LLM의 긴 컨텍스트 RAG 성능
컨텍스트가 길다고 항상 도움이 되는 것은 아닙니다
작성자: 퀸 렝, Jacob Portes, Sam Havens, Matei Zaharia , Michael Carbin
검색 증강 생성(RAG)은 저희 고객들 사이에서 가장 널리 채택된 생성형 AI 사용 사례입니다. RAG는 비정형 문서나 정형 데이터와 같은 외부 소스에서 정보를 검색하여 LLM의 정확도를 향상시킵니다. Anthropic Claude(200k 컨텍스트 길이), GPT-4-turbo(128k 컨텍스트 길이) 및 Google Gemini 1.5 pro(2백만 컨텍스트 길이)와 같이 더 긴 컨텍스트 길이를 가진 LLM을 사용할 수 있게 되면서, LLM 앱 개발자들은 더 많은 문서를 RAG 애플리케이션에 공급할 수 있습니다. 긴 컨텍스트 길이를 극단적으로 활용하면, 긴 컨텍스트 언어 모델이 결국 RAG 워크플로우를 대체할 것인지에 대한 논쟁까지 있습니다. 전체 코퍼스를 컨텍스트 창에 삽입할 수 있다면 왜 데이터베이스에서 개별 문서를 검색해야 할까요?
이 블로그 게시물은 컨텍스트 길이 증가가 RAG 애플리케이션의 품질에 미치는 영향을 탐구합니다. 저희는 13개의 인기 있는 오픈 소스 및 상용 LLM에 대해 2,000건 이상의 실험을 실행하여 다양한 도메인별 데이터셋에서의 성능을 파악했습니다. 저희는 다음과 같은 사실을 발견했습니다:
- 더 많은 문서를 검색하는 것이 실제로 유익할 수 있습니다: 주어진 쿼리에 대해 더 많은 정보를 검색하면 올�바른 정보가 LLM에 전달될 가능성이 높아집니다. 긴 컨텍스트 길이를 가진 최신 LLM은 이를 활용하여 전반적인 RAG 시스템을 개선할 수 있습니다.
- 더 긴 컨텍스트가 항상 RAG에 최적인 것은 아닙니다: 대부분의 모델 성능은 특정 컨텍스트 크기 이후에 감소합니다. 특히 Llama-3.1-405b의 성능은 32k 토큰 이후 감소하기 시작하고, GPT-4-0125-preview는 64k 토큰 이후 감소하기 시작하며, 일부 모델만이 모든 데이터셋에서 일관된 긴 컨텍스트 RAG 성능을 유지할 수 있습니다.
- 모델은 매우 다른 방식으로 긴 컨텍스트에서 실패합니다: 저희는 Llama-3.1-405b, GPT-4, Claude-3-sonnet, DBRX 및 Mixtral의 긴 컨텍스트 성능에 대한 심층 분석을 수행했으며, 저작권 문제로 인한 거부 또는 항상 컨텍스트를 요약하는 것과 같은 고유한 실패 패턴을 식별했습니다. 이러한 동작 중 다수는 충분한 긴 컨텍스트 후처리 학습 부족을 시사합니다.
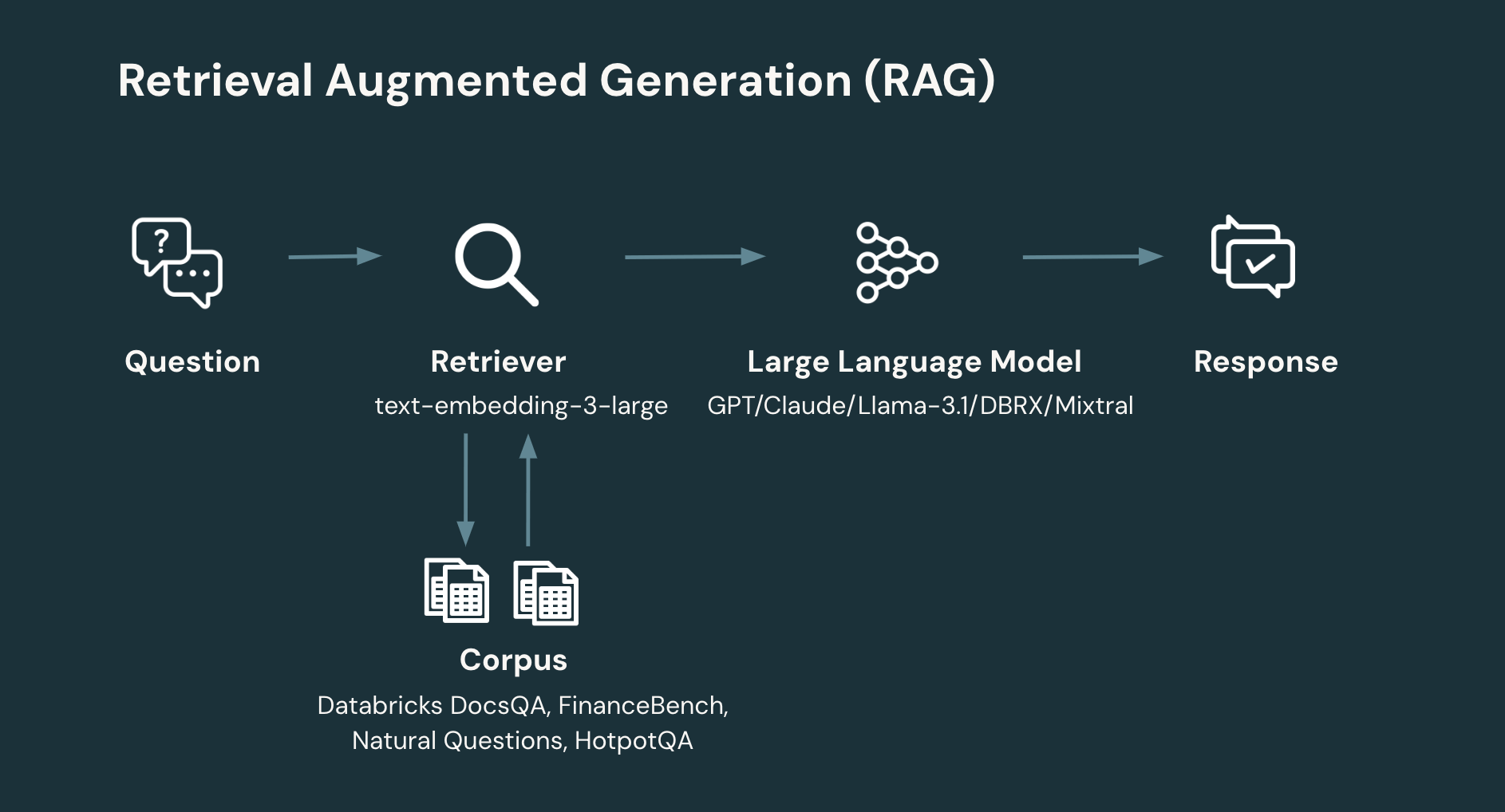
배경
RAG: 일반적인 RAG 워크플로우는 최소 두 단계로 구성됩니다:
- 검색: 사용자의 질문이 주어지면 코퍼스 또는 데이터베�이스에서 관련 정보를 검색합니다. 정보 검색은 시스템 설계의 풍부한 영역입니다. 그러나 간단하고 현대적인 접근 방식은 개별 문서를 임베딩하여 벡터 모음을 생성하고 이를 벡터 데이터베이스에 저장하는 것입니다. 그런 다음 시스템은 사용자의 질문과 문서 간의 유사성을 기반으로 관련 문서를 검색합니다. 검색의 핵심 설계 매개변수는 문서 수이며, 따라서 반환되는 총 토큰 수입니다.
