AI Runtime 소개: Databricks에서 학습 및 미세 조정을 위한 확장 가능하고 서버리스인 NVIDIA GPU
Lakehouse에 연결된 즉시 사용 가능한 NVIDIA H100 GPU로 최신 LLM을 학습하세요.
작성자: 테자스 순다레산, 젠웨이 셰, Bandish Shah , Hanlin Tang
- AI Runtime을 통해 Databricks는 Serverless Compute에서 NVIDIA GPU를 지원하게 되었으며, 인프라 오버헤드 없이 확장 가능한 NVIDIA A10 및 H100에 대한 온디맨드 액세스를 가능하게 합니다.
- 분산 학습을 위한 전용 런타임으로 컴퓨터 비전 모델, LLM, 딥러닝 기반 추천 시스템 및 기타 모델을 학습하세요. 모든 기능이 포함되어 있습니다.
- AI Runtime은 Lakehouse 데이터의 고속 데이터 로딩, Lakeflow를 통한 워크플로 오케스트레이션, Unity Catalog를 통한 거버넌스와 통합됩니다.
오늘날 가장 발전된 AI 워크로드는 예측 및 추천부터 멀티모달 파운데이션 모델까지 GPU를 활용합니다. 하지만 팀들은 GPU 인프라 조달 및 관리, 분산 학습 환경 구성, 데이터 로딩 병목 현상 디버깅에 어려움을 겪고 있습니다. 딥러닝 연구원들은 인프라 문제 해결보다는 모델링에 집중하고 싶어 합니다.
저희는 A10 및 H100에서 온디맨드 분산 GPU 학습을 지원하는 새로운 학습 스택인 AI Runtime (AIR)의 공개 미리 보기 출시를 발표하게 되어 기쁩니다. AI Runtime에는 MPT 및 DBRX와 같은 LLM의 대규모 학습에 사용되는 모든 기술이 포함되어 있습니다. 베타 버전임에도 불구하고 Rivian, Factset, YipitData를 포함한 수백 명의 고객이 AIR를 사용하여 딥러닝 모델을 학습하고 프로덕션에 배포했습니다. 사용 사례는 컴퓨터 비전 모델부터 추천 시스템, ��에이전트 작업용으로 미세 조정된 LLM까지 다양합니다. 저희 Databricks AI Research 팀은 최근 KARL 논문에서와 같이 모델의 강화 학습에 AIR를 사용했습니다.
