Databricks의 Spatial SQL 소개: 고성능 지리공간 분석을 위한 80개 이상의 함수
최고의 데이터 "웨어하우스"는 레이크하우스입니다
- 80개 이상의 공간 SQL 함수를 사용하여 확장된 지리 공간 쿼리를 가속화하세요. 현재 공개 미리 보기로 제공됩니다.
- 기본 GEOMETRY 및 GEOGRAPHY 데이터 유형을 사용하여 평면 및 측지 데이터를 모두 원활하게 저장하세요.
- 고성능 공간 조인으로 공간 분석을 강화하고 수동 인덱싱은 잊어버�리세요.
매일 수십억 개의 데이터 포인트가 지도상의 위치와 연결됩니다. 배송 경로, 매장 방문, 도로망, 기지국, 작물 밭 등은 모두 비즈니스 의사 결정에 중요한 맥락을 제공합니다. 문제는 이러한 데이터를 대규모로 분석하는 것이 어려웠다는 것입니다. 기존 공간 시스템은 느리고 수동 인덱싱이 필요하며 종종 정보를 독점 형식으로 고정시킵니다.
오늘 Databricks에서 Spatial SQL을 소개합니다. Spatial SQL은 Databricks 플랫폼에 지리 공간 분석을 직접 제공합니다. 이제 네이티브 GEOMETRY 및 GEOGRAPHY 데이터 유형을 사용하여 80개 이상의 SQL 함수를 활용하고, 데이터를 개방적이고 확장 가능하게 유지하면서 고속 및 고성능으로 공간 조인을 실행할 수 있습니다.
위치 데이터는 거의 모든 산업에서 중요한 역할을 하며, Spatial SQL은 해당 정보를 더 쉽게 사용할 수 있도록 합니다.
다음은 몇 가지 예시입니다.
- 소매 운영팀은 지역 및 유동 인구를 분석하여 고객이 어디에서 오는지 파악할 수 있습니다.
- 교통 분석가는 차량 사고 및 셀룰러 네트워크 연결을 분석하여 안전과 고객 경험을 개선할 수 있습니다.
- 에너지 회사는 정전 시 팀 배치를 최적화하고 풍력 및 태양�광 발전소를 위한 이상적인 위치를 찾을 수 있습니다.
- 농업 운영자는 정밀 농업 기술을 적용하여 비용을 절감하고 수확량 효율성을 개선할 수 있습니다.
- 보험 분석가는 정책 소유자의 주소를 홍수, 화재, 허리케인 지역에 걸쳐 분석하여 위험을 이해할 수 있습니다.
- 의료 기관은 지역에 걸친 환경 요인을 분석하여 건강 결과를 비교하고 예측할 수 있습니다.
- 그리고 훨씬 더 많은 가능성이 있습니다!
Spatial SQL은 이미 고객들이 성능을 가속화하고 비용을 절감하는 데 도움을 주고 있습니다.
“Databricks Spatial SQL은 대규모 공간 조인 실행 방식을 재정의했습니다. Spatial SQL 함수를 처리 파이프라인에 통합함으로써 동일한 워크로드에서 20배 이상의 성능 향상과 50% 이상의 비용 절감을 확인했습니다. 이 혁신적인 기능 덕분에 이전에는 실현 불가능했던 규모와 속도로 풍부한 도로망 데이터를 통합하고 제공할 수 있게 되었습니다.”
– Laxmi Duddu, Sr. Manager, Autonomy Data Platform & Analytics, Rivian Automotive
고객들은 이전에 기존 시스템, 타사 라이브러리 또는 수동 인덱싱 전략에 의존하여 공간 워크로드를 관리하고 확장하는 데 어려움을 겪었습니다. Spatial SQL을 사용하면 고객은 즉시 사용 가능한 단순성과 확장성을 얻을 수 있습니다.
“Spatial SQL을 통해 이전과는 비교할 수 없을 정도로 지리 공간 ETL을 확장할 수 있습니다. 무거운 쿼리로 PostGIS 서버에 과부하를 주는 대신, 부하를 Databricks로 옮겨 분산 처리, 빠른 공간 조인 및 벡터 데이터의 효율적인 처리를 활용합니�다. 대규모의 복잡한 지리 공간 데이터를 처리하는 데 있어 더 효율적이고 탄력적이며 확장 가능한 접근 방식입니다.”
— Pierre Chenaux, Tech Leader of Geospatial department, TotalEnergies
성능의 주요 동인은 1급 지리 공간 데이터 유형에 대한 지원입니다. geo 데이터를 문자열, 이진 또는 십진수 열에 저장하는 대신, 이제 네이티브 GEOMETRY 및 GEOGRAPHY 데이터 유형을 사용할 수 있습니다. 이러한 유형에는 Databricks가 쿼리 실행 중에 관련 없는 데이터를 건너뛰고 조인을 가속화하는 데 사용하는 경계 상자 통계가 포함됩니다. Spatial SQL은 또한 Well Known Text, Well Known Binary, GeoJSON 및 간단한 위도 또는 경도 값과 같은 표준 형식에 대한 import 함수를 제공합니다.
