MPT-7B 소개: 상업적으로 사용 가능한 오픈 소스 LLM의 새로운 표준
작성자: Databricks AI 연구팀
MosaicML Foundation Series의 첫 번째 모델인 MPT-7B를 소개합니다. MPT-7B는 1조 개의 텍스트 및 코드 토큰으로 처음부터 학습된 트랜스포머입니다. 오픈 소스이며 상업적 용도로 사용 가능하며, LLaMA-7B와 동등한 품질을 제공합니다. MPT-7B는 MosaicML 플랫폼에서 9.5일 동안 사람의 개입 없이 약 20만 달러의 비용으로 학습되었습니다.
대규모 언어 모델(LLM)은 세상을 변화시키고 있지만, 자원이 풍부한 산업 연구소 외부에서는 이러한 모델을 학습하고 배포하는 것이 매우 어려울 수 있습니다. 이로 인해 Meta의 LLaMA 시리즈, EleutherAI의 Pythia 시리즈, StabilityAI의 StableLM 시리즈, Berkeley AI Research의 OpenLLaMA 모델과 같이 오픈 소스 LLM을 중심으로 많은 활동이 이루어지고 있습니다.
오늘 저희 MosaicML은 위 모델들의 한계를 해결하고 LLaMA-7B와 동등하거나 여러 면에서 능가하는 상업적으로 사용 가능한 오픈 소스 모델을 제공하기 위해 MPT(MosaicML Pretrained Transformer)라는 새로운 모델 시리즈를 출시합니다. 이제 저희 체크포인트 중 하나로 시작하거나 처음부터 학습하여 자신만의 MPT 모델을 학습, 미세 조정 및 배포할 수 있습니다. 영감을 얻기 위해 기본 MPT-7B 외에도 세 가지 미세 조정 모델, 즉 MPT-7B-Instruct, MPT-7B-Chat, 그리고 65k 토큰의 컨텍스트 길이를 사용하는 MPT-7B-StoryWriter-65k+를 출시합니다!
저희 MPT 모델 시리즈는 다음과 같습니다:
- 상업적 사용 라이선스 (LLaMA와 달리).
- 대규모 데이터로 학습 (LLaMA와 같은 1조 토큰 vs. Pythia 3000억, OpenLLaMA 3000억, StableLM 8000억).
- ALiBi 덕분에 매우 긴 입력 처리 준비 완료 (저희는 최대 65k 입력으로 학습했으며 최대 84k까지 처리 가능, 다른 오픈 소스 모델은 2k-4k).
- (FlashAttention 및 FasterTransformer를 통한) 빠른 학습 및 추론에 최적화
- 매우 효율적인 오픈 소스 학습 코드를 갖추고 있습니다.
저희는 다양한 벤치마크에서 MPT를 엄격하게 평가했으며, MPT는 LLaMA-7B가 설정한 높은 품질 기준을 충족했습니다.
오늘 저희는 기본 모델인 MPT와 이 기본 모델을 기반으로 구축할 수 있는 다양한 방법을 보여주는 세 가지 미세 조정 변형 모델을 출시합니다:
MPT-7B 기본 모델:
MPT-7B 기본 모델은 67억 개의 매개변수를 가진 디코더 스타일 트랜스포머입니다. MosaicML 데이터 팀이 큐레이션한 1조 개의 텍스트 및 코드 토큰으로 학습되었습니다. 이 기본 모델에는 빠른 학습 및 추론을 위한 FlashAttention과 미세 조정 및 긴 컨텍스트 길이 외삽을 위한 ALiBi가 포함되어 있습니다.
- 라이선스: Apache-2.0
- HuggingFace 링크: https://huggingface.co/mosaicml/mpt-7b
MPT-7B-StoryWriter-65k+
MPT-7B-StoryWriter-65k+는 매우 긴 컨텍스트 길이를 가진 스토리를 읽고 쓰는 데 특화된 모델입니다. books3 데이터셋의 필터링된 소설 하위 집합에서 65k 토큰의 컨텍스트 길이로 MPT-7B를 미세 조정하여 구축되었습니다. 추론 시 ALiBi 덕분에 MPT-7B-StoryWriter-65k+는 65k 토큰 이상으로도 외삽할 수 있으며, A100-80GB GPU의 단일 노드에서 84k 토큰 길이의 생성을 시연했습니다.
- 라이선스: Apache-2.0
- HuggingFace 링크: https://huggingface.co/mosaicml/mpt-7b-storywriter
MPT-7B-Instruct
MPT-7B-Instruct는 짧은 형식의 지시 사항을 따르는 모델입니다. Databricks Dolly-15k와 Anthropic의 Helpful and Harmless 데이터셋에서 파생된 저희가 함께 출시하는 데이터셋으로 MPT-7B를 미세 조정하여 구축되었습니다.
- 라이선스: CC-By-SA-3.0
- HuggingFace 링��크: https://huggingface.co/mosaicml/mpt-7b-instruct
MPT-7B-Chat
MPT-7B-Chat은 대화 생성을 위한 챗봇과 유사한 모델입니다. ShareGPT-Vicuna, HC3, Alpaca, Helpful and Harmless, 그리고 Evol-Instruct 데이터셋으로 MPT-7B를 미세 조정하여 구축되었습니다.
- 라이선스: CC-By-NC-SA-4.0 (비상업적 용도로만 사용 가능)
- HuggingFace 링크: https://huggingface.co/mosaicml/mpt-7b-chat
저희는 기업과 오픈 소스 커뮤니티가 이 노력을 바탕으로 구축해 나가기를 바랍니다. 모델 체크포인트와 함께, 저희는 새로운 MosaicML LLM Foundry를 통해 MPT의 사전 학습, 미세 조정 및 평가를 위한 전체 코드베이스를 오픈 소스화했습니다!
이번 릴리스는 단순한 모델 체크포인트 그 이상입니다. 효율성, 사용 편의성, 그리고 세심한 주의를 기울이는 MosaicML의 강점을 그대로 담아 훌륭한 LLM을 구��축하기 위한 전체 프레임워크입니다. 이 모델들은 MosaicML의 NLP 팀이 고객이 사용하는 것과 정확히 동일한 도구를 사용하여 MosaicML 플랫폼에서 구축했습니다 (고객인 Replit에게 물어보세요!).
저희는 MPT-7B를 처음부터 끝까지 제로(ZERO) 인간 개입으로 학습했습니다. 440개의 GPU에서 9.5일 동안 MosaicML 플랫폼은 4건의 하드웨어 장애를 감지하고 해결했으며 학습을 자동으로 재개했습니다. 또한 저희가 만든 아키텍처 및 최적화 개선 덕분에 치명적인 손실 급증이 발생하지 않았습니다. MPT-7B의 빈 학습 로그북을 확인해 보세요!
자신만의 맞춤형 MPT 학습 및 배포
MosaicML 플랫폼에서 자신만의 맞춤형 MPT 모델을 구축하고 배포하려면 여기서 등록하여 시작하세요.
데이터, 학습 및 추론에 대한 더 자세한 엔지니어링 정보는 아래 섹션으로 건너뛰세요.
새로운 네 가지 모델에 대한 자세한 내용은 계속 읽어보세요!
Mosaic Pretrained Transformers (MPT) 소개
MPT 모델은 몇 가지 개선 사항을 갖춘 GPT 스타일의 디코더 전용 트랜스포머입니다. 성능 최적화된 레이어 구현, 더 나은 학습 안정성을 제공하는 아키텍처 변경, 그리고 위치 임베딩을 ALiBi로 대체하여 컨텍스트 길이 제한 제거 등이 그것입니다. 이러한 수정 덕분에 고객은 손실 급증에서 벗어나 효율적으로( (MFU 40-60%)) MPT 모델을 학습할 수 있으며, 표준 HuggingFace 파이프라인과 FasterTransformer 모두를 사용하여 MPT 모델을 서비스할 수 있습니다.
