 방식에 비해 품질이 높고 비용이 저렴합니다.
Agent Bricks를 사용하면 자동 평가를 통해 추측을 제거할 수 있습니다. 저희는 설정을 자동으로 최적화하므로 에이전트 성능을 신뢰하고 최대 효율로 실행 중임을 알 수 있습니다. 최종 결과는 이제 고품질의 비용 효율적인 에이전트를 운영 환경에 배포할 수 있다는 것입니다. Agent Bricks는 구조화된 정보 추출, 신뢰할 수 있는 지식 지원, 사용자 정의 텍스트 변환 및 오케스트레이션된 다중 에이전트 시스템을 포함한 일반적인 산업 사용 사례에 최적화되어 있습니다.
Agent Bricks로 고품질 에이전트 구축
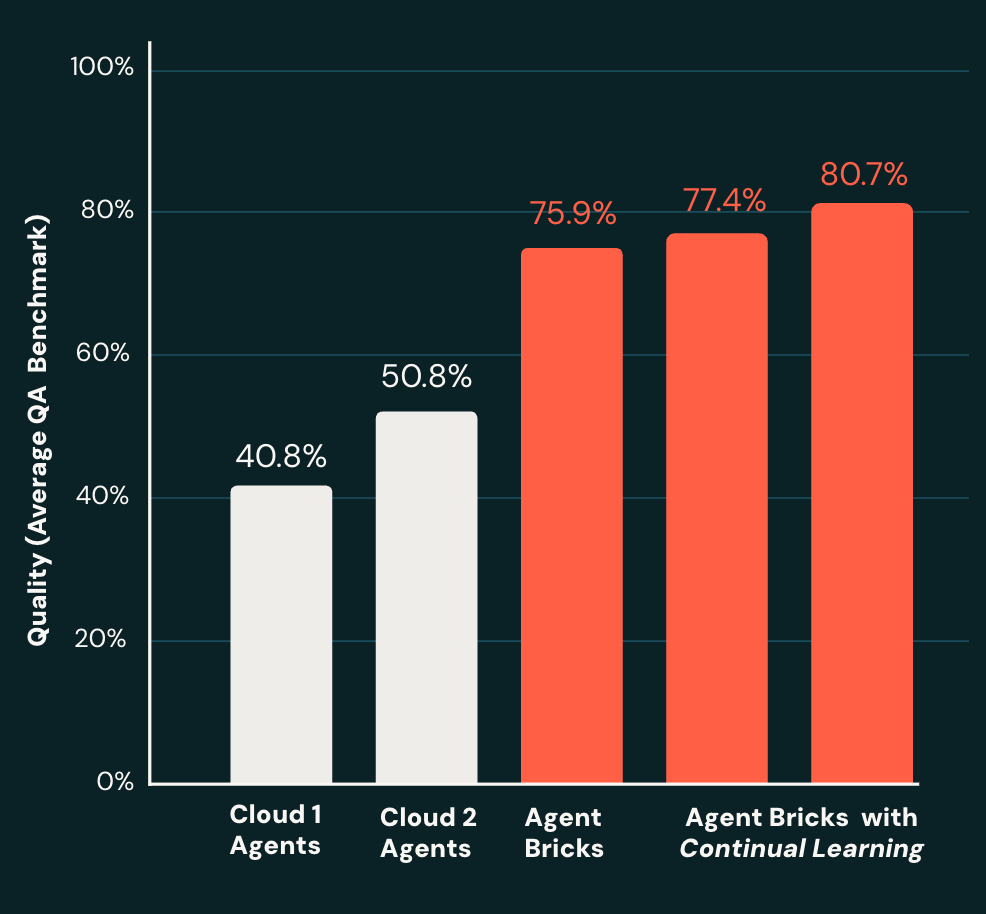
Agent Bricks는 고유하게 품질을 측정, 구축 및 지속적으로 개선할 수 있습니다. 예를 들어 문서에 대한 대화형 에이전트를 구축할 때, 여러 Q&A 벤치마크에 걸쳐 평균 품질을 측정했습니다. 이 분야의 다른 제품과 비교했을 때, Agent Bricks는 훨씬 더 높은 품질의 에이전트를 구축했습니다(그림 1). 뿐만 아니라, 지속적인 학습 능력을 통해 성능은 시간이 지남에 따라 계속 향상됩니다.