- 생성: 사용자의 질문과 검색된 정보가 주어지면 해당 응답을 생성합니다(또는 답변을 생성할 정보가 충분하지 않으면 거부합니다). 생성 단계는 광범위한 기술을 사용할 수 있습니다. 그러나 간단하고 현대적인 접근 방식은 검색된 정보와 답변할 질문에 대한 관련 컨텍스트를 소개하는 간단한 프롬프트를 통해 LLM에 프롬프트를 제공하는 것입니다.
RAG는 많은 도메인과 작업에서 QA 시스템의 품질을 향상시키는 것으로 나타났습니다(Lewis et.al 2020).
긴 컨텍스트 언어 모델: 최신 LLM은 점점 더 큰 컨텍스트 길이를 지원합니다.
원래 GPT-3.5는 컨텍스트 길이가 4k 토큰에 불과했지만, GPT-4-turbo 및 GPT-4o는 컨텍스트 길이가 128k입니다. 마��찬가지로 Claude 2는 컨텍스트 길이가 200k 토큰이고 Gemini 1.5 pro는 2백만 토큰의 컨텍스트 길이를 자랑합니다. 오픈 소스 LLM의 최대 컨텍스트 길이도 비슷한 추세를 따랐습니다. 첫 세대 Llama 모델은 컨텍스트 길이가 2k 토큰에 불과했지만, Mixtral 및 DBRX와 같은 최신 모델은 32k 토큰 컨텍스트 길이를 가지고 있습니다. 최근 출시된 Llama 3.1은 최대 128k 토큰을 지원합니다.
RAG에 긴 컨텍스트를 사용하는 이점은 시스템이 검색 단계를 증강하여 생성 모델의 컨텍스트에 더 많은 검색된 문서를 포함할 수 있다는 것입니다. 이는 질문 답변에 관련된 문서가 모델에 제공될 확률을 높입니다.
반면에, 긴 컨텍스트 모델에 대한 최근 평가는 두 가지 광범위한 한계를 드러냈습니다:
- “중간에서 길을 잃는” 문제: “중간에서 길을 잃는” 문제는 모델이 긴 텍스트의 중간 부분에서 정보를 유지하고 효과적으로 활용하는 데 어려움을 겪을 때 발생합니다. 이 문제는 컨텍스트 길이가 증가함에 따라 성능 저하로 이어질 수 있으며, 모델은 광범위한 컨텍스트에 걸쳐 분산된 정보를 통합하는 데 덜 효과적이 됩니다.
- Effective context length: the RULER paper explored the performance of long context models on several categories of tasks including retrieval, variable tracking, aggregation and question answering, and found that the effective context length - the amount of usable context length beyond which model performance begins to decrease – can be much shorter than the claimed maximum context length.
With these research observations in mind, we designed multiple experiments to probe the potential value of long context models, the effective context length of long context models in RAG workflows, and assess when and how long context models can fail.
Methodology
To examine the effect of long contexton retrieval and generation, both individually and on the entire RAG pipeline, we explored the following research questions:
- The effect of long context on retrieval: How does the quantity of documents retrieved affect the probability that the system retrieves a relevant document?
- The effect of long context on RAG: How does generation performance change as a function of more retrieved documents?
- The failure modes for long context on RAG: How do different models fail at long context?
We used the following retrieval settings for experiments 1 and 2:
- embedding model: (OpenAI) text-embedding-3-large
- chunk size: 512 tokens (we split the documents from the corpus into chunk size of 512 tokens)
- stride size: 256 tokens (the overlap between adjacent chunks is 256 tokens)
- vector store: FAISS (with IndexFlatL2 index)
We used the following LLM generation settings for experiment 2:
- generation models: gpt-4o, claude-3-5-sonnet, claude-3-opus, claude-3-haiku, gpt-4o-mini, gpt-4-turbo, claude-3-sonnet, gpt-4, meta-llama-3.1-405b, meta-llama-3-70b, mixtral-8x7b, dbrx, gpt-3.5-turbo
- temperature: 0.0
- max_output_tokens: 1024
When benchmarking the performance at context length X, we used the following method to calculate how many tokens to use for the prompt:
- Given the context length X, we first subtracted 1k tokens which is used for the model output
- We then left a buffer size of 512 tokens
The rest is the cap for how long the prompt can be (this is the reason why we used a context length 125k instead of 128k, since we wanted to leave enough buffer to avoid hitting out-of-context errors).
Evaluation datasets
In this study, we benchmarked all LLMs on 4 curated RAG datasets that were formatted for both retrieval and generation. These included Databricks DocsQA and FinanceBench, which represent industry use cases and Natural Questions (NQ) and HotPotQA, which represent more academic settings . Below are the dataset details:
| Dataset \ Details | Category | Corpus #docs | # queries | AVG doc length (tokens) | min doc length (tokens) | max doc length (tokens) | Description |
| Databricks DocsQA (v2) | Use case specific: corporate question-answering | 7563 | 139 | 2856 | 35 | 225941 | DocsQA is an internal question-answering dataset using information from public Databricks documentation and real user questions and labeled answers. Each of the documents in the corpus is a web page. |
| FinanceBench (150 tasks) | Use case specific: finance question-answering | 53399 | 150 | 811 | 0 | 8633 | FinanceBench는 공개 기업의 360개 SEC 10k 제출 서류와 SEC 10k 문서를 기반으로 한 해당 질문 및 정답을 포함하는 학술 질의응답 데이터셋입니다. 더 자세한 내용은 논문 Islam et al. (2023)에서 확인할 수 있습니다. 저희는 Patronus의 전체 데이터셋의 독점 (비공개 소스) 버전을 사용합니다. 저희 코퍼스에 있는 각 문서는 SEC 10k PDF 파일의 페이지에 해당합니다. |
| Natural Questions (dev split) | 학술: 일반 지식 (위키피디아) 질의응답 | 7369 | 534 | 11354 | 716 | 13362 | Natural Questions는 Google의 학술 질의응답 데이터셋으로, 2019년 논문 (Kwiatkowski et al., 2019)에서 다루어졌습니다. 쿼리는 Google 검색 쿼리입니다. 각 질문은 검색 결과의 위키피디아 페이지 내용을 사용하여 답변됩니다. 저희는 비자연어 텍스트의 대부분이 제거된 위키 페이지의 간소화된 버전을 사용하지만, 문서 내 유용한 구조(예: 테이블)를 정의하기 위해 일부 HTML 태그가 남아 있습니다. 간소화는 원본 구현을 적용하여 수행됩니다. |
| BEIR-HotpotQA | 학술: 다중홉 일반 지식 (위키피디아) 질의응답 | 5233329 | 7405 | 65 | 0 | 3632 | HotpotQA는 영어 위키피디아에서 수집된 학술 질의응답 데이터셋입니다. 저희는 BEIR 논문(Thakur et al, 2021)의 HotpotQA 버전을 사용합니다. |
평가 지표:
- 검색 지표: 검색 성능을 측정하기 위해 재현율을 사용했습니다. 재현율 점수는 검색된 관련 문서 수를 총 관련 문서 수로 나눈 비율로 정의됩니다.
- 생성 지표: 생성 성능을 측정하기 위해 답변 정확도 지표를 사용했습니다. 저희는 GPT-4o 기반의 보정된 LLM-as-a-judge 시스템을 통해 답변 정확도를 구현했습니다. 저희 보정 결과는 judge-to-human 일치율이 human-to-human 일치율만큼 높다는 것을 보여주었습니다.