AI Runtime을 통해 Databricks 사용자는 이제 다음을 사용할 수 있습니다.
- 서버리스 온디맨드 NVIDIA GPU: 노트북을 2-3번의 클릭으로 구성하면 서버리스 A10 및 H100 GPU에 빠르게 연결하여 학습을 시작할 수 있습니다. 클러스터가 필요 없습니다. 사용한 GPU에 대해서만 비용을 지불하며 유휴 시간 활용에 대한 걱정이 없습니다.
- 강력한 오케스트레이션 도구: 장기 실행 GPU 워크로드에 대한 Lakeflow Jobs 및 DAB 지원을 통해 Databricks 오케스트레이션 제품군의 전체 기능을 활용합니다.
- 최적화된 분산 학습: AIR는 RDMA 및 고성능 데이터 로딩과 같은 분산 GPU 성능 향상 기능을 번들로 제공합니다.
- 중앙 집중식 거버넌스 및 관찰 가능성: MLflow를 통한 내장 실험 관리, Unity Catalog를 통한 액세스 관리, 에이전트 지원 디버깅을 통해 데이터가 있는 위치에서 GPU 워크로드를 실행, 관찰 및 관리합니다.
노트북에서 온디맨드 NVIDIA H100 및 A10 GPU
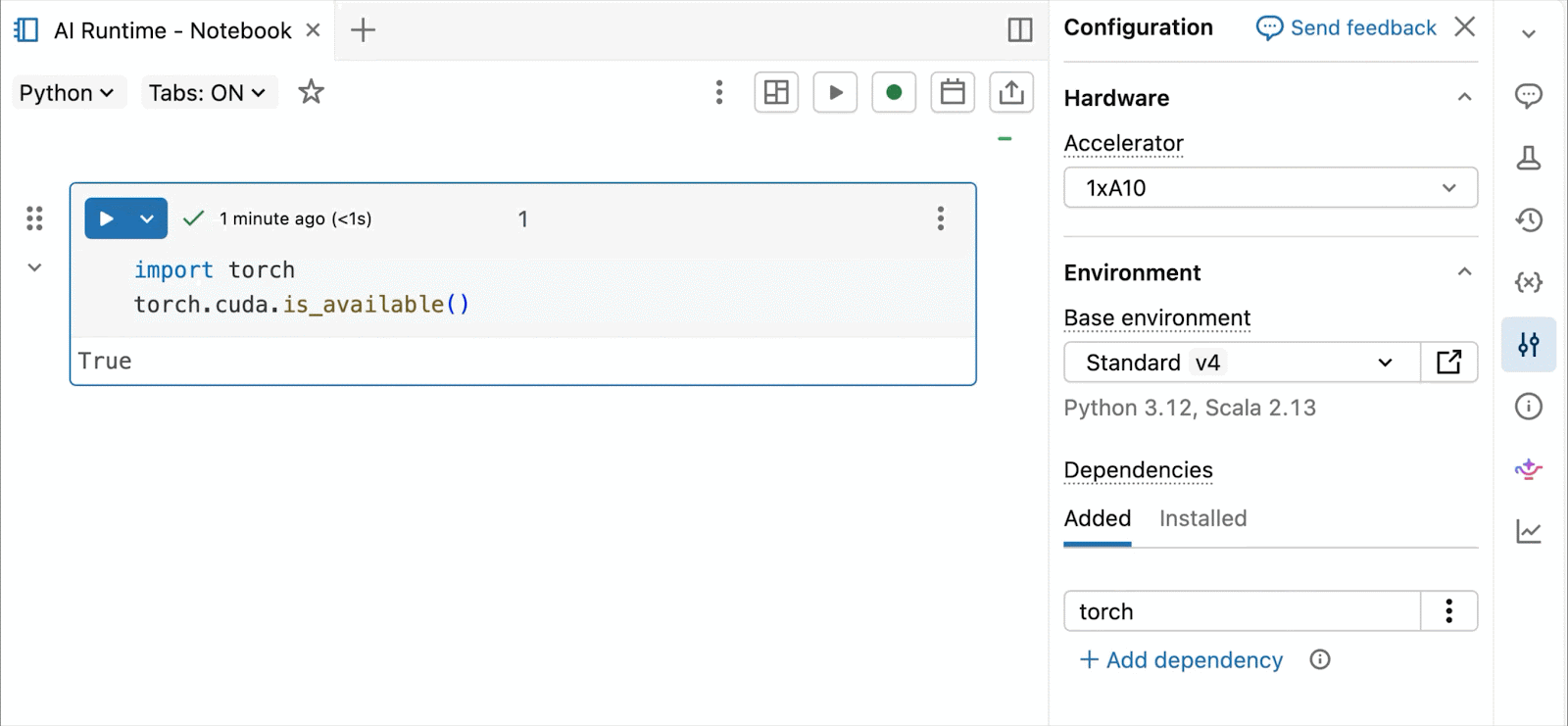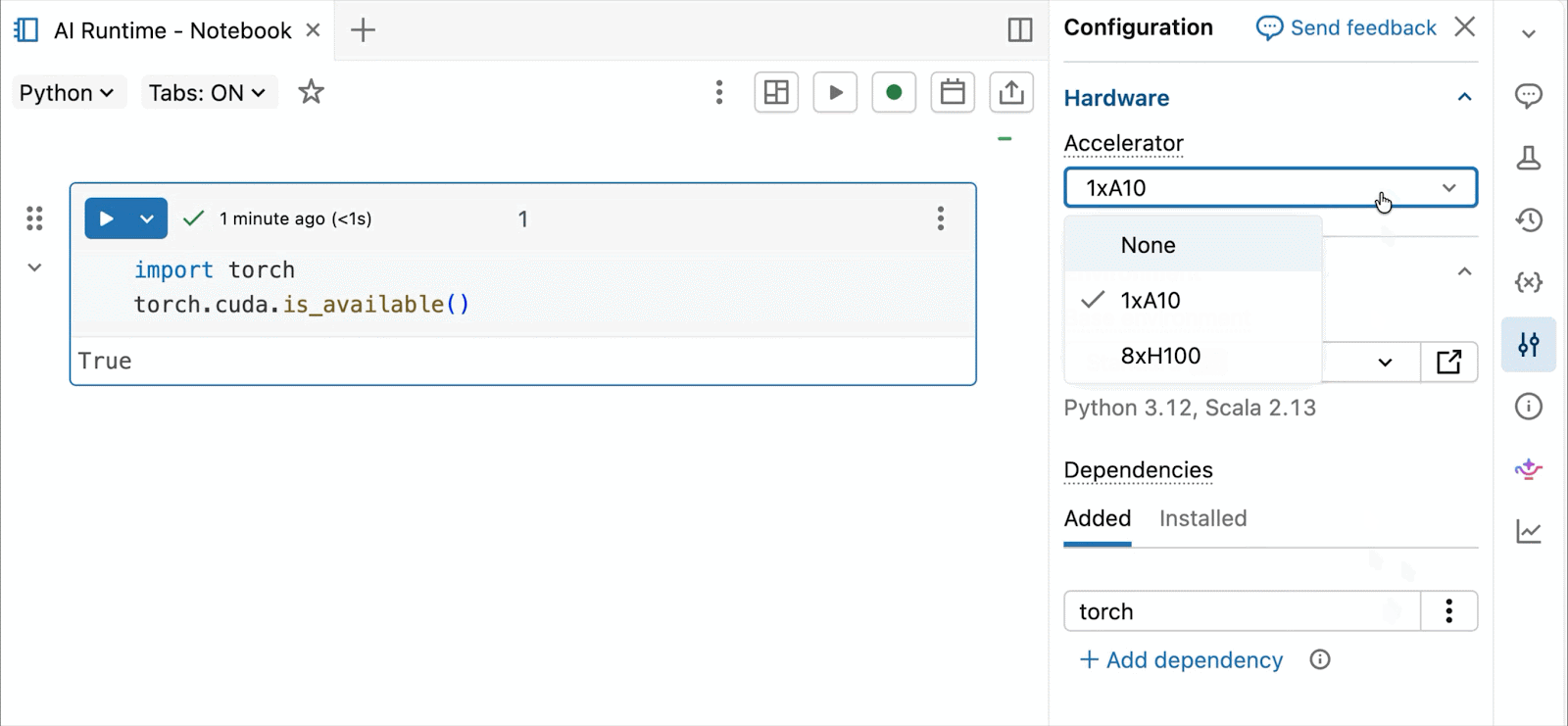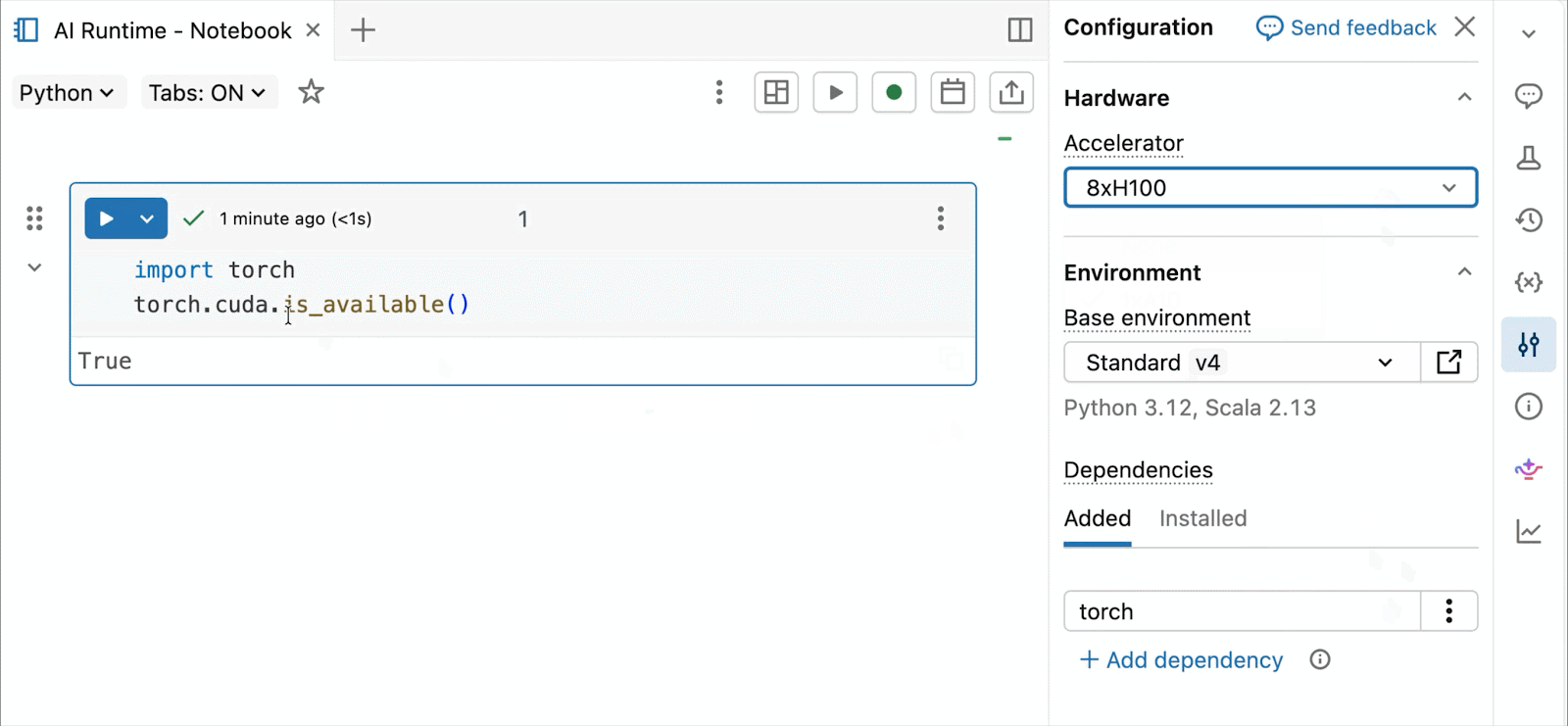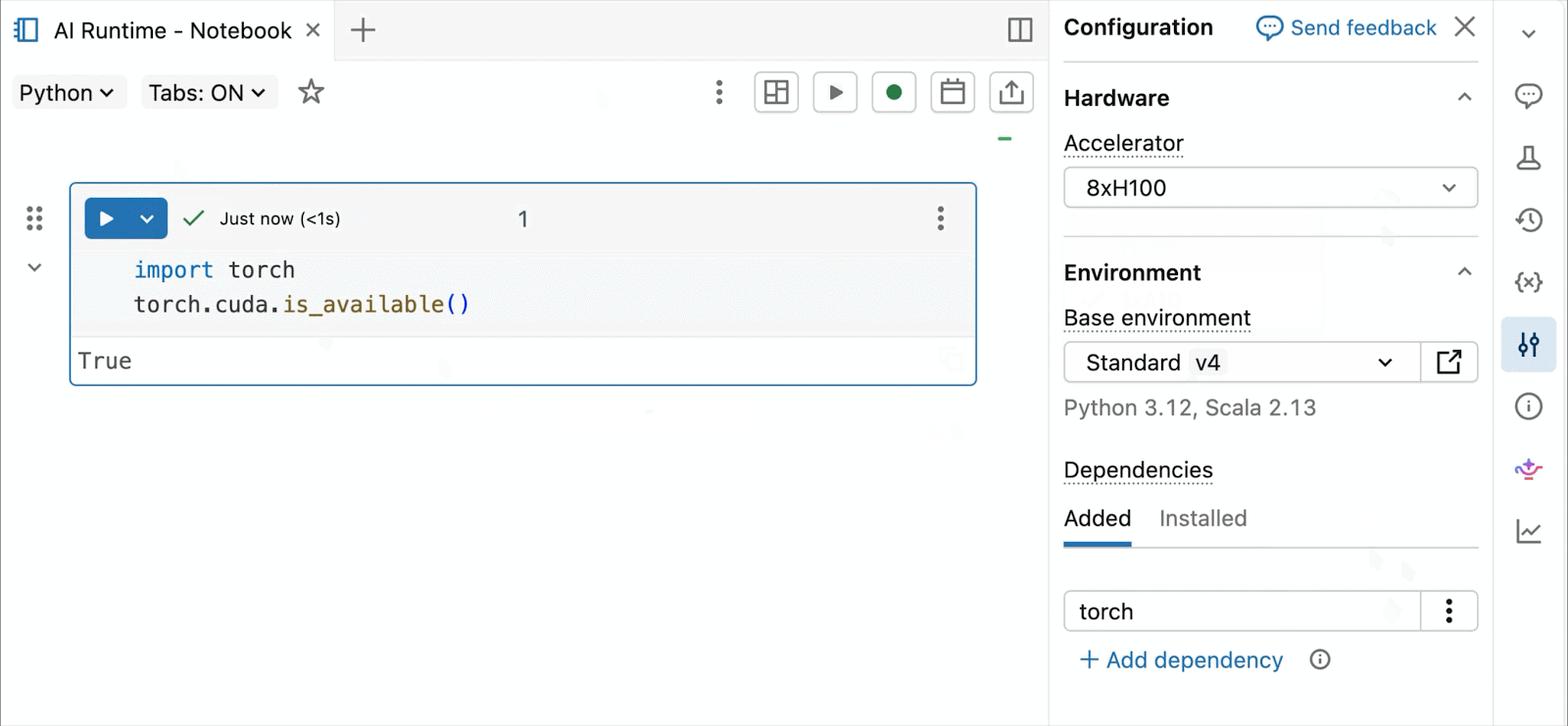
대화형 개발 및 디버깅을 위해 몇 번의 클릭만으로 Databricks 노트북에서 온디맨드 A10 및 H100에 연결할 수 있습니다. 거기에서 일반적인 Python 패키지의 환경 관리부터 Genie Code를 통한 에이전트 기반 작성 및 디버깅에 이르기까지 Databricks가 제공하는 모든 개발자 편의 기능을 활용할 수 있습니다. Lakehouse에서 데이터를 쉽게 마운트하여 딥러닝 모델을 학습하거나, GPU 지원 노트북에서 원격 CPU를 호출하여 Spark 데이터 처리 워크로드를 실행하여 데이터를 준비할 수 있습니다.
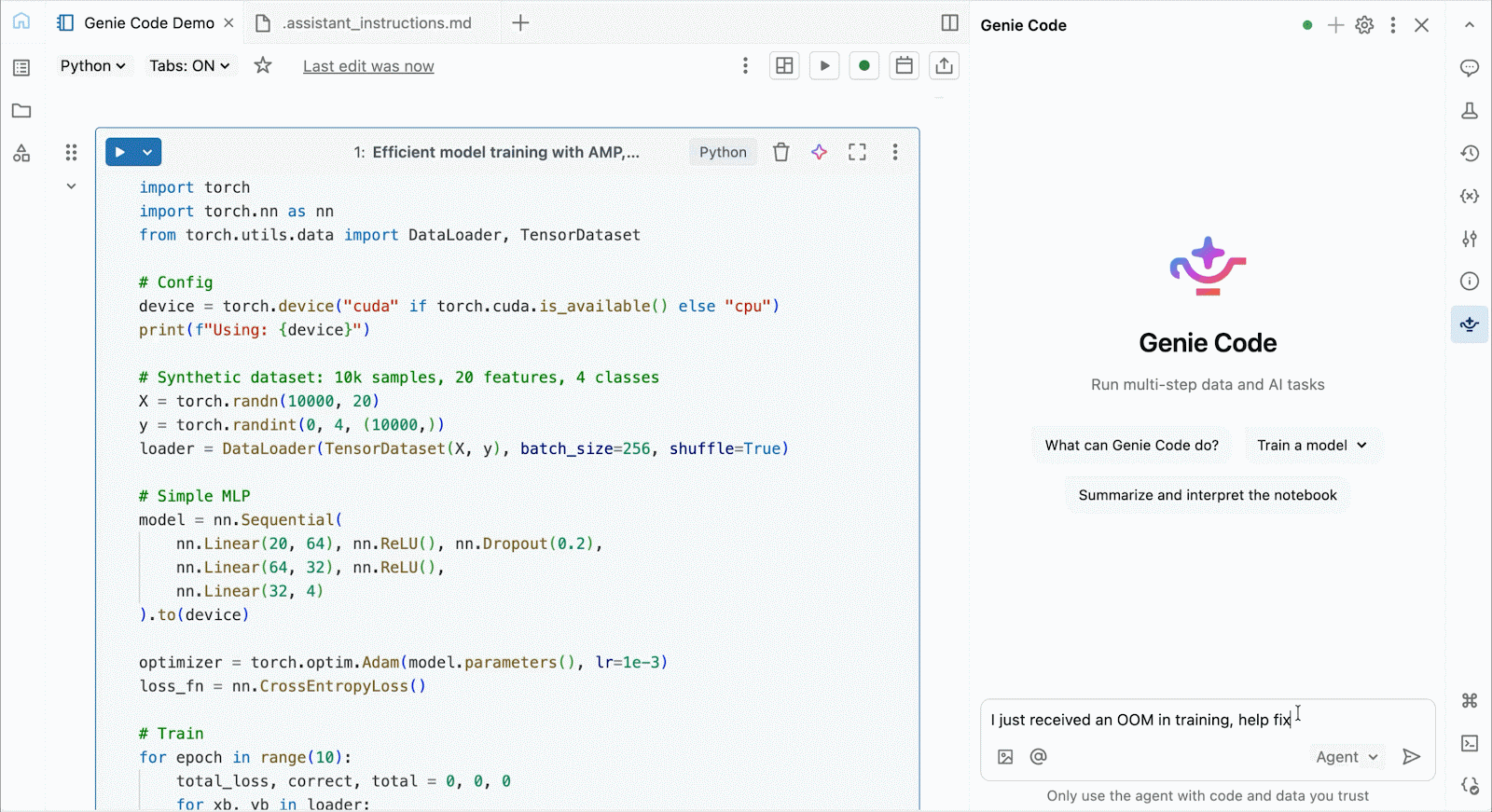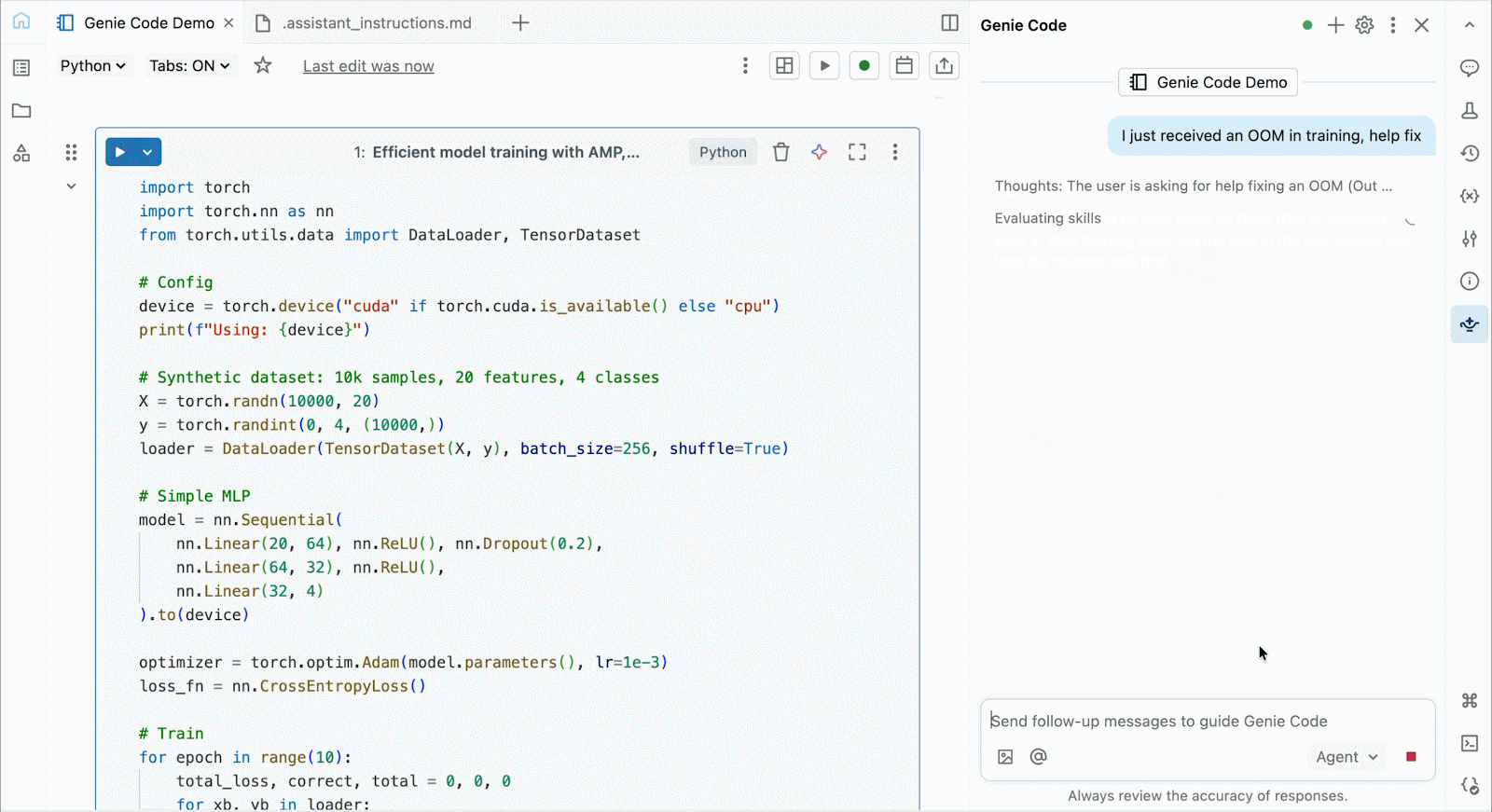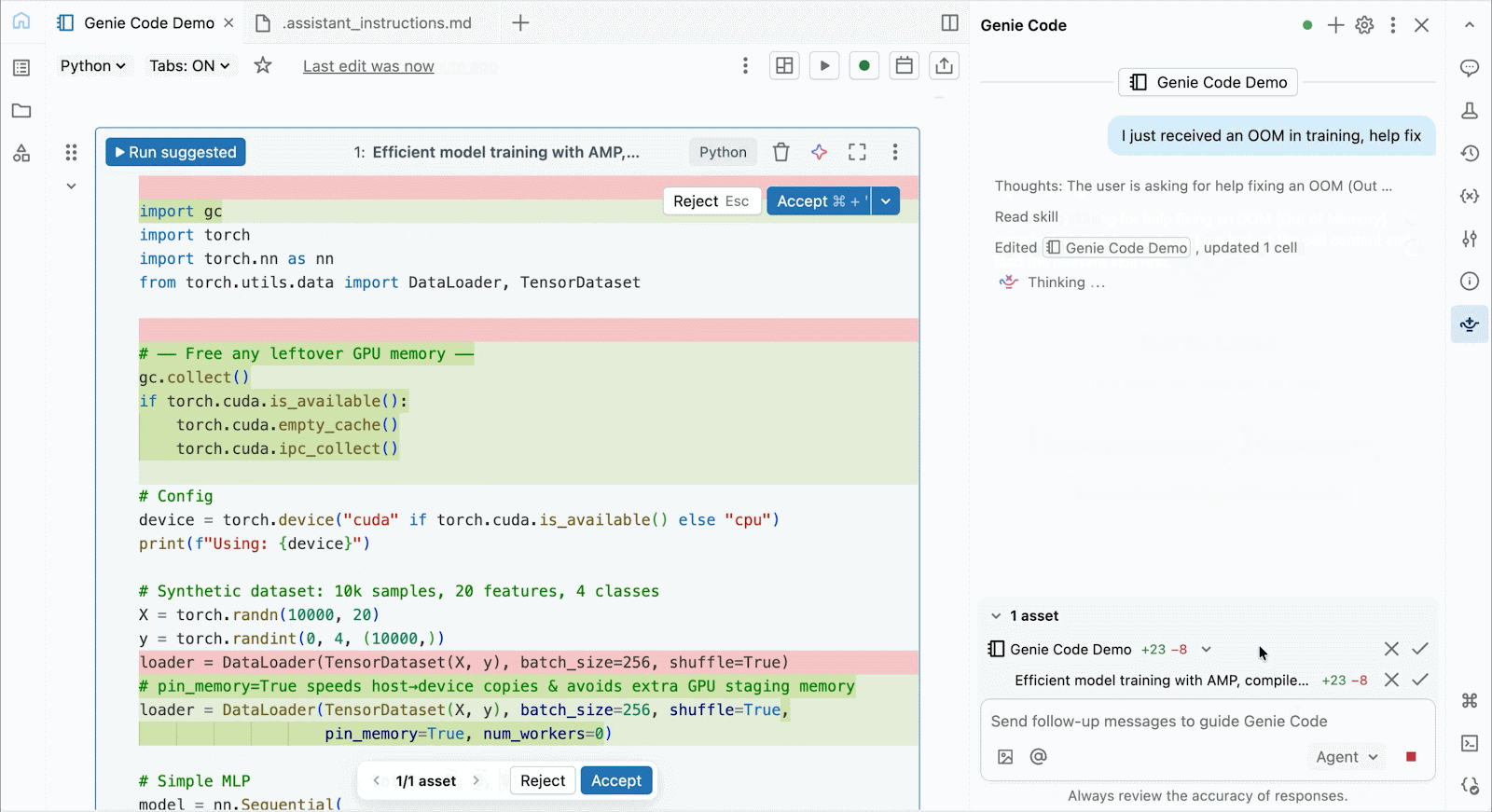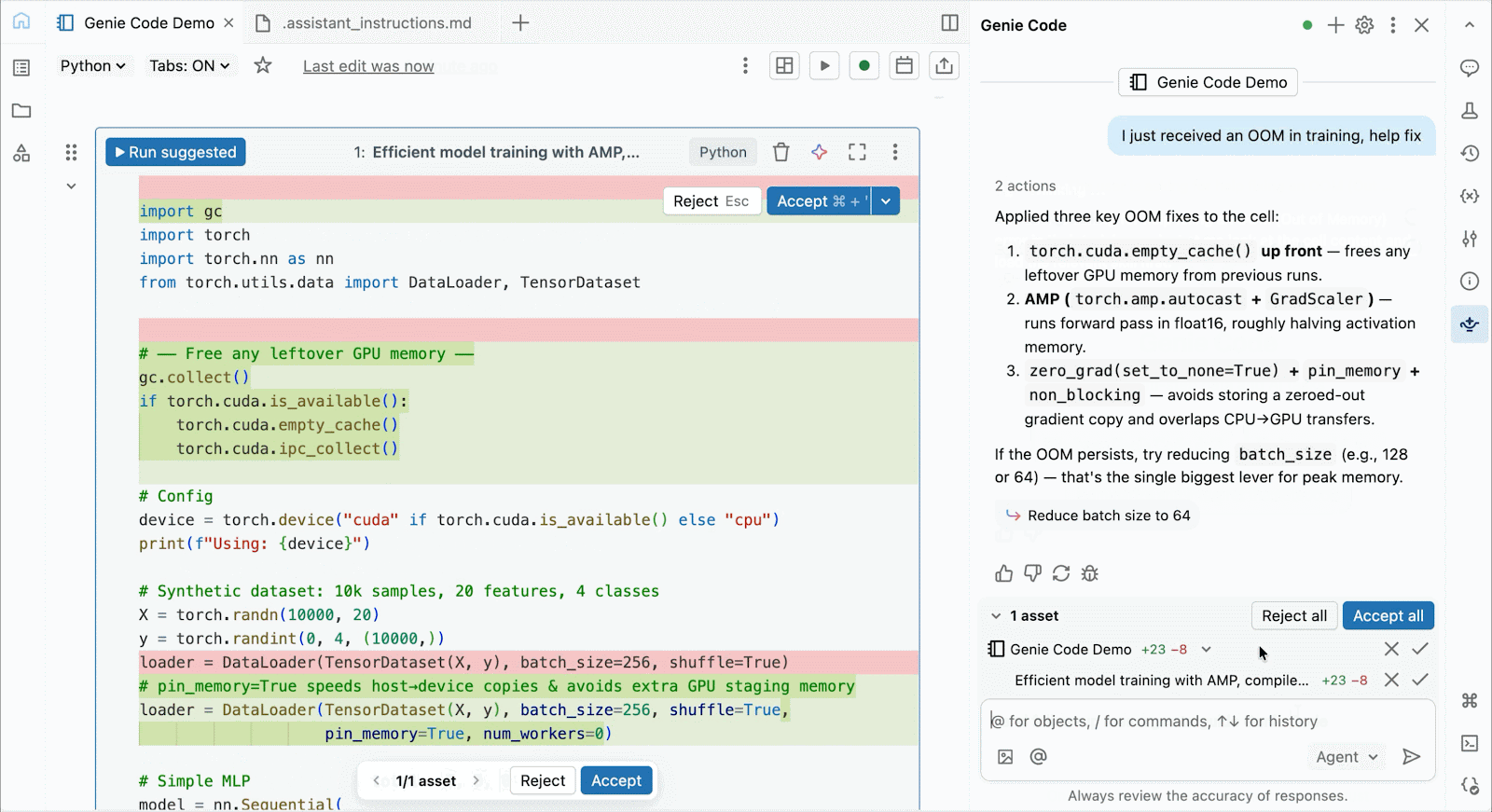
Genie Code를 사용하여 성능 병목 현상을 해결하고, 새로운 아키텍처를 실험하거나, 모델 수렴 또는 난해한 프레임워크 오류 주변의 까다로운 버그를 디버깅할 수 있습니다.
프로덕션 준비 워크로드를 위한 Lakeflow
AI Runtime은 가속 컴퓨팅을 위한 프로덕션 등급 플랫폼입니다. 대화형 노트북에서 딥러닝 코드를 개발한 다음, GPU 컴퓨팅에서 작업을 제출하고 오케스트레이션하기 위해 Lakeflow의 전체 기능을 사용합니다. 노트북과 사용자 지정 코드 리포지토리 모두 장기 실행 또는 예약된 작업을 위해 Lakeflow에서 실행할 수 있습니다. CI/CD(지속적 통합 및 지속적 배포)와 같은 프로덕션 요구 사항의 경우 AI Runtime은 선언적 자동화 번들(DAB)과 완벽하게 호환됩니다.
Lakeflow 통합을 통해 고객은 모델 학습 및 미세 조정을 상위 데이터 파이프라인 및 하위 프로덕션 시스템과 긴밀하게 동기화할 수 있습니다.