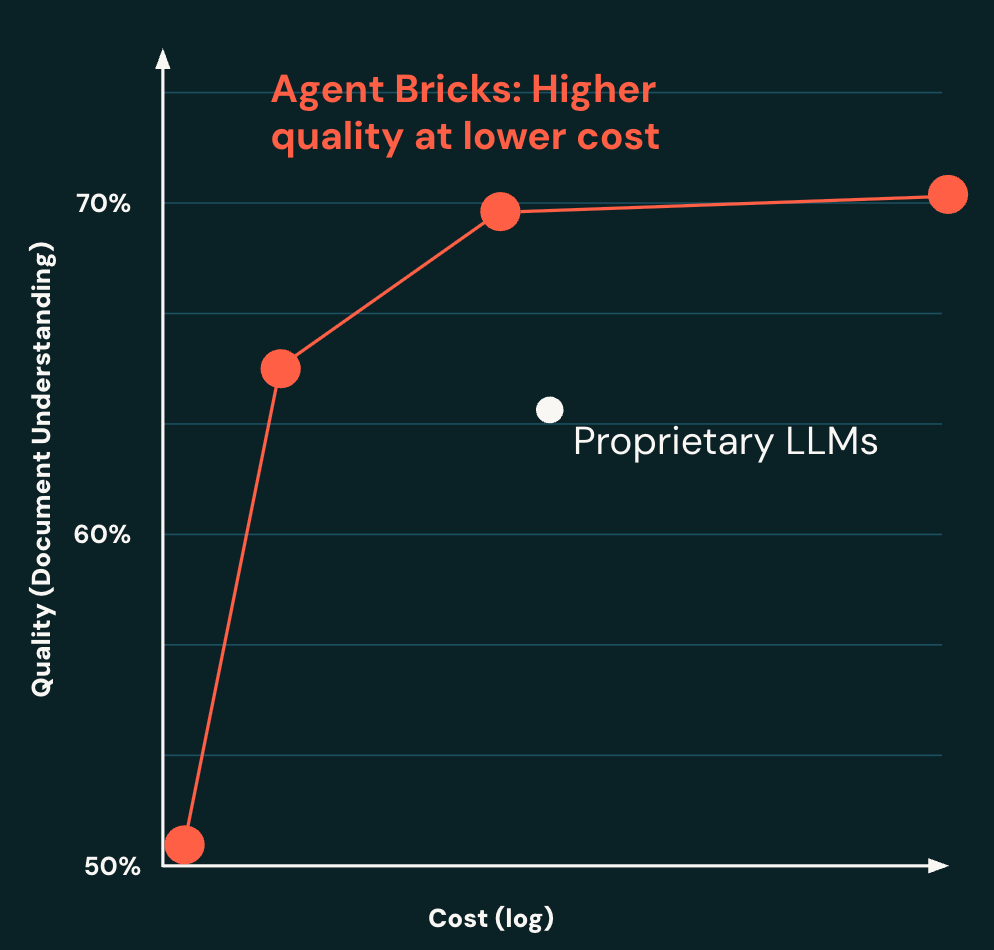
문서 이해 측면에서 Agent Bricks는 프롬프트 최적화된 독점 LLM과 비교하여 더 높은 품질과 더 낮은 비용의 시스템을 구축합니다(그림 2). 문서 파싱 벤치마크에서 더 높은 품질을 가진 시스템을 달성할 수 있으며, 비용은 최대 10배 저렴합니다.
이러한 벤치마크 외에도, 저희 고객들은 Agent Bricks를 사용하여 품질 좋은 에이전트를 구축할 수 있습니다.
"Agent Bricks를 통해 표준 상용 LLM에 비해 의료 정확도를 두 배로 높일 수 있었으며, Flo Health의 임상 정확도, 안전성, 개인 정보 보호 및 보안에 대한 높은 내부 기준을 충족했습니다." —Roman Bugaev, CTO, Flo Health
“Agent Bricks는 LLM-as-judge와 인간 평가 정확도 지표 모두에서 원래의 오픈 소스 구현보다 훨씬 뛰어난 성능을 보였습니다.” —Joel Wasson, Enterprise Data & Analytics, Hawaiian Electric
“[Agent Bricks]는 피드백 루프에서 품질 개선을 안내하고 성능이 동일한 더 저렴한 옵션을 식별함으로써 엔터프라이즈 전반에 걸쳐 AI 기능을 가속화했습니다.� ” —Chris Nishnick, Director of AI, Lippert
에이전트 학습의 최신 연구로 구동
Agent Bricks는 Databricks 연구팀의 연구를 기반으로 이러한 결과를 달성할 수 있습니다. 에이전트 품질을 개선하기 위한 다양한 방법이 있으며, 새로운 연구가 매우 빠른 속도로 발표되고 있습니다. 저희 팀은 기존 연구를 큐레이션하고 Agent Bricks가 자동 평가 및 최적화 단계에서 사용하는 새로운 혁신을 개발합니다. 저희는 방대한 방법론을 보유하고 있지만, 오늘 저희 혁신 중 하나인 Agent Learning from Human Feedback(ALHF)을 강조하게 되어 기쁩니다.