RAG에 긴 컨텍스트가 필요한 이유?
실험 1: 더 많은 문서를 검색할 때의 이점
이 실험에서는 더 많은 결과를 검색하는 것이 생성 모델의 컨텍스트에 포함되는 관련 정보의 양에 어떤 영향을 미치는지 평가했습니다. 구체적으로, 검색기가 X개의 토큰을 반환한다고 가정하고 해당 컷오프에서의 재현율 점수를 계산했습니다. 다른 관점에서 보면, 재현율 성능은 생성 모델이 답변 생성에 검색된 문서만 사용해야 할 때 생성 모델 성능의 상한선입니다.
아래�는 4개의 데이터셋과 다른 컨텍스트 길이에 대한 OpenAI text-embedding-3-large 임베딩 모델의 재현율 결과입니다. 청크 크기는 512 토큰을 사용하고 프롬프트 및 생성을 위해 1.5k 버퍼를 남겨둡니다.
| # 검색된 청크 | 1 | 5 | 13 | 29 | 61 | 125 | 189 | 253 | 317 | 381 |
Recall@k \ 컨텍스트 길이 | 2k | 4k | 8k | 16k | 32k | 64k | 96k | 128k | 160k | 192k |
| Databricks DocsQA | 0.547 | 0.856 | 0.906 | 0.957 | 0.978 | 0.986 | 0.993 | 0.993 | 0.993 | 0.993 |
| FinanceBench | 0.097 | 0.287 | 0.493 | 0.603 | 0.764 | 0.856 | 0.916 | 0.916 | 0.916 | 0.916 |
| NQ | 0.845 | 0.992 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| HotPotQA | 0.382 | 0.672 | 0.751 | 0.797 | 0.833 | 0.864 | 0.880 | 0.890 | 0.890 | 0.890 |
| Average | 0.468 | 0.702 | 0.788 | 0.839 | 0.894 | 0.927 | 0.947 | 0.95 | 0.95 | 0.95 |
Saturation point: as can be observed in the table, each dataset’s retrieval recall score saturates at a different context length. For the NQ dataset, it saturates early at 8k context length, whereas DocsQA, HotpotQA and FinanceBench datasets saturate at 96k and 128k context length, respectively. These results demonstrate that with a simple retrieval approach, there is additional relevant information available to the generation model all the way up to 96k or 128k tokens. Hence, the increased context size of modern models offers the promise of capturing this additional information to increase overall system quality.
Using longer context does not uniformly increase RAG performance
Experiment 2: Long context on RAG
이번 실험에서는 검색 단계와 생성 단계를 간단한 RAG 파이프라인으로 구성했습니다. 특정 컨텍스트 길이에서의 RAG 성능을 측정하기 위해, 생성 모델의 컨텍스트를 주어진 컨텍스트 길이까지 채우도록 검색기가 반환하는 청크 수를 늘립니다. 그런 다음 주어진 벤치마크에 대한 질문에 답변하도록 모델에 프롬프트를 제공합니다. 아래는 다양한 컨텍스트 길이에서의 이러한 모델들의 결과입니다. 검색기가 반환하는 청크 수
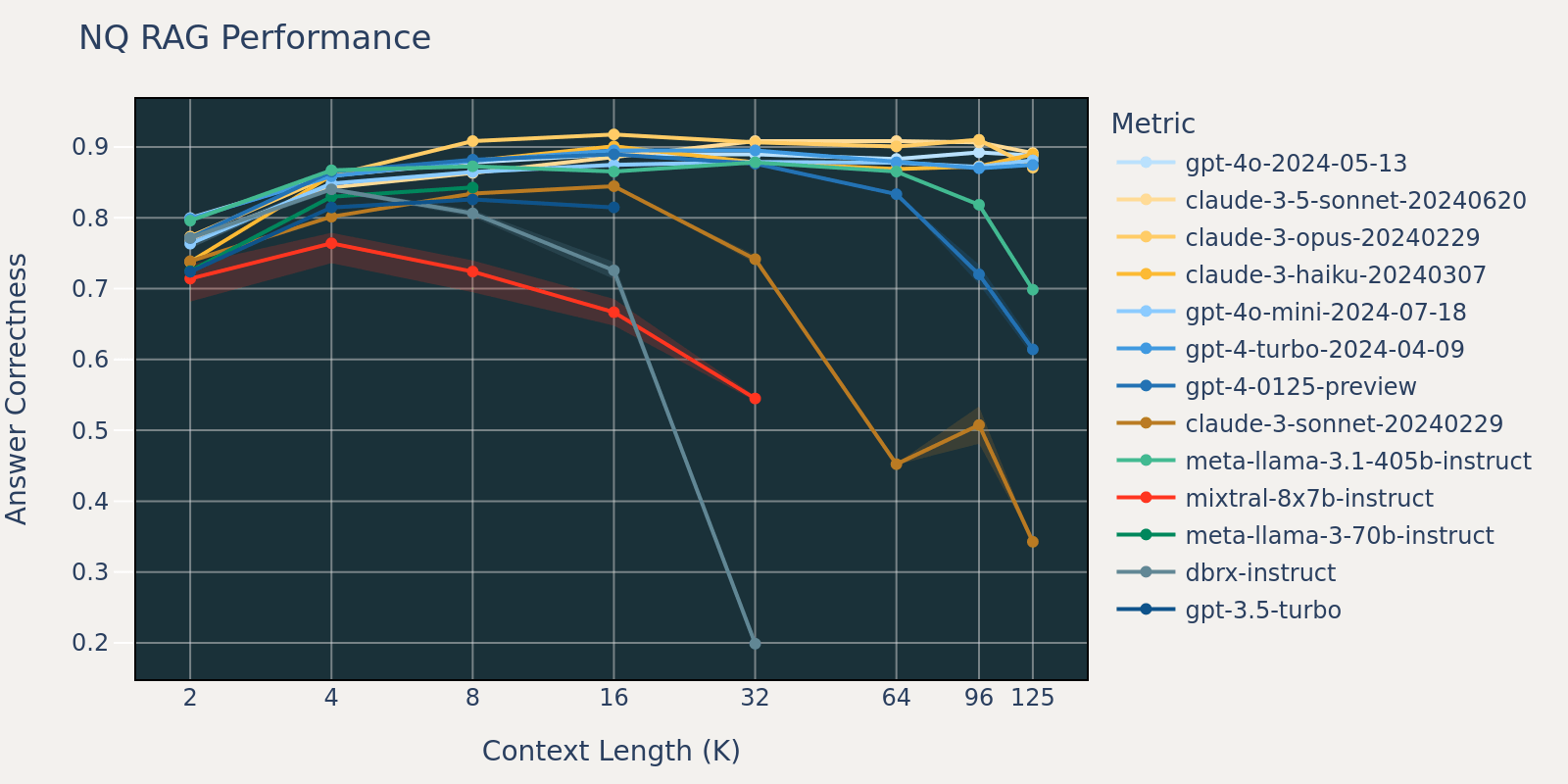
Natural Questions 데이터셋은 공개적으로 사용 가능한 일반적인 질문 답변 데이터셋입니다. 대부분의 언어 모델이 Natural Question과 유사한 작업으로 학습 또는 미세 조정되었을 것이라고 추측하므로, 짧은 컨텍스트 길이에서는 모델 간에 상대적으로 작은 점수 차이를 관찰할 수 있습니다. 컨텍스트 길이가 늘어남에 따라 일부 모델의 성능이 감소하기 시작합니다.