“Databricks의 AI Runtime은 사용자 지정 텍스트-수식(TTF) 모델 학습 프로세스를 크게 간소화했습니다. 인프라 설정이나 지연 없이 프롬프트 크기 및 출력 토큰 생성에 따라 올바른 컴퓨팅을 쉽게 선택할 수 있었습니다. 이를 통해 신속하게 이동하고 Lakehouse 워크플로를 유지하며 전체 거버넌스를 갖춘 고품질 모델을 제공하여 모델 설정, 학습 및 배포 시간을 며칠에서 몇 시간으로 단축할 수 있었습니다.”—Nikhil Sunderraj, 수석 머신러닝 엔지니어, FactSet Research Systems, Inc.
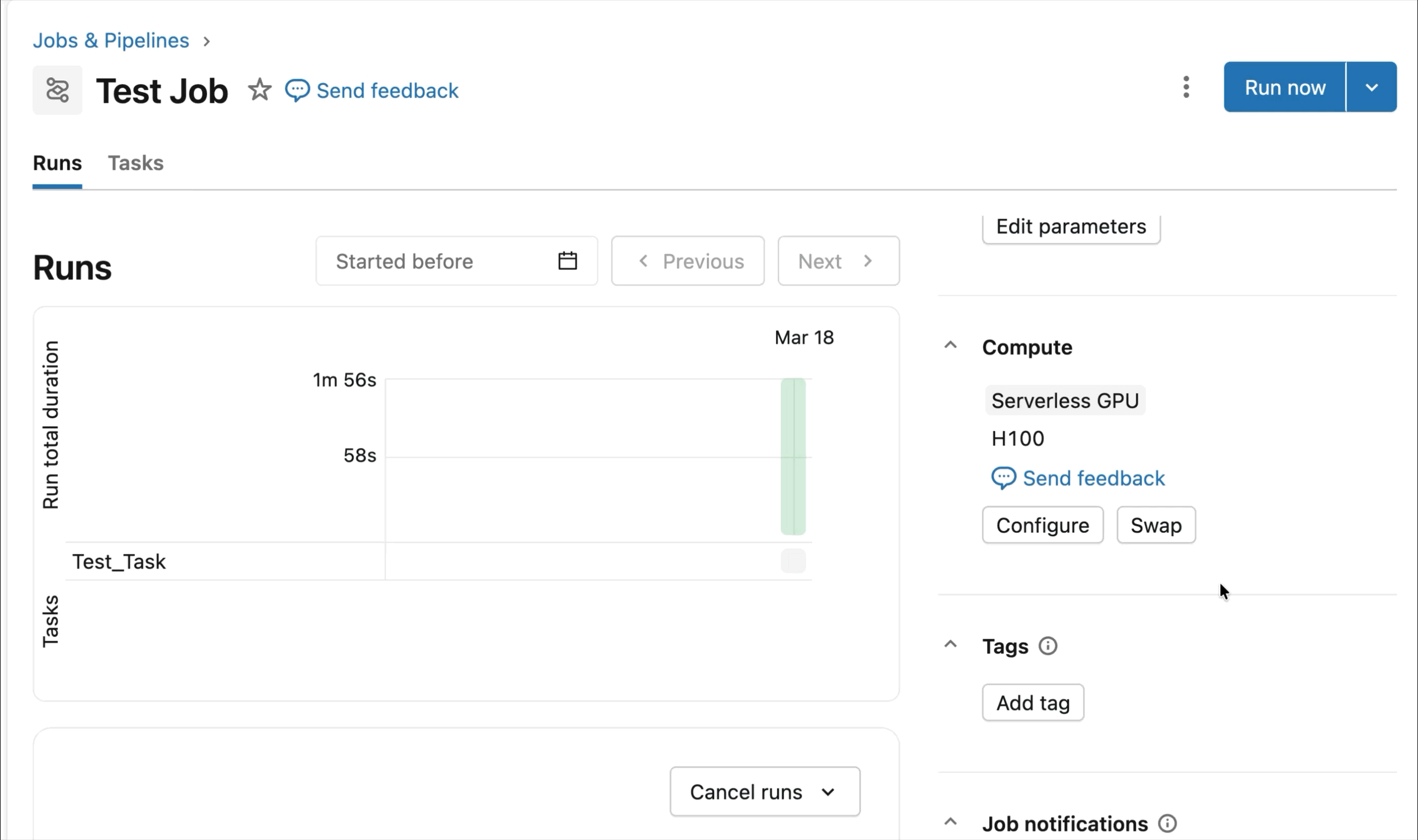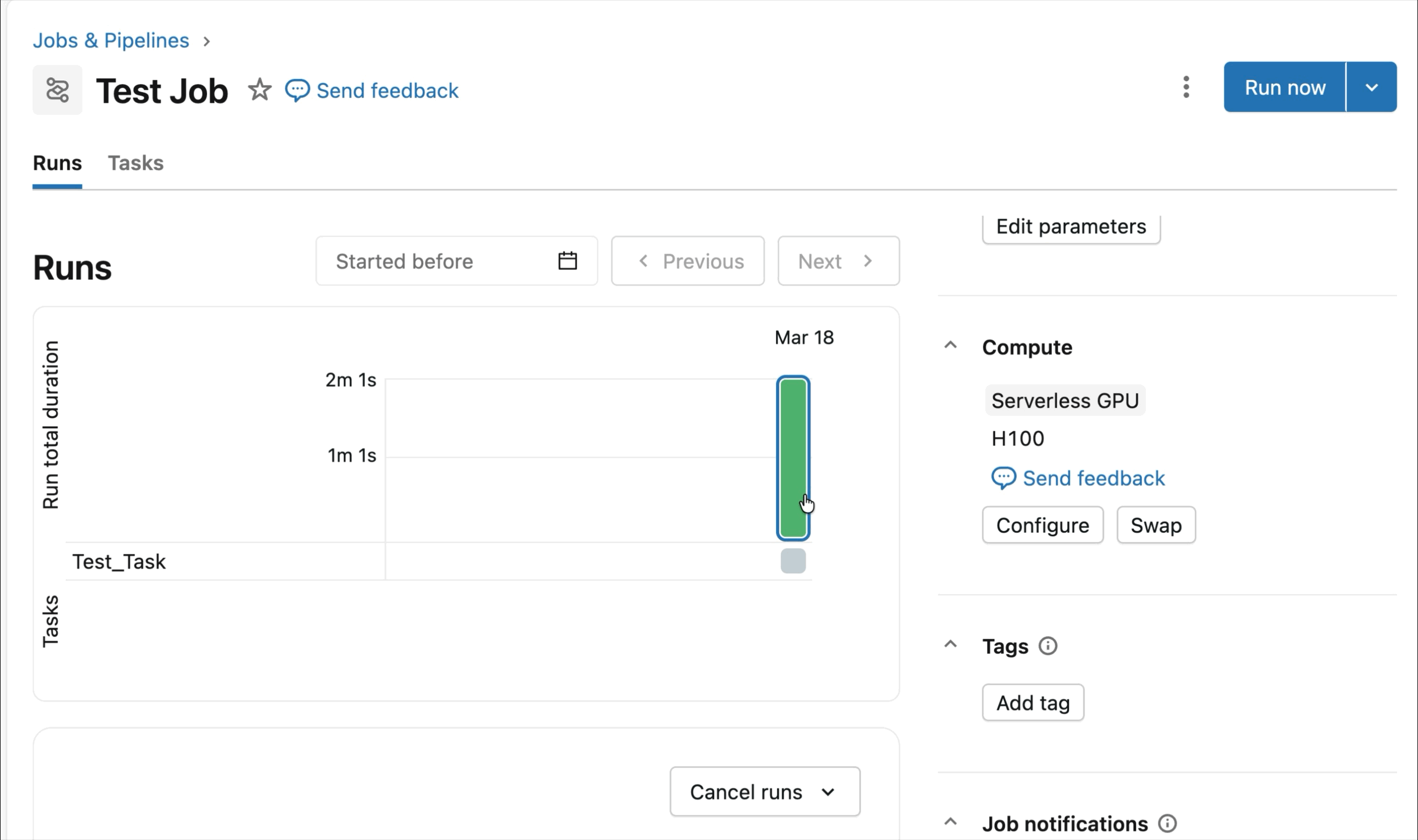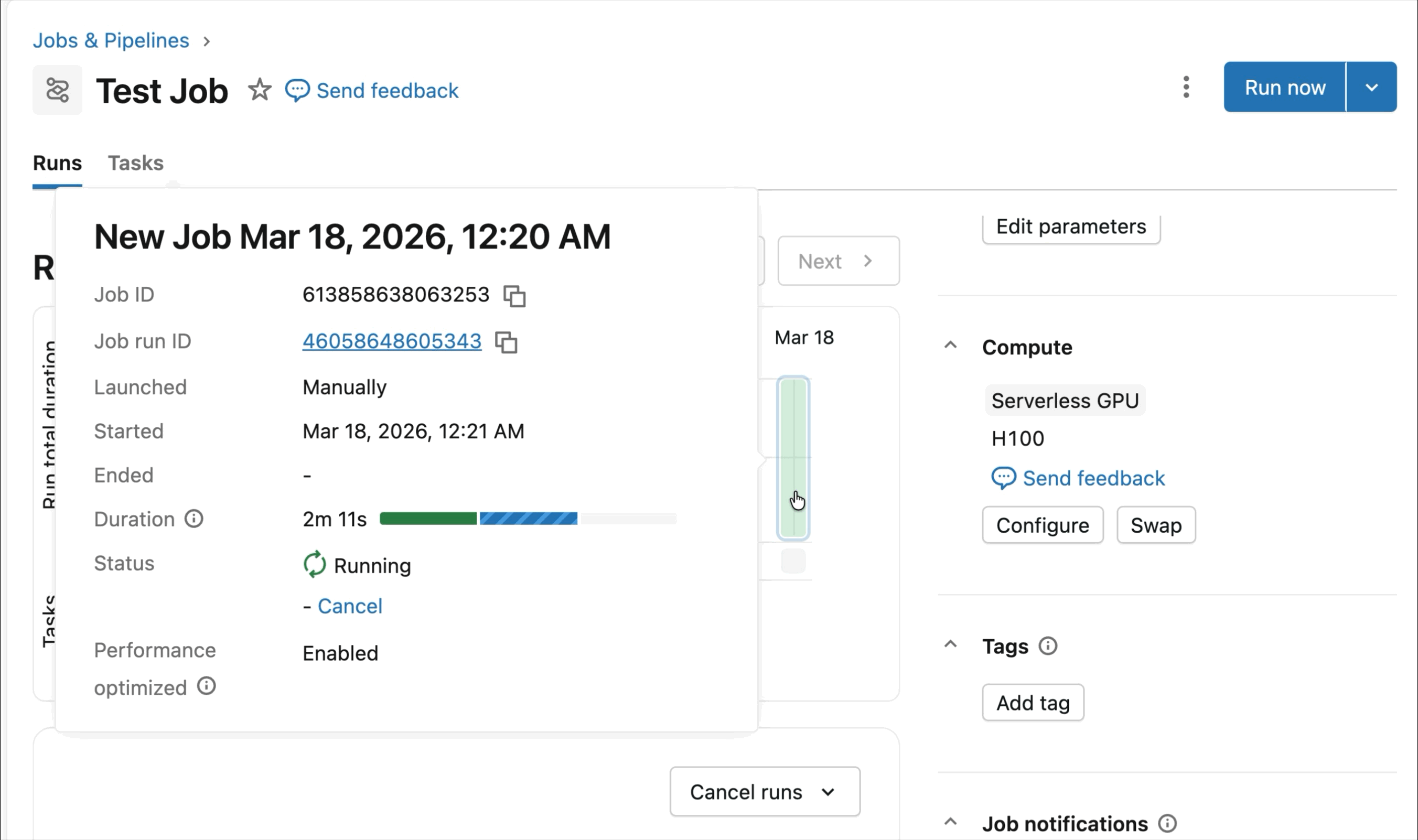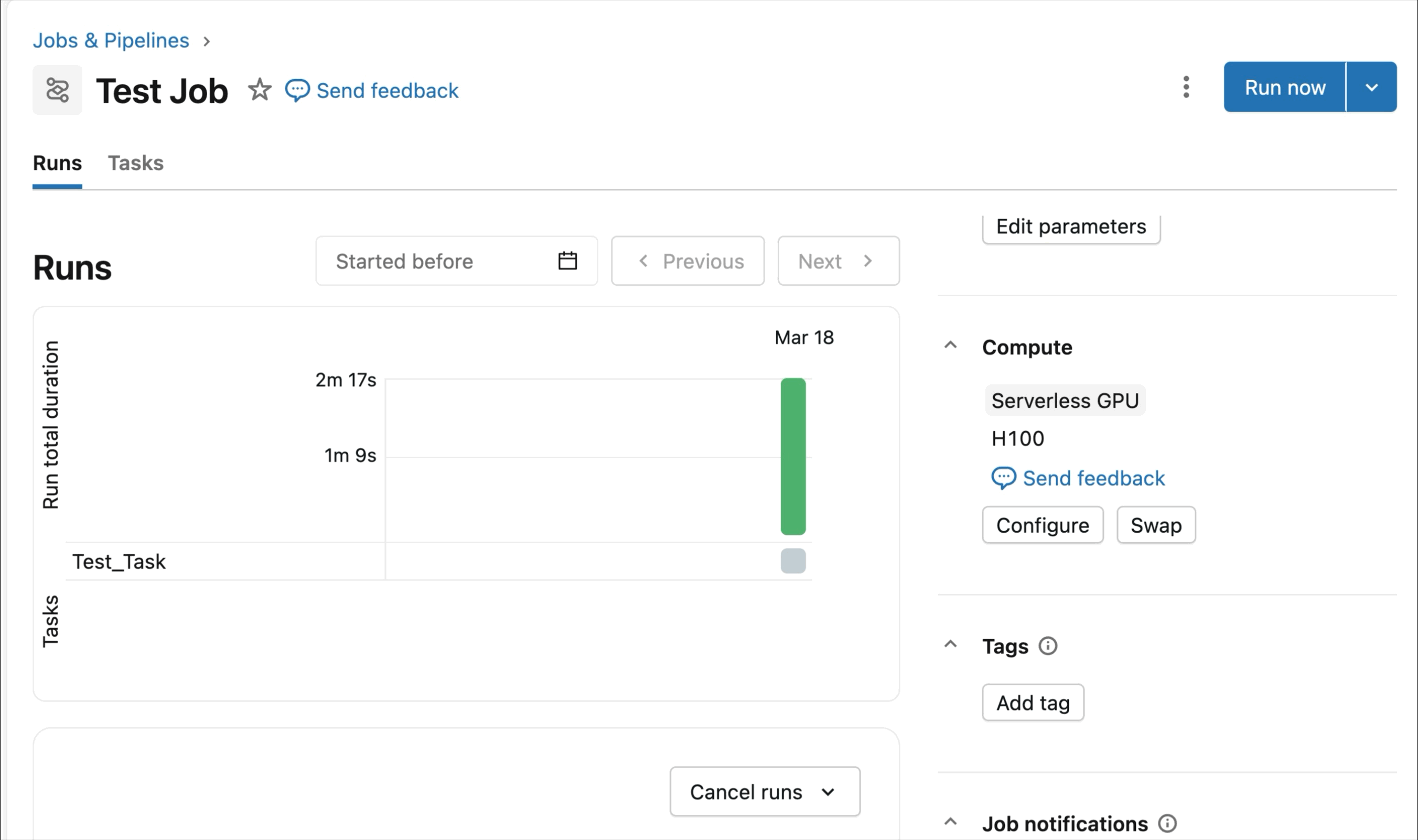
분산 딥러닝에 최적화된 런타임
분산 학습 워크로드는 준비, 디버깅 및 관찰이 까다로울 수 있습니다. RDMA 설정 문제 해결부터 여러 GPU의 원격 측정 추적, 적절한 소프트웨어 구성에 이르기까지 사용자는 모델 학습을 크게 느리게 하는 중요한 세부 정보를 쉽게 놓칠 수 있습니다.