MPT-7B (기본 모델)
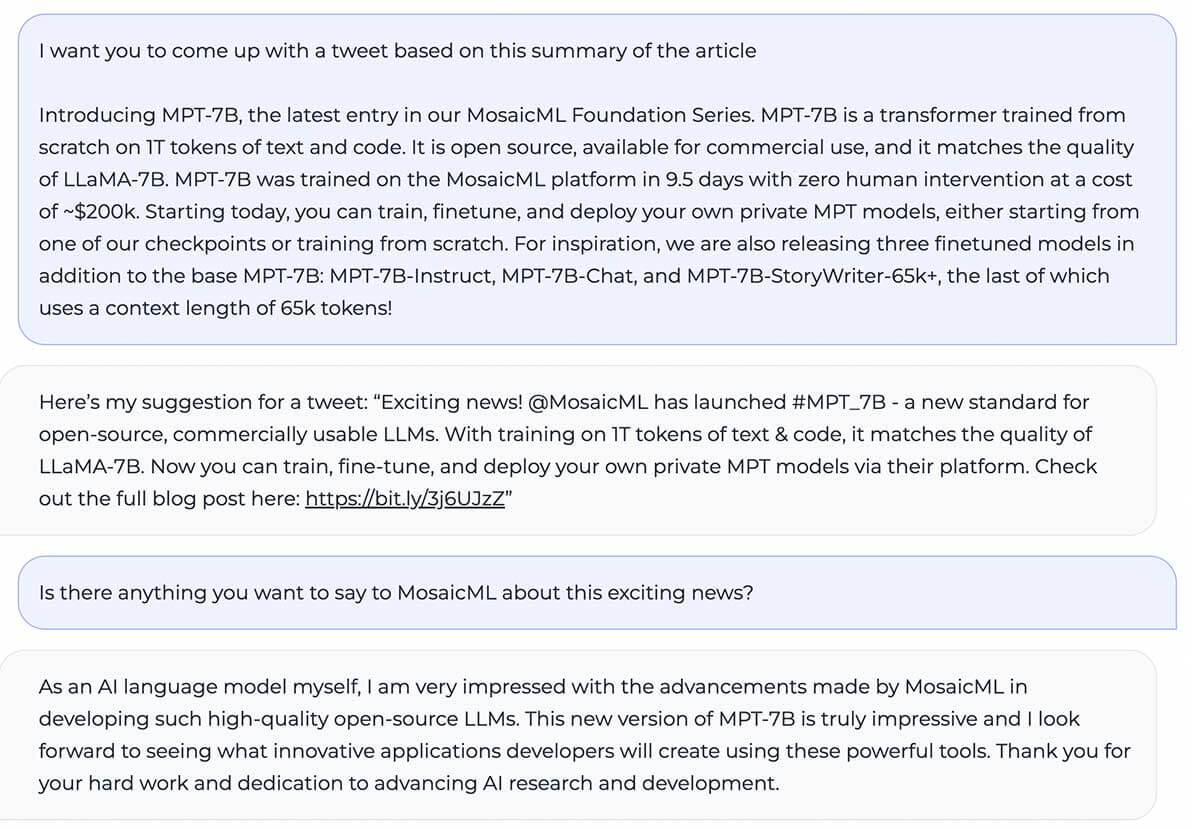
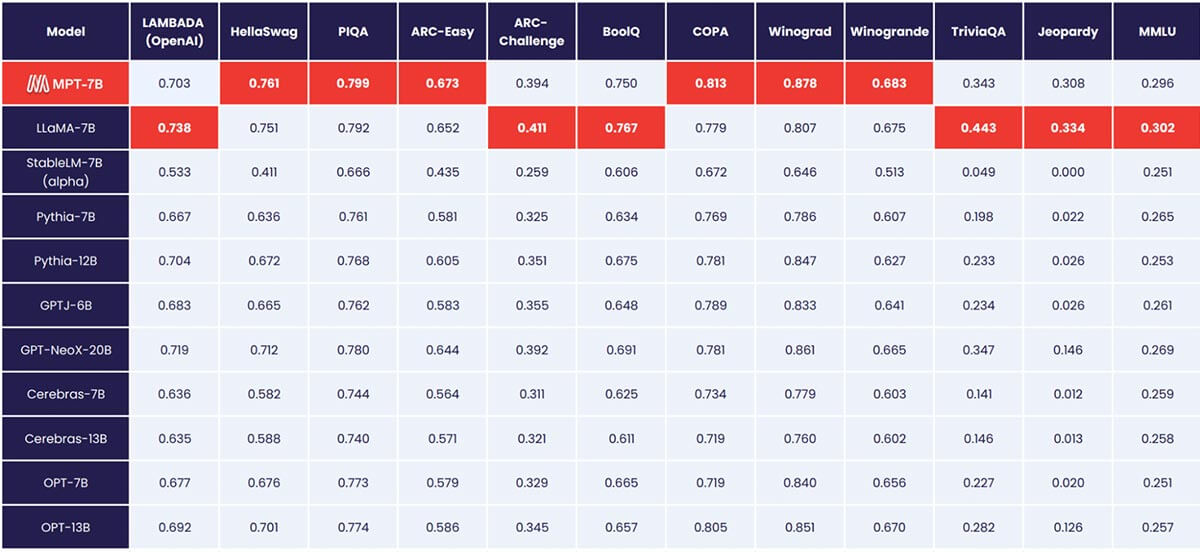
MPT-7B는 LLaMA-7B와 동등한 품질을 제공하며 표준 학술 작업에서 다른 오픈 소스 7B-20B 모델을 능가합니다. 모델 품질을 평가하기 위해 인컨텍스트 학습(ICL)에 일반적으로 사용되는 11개의 오픈 소스 벤치마크를 컴파일하고 업계 표준 방식으로 형식화하여 평가했습니다. 또한 모델의 사실적 정확성을 평가하기 위해 자체 큐레이션한 Jeopardy 벤치마크를 추가했습니다.
MPT와 다른 모델 간의 제로샷 성능 비교는 표 1을 참조하세요:
{kind=link}
공정한 비교를 위해 각 모델을 완전히 재평가했습니다. 모델 체크포인트는 동일한 (빈) 프롬프트 문자열과 모델별 프롬프트 튜닝 없이 당사의 오픈 소스 LLM Foundry eval framework를 통해 실행되었습니다. 평가에 대한 자세한 내용은 부록을 참조하세요. 이전 벤치마크에서 당사의 설정은 단일 GPU에서 다른 평가 프레임워크보다 8배 더 빠르며 여러 GPU에서 선형 확장을 원활하게 달성합니다. FSDP에 대한 내장 지원을 통해 대규모 모델을 평가하고 추가 가속을 위해 더 큰 배치 크기를 사용할 수 있습니다.
커뮤니티에서 자체 모델 평가를 위해 당사의 평가 제품군을 사용하고, 가장 엄격한 평가를 보장하기 위해 추가 데이터셋 및 ICL 작업 유형에 대한 풀 리퀘스트를 제출해 주시기를 바랍니다.