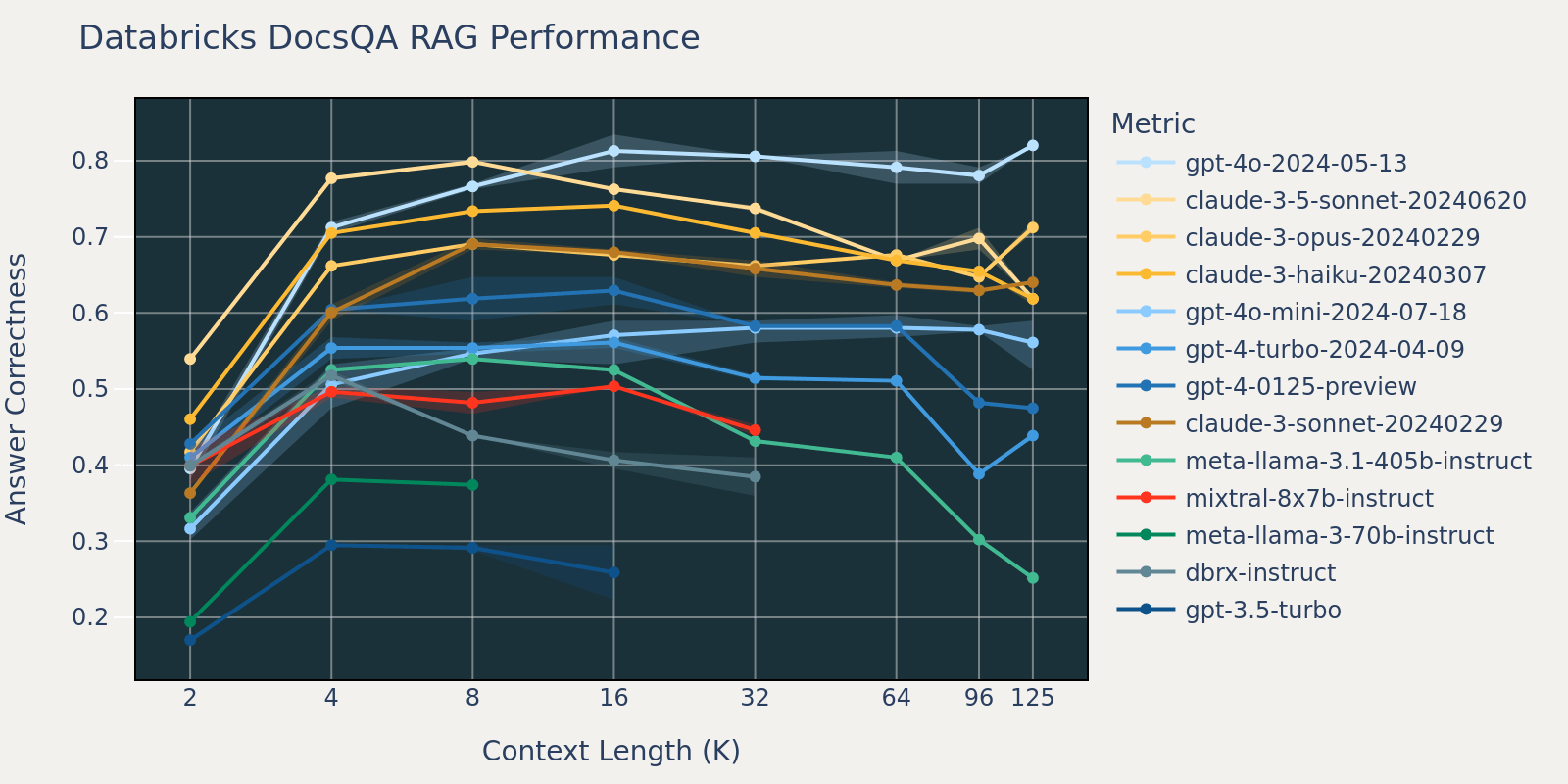
Natural Questions와 비교했을 때, Databricks DocsQA 데이터셋은 공개적으로 사용 가능하지 않습니다(데이터셋은 공개적으로 사용 가능한 문서에서 큐레이션되었지만). 이 작업은 사용 사례에 더 특화되어 있으며 Databricks 문서 기반의 엔터프라이즈 질문 답변에 중점을 둡니다. 모델이 유사한 작업으로 학습되었을 가능성이 낮기 때문에, 모델 간 RAG 성능이 Natural Questions보다 더 다양하다고 추측합니다. 또한, 이 데이터셋의 평균 문서 길이가 3k로 FinanceBench보다 훨씬 짧기 때문에, FinanceBench보다 성능 포화가 더 일찍 발생합니다.