이러한 데이터 유형은 Parquet, Iceberg, 및 Delta에서 완전히 개방적입니다. Databricks 팀은 독점 웨어하우스에 대한 종속성이 없도록 제안된 사양을 만드는 데 기여했습니다. 승인된 Apache Spark™ SPIP를 통해 GEOMETRY 및 GEOGRAPHY는 곧 오픈 소스 엔진에서도 1급 데이터 유형이 될 것입니다.
Spatial SQL로 무엇을 할 수 있나요?
Spatial SQL은 새로운 함수의 집합 그 이상입니다. 저장, 가져오기부터 분석 및 변환까지 공간 데이터의 전체 여정을 관리할 수 있는 빌딩 블록을 제공합니다. 네이티브 데이터 유형과 효율적인 연산을 사용하여 복잡성을 추가하지 않고도 일상적인 쿼리에 위치 정보를 통합할 수 있습니다.
다음은 수행할 수 있는 몇 가지 핵심 작업입니다.
- GEOMETRY 및 GEOGRAPHY를 사용하여 공간 데이터를 네이티브로 저장
- WKT, WKB, GeoJSON, GeoHash와 같은 형식으로 가져오기 및 내보내기
- ST_Point 또는 ST_MakeLine과 같은 생성자를 사용하여 새 객체 구축
- ST_Distance 및 ST_AREA와 같은 함수를 사용하여 측정값 계산
- ST_Contains 및 ST_Intersects와 같은 관계를 사용하여 공간 조인 수행
- ST_Transform을 사용하여 좌표계 간 변환
- ST_ISVALID 또는 ST_UNION_AGG를 사용하여 공간 객체 편집, 유효성 검사 및 결합
- 그리고 훨씬 더 많은 가능성이 있습니다!
이러한 기능은 SQL에서 직접 사용할 수 있는 완전한 공간 분석 도구 키트를 제공하며, Python 및 Scala API에서도 사용할 수 있습니다. 이러한 기능들을 결합하면 실제 워크플로우를 구현할 수 있으며, 다음 섹션에서 자세히 살펴보겠습니다.
실제 Spatial SQL 예시
지리 공간 데이터는 어디에나 존재하며 계속 증가하고 있습니다. 위도와 경도를 포함한 GPS 추적 데이터는 매초마다 점점 더 많은 장치, 센서 및 차량에서 생성됩니다. 세상은 점, 선, 다각형으로 모델링된 장소, 도로, 네트워크 및 경계를 포함하여 끊임없이 기록되고 업데이트되고 있습니다. 소매, 운송 및 물류, 에너지, 기후 및 자연 과학, 농업, 공공 부문, 금융 서비스, 부동산, 보험, 통신 등 모든 산업 분야에서 위치는 데이터의 “어디에”를 이해해야 하는 모든 의사 결정권자에게 중요합니다.
새로운 공간 데이터 유형 및 표현식을 사용하여 작업하기 위한 네 가지 짧은 예시를 다음과 같은 목표로 준비했습니다.
- 새로운 GEOMETRY 유형을 사용하여 효율적인 처리를 위한 데이터 준비
- 공간 조인을 사용하여 두 개의 공간 데이터 세트를 결합하여 데이터 보강
- 거리 측정의 정확도를 높이기 위해 데이터를 적절한 공간 참조 시스템으로 변환
- 두 도시 간의 거리 측정
이 예시에서는 OvertureMaps.org의 주소, 건물 및 지역 데이터 세트를 사용합니다. 이러한 데이터 세트는 GeoParquet와 같은 다양한 방법으로 다운로드할 수 있습니다.