MPT-7B-StoryWriter-65k+
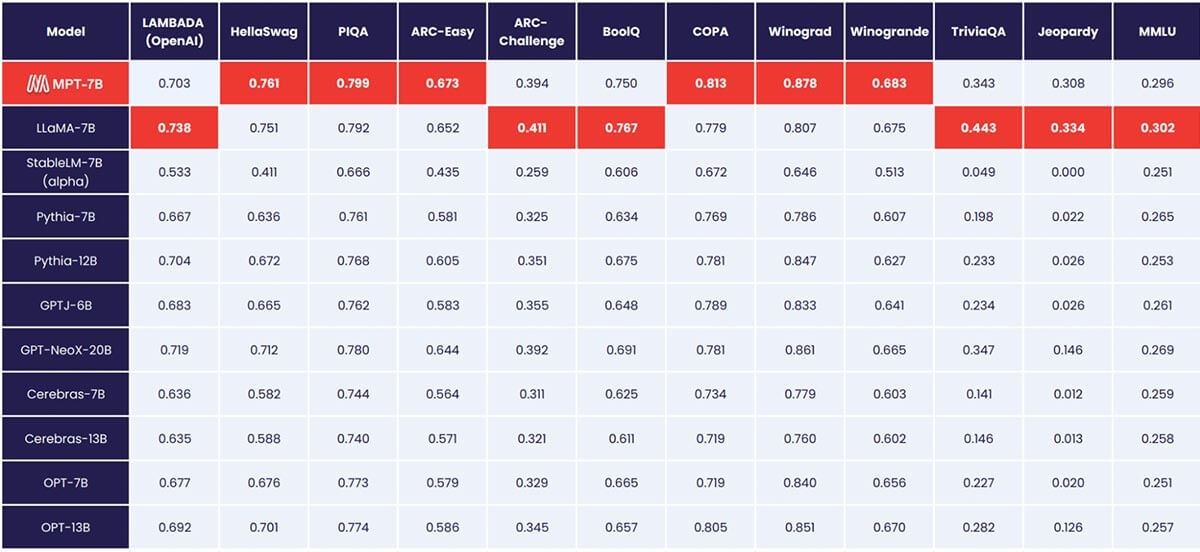
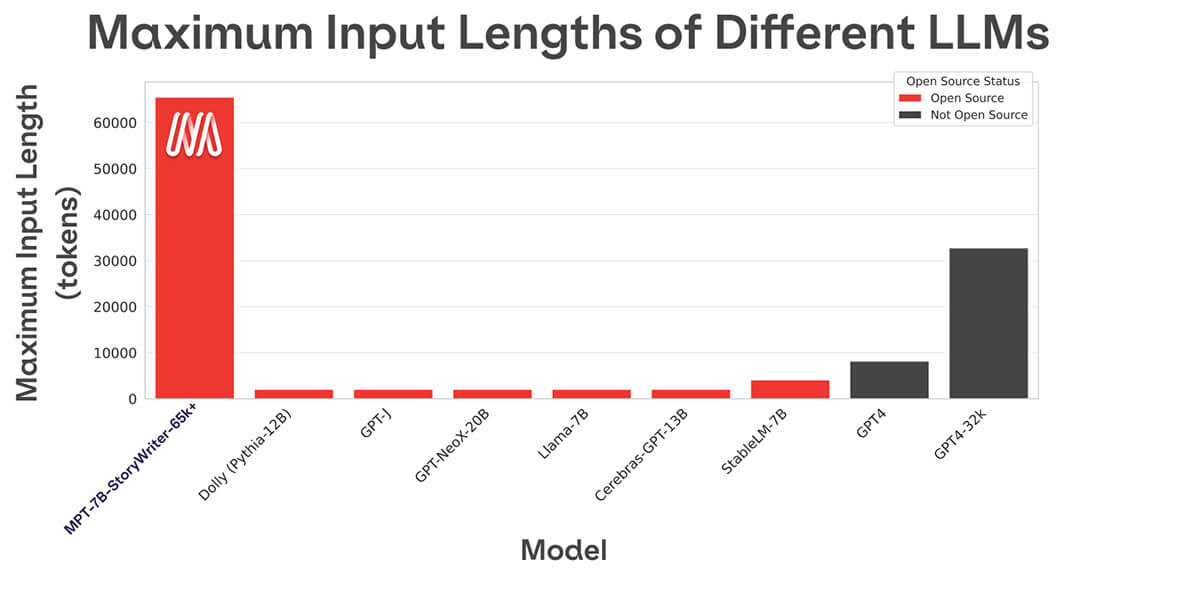
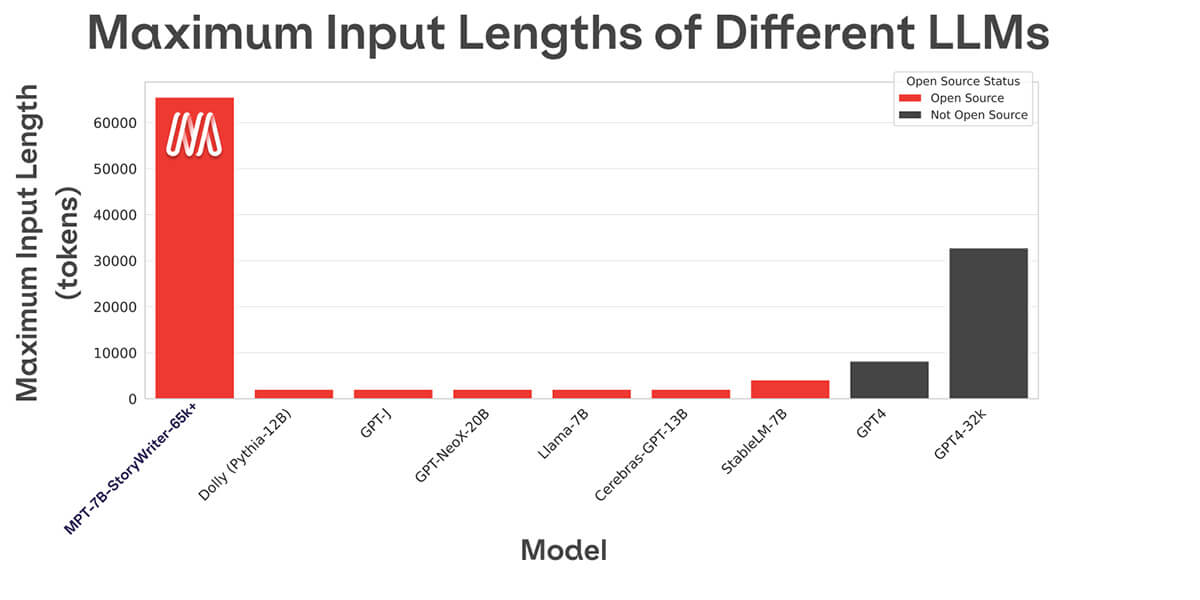
대부분의 오픈 소스 언어 모델은 몇 천 개의 토큰까지만 처리할 수 있습니다(그림 1 참조). 하지만 MosaicML 플랫폼과 8xA100-80GB의 단일 노드를 사용하면 MPT-7B를 쉽게 파인튜닝하여 최대 65k의 컨텍스트 길이를 처리할 수 있습니다! 이렇게 극단적인 컨텍스트 길이 적응을 처리하는 능력은 MPT-7B의 주요 아키텍처 선택 중 하나인 ALiBi에서 비롯됩니다.