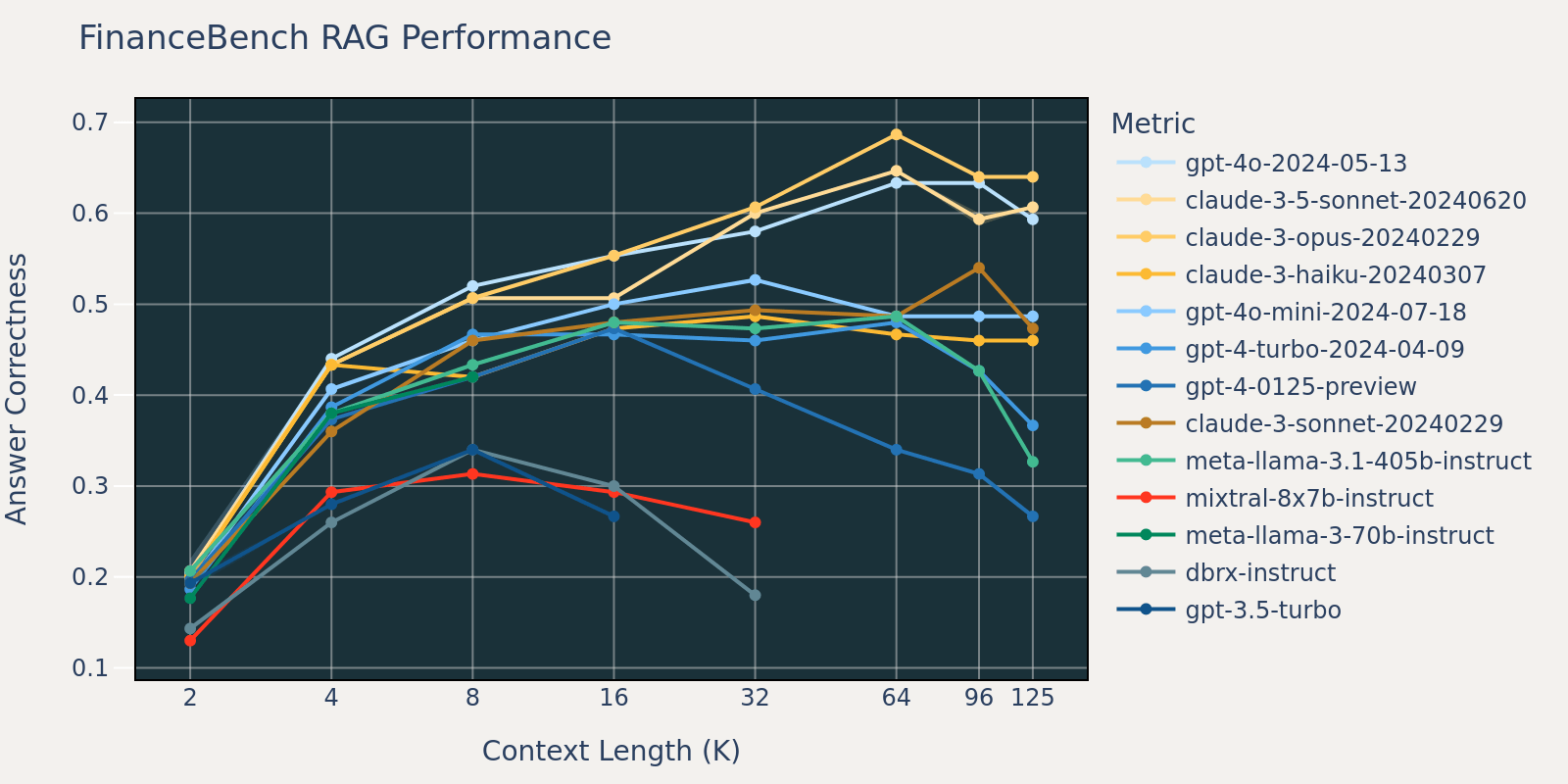
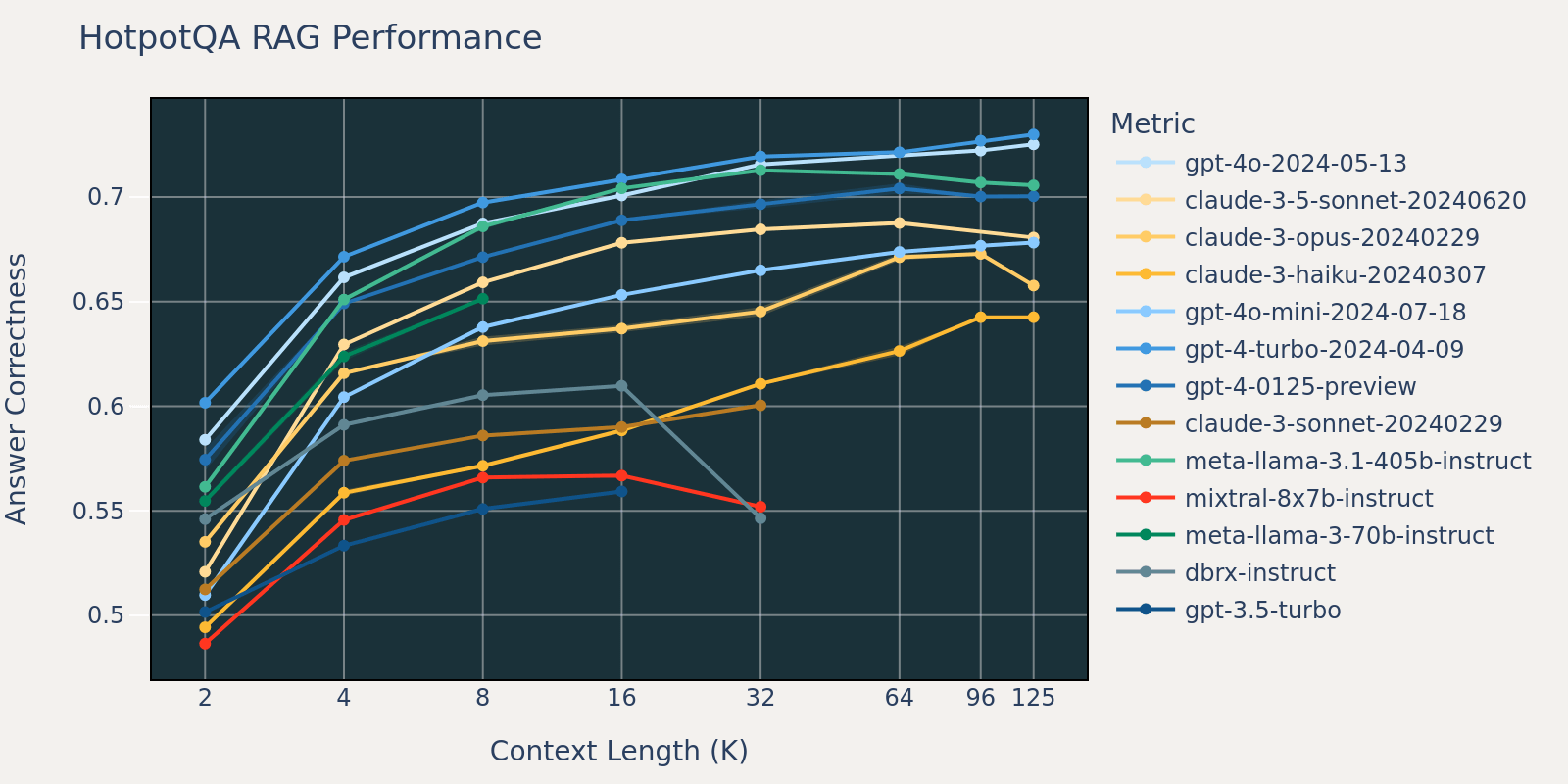
FinanceBench 데이터셋은 SEC 10k 제출 서류와 같은 더 긴 문서를 포함하��는 또 다른 사용 사례별 벤치마크입니다. 벤치마크의 질문에 올바르게 답하려면 모델이 코퍼스에서 관련 정보를 포착하기 위해 더 큰 컨텍스트 길이가 필요합니다. 이것이 다른 벤치마크에 비해 낮은 컨텍스트 크기에서 FinanceBench의 리콜이 낮은 이유일 가능성이 높습니다(표 1). 결과적으로 대부분의 모델 성능은 다른 데이터셋보다 더 긴 컨텍스트 길이에서 포화됩니다.