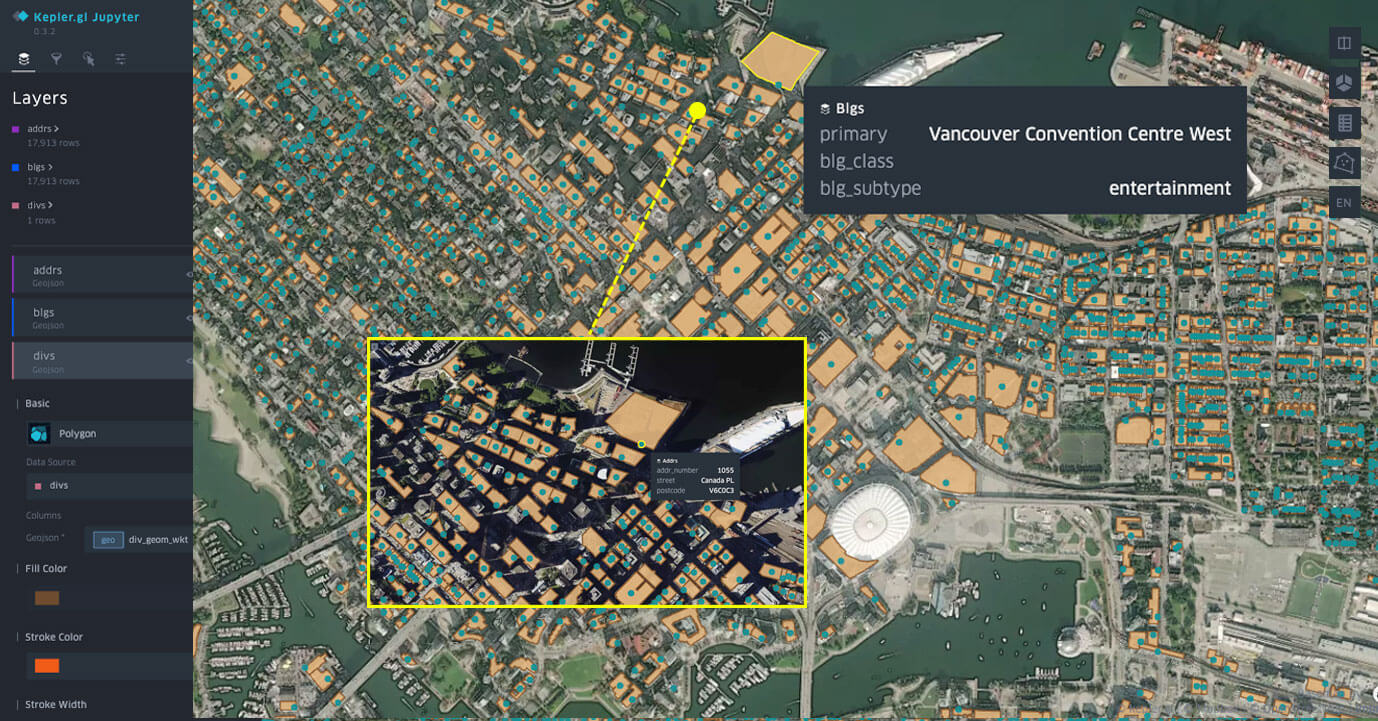
Databricks Notebook에서 kepler.gl을 사용하여 시각화된 Overture Maps 데이터 세트.
1. GEOMETRY 열 생성
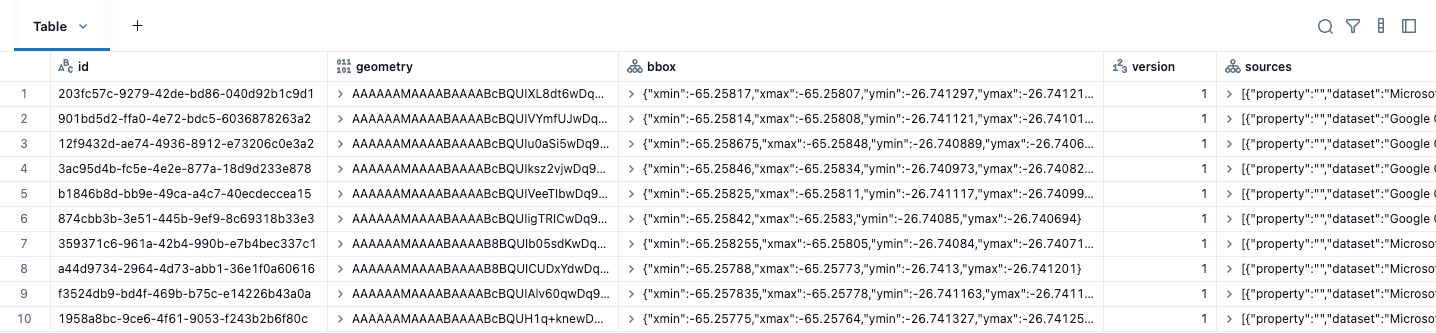
공간 분석을 수행하기 전 첫 번째 단계는 데이터를 GEOMETRY 또는 GEOGRAPHY 데이터 유형을 사용하도록 변환하는 것입니다. Overture Maps 데이터를 다운로드한 후, 제공된 WKB geometry 열에서 네이티브 GEOMETRY 열을 생성하고 bbox와 같은 다른 불필요한 열을 삭제하기만 하면 됩니다. 경계 상자는 지오메트리를 포함하는 가장 작은 사각형입니다. 공간 쿼리에서 경계 상자는 잠재적으로 겹칠 수 있는 데이터를 빠르게 폐기하여 쿼리를 가속화합니다. 두 경계 상자가 교차하지 않으면 그 안의 지오메트리도 확실히 교차하지 않으므로, 데이터베이스는 비싼 교차점 확인을 건너뛰고 처리되는 데이터 양을 줄일 수 있습니다. 이 정보는 이제 열 통계에서 관리되므로 bbox 필드는 필요하지 않습니다. 이러한 데이터 세트의 경우, 주소는 POINTS이고 건물 및 지역은 POLYGONS / MULTI-POLYGONS입니다. 다음은 처음에 다운로드한 건물 데이터이며 처음 다섯 개의 열을 보여줍니다.