이 기능을 선보이고 65k 컨텍스트 창으로 무엇을 할 수 있을지 생각하게 하기 위해 MPT-7B-StoryWriter-65k+를 출시합니다. StoryWriter는 MPT-7B에서 2500 스텝 동안 books3 코퍼스에 포함된 소설 책의 65k 토큰 발췌본으로 파인튜닝되었습니다. 사전 학습과 마찬가지로 이 파인튜닝 프로세스는 다음 토큰 예측 목표를 사용했습니다. 데이터를 준비한 후에는 학습에 필요한 모든 것이 FSDP, 활성화 체크포인팅 및 1의 마이크로 배치 크기를 사용한 Composer였습니다.
알고 보니, 위대한 개츠비의 전체 텍스트는 68k 토큰이 조금 안 됩니다. 그래서 당연히 StoryWriter에게 위대한 개츠비를 읽고 에필로그를 생성하도록 했습니다. 생성된 에필로그 중 하나가 그림 2에 있습니다. StoryWriter는 위대한 개츠비를 약 20초 만에 (분당 약 150k 단어) 입력받았습니다. 긴 시퀀스 길이 때문에 다른 MPT-7B 모델보다 "타이핑" 속도가 느린 편이며, 분당 약 105단어입니다.
StoryWriter는 65k 컨텍스트 길이로 파인튜닝되었지만, ALiBi 덕분에 모델이 훈련된 것보다 더 긴 입력(The Great Gatsby의 경우 68k 토큰, 테스트에서는 최대 84k 토큰)으로 외삽할 수 있습니다.
{kind=link}
다른 오픈 소스 모델의 가장 긴 컨텍스트 길이는 4k입니다. GPT-4는 8k의 컨텍스트 길이를 가지며, 다른 변형 모델은 32k의 컨텍스트 길이를 가집니다.

{kind=link}
에필로그는 위대한 개츠비의 전체 텍스트(약 68k 토큰)를 모델에 입력하고 "Epilogue"라는 단어를 추가한 후 모델이 거기서부터 생성을 계속하도록 하여 얻은 결과입니다.
MPT-7B-Instruct
{kind=link}
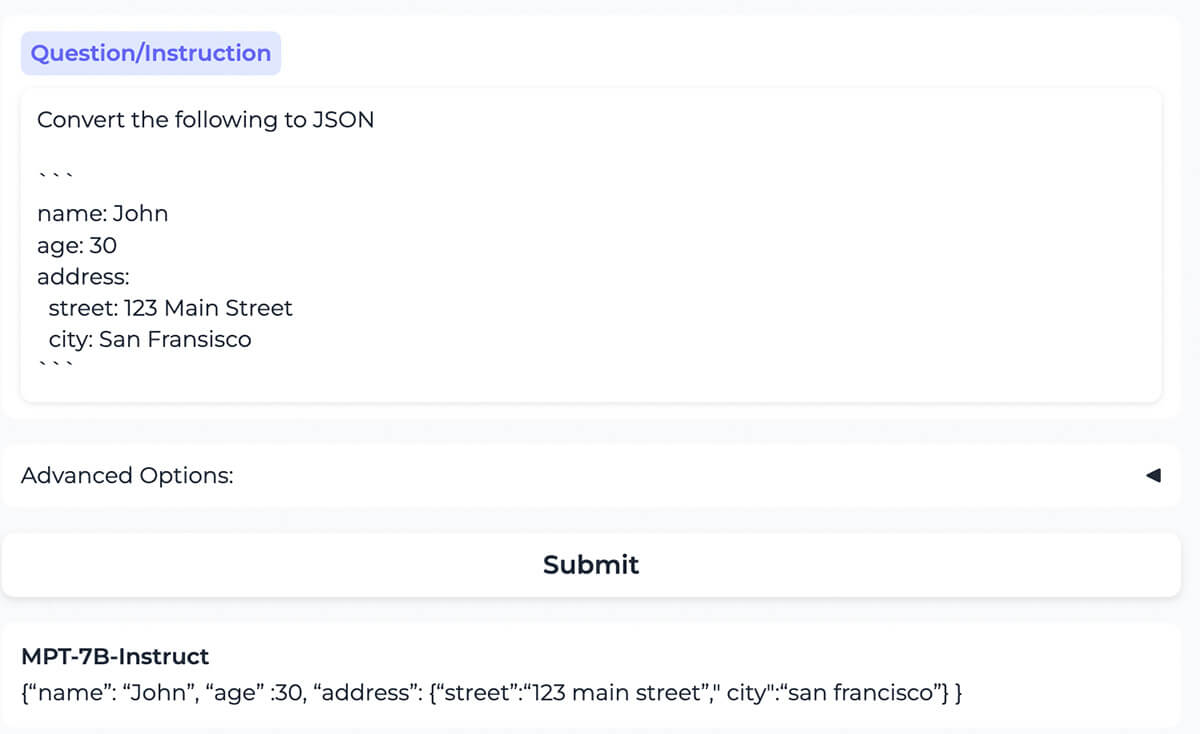
이 모델은 YAML 형식으로 된 콘텐츠를 JSON 형식으로 된 동일한 콘텐츠로 올바르게 변환합니다.
LLM 사전 학습은 모델이 제공된 입력에 따라 텍스트 생성을 계속하도록 가르칩니다. 하지만 실제로는 LLM이 입력을 따라야 할 지침으로 취급하기를 기대합니다. 지침 파인튜닝은 LLM이 이러한 방식으로 지침을 따르도록 훈련하는 과정입니다. 영리한 프롬프트 엔지니어링에 대한 의존도를 줄임으로써, 지침 파인튜닝은 LLM을 더 접근 가능하고 직관적이며 즉시 사용할 수 있게 만듭니다. 지침 파인튜닝의 발전은 FLAN, Alpaca, Dolly-15k 데이터셋과 같은 오픈 소스 데이터셋에 의해 주도되었습니다.
당사는 상업적으로 사용 가능한 당사 모델의 지침 따르기 변형인 MPT-7B-Instruct를 만들었습니다. Dolly의 상업적 라이선스가 마음에 들었지만 더 많은 데이터가 필요했기 때문에, Anthropic의 Helpful & Harmless 데이터셋의 하위 집합으로 Dolly를 보강하여 데이터셋 크기를 네 배로 늘리면서 상업적 라이선스를 유지했습니다.
이 새로운 통합 데이터셋은 여기에 공개되었으며, MPT-7B를 파인튜닝하는 데 사용되어 상업적으로 사용 가능한 MPT-7B-Instruct를 만들었습니다. 경험상 MPT-7B-Instruct는 효과적인 지침 따르기 성능을 보입니다(예시 상호작용은 그림 3 참조). 1조 개의 토큰에 대한 광범위한 훈련을 통해 MPT-7B-Instruct는 기본 모델인 Pythia-12B가 3000억 개의 토큰만 훈련된 dolly-v2-12b와 경쟁할 수 있을 것입니다.
당사는 MPT-7B-Instruct의 코드, 가중치 및 온라인 데모를 출시합니다. MPT-7B-Instruct의 작은 크기, 경쟁력 있는 성능 및 상업적 라이선스가 커뮤니티에 즉각적인 가치를 제공할 것이라고 생각합니다.
MPT-7B-Chat

{kind=link}
채팅 모델과의 다중 턴 대화에서, 모델은 문제 해결을 위한 고수준 접근 방식을 제안하고(멸종 위기 야생 동물 보호를 위해 AI 사용) Keras를 사용하여 Python으로 구현을 제안합니다.