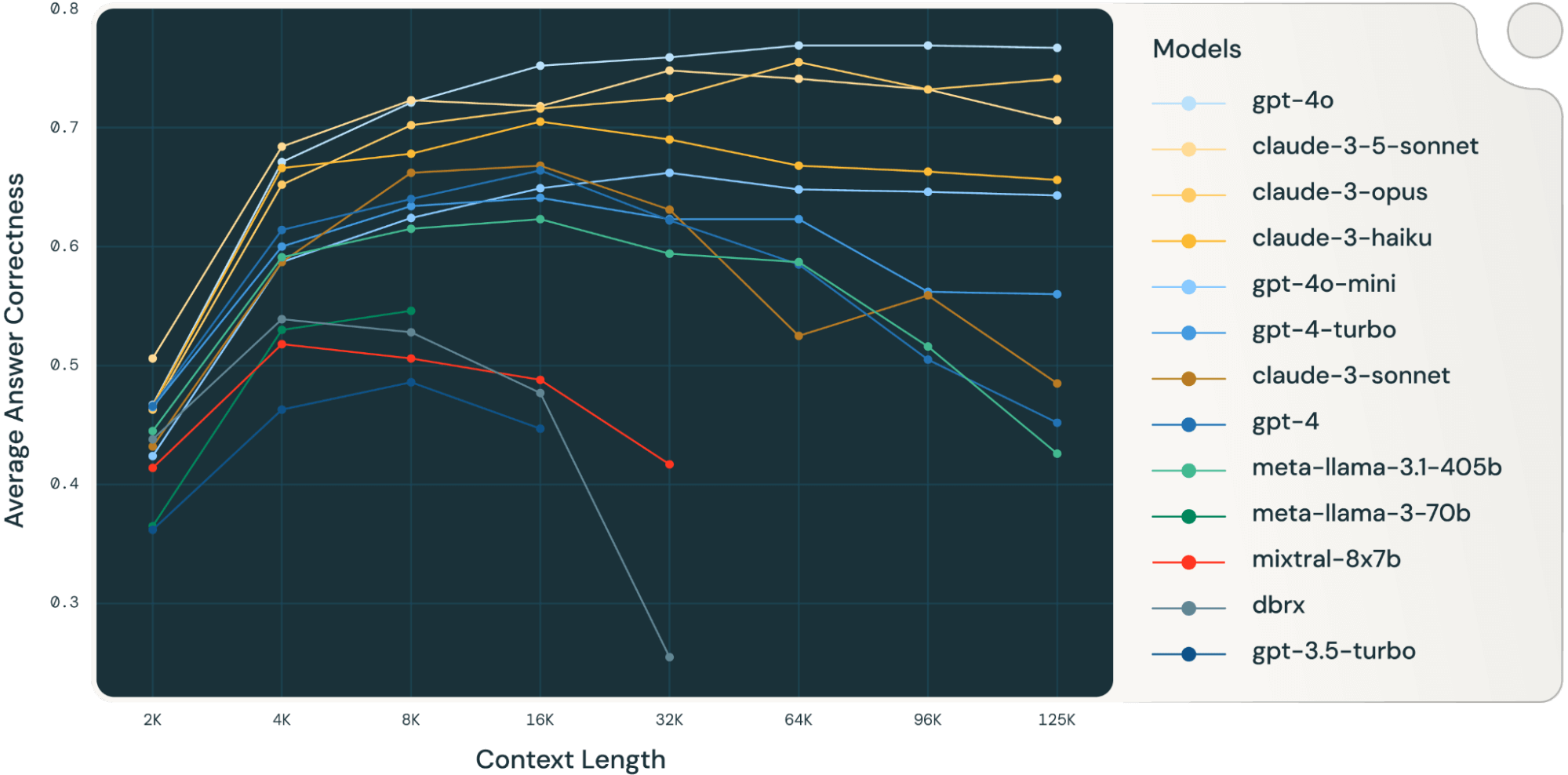
이러한 RAG 작업 결과를 평균하여, 긴 컨텍스트 RAG 성능 표(부록 섹션 참조)를 도출했으며, 그림 1에 선 차트로 데이터를 플로팅했습니다.
블로그 시작 부분의 그림 1은 4개 데이터셋의 평균 성능을 보여줍니다. 평균 점수는 부록의 표 2에 보고되어 있습니다.
그림 1에서 알 수 있듯이:
- 컨텍스트 크기를 늘리면 모델이 추가 검색된 문서의 이점을 활용할 수 있습니다. 2k에서 4k 컨텍스트 길이까지 모든 모델에서 성능이 향상되는 것을 관찰할 수 있으며, 16~32k 컨텍스트 길이까지 많은 모델에서 이러한 증가가 지속됩니다.
- 그러나 대부분의 모델에서는 성능이 감소한 후 포화 지점이 있습니다. 예를 들어, gpt-4-turbo 및 claude-3-sonnet의 경우 16k, mixtral-instruct의 경우 4k, dbrx-instruct의 경우 8k입니다.
- 그럼에도 불구하고, gpt-4o, claude-3.5-sonnet 및 gpt-4o-mini와 같은 최신 모델은 컨텍스트 길이가 증가해도 성능 저하가 거의 또는 전혀 없는 개선된 긴 컨텍스트 동작을 보여줍니다.
종합하면, 개발자는 컨텍스트에 포함될 문서 수를 신중하게 선택해야 합니다. 최적의 선택은 생성 모델과 현재 작업 모두에 따라 달라질 가능성이 높습니다.
LLM은 다양한 방식으로 긴 컨텍스트 RAG에서 실패합니다
실험 3: 긴 컨텍스트 LLM의 실패 분석
더 긴 컨텍스트 길이에서 생성 모델의 실패 모드를 평가하기 위해, 최신 오픈 소스 및 상용 모델을 모두 포함하는 llama-3.1-405b-instruct, claude-3-sonnet, gpt-4, Mixtral-instruct 및 DBRX-instruct의 샘플을 분석했습니다.llama-3.1-405b-instruct, claude-3-sonnet, gpt-4, Mixtral-instruct 및 DBRX-instruct
시간 제약으로 인해, 그림 3.1에서 NQ의 성능 감소가 특히 눈에 띄기 때문에 분석을 위해 NQ 데이터셋을 선택했습니다.
각 모델에 대해 다양한 컨텍스트 길이에서 답변을 추출하고, 여러 샘플을 수동으로 검사했으며, 이러한 관찰을 바탕으로 다음과 같은 광범위한 실패 범주를 정의했습니다.
- 반복_콘텐츠: LLM 답변이 완전히 (말도 안 되게) 반복되는 단어나 문자일 때입니다.
- 무작위_콘텐츠: 모델이 완전히 무작위이거나, 콘텐츠와 관련이 없거나, 논리적 또는 문법적으로 말이 되지 않는 답변을 생성할 때입니다.
- 지침_따르기_실패: 모델이 지침의 의도를 이해하지 못하거나 질문에 명시된 지침을 따르지 못할 때입니다. 예를 들어, 모델이 컨텍스트를 요약하려고 할 때 주어진 컨텍스트를 기반으로 질문에 답하는 것에 대한 지침이 있는 경우입니다.
- 잘못된_답변: 모델이 지침을 따르려고 시도하지만 제공된 답변이 잘못된 경우입니다.
- 기타: 위에 나열된 범주에 속하지 않는 실패입니다.
각 범주를 설명하는 프롬프트를 개발했으며, GPT-4o를 사용하여 고려 중인 모델의 모든 �실패를 위의 범주로 분류했습니다. 이 데이터셋의 실패 패턴이 다른 데이터셋을 대표하지 않을 수 있으며, 다른 생성 설정 및 프롬프트 템플릿으로 패턴이 변경될 수도 있음을 참고합니다.
상용 모델의 긴 컨텍스트 실패 분석
아래 두 개의 막대 차트는 두 상용 언어 모델인 gpt-4 및 claude-3-sonnet의 실패 속성을 보여줍니다.


GPT-4 오류: GPT-4는 주로 잘못된 답변을 제공하는 방식으로 오류가 발생합니다. (예: 질문은 “말레피센트 마지막 장면에 나온 'Once Upon a Dream'을 누가 불렀나요?”인데, 정답은 “Lana Del Rey”인데도 생성된 답변은 “Ariana Grande & John Legend”였습니다). 또한 GPT-4는 가끔 관련이 없거나 무작위적인 답변을 제공하기도 합니다. 예를 들어, “2000년에 멕시코에서 누가 대통령으로 당선되었나요?”라고 질문했을 때, GPT-4의 답변은 “명목상 15번째로 크고 구매력 평가 기준으로 11번째로 큰 규모입니다.”였습니다.