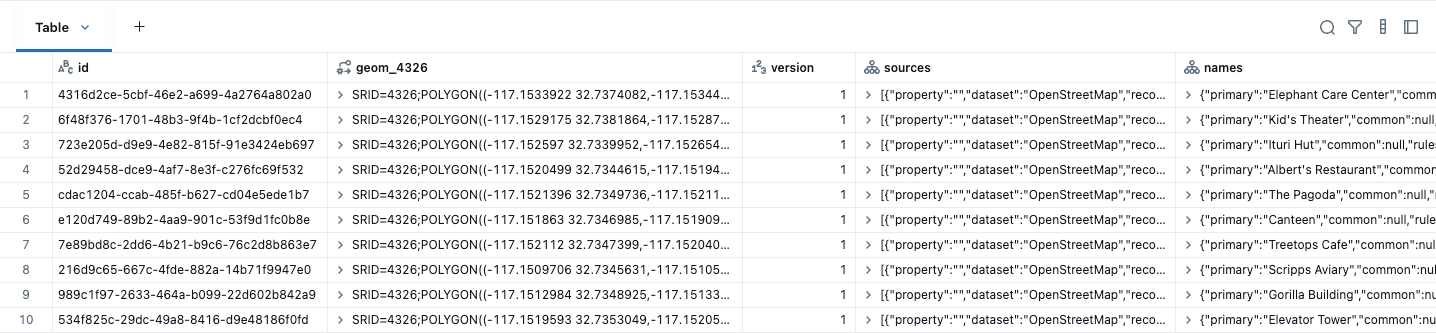
이 데이터는 건물에 대한 아래 예시에서 볼 수 있듯이 네이티브 GEOMETRY를 사용하여 ST_GeomFromWKB로 쉽게 Lakehouse 테이블로 변환할 수 있습니다. 데이터가 WGS84(EPSG:4326)에 있다는 것을 알고 있으므로 공간 유형 생성 시 이를 지정합니다. SRID는 공간 데이터의 좌표 시스템을 식별하며, 거리 및 면적과 같은 계산에 사용되는 단위(예: 도 또는 미터)를 정의합니다. 기하학적 열을 생성할 때 유효한 SRID를 설정해야 하며, 그렇지 않으면 쿼리가 오류를 반환합니다. 또한 네이티브 유형이 사람이 읽기 쉬운 형식(EWKT)으로 표시된다는 점에 유의하세요.
WKB 외에도 공간 데이터는 가장 일반적인 교환 형식에서 네이티브 유형으로 직접 가져올 수 있습니다.
- ST_POINT를 사용한 위도 및 경도 좌표
- ST_GeomFromWKT 또는 ST_GeomFromText를 사용한 WKT
- ST_GeomFromWKB 또는 ST_GeomFromBinary를 사용한 WKB
- ST_GeomFromGeoJSON을 사용한 GeoJSON
- ST_PointFromGeoHash를 사용한 GeoHash
마찬가지로 공간 데이터는 다음과 같은 여러 형식으로 내보낼 수 있습니다.
- ST_AsWKT 또는 ST_AsText를 사용한 WKT
- ST_AsWKB 또는 ST_AsBinary를 사용한 WKB
- ST_AsGeoJSON을 사용한 GeoJSON
- ST_AsEWKT를 사용한 확장 WKT
- ST_AsEWKB를 사용한 확장 WKB
- ST_GeoHash를 사용한 GeoHash
참고: GEOGRAPHY 유형에 대한 가져오기 및 내보내기 표현식도 있습니다.
2. 여러 데이터 세트를 공간적으로 조인하기
공간 조인은 지리 공간 데이터 처리에서 가장 중요하고 널리 사용되는 작업 중 하나입니다. 이를 통해 다른 데이터 세트의 속성을 결합하고 포함, 교차 및 근접성과 같은 공간 관계를 기반으로 집계 또는 데이터 보강을 수행할 수 있습니다. 이를 통해 홍수 지역 내에 속하는 건물 식별, 주소에 대한 인구 통계 지정, 통신 범위 영역 내의 연결된 차량 분석과 같은 실제 질문에 답하는 데 필수적입니다. 지리 공간 분석의 상당 부분이 여러 데이터 세트 통합에 의존하므로 공간 조인은 탐색적 공간 분석, 공간 모델링 및 위치 기반 의사 결정의 첫 단계가 되는 경우가 많습니다.