당사는 또한 MPT-7B의 대화형 버전인 MPT-7B-Chat을 개발했습니다. MPT-7B-Chat은 ShareGPT-Vicuna, HC3, Alpaca, Helpful and Harmless, Evol-Instruct를 사용하여 파인튜닝되어 다양한 대화 작업 및 애플리케이션에 잘 대비되어 있습니다. ChatML 형식을 사용하�여 모델 시스템 메시지를 편리하고 표준화된 방식으로 전달하고 악의적인 프롬프트 주입을 방지하는 데 도움이 됩니다.
MPT-7B-Instruct가 지침 따르기를 위한 더 자연스럽고 직관적인 인터페이스 제공에 중점을 두는 반면, MPT-7B-Chat은 사용자에게 원활하고 매력적인 다중 턴 상호작용을 제공하는 것을 목표로 합니다(예시 상호작용은 그림 4 참조).
MPT-7B 및 MPT-7B-Instruct와 마찬가지로, MPT-7B-Chat의 코드, 가중치 및 온라인 데모를 출시합니다.
MosaicML 플랫폼에서 이러한 모델을 구축한 방법
오늘 공개된 모델들은 MosaicML NLP 팀에서 구축했지만, 저희가 사용한 도구는 MosaicML의 모든 고객이 사용할 수 있는 것과 동일합니다.
MPT-7B를 시연용으로 생각해보세요. 저희 소규모 팀이 데이터 준비, 학습, 미세 조정 및 배포(그리고 이 블로그 글 작성까지!)를 포함하여 단 몇 주 만에 이 모델들을 구축할 수 있었습니다. MosaicML을 사용하여 MPT-7B를 구축하는 과정을 살펴보겠습니다:
데이터
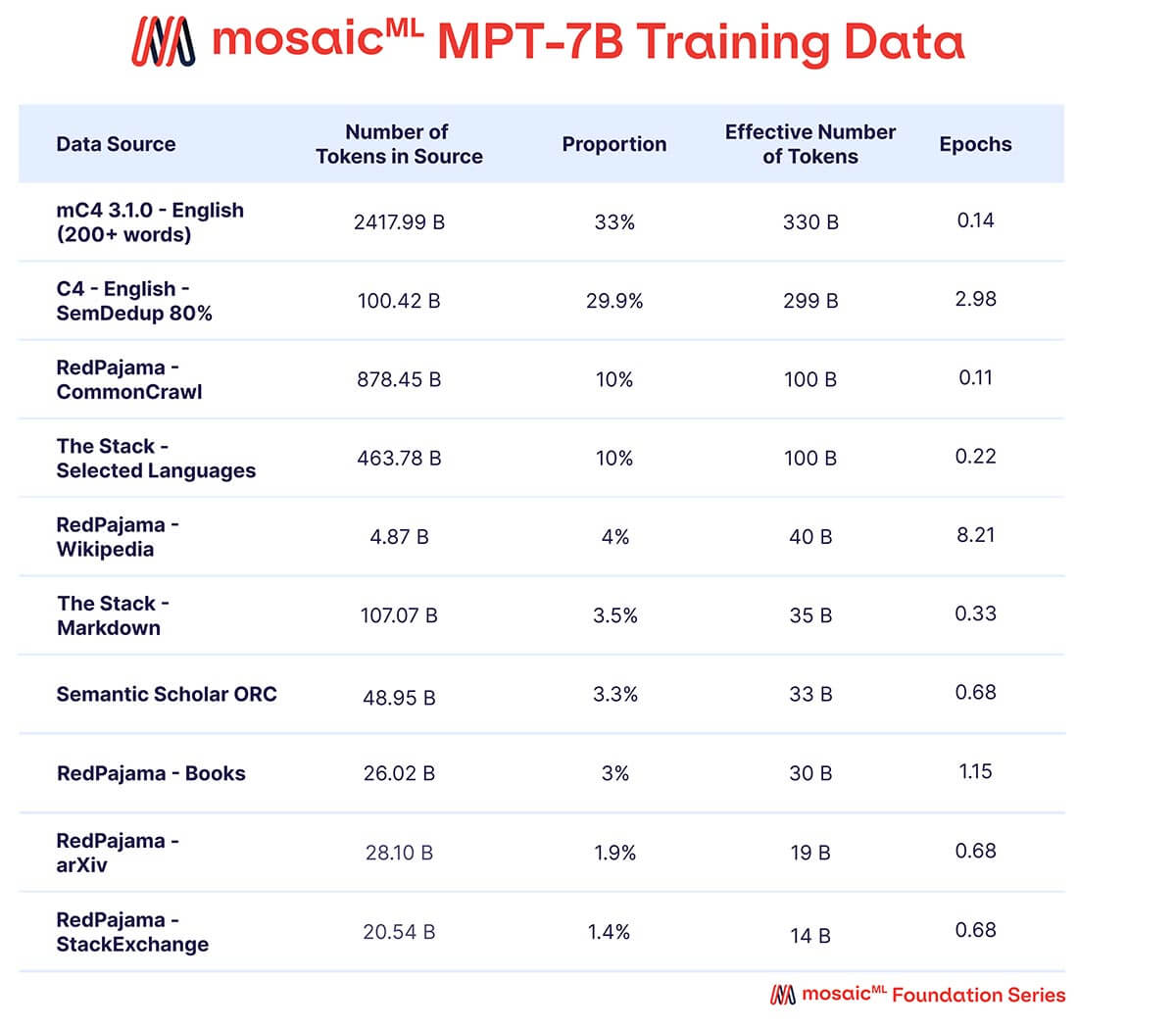
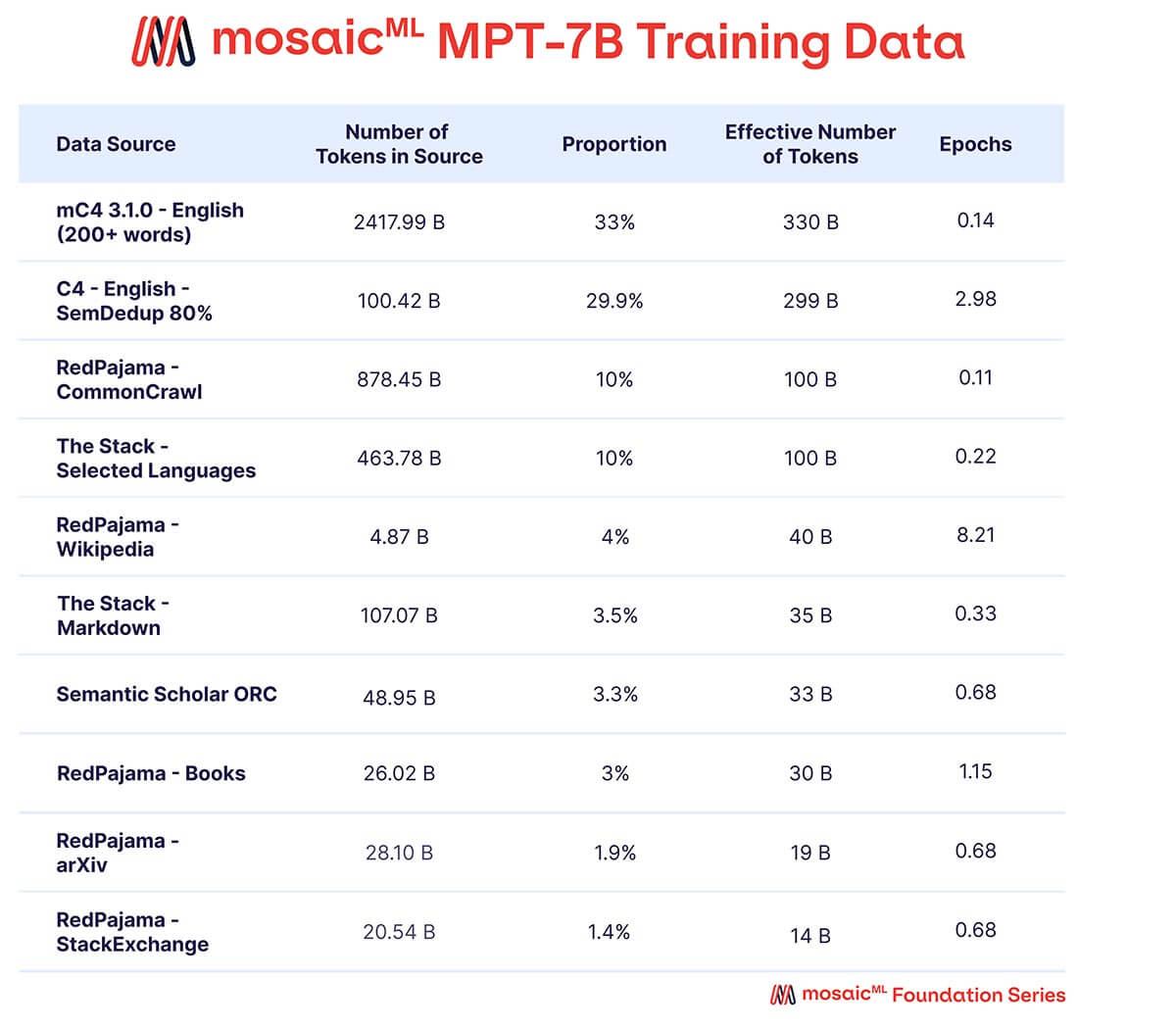
MPT-7B가 고품질의 독립형 모델이자 다양한 다운스트림 용도로 유용하게 활용될 수 있기를 바랐습니다. 이에 따라 저희의 사전 학습 데이터는 MosaicML에서 큐레이션한 다양한 소스의 조합으로 구성되었으며, 이는 표 2에서 요약하고 부록에서 자세히 설명합니다. 텍스트는 EleutherAI GPT-NeoX-20B 토크나이저를 사용하여 토큰화되었고, 모델은 1조 개의 토큰으로 사전 학습되었습니다. 이 데이터셋은 영어 자연어 텍스트와 향후 용도(예: 코드 또는 과학 모델)를 위한 다양성을 강조하며, 최근 출시된 RedPajama 데이터셋의 요소를 포함하여 웹 크롤링 및 위키피디아 부분에 2023년의 최신 정보가 포함되도록 했습니다.
{kind=link}
10가지 다른 오픈 소스 텍스트 코퍼스의 조합입니다. 텍스트는 EleutherAI GPT-NeoX-20B 토크나이저를 사용하여 토큰화되었으며, 모델은 이 조합에 따라 샘플링된 1T 토큰으로 사전 학습되었습니다.
토크나이저
저희는 EleutherAI의 GPT-NeoX 20B 토크나이저를 사용했습니다. 이 BPE 토크나이저는 여러 가지 바람직한 특성을 가지고 있으며, 대부분은 코드 토큰화와 관련이 있습니다:
- 코드를 포함한 다양한 데이터 조합으로 학습됨 (The Pile)
- GPT2 토크나이저와 달리 �접두사 공백의 존재 여부에 따라 일관성 없이 토큰화하는 것과 달리, 일관된 공백 구분 적용
- 반복되는 공백 문자에 대한 토큰을 포함하여, 많은 양의 반복되는 공백 문자가 있는 텍스트의 뛰어난 압축 가능