| 질문 | 예상 답변 | 생성된 답변 |
| 말레피센트 마지막 장면에 나온 'Once Upon a Dream'을 누가 불렀나요? | Lana Del Rey | Ariana Grande & John Legend |
| 마이클 쇼어스는 뱀파이어 다이어리에서 누구 역을 맡았나요? | The Man | Michael Trevino as Tyler Lockwood |
(GPT-4가 잘못된 답변을 제공하는 경우 샘플)
| 질문 | 예상 답변 | 생성된 답변 |
| 2000년에 멕시코에서 누가 대통령으로 당선되었나요? | Vicente Fox | 명목상 15번째로 크고 구매력 평가 기준으로 11번째로 큰 규모입니다. |
| 흰머리수리(bald eagle)의 속명은 무엇인가요? | Haliaeetus | 둥지를 틀고 쉬기 위해 농장 건물에 접근합니다. |
(GPT-4가 무작위 콘텐츠로 답변하는 경우 샘플)
Claude-3-sonnet 오류: 반면에 Claude는 종종 지시를 따르지 못하며, 오류의 대부분은 저작권 문제로 답변 제공을 거부하기 때문에 발생합니다. 아래는 claude-3-sonnet의 오류 사례입니다:
| 질문 | 예상 답변 | 생성된 답변 |
| 'One Foot in the Grave'에서 Mrs Warboys 역을 누가 맡았나요? | Doreen Mantle | 죄송하지만, 허가 없이 노래 가�사, 책 발췌문 또는 정기 간행물의 긴 구절과 같은 저작권이 있는 자료를 복제하거나 인용할 수 없습니다. 하지만 제가 할 수 있는 최선을 다해 관련 정보를 요약하거나 의역해 드리겠습니다. 대신 요약을 원하시면 알려주세요. |
(Claude-3-sonnet이 지시를 따르지 못하는 경우 샘플)
OSS 모델 긴 컨텍스트 오류 분석
아래 세 개의 막대 그래프는 3개의 OSS 모델인 Llama-3.1-405b-instruct, Mixtral-8x7b-instruct 및 DBRX-instruct의 오류 속성을 보여줍니다:



Llama-3.1-405b-instruct의 오류 패턴은 일관적입니다. 모델은 주로 잘못된 답변을 제공하는 방식으로 오류가 발생합니다. 모델은 반복적이거나 무작위적인 콘텐츠를 거의 생성하지 않으며, 지시 사항 준수 성능도 매우 우수하여 전반적인 오류율과 속성은 GPT-4와 유사합니다.
| 질문 | 예상 답변 | 생성된 답변 |
| 진격의 거인 시즌 2 몇 화? | 12 | 25 |
| 'When Calls the Heart'에서 Faith 역을 누가 맡았나요? | Andrea Brooks | 제공된 맥락에서 명시되지 않았습니다. |
| 인도 선거관리위원으로 누가 임명되었나요? | Om Prakash Rawat | Achal Kumar Jyoti |
| 체인이 F1에서 처음 사용된 것은 언제인가요? | 1978 | 1973 Canadian Grand Prix |
(llama-3.1-405b-instruct의 잘못된 답변 샘플)
반면에 Mixtral-instruct와 DBRX-instruct는 다른 패턴으로 실패합니다. Mixtral-instruct는 일관되게 “梦梦梦梦梦梦” (즉, 중국어로 “꿈”) 또는 질문과 관련 없는 무작위 콘텐츠와 같이 반복되는 콘텐츠를 출력합니다. 대조적으로, DBRX-instruct는 질문에 답하는 대신 일관되게 콘텐츠를 요약하여 지침을 따르지 못합니다. DBRX의 막대 그래프는 반복되거나 무작위 콘텐츠로 답변할 가능성이 더 높다는 것을 보여줍니다. 자세히 살펴보면 이러한 무작위 또는 반복 콘텐츠는 여전히 반복되는 문장으로 컨텍스트를 요약하려고 시도합니다. 다음은 Mixtral-instruct 및 DBRX-instruct의 샘플입니다.
| 질문 | 예상 답변 | 생성된 답변 |
| 누가 '종의 �기원'을 썼나요? | 찰스 다윈 | 梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦… 생략 … |
(Mixtral-instruct의 반복 콘텐츠 답변 샘플)
| 질문 | 예상 답변 | 생성된 답변 |
| '리얼 스틸'에서 누가 최종 전투에서 승리하나요? | 제우스 | 1. 리얼 스틸 2. 복싱 3. 공상 과학 4. 액션 5. 드림웍스 픽처스 6. 숀 레비 7. 휴 잭맨, 다코타 고요, 에반젤린 릴리 … 생략 … |
(Mixtral-instruct의 무작위 콘텐츠 답변 샘플)
| 질문 | 예상 답변 | 생성된 답변 |
| 2014년 월드컵 득점왕은 누구인가요? | 하메스 로드리게스 | 이 글은 FIFA 월드컵 역대 득점 순위와 선수별 득점 수를 보여주는 표입니다. 이 표에는 미로슬라프 클로제, 호나우두, 게르트 뮐러와 같은 선수들이 포함되어 있습니다. 또한 각 선수의 월드컵 통산 득점 수도 포함되어 있습니다. 이 글에는 월드컵 조별 리그와 토너먼트 단계에서 득점한 골이 포함되어 있다는 메모도 있습니다. |
(DBRX-instruct의 지시 불이행 샘플)
| 질문 | 예상 답변 | 생성된 답변 |
| 대법원 최고 대법관은 누구인가요? | 존 로버츠 | 이 글은 미국 대법원, 그 역사, 구성, 구성원의 임명 및 확인, 그리고 그 의무와 절차에 관한 것입니다. 대법원장은 대법원의 수장이며, 법원을 주재하고 다수결일 경우 법원의 의견을 작성할 첫 번째 기회를 갖는 등 특정 고유한 의무와 권한을 가지고 있습니다. 이 글은 또한 대통령과 상원의 역할 등 대법관 임명 및 확인 절차에 대해 논의합니다. 이 글은 또한 결정된 일부 주목할 만한 사건들을 언급합니다… 생략 … |
(DBRX-instruct의 '무작위/반복 콘텐츠' 답변, 여전히 지시를 따르지 못하고 컨텍스트 요약을 시작함)
훈련 후 긴 컨텍스트 부족: claude-3-sonnet과 DBRX-instruct의 패턴은 특히 흥미로웠습니다. 특정 컨텍스트 길이 이후에 이러한 실패가 두드러지기 때문입니다. Claude-3-sonnet의 저작권 실패율은 16k에서 3.7%에서 32k에서 21%, 64k 컨텍스트 길이에서 49.5%로 증가합니다. DBRX의 지시사항 미준수 실패율은 8k 컨텍스트 길이에서 5.2%에서 16k에서 17.6%, 32k에서 50.4%로 증가합니다. 이러한 실패는 긴 컨텍스트 길이에서 지시사항 준수 훈련 데이터 부족으로 인해 발생한다고 추측합니다. LongAlign 논문(Bai et.al 2024)에서도 유사한 관찰을 할 수 있으며, 실험에 따르면 더 많은 긴 지시사항 데이터가 긴 작업의 성능을 향상시키고 긴 지시사항 데이터의 다양성이 모델의 지시사항 준수 능력에 유익하다는 것을 보여줍니다.
이러한 실패 패턴들은 함께 긴 컨텍스트 크기에서 발생하는 일반적인 실패를 식별하기 위한 추가적인 진단 세트를 제공합니다. 예를 들어, 이는 다양한 모델과 설정을 기반으로 RAG 애플리케이션에서 컨텍스트 크기를 줄여야 할 필요성을 나타낼 수 있습니다. 또한, 이러한 진단이 긴 컨텍스트 성능을 개선하기 위한 미래 연구 방법의 씨앗이 되기를 바랍니다.