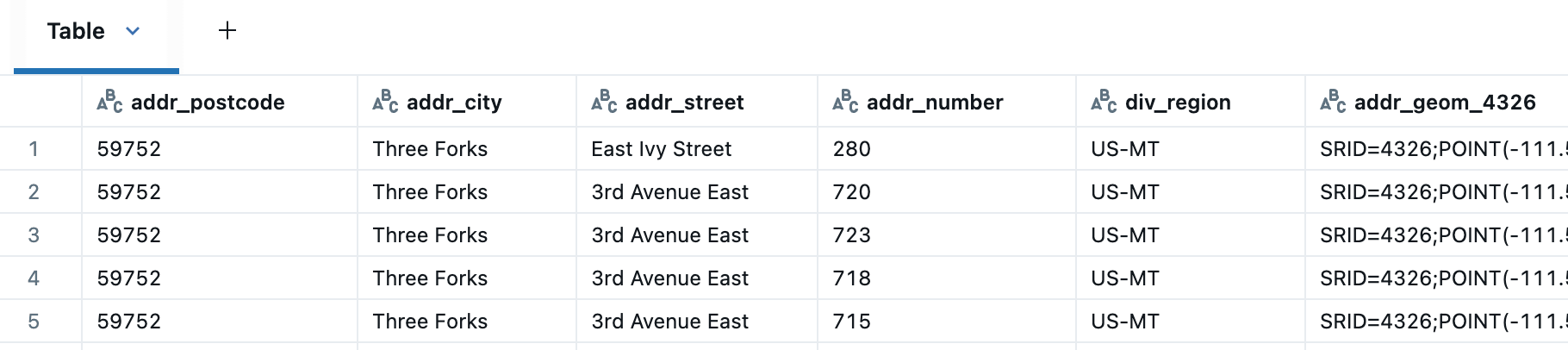
다음으로 공간 조인을 사용하여 주소 및 부서 테이블을 조인합니다. 주소 데이터 소스를 다루어 본 사람은 누구나 주소가 지저분한 데이터가 될 수 있다는 것을 알고 있습니다(한 가지 일반적인 원인은 다른 국가에서 다른 주소 체계를 사용한다는 것입니다). 또한 주소 테이블에는 전체 관리 계층 구조가 포함되어 있지 않습니다(예: 미국 주소에 대한 카운티 정보 없음). 따라서 부서 테이블을 사용하여 도시 정보를 확인하고 카운티와 동등한 정보를 추가하여 보강할 것입니다.
이 데이터 유효성 검사 및 보강 프로세스는 공간 조인 없이는 해결하기가 다를 것입니다. 이를 위해 부서 내에서 주소�를 찾아야 합니다. 포인트-인-폴리곤 공간 조인을 수행하기 위해 ST_Contains를 사용하며, Databricks가 작업의 내부를 처리하도록 하여 수동 공간 인덱싱이 필요하지 않습니다.
이제 부서 테이블에 제공된 정보를 사용하여 누락된 도시를 대체하는 등 올바른 도시, 주, 카운티 및 국가로 더 쉽게 표준화할 수 있습니다.
주소를 확인한 후 유사한 접근 방식을 사용하여 ST_Intersects를 통해 주소와 건물을 조인하여 건물 테이블을 주소 정보로 보강했습니다. 미국에서는 이 공간 조인이 4,400만 개의 주소를 건물과 일치시켰고 5,500만 개의 건물은 일치하지 않았습니다. 다음 예에서는 근접성을 사용하여 주소와 일치하지 않은 건물을 식별하는 방법을 살펴보겠습니다.
3. 특정 공간 참조 시스템으로 데이터 변환하기
지리 공간 데이터 세트는 종종 원본 및 목적에 따라 위도-경도(WGS84) 또는 UTM과 같은 투영 시스템과 같은 다른 좌표 참조 시스템(CRS)으로 생성됩니다. 각 CRS는 지구의 곡면이 평평한 지도에 어떻게 표현되는지를 정의하지만, 투영이 일치하지 않는 데이터 세트를 사용하면 피처가 잘못 정렬되��거나, 거리가 왜곡되거나, 잘못된 공간 조인 및 측정이 발생할 수 있습니다. 홍수 지역에 있는 상점은 다른 좌표계를 사용하는 경우 공간 조인에서 일치하지 않습니다. 영역 계산, 레이어 조인 또는 공간 관계 시각화와 같은 정확한 분석을 위해서는 모든 데이터 세트가 동일한 투영으로 변환되어 일관된 공간 참조를 공유하도록 하는 것이 필수적입니다.
미국에서 일치하지 않은 나머지 5,500만 건물과의 근접성 내 주소를 식별하기 위해 WGS84 GEOMETRY 데이터를 북미의 Conus Albers(EPSG:5070)로 투영하여 미터 단위의 단위를 얻습니다. 이는 ST_Transform 함수를 사용하여 수행됩니다.
일치하지 않은 미국 건물과 주소 간에 2미터의 거리 내 값을 사용하여 ST_DWithin을 적용해 보겠습니다.
거리 내 값은 잠재적인 주소 일치 세트를 수집하기 위해 필요에 따라 증가할 수 있으며, 재귀 CTE를 사용하여 여러 거리에 걸쳐 반복할 수 있습니다. 이 예에서는 필터 폴리곤을 사용하여 검색을 세인트피터즈버그, 플로리다 근처로 쉽게 격리할 수 있습니다. 폴리곤은 처음에 WKT를 사용하여 준비된 다음, 주소 및 건물 데이터와 일치하도록 SRID 5070으로 변환됩니다.
재귀 CTE에 대한 데이터 세트를 설정하기 위해 건물과 주소를 검색 폴리곤과 교차시켜 데이터에 공간 필터를 적용합니다. 아래는 건물(주소는 유사하게 처리됨)을 보여줍니다.
아래의 재귀 CTE는 5미터, 10미터, 15미터 이내의 주소 후보를 식별하기 위해 건물을 반복합니다. 결과 테이블은 다음 창 표현식을 사용하여 연속적인 거리에 걸쳐 중복 주소를 제거합니다: QUALIFY RANK() OVER (PARTITION BY blg_id,addr_id ORDER BY dwithin) = 1.