대신 AI Runtime은 전체 딥러닝 수명 주기에 최적화되어 있으며 시간을 절약하도록 설계되었습니다. PyTorch 및 CUDA와 같은 주요 종속성이 사전 설치되어 있으며 Ray, Hugging Face Transformers, Composer 및 기타 라이브러리와 같은 분산 학습 프레임워크에 대한 최적화된 지원이 제공되므로 환경을 관리하지 않고도 즉시 학습을 시작할 수 있습니다. 고객은 Unsloth, TorchRec 또는 사용자 지정 학습 루프와 같은 자체 라이브러리를 가져올 수도 있습니다.

통합 SDK 및 관찰 가능성 도구는 분산 학습 워크로드 관리를 단순화합니다. MLFlow는 GPU 활용률 및 학습 실험의 자동 추적을 통해 GPU 워크로드에 대한 심층적인 관찰 가능성을 제공합니다. 파운데이션 모델을 미세 조정하든 예측 및 개인화 모델을 학습하든 런타임은 최소한의 설정으로 학습 워크플로를 가속화하도록 최적화되었습니다.
오늘날 AI Runtime의 공개 미리 보기는 단일 노드에서 8x H100에 걸친 분산 학습을 지원하며, 멀티 노드 지원은 현재 비공개 미리 보기 상태입니다.
"Databricks의 AI Runtime을 통해 인프라 오버헤드 없이 Lakehouse에서 직접 LLM 워크로드(미세 조정 및 추론)를 효율적으로 실행할 수 있습니다. 이 원활한 통합은 파이프라인을 단순화하고 GPU를 효율적으로 사용하여 고객에게 고품질 AI 인사이트를 제공하고 인프라가 아닌 혁신에 집중할 수 있도록 합니다.”—Lucas Froguel, 수석 AI 플랫폼 엔지니어, YipitData
중앙 집중식 데이터 거버넌스 및 관찰 가능성
AI Runtime은 Databricks Lakehouse와 기본적으로 통합되어 데이터가 있는 위치에서 GPU 워크로드를 실행하고 관리할 수 있습니다. 이를 통해 파편화된 워크플로를 제거하고 실험에서 프로덕션까지의 경로를 단순화합니다.
- Unity Catalog를 통한 중앙 집중식 거버넌스: 데이터 및 AI 워크로드 전반에 걸쳐 일관된 액세스 제어, 계보 및 거버넌스 정책을 적용하여 GPU 리소스의 안전하고 규정을 준수하는 사용을 가능하게 합니다.
- 통합 관찰 가능성: 통합 감사, 사용량 추적 및 운영 인사이트를 위한 기본 시스템 테이블을 사용하여 한 곳에서 모든 워크로드(CPU 및 GPU)를 추적하고 모니터링합니다.
AI 워크로드는 엔터프라이즈 데이터 경계 내에서 완전히 실행되어 실험 및 확장을 위한 유연성을 희생하지 않으면서 강력한 거버넌스 및 보안을 제공합니다.
“Lakehouse 내에서 Databricks의 서버리스 GPU 지원을 활용하면 인프라 오버헤드 없이 고급 오디오 및 멀티모달 모델을 효율적으로 학습할 수 있습니다. 이 원활한 통합은 워크플로를 단순화하고 GPU 리소스의 효율적인 사용을 제공하여 고�성능 시스템을 제공하고 혁신에 집중할 수 있도록 보장합니다.”—Arjuna Siva, 부사장, 인포테인먼트 및 커넥티비티, Rivian 및 Volkswagen Group Technologies
NVIDIA의 차세대 GPU 혁신 통합
AI 워크로드와 에이전트 시스템 전반에 걸쳐 가속 컴퓨팅에 대한 수요가 계속 증가하고 있습니다. AI Runtime을 통해 더 많은 Databricks 고객이 NVIDIA 하드웨어를 활용하여 AI 워크로드를 가속화하고 비즈니스를 발전시킬 수 있습니다. GTC 2026에서 발표된 RTX PRO 4500 Blackwell Server Edition과 같은 최신 NVIDIA 기술을 고객에게 제공하기 위해 NVIDIA와 계속 협력하게 되어 기쁩니다.
"산업 전반에 걸쳐 AI 채택이 가속화됨에 따라 조직은 데이터 및 AI 워크로드에 성능을 제공할 확장 가능하고 고성능 인프라가 필요합니다. NVIDIA 기술은 Databricks Lakehouse Platform의 AI Runtime에 가속화된 성능을 제공합니다."—NVIDIA 전략 파트너십 부사장 Pat Lee.
지금 바로 AI Runtime으로 시작하세요
시작하는 데 도움이 되도록 몇 가지 템플릿 노트북과 시작 가이드를 준비했습니다.
- 설정 및 일상적인 사용에 대한 자세한 지침은 문서를 참조하세요.
- 추천 시스템, 클래식 ML 모델, LLM 미세 조정 등을 위한 시작 템플릿을 확인하세요!
- 클래식 컴퓨팅 GPU 워크로드에서 서버리스로 마이그레이션하는 마이그레이션 가이드를 확인하세요.
자세한 내용은 계정 팀에 문의하거나 질문이 있으시면 언제든지 문의해 주세요!
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.