인간 피드백을 통한 에이전트 학습(ALHF)
품질의 주요 과제는 피드백을 통해 에이전트 동작을 조정하는 능력입니다. 피드백이 종종 좋아요 또는 싫어요로만 제공되고, 피드백을 존중하기 위해 에이전트 시스템 내부의 여러 구성 요소 및 설정값 중 어떤 것을 조정해야 하는지 불분명하기 때문에 이는 특히 어렵습니다. 모든 지침을 하나의 거대한 LLM 프롬프트에 담는 현재 접근 방식은 취약하며 더 복잡한 에이전트 시스템에는 일반화되지 않습니다.
ALHF를 통해 저희는 두 가지 접근 방식으로 이 문제를 해결했습니다. 첫째, 자연어 지침(예: 1990년 5월 이전의 모든 데이터 무시)의 풍부한 컨텍스트를 받을 수 있습니다. 둘째, 이 자연어 지침을 기반으로 저희 알고리즘은 검색 알고리즘을 개선하고, 프롬프트를 강화하고, 벡터 데이터베이스를 필터링하거나, 에이전트 패턴을 수정하는 등 기술적 최적화로 지침을 지능적으로 변환합니다.
이 접근 방식은 에이전트 개발을 민주화하여 도메인 전문가가 AI 인프라에 대한 깊은 기술 전문 지식 없이도 시스템 개선에 직접 기여할 수 있도록 합니다.
"정확도를 지속적으로 평가하고 개선하는 능력은 Experian에게 핵심적인 기능이며, 특히 규제가 심한 산업에서는 더욱 그렇습니다.." —James Lin, Head of AI ML Innovation, Experian
향후 경로: 실험실에서 운영 환경까지 며칠 만에, 몇 달이 아닌
Agent Bricks를 사용하는 초기 고객들은 이미 Agent Bricks가 제공하는 혁신을 경험하고 있습니다. 성능 벤치마크를 두 배로 향상시키고 개발 기간을 몇 주에서 단 하루로 단축하는 정확도 개선을 경험하고 있습니다. 더 중요한 것은, 불과 몇 달 전에는 불가능해 보였던 것을 달성하고 있다는 것입니다. 바로 지속 가능하고 확장 가능한 AI 시스템으로 일관된 비즈니스 가치를 제공하는 것입니다.
Agent Bricks는 단순한 도구의 진화를 넘어, 성숙하고 프로덕션 준비가 된 AI 개발로의 근본적인 전환을 나타냅니다. 에이전트 시스템이 기업 운영의 핵심이 되어감에 따라, 과거의 “느낌만으로 판단하는” 접근 방식은 더 이상 확장될 수 없습니다. 조직은 실제 비즈니스 애플리케이션의 복잡성과 요구 사항을 처리할 수 있는 지능형 에이전트를 구축하고 최적화하기 위한 강력하고 체계적인 접근 방식이 필요합니다.
Agent Bricks를 사용하는 고객
많은 Databricks 고객들이 이미 Agent Bricks로 AI 에이전트를 구축했으며, 앞으로 그들이 무엇을 할 수 있을지 기대하고 있습니다.
Experian 및 Flo Health와 함께하는 동영상을 시청하세요
“Agent Bricks를 통해 저희 팀은 단 한 줄의 코드도 작성하지 않고 400,000건 이상의 임상 시험 문서를 분석하고 구조화된 데이터를 추출할 수 있었습니다. 단 60분 만에 분석에 사용할 수 있는 복잡한 비정형 데이터를 변환할 수 있는 작동하는 에이전트를 확보했습니다.” —Joseph Roemer, Head of Data & AI, Commercial IT, AstraZeneca
�“Agent Bricks를 통해 프로덕션에서 신뢰할 수 있는 비용 효율적인 에이전트를 구축할 수 있었습니다. 맞춤형 평가를 통해 비정형 입법 달력을 분석하는 정보 추출 에이전트를 자신 있게 개발하여 수동 시행착오 최적화에 30일을 절약했습니다.” —Ryan Jockers, Assistant Director of Reporting and Analytics at the North Dakota University System
지금 Agent Bricks를 사용해보세요
“데모 수준”과 “프로덕션 수준” 사이의 격차를 해소할 준비가 되셨나요? Agent Bricks가 이제 베타 버전으로 제공됩니다.
시작하기:
- 문서 읽기
- 키노트 시청
- 고객들이 Agent Bricks 사용의 이점을 설명하는 동영상 시청
- Databricks Agent Bricks를 사용하여 자체 데이터로 자동 최적화되는 지능형 노코드 AI 에이전트를 만드는 방법을 알아보려면 제품 투어 살펴보기
기업 AI의 미래는 복잡성을 관리하는 것이 아니라, Agent Bricks가 나머지를 처리하는 동안 중요한 결과에 집중하는 것입니다.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.