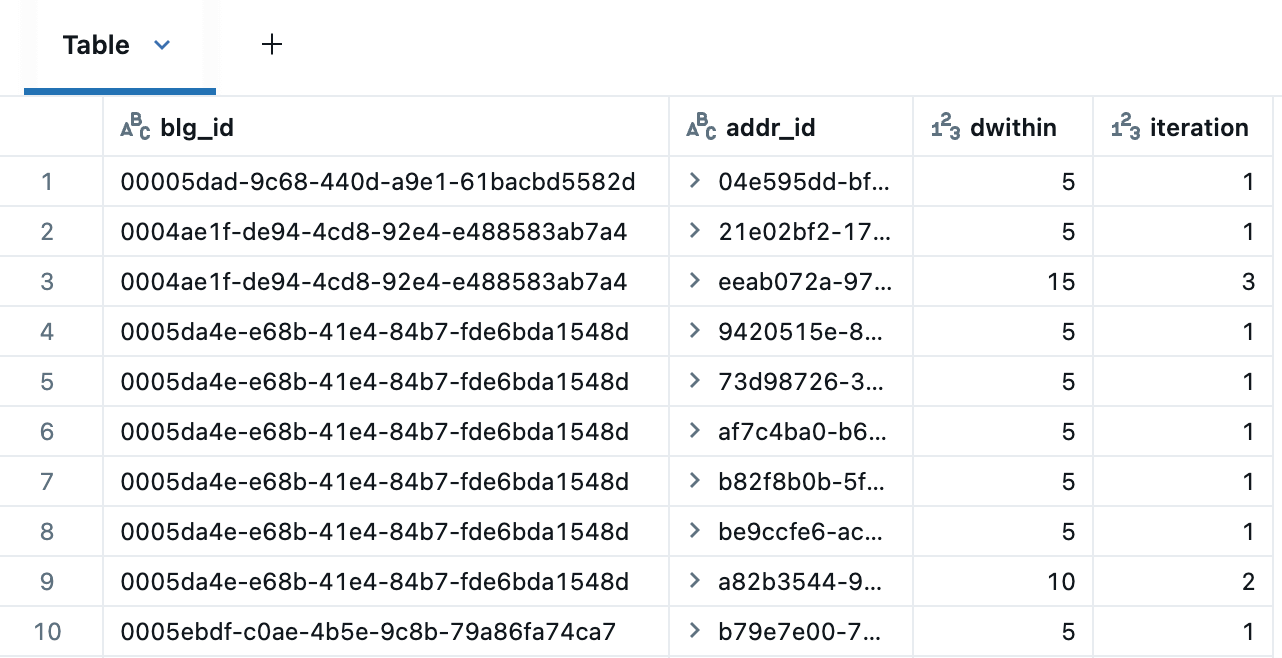
다음은 건물 주변의 주소 후보 목록으로, 5m(파란색), 10m(주황색), 15m(녹색)에서의 일치 항목을 보여줍니다. 이는 Databricks의 내장 마커 맵을 클러스터링 모드로 렌더링한 것으로, 보기 쉽게 가까운 지점을 분산시킵니다. 대시보드를 생성할 때 교차 필터링 및 드릴스루를 지원하는 AI/BI 포인트 맵을 사용했을 수도 있습니다.
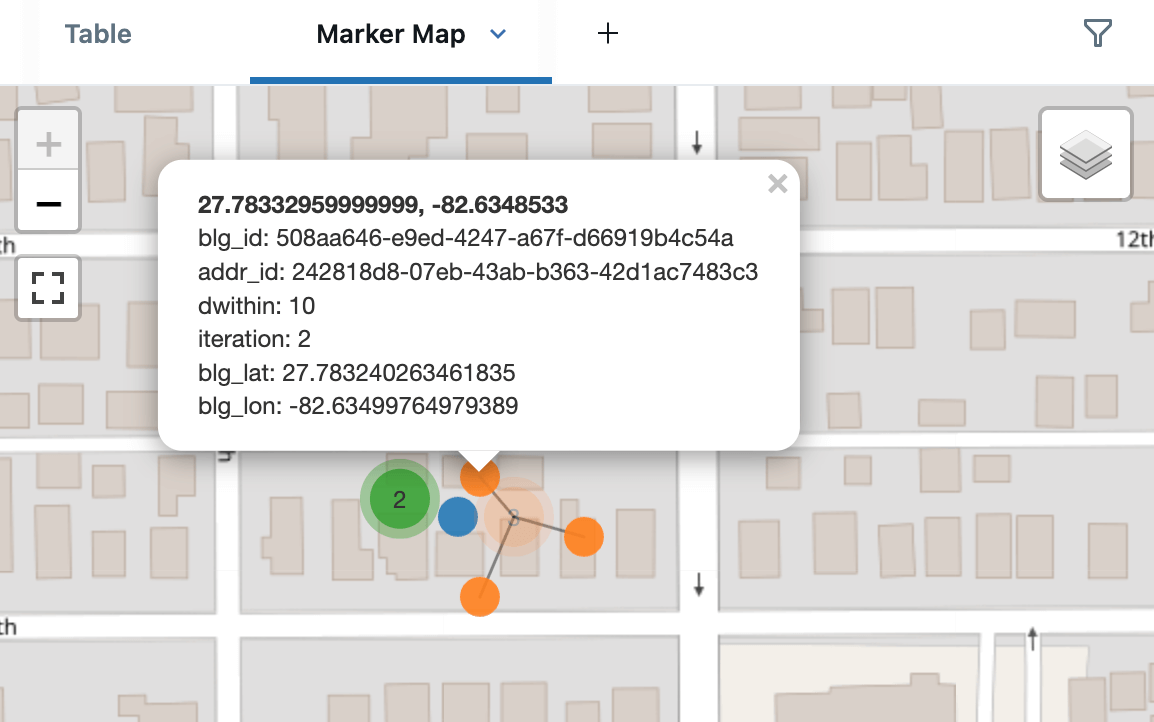
재귀 CTE를 공간 처리에 사용하는 수많은 대안이 있습니다. 예를 들어, 배송 지점의 최소 신장 트리를 구축하기 위한 Prim 알고리즘 구현이 있습니다.