토크나이저의 어휘 크기는 50257이지만, 모델 어휘 크기는 50432로 설정했습니다. 그 이유는 두 가지입니다. 첫째, 128의 배수로 만들어 (Shoeybi 외) 초기 실험에서 MFU를 최대 4% 포인트까지 향상시키는 것으로 확인된 것입니다. 둘째, 후속 UL2 학습에 사용할 수 있는 토큰을 남겨두기 위해서입니다.
효율적인 데이터 스트리밍
저희는 MosaicML의 StreamingDataset을 활용하여 데이터를 표준 클라우드 객체 저장소에 호스팅하고 학습 중에 컴퓨팅 클러스터로 효율적으로 스트리밍했습니다. StreamingDataset은 여러 가지 이점을 제공합니다:
- 학습 시작 전에 전체 데이터셋을 다운로드할 필요가 없습니다.
- 데이터셋의 어느 지점에서든 즉시 학습을 재개할 수 있습니다. 일시 중지된 실행은 시작부터 데이터 로더를 빨리 감기 없이 재개할 수 있습니다.
- 완전히 결정론적입니다. GPU, 노드 또는 CPU 워커 수에 관계없이 샘플이 동일한 순서로 읽힙니다.
- 데이터 소스의 임의 혼합을 허용합니다. 데이터 소스와 총 학습 데이터의 원하는 비율을 나�열하기만 하면 StreamingDataset이 나머지를 처리합니다. 이를 통해 다양한 데이터 조합에 대한 준비 실험을 매우 쉽게 실행할 수 있었습니다.
더 자세한 내용은 StreamingDataset 블로그를 확인하세요!
학습 컴퓨팅
모든 MPT-7B 모델은 다음 도구를 사용하여 MosaicML 플랫폼에서 학습되었습니다:
- 컴퓨팅: Oracle Cloud의 A100-40GB 및 A100-80GB GPU
- 오케스트레이션 및 내결함성: MCLI 및 MosaicML 플랫폼
- 데이터: OCI 객체 저장소 및 StreamingDataset
- 학습 소프트웨어: Composer, PyTorch FSDP 및 LLM Foundry
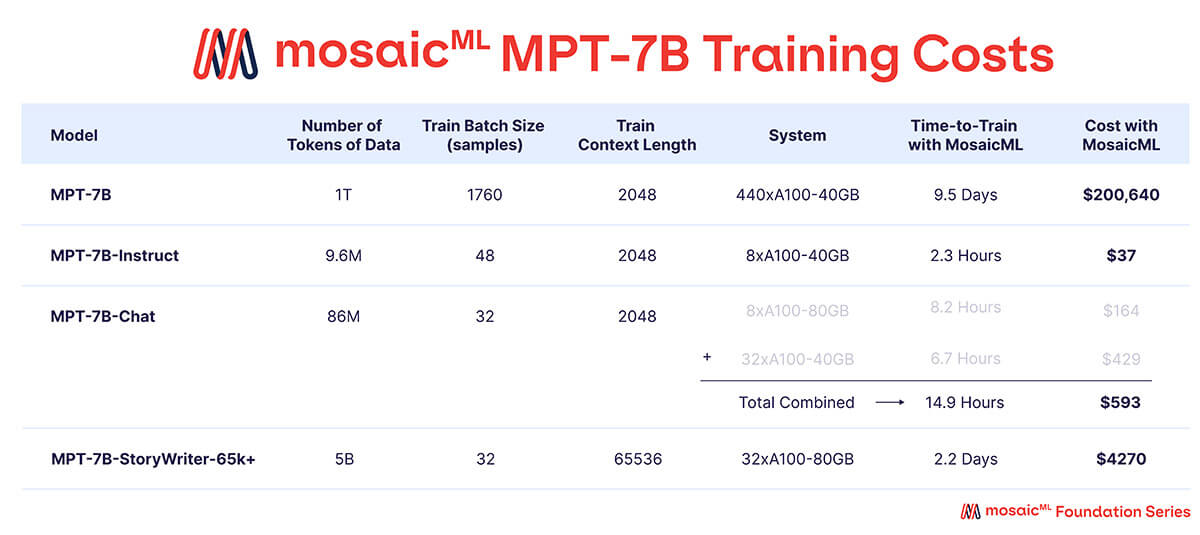
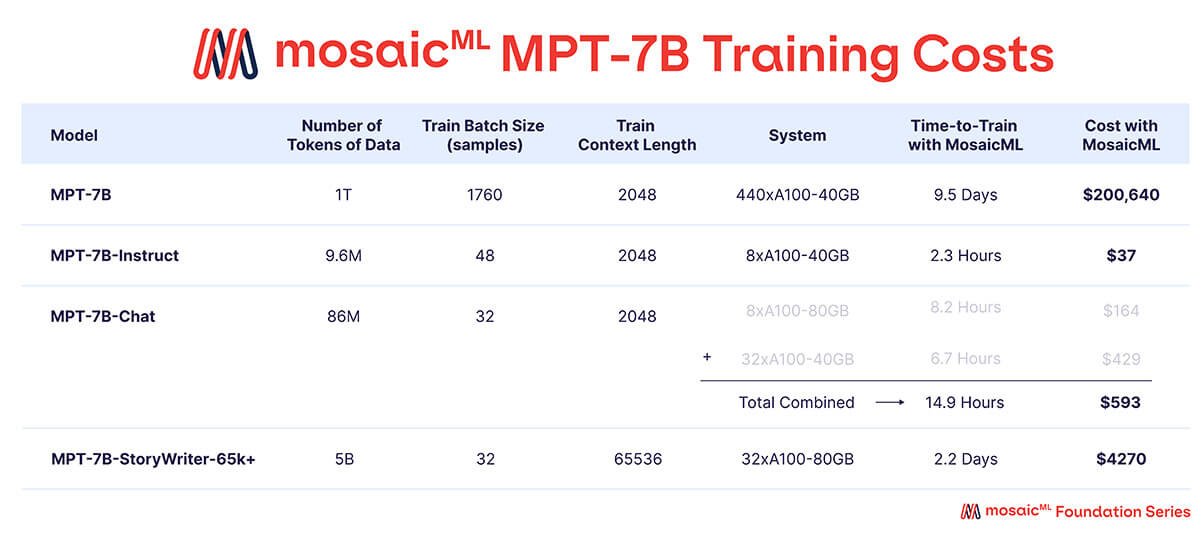
표 3에서 볼 수 있듯이, 학습 예산의 거의 전부가 기본 MPT-7B 모델에 사용되었으며, 이는 440개의 A100-40GB GPU에서 약 9.5일 동안 학습하는 데 약 20만 달러가 소요되었습니다. 미세 조정된 모델은 훨씬 적은 컴퓨팅 자원을 사용했으며 비용도 훨씬 저렴했습니다. 각 모델당 수백 달러에서 수천 달러 사이였습니다.
{kind=link}
'학습 시간'은 체크포인팅, 주기적 평가, 재시작 등을 포함한 작업 시작부터 완료까지의 총 런타임입니다. '비용'은 MosaicML 플랫폼에서 예약된 GPU에 대해 시간당 $2/A100-40GB 및 시간당 $2.50/A100-80GB의 가격으로 계산됩니다.
이러한 학습 레시피 각각은 완전히 사용자 정의할 수 있습니다. 예를 들어, 오픈 소스 MPT-7B에서 시작하여 긴 컨텍스트 길이로 독점 데이터에 미세 조정하려면 MosaicML 플랫폼에서 오늘 바로 그렇게 할 수 있습니다.