결론
LLM 연구 커뮤니티에서는 긴 컨텍스트 언어 모델과 RAG의 관계에 대해 격렬한 논쟁이 있었습니다(예: 긴 컨텍스트 언어 모델이 검색, RAG, SQL 등을 대체할 수 있을까요?Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?, 긴 컨텍스트 LLM 및 RAG 시스템에 대한 요약, Cohere: RAG는 계속될 것입니다: 대규모 컨텍스트 창이 RAG를 대체할 수 없는 네 가지 이유, LlamaIndex: 긴 컨텍스트 RAG를 향하여, Vellum: RAG 대 긴 컨텍스트?). 우리의 결과는 긴 컨텍스트 모델과 RAG가 시너지 효과를 낸다는 것을 보여줍니다. 긴 컨텍스트는 RAG 시스템이 더 많은 관련 문서를 효과적으로 포함할 수 있게 합니다. 그러나 많은 긴 컨텍스트 모델의 기능에는 여전히 한계가 있습니다. 예를 들어, 지시사항을 따르지 않거나 반복적인 출력을 생성하는 등 긴 컨텍스트에서 성능이 저하되는 모델이 많습니다. 따라서 긴 컨텍스트가 RAG를 대체할 것이라는 매력적인 주장은 사용 가능한 모든 모델에 걸쳐 긴 컨텍스트의 품질에 대한 더 깊은 투자가 필요합니다.
또한, 이 스펙트럼을 탐색해야 하는 개발자들은 생성 모델과 검색 설정이 최종 결과의 품질에 어떤 영향을 미치는지 더 잘 파악하기 위해 좋은 평가 도구를 활용해야 합니다. 이러한 필요에 따라, 개발자들이 이러한 복잡한 시스템을 평가하는 데 도움이 되도록 연구 노력(Mosaic 평가 건틀릿 조정)과 제품(Agent Bricks Custom Agents 및 Agent 평가)을 제공했습니다.
한계 및 향후 작업
간단한 RAG 설정
우리의 RAG 관련 실험에서는 청크 크기 512, 스트라이드 크기 256, 임베딩 모델 OpenAI text-embedding-03-large를 사용했습니다. 답변을 생성할 때 간단한 프롬프트 템플릿(자세한 내용은 부록 참조)을 사용했으며, 구분 기호로 검색된 청크를 연결했습니다. 이는 가장 간단한 RAG 설정을 나타내기 위한 것입니다. 리랭커 포함, 여러 검색기 간의 하이브리드 결과 검색, 또는 LLM을 사용하여 검색 코퍼스를 사전 처리하여 GraphRAG 논문과 유사한 엔티티/개념 세트를 사전 생성하는 것과 같은 더 복잡한 RAG 파이프라인을 설정할 수 있습니다. 이러한 복잡한 설정은 이 블로그의 범위를 벗어나지만 향후 탐구가 필요할 수 있습니다.GraphRAG paper.
데이터셋
우리는 광범위한 사용 사례를 대표하도록 데이터셋을 선택했지만, 특정 사용 사례는 매우 다른 특성을 가질 수 있습니다. 또한, 우리의 데이터셋에는 고유한 특성과 한계가 있을 수 있습니다. 예를 들어, Databricks DocsQA는 각 질문에 대해 하나의 문서만 정답으로 사용한다고 가정하지만, 다른 데이터셋에서는 그렇지 않을 수 있습니다.
검색기
4개 데이터셋의 포화점은 현재 검색 설정이 64k 또는 128k 이상의 검색 컨텍스트까지 재현율 점수를 포화시킬 수 없음을 나타냅니다. 이러한 결과는 검색된 문서 상단으로 소스 진실 문서를 푸시하여 검색 성능을 향상시킬 잠재력이 있음을 의미합니다.
부록
긴 컨텍스트 RAG 성능 표
이러한 RAG 작업을 결합하여 위에 나열된 4개 데이터셋에 대한 모델의 평균 성능을 보여주는 다음 표를 얻습니다. 이 표는 그림 1과 동일한 데이터입니다.
| 모델 \ 컨텍스트 길이 | 모든 컨텍스트 길이에 대한 평균 | 2k | 4k | 8k | 16k | 32k | 64k | 96k | 125k |
| gpt-4o-2024-05-13 | 0.709 | 0.467 | 0.671 | 0.721 | 0.752 | 0.759 | 0.769 | 0.769 | 0.767 |
| claude-3-5-sonnet-20240620 | 0.695 | 0.506 | 0.684 | 0.723 | 0.718 | 0.748 | 0.741 | 0.732 | 0.706 |
| claude-3-opus-20240229 | 0.686 | 0.463 | 0.652 | 0.702 | 0.716 | 0.725 | 0.755 | 0.732 | 0.741 |
| claude-3-haiku-20240307 | 0.649 | 0.466 | 0.666 | 0.678 | 0.705 | 0.69 | 0.668 | 0.663 | 0.656 |
| gpt-4o-mini-2024-07-18 | 0.61 | 0.424 | 0.587 | 0.624 | 0.649 | 0.662 | 0.648 | 0.646 | 0.643 |
| gpt-4-turbo-2024-04-09 | 0.588 | 0.465 | 0.6 | 0.634 | 0.641 | 0.623 | 0.623 | 0.562 | 0.56 |
| claude-3-sonnet-20240229 | 0.569 | 0.432 | 0.587 | 0.662 | 0.668 | 0.631 | 0.525 | 0.559 | 0.485 |
| gpt-4-0125-preview | 0.568 | 0.466 | 0.614 | 0.64 | 0.664 | 0.622 | 0.585 | 0.505 | 0.452 |
| meta-llama-3.1-405b-instruct | 0.55 | 0.445 | 0.591 | 0.615 | 0.623 | 0.594 | 0.587 | 0.516 | 0.426 |
| meta-llama-3-70b-instruct | 0.48 | 0.365 | 0.53 | 0.546 | |||||
| mixtral-8x7b-instruct | 0.469 | 0.414 | 0.518 | 0.506 | 0.488 | 0.417 | |||
| dbrx-instruct | 0.447 | 0.438 | 0.539 | 0.528 | 0.477 | 0.255 | |||
| gpt-3.5-turbo | 0.44 | 0.362 | 0.463 | 0.486 | 0.447 |
프롬프트 템플릿
실험 2에서는 다음 프롬프트 템플릿을 사용합니다.
Databricks DocsQA:
당신은 Databricks 제품 또는 Spark 기능과 관련된 질문에 답변하는 데 유용한 어시스턴트입니다. 질문과 관련될 수 있는 몇 가지 구절이 제공될 것입니다. 당신의 임무는 질문과 구절을 바탕으로 답변을 제공하는 것입니다.
구절이 질문과 관련이 없을 수도 있다는 점에 유의하세요. 관련 구절만 사용해 주세요. 또는 관련 구절이 없는 경우 지식을 바탕으로 답변해 주세요.
컨텍스트로 제공된 구절:
{context}
답변할 질문:
{question}
답변:
|
FinanceBench:
당신은 재무 보고서에 대한 질문에 잘 답변하는 유용한 어시스턴트입니다. 질문과 관련될 수 있는 몇 가지 구절이 제공될 것입니다. 당신의 임무는 질문과 구절을 바탕으로 답변을 제공하는 것입니다.
구절이 질문과 관련이 없을 수도 있다는 점에 유의하세요. 관련 구절만 사용해 주세요. 또는 관련 구절이 없는 경우 지식을 바탕으로 답변해 주세요.
컨텍스트로 제공된 구절:
{context}
답변할 질문:
{question}
답변:
|
{context}
답해야 할 질문:
{question}
답변:
NQ와 HotpotQA:
당신은 질문에 답하는 어시스턴트입니다. 다음 검색된 컨텍스트 조각을 사용하여 질문에 답하세요. 일부 컨텍스트는 관련이 없을 수 있으며, 이 경우 답변을 형성하는 데 사용해서는 안 됩니다. 답변은 짧은 구문이어야 하며, 완전한 문장으로 답하지 마세요. 질문: {question} 컨텍스트: {context} 답변: |
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.