4. 위치 간 거리 측정
근접성은 공간 분석의 핵심 개념입니다. 왜냐하면 거리가 종종 위치 간 관계의 강도나 관련성을 결정하기 때문입니다. 가장 가까운 병원을 식별하든, 상점 간 경쟁을 분석하든, 통근 패턴을 매핑하든, 피처 간의 거리를 이해하는 것은 중요한 맥락을 제공합니다.
예제 데이터셋을 계속해서, 플로리다의 도시들에 동일한 Conus Albers 변환 연산을 수행하여 거리를 측정했습니다. 함수를 사용하여 생성된 도시의 기하학적 중심에서 측정하고 있습니다: ST_Centroid.
두 GEOMETRY 간의 거리를 계산할 때 고려해야 할 몇 가지 다른 함수가 있습니다:
- ST_Distance - 제공된 GEOMETRY의 단위로 데카르트 거리를 반환합니다. 지구를 평평하다고 가정하고 x 및 y 좌표를 기반으로 직선 경로를 ��계산합니다.
- ST_DistanceSphere - 두 지점 GEOMETRY 간의 구면 거리를 반환합니다(항상 미터 단위). WGS84 타원체의 평균 반경을 기준으로 측정하며, 좌표 지점은 도 단위라고 가정합니다. 예를 들어 SRID 4326은 유효하지만 SRID 5070은 유효하지 않습니다.
- ST_DistanceSpheroid - WGS84 타원체 상의 두 지점 GEOMETRY 간의 측지 거리(항상 미터 단위)를 반환합니다. 또한 좌표 지점은 도 단위라고 가정합니다. 다시 말하지만, SRID 4326 또는 도 단위의 다른 SRID는 이 예제의 유효한 입력입니다.
다양한 거리 계산은 city1과 city2 사이에 적용됩니다. 5070의 GEOMETRY에는 ST_Distance를 사용하고, 4326의 GEOMETRY에는 ST_DistanceSphere 및 ST_DistanceSpheroid를 사용합니다.
거리 함수 중에서 ST_DistanceSpheriod(지구의 타원체 모양 기반 측정)가 이 경우 가장 정확할 것으로 예상되며, 그 다음으로 ST_DistanceSphere(측정은 지구가 완벽한 구라고 가정)가 올 것입니다. ST_Distance는 투영된 좌표 참조 시스템에서 작업하거나 지구 곡률을 무시할 수 있는 경우에 가장 유용합니다. SRID 5070은 미터 단위이지만, 더 먼 거리에서 데카르트 계산의 효과를 볼 수 있습니다. 플로리다 주 내에서만도 경도 1도의 차이가 최대 6KM에 달하므로, ST_Distance는 일반적으로 SRID 4326에 적합한 선택이 아닐 것입니다.