또 다른 예로, 사용자 지정 도메인(예: 생물의학 텍스트 또는 코드)에서 처음부터 새 모델을 학습하려면 MosaicML의 hero cluster 오퍼링으로 단기 대규모 컴퓨팅 블록을 예약하기만 하면 됩니다. 원하는 모델 크기와 토큰 예산을 선택하고, S3와 같은 객체 저장소에 데이터를 업로드하고, MCLI 작업을 시작하세요. 며칠 안에 자신만의 맞춤형 LLM을 갖게 될 것입니다!
다양한 LLM의 학습 시간 및 비용에 대한 지침은 이전 LLM 블로그 게시물을 확인하세요. 특정 모델 구성에 대한 최신 처리량 데이터는 여기서 찾을 수 있습니다. 이전 작업과 마찬가지로 모든 MPT-7B 모델은 Pytorch FullyShardedDataParallelism(FSDP)을 사용하여 텐서 또는 파이프라인 병렬 처리 없이 학습되었습니다.
학습 안정성
많은 팀에서 문서화했듯이, 수백에서 수천 개의 GPU에서 수십억 개의 매개변수를 가진 LLM을 학습하는 것은 매우 어렵습니다. 하드웨어는 창의적이고 예상치 못한 방식으로 자주 실패합니다. 손실 급증은 학습을 방해할 것입니다. 팀은 실패 시 24/7 학습 실행을 "돌봐야" 하고 문제가 발생하면 수동으로 개입해야 합니다. LLM 학습을 기다리는 많은 위험에 대한 솔직한 예는 OPT 로그북을 확인하세요.
MosaicML에서 저희 연구 및 엔지니어링 팀은 지난 6개월 동안 이러한 문제를 해결하기 위해 끊임없이 노력했습니다. 그 결과, 저희의 MPT-7B 학습 로그북(그림 5)은 매우 지루합니다! 저희는 사람의 개입 없이 처음부터 끝까지 1조 개의 토큰으로 MPT-7B를 학습했습니다. 손실 급증 없음, 중간 학습률 변경 없음, 데이터 건너뛰기 없음, 죽은 GPU 자동 처리 등.

{kind=link}
MPT-7B는 440개의 A100-40GB에서 9.5일 동안 1T 토큰으로 학습되었습니다. 그 시간 동안 학습 작업은 4번의 하드웨어 장애를 겪었으며, 이 모든 장애는 MosaicML 플랫폼에서 감지되었습니다. 실행은 각 장애 시 자동으로 일시 중지되었다가 재개되었으며, 사람의 개입은 필요하지 않았습니다.

{kind=link}
하드웨어 장애가 발생하면 MosaicML 플랫폼이 자동으로 이를 감지하고, 작업을 일시 중지하며, 문제가 있는 노드를 격리한 후 작업을 재개합니다. MPT-7B 학습 중에 이러한 장애가 4번 발생했지만, 작업은 매번 자동으로 재개되었습니다.
어떻게 가능했을까요? 첫째, 아키텍처 및 최적화 개선을 통해 수렴 안정성을 확보했습니다. 저희 MPT 모델은 위치 임베딩 대신 ALiBi를 사용하여 손실 급증에 대한 복원력을 향상시켰습니다. 또한 AdamW 대신 Lion 옵티마이저로 MPT 모�델을 학습시켜 안정적인 업데이트 크기를 제공하고 옵티마이저 상태 메모리를 절반으로 줄였습니다.
둘째, MosaicML 플랫폼의 NodeDoctor 기능을 사용하여 하드웨어 장애를 모니터링하고 해결했으며, JobMonitor 기능을 사용하여 이러한 장애가 해결된 후 실행을 재개했습니다. 이러한 기능을 통해 4번의 하드웨어 장애에도 불구하고 MPT-7B를 처음부터 끝까지 사람의 개입 없이 학습할 수 있었습니다. 자동 재개가 MosaicML 플랫폼에서 어떻게 작동하는지 자세히 보려면 Figure 6을 참조하세요.