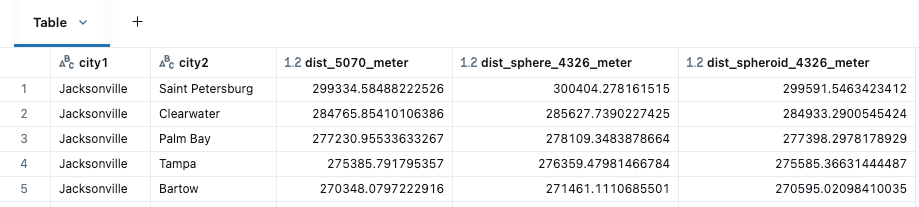
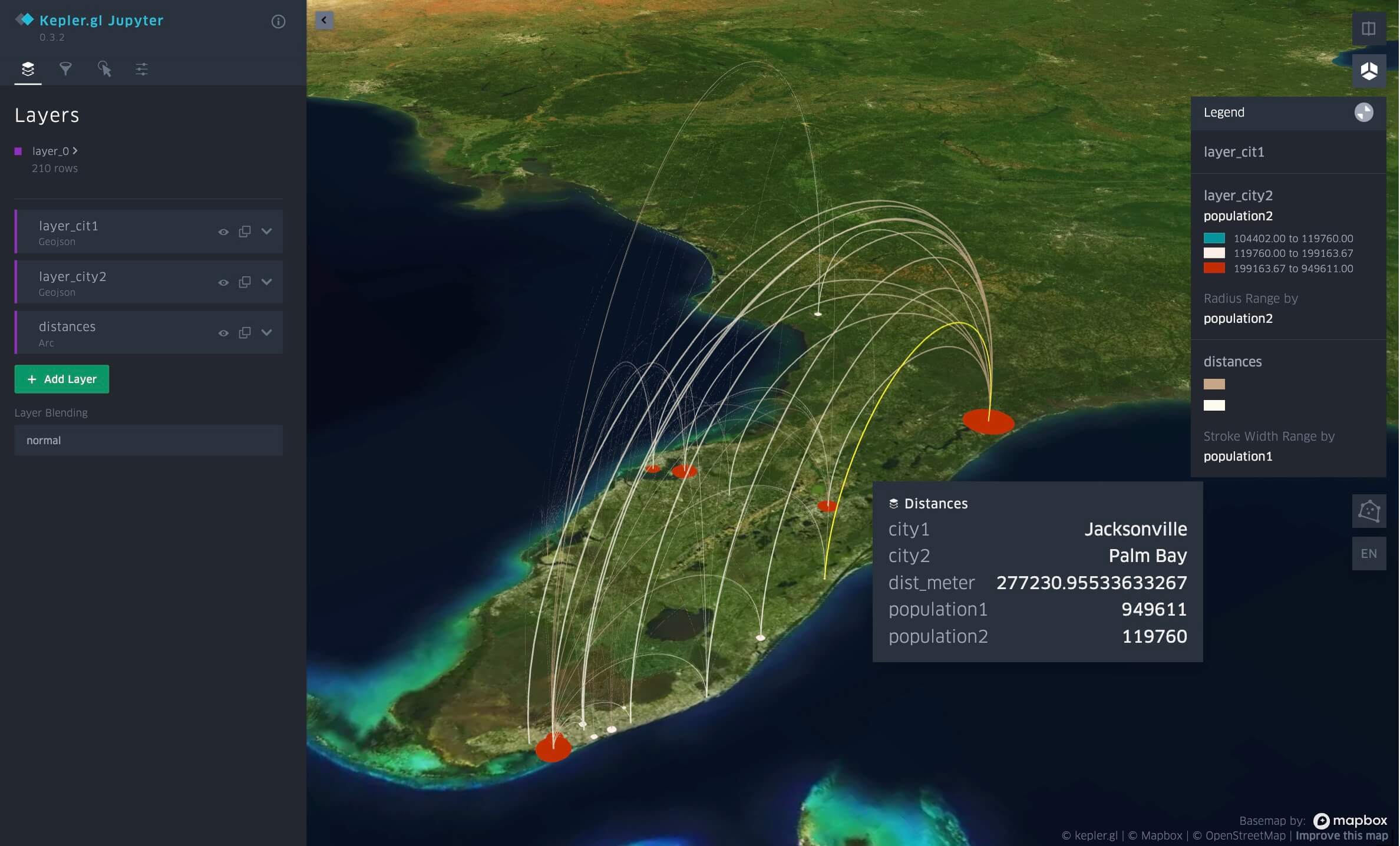
플로리다 도시 간 거리별 근접성. Databricks Notebook에서 kepler.gl을 사용하여 시각화했습니다.
Spatial SQL은 80개 이상의 함수를 포함하여 고객이 일반적인 공간 데이터 작업을 단순하고 확장 가능하게 수행할 수 있도록 합니다. Spatial SQL을 통해 고객은 GIS 시스템과의 통합 및 관리 접근 방식을 전환하기 시작했습니다:
“공간 데이터는 OSPRI의 모든 것의 핵심입니다. 가축 추적성, 질병 근절 또는 해충 관리 모두 마찬가지입니다. Databricks Spatial SQL을 통해 모든 작업에 Databricks를 완전히 통합할 수 있습니다. 이러한 발전으로 인해 대규모 데스크톱 기반 공간 모델링 작업을 데이터에 더 가깝고 병렬로 빠르게 실행할 수 있는 플랫폼으로 전환할 수 있습니다. 운영 경계를 넘나드는 몇 주간의 반복 작업이 하루 또는 이틀 내에 편안하게 완료될 수 있어 의사 결정 시간이 단축됩니다. 또한 이러한 새로운 함수를 통해 Databricks를 운영 시스템과 GIS 플랫폼 간의 통합 계층으로 만들어 조직 전체의 데이터로 타협 없이 정보를 얻을 수 있습니다.” - Campbell Fleury, Manager, Data and Information Products, OSPRI New Zealand
다음 단계
Databricks의 Spatial SQL로 할 수 있는 일은 매우 많으며, 새로운 표현식과 더 빠른 공간 조인을 포함하여 더 많은 기능이 추가될 예정입니다. 추가로 필요한 ST 표현식이 있다면 이 짧은 설문조사를 작성해 주세요.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.