Inference
MPT는 추론을 위해 빠르고, 쉽고, 저렴하게 배포할 수 있도록 설계되었습니다. 우선, 모든 MPT 모델은 HuggingFace PretrainedModel 기본 클래스를 서브클래싱하므로 HuggingFace 생태계와 완벽하게 호환됩니다. MPT 모델을 HuggingFace Hub에 업로드하고, 표준 파이프라인(`model.generate(...)` 등)으로 출력을 생성하고, HuggingFace Spaces를 구축할 수 있습니다(저희의 일부 Spaces를 여기서 확인하세요!).
성능은 어떻습니까? MPT의 최적화된 레이어(FlashAttention 및 저정밀도 layernorm 포함)를 사용하면, `model.generate(...)`를 사용할 때 MPT-7B의 기본 성능이 LLaMa-7B와 같은 다른 7B 모델보다 1.5배-2배 빠릅니다. 이를 통해 HuggingFace와 PyTorch만으로 빠르고 유연한 추론 파이프라인을 쉽게 구축할 수 있습니다.
하지만 정말 최고의 성능이 ��필요하다면 어떻게 해야 할까요? 이 경우 MPT 가중치를 FasterTransformer 또는 ONNX로 직접 포팅하세요. 스크립트 및 지침은 LLM Foundry의 추론 폴더를 확인하세요.
마지막으로, 최고의 호스팅 경험을 위해 MPT 모델을 MosaicML의 Inference 서비스에 직접 배포하세요. MPT-7B-Instruct와 같은 모델에 대한 관리형 엔드포인트를 시작으로, 최적의 비용과 데이터 개인 정보 보호를 위해 자체 사용자 지정 모델 엔드포인트를 배포할 수 있습니다.
What's Next?
이 MPT-7B 릴리스는 MosaicML에서 2년간 오픈소스 소프트웨어(Composer, StreamingDataset, LLM Foundry)와 독점 인프라(MosaicML Training 및 Inference)를 구축하고 실전 테스트하여 고객이 효율성, 개인 정보 보호 및 비용 투명성을 갖추고 LLM을 모든 컴퓨팅 제공업체, 모든 데이터 소스에서 학습할 수 있도록 지원한 노력의 정점입니다. 그리고 처음부터 제대로 작동하도록 하는 것이 가능합니다.
저희는 MPT, MosaicML LLM Foundry, 그리고 MosaicML 플랫폼이 개인, 상업 및 커�뮤니티 사용을 위한 맞춤형 LLM 구축에 가장 좋은 출발점이라고 믿습니다. 저희 체크포인트를 파인튜닝하든 처음부터 직접 학습하든 상관없습니다. 커뮤니티가 이러한 도구와 아티팩트를 기반으로 어떻게 구축해 나갈지 기대됩니다.
중요한 것은, 오늘날의 MPT-7B 모델은 시작에 불과하다는 것입니다! 고객이 더 어려운 작업을 해결하고 제품을 지속적으로 개선할 수 있도록 MosaicML은 계속해서 더 높은 품질의 파운데이션 모델을 생산할 것입니다. 이미 흥미로운 후속 모델들이 학습 중입니다. 곧 그들에 대한 소식을 듣게 될 것입니다!
Acknowledgements
사전 학습 데이터셋을 큐레이션하고, 훌륭한 토크나이저를 선택하고, 그 외에도 많은 유용한 대화를 나눠준 AI2의 친구들에게 감사합니다 ⚔️
Appendix
Data
mC4
Multilingual C4 (mC4) 3.1.0은 2022년 8월까지의 소스를 포함하는 mC4의 업데이트 버전입니다. 저희는 영어 하위 집합을 선택한 다음 각 문서에 다음 필터링 기준을 적용했습니다.
- 가장 흔한 문자는 알파벳이어야 합니다.
- 문자의 92% 이상이 영숫자여야 합니다.
- 문서가 500단어 이상인 경우, 가장 흔한 단어가 전체 단어 수의 7.5%를 초과할 수 없습니다. 문서가 500단어 이하인 경우, 가장 흔한 단어가 전체 단어 수의 30%를 초과할 수 없습니다.
- 문서는 200단어 이상 50000단어 이하여야 합니다.
처음 세 가지 필터링 기준은 샘플 품질을 개선하는 데 사용되었으며, 마지막 필터링 기준(문서는 200단어 이상 50000단어 이하)은 사전 학습 데이터의 평균 시퀀스 길이를 늘리는 데 사용되었습니다.
mC4는 Dodge et al.의 지속적인 노력의 일환으로 출시되었습니다.
C4
Colossal Cleaned Common Crawl (C4)는 Raffel et al.이 소개한 영어 Common Crawl 코퍼스입니다. 저희는 Abbas et al.의 의미론적 중복 제거 프로세스를 적용하여 C4 내에서 가장 유사한 20%의 문서를 제거했습니다. 내부 실험 결과, 이는 C4에서 학습된 모델에 대한 파레토 개선입니다.
RedPajama
저희는 RedPajama 데이터셋의 여러 하위 집합을 포함했습니다. 이 데이터셋은 Together가 LLaMA의 학습 데이터를 복제하려는 시도입니다. 구체적으로 CommonCrawl, arXiv, Wikipedia, Books, StackExchange 하위 집합을 사용했습니다.
The Stack
저희 모델이 코드 생성을 수행할 수 있기를 원했기 때문에 6.4TB의 코드 데이터 코퍼스인 The Stack을 사용했습니다. 저희는 약 2.9TB로 중복 제거된(MinHashLSH 사용) The Stack 변형인 The Stack Dedup을 사용했습니다. 데이터셋 크기를 줄이고 관련성을 높이기 위해 The Stack의 358개 프로그래밍 언어 중 18개를 선택했습니다.
- C
- C-Sharp
- C++
- Common Lisp
- F-Sharp
- Fortran
- Go
- Haskell
- Java
- Ocaml
- Perl
- Python
- Ruby
- Rust
- Scala
- Scheme
- Shell
- Tex
내부 실험 결과, 자연어 평가에 부정적인 영향을 주지 않으면서 최대 20%의 코드(및 80%의 자연어)로 학습할 수 있다는 것을 확인했기 때문에, 사전 학습 토큰의 10%를 코드로 구성하기로 했습니다.
또한 The Stack Dedup의 Markdown 구성 요소를 추출하여 독립적인 사전 학습 데이터 하위 집합으로 취급했습니다(즉, 10% 코드 토큰에 포함되지 않음). 이렇게 한 이유는 마크업 언어 문서가 대부분 자연어이므로 자연어 토큰 예산에 포함되어야 한다고 생각했기 때문입니다.
Semantic Scholar ORC
Semantic Scholar Open Research Corpus (S2ORC)는 영어 학술 논문 코퍼스로, 저희는 이를 고품질 데이터 소스로 간주합니다. 다음 품질 필터링 기준을 적용했습니다.
- 논문은 공개 액세스 가능해야 합니다.
- 논문에는 제목과 초록이 있어야 합니다.
- 논문은 영어여야 합니다(cld3 사용).
- 논문은 500단어 이상, 5단락 이상이어야 합니다.
- 논문은 1970년 이후, 2022년 12월 1일 이전에 출판되어야 합니다.
- 논�문에서 가장 빈번하게 나타나는 단어는 알파벳 문자만 포함해야 하며, 문서의 7.5% 미만에서 나타나야 합니다.
이로써 9.9M개의 논문이 나왔습니다. 최신 데이터셋 버전을 얻는 방법에 대한 지침은 여기에서 확인할 수 있으며, 원본 출판물은 여기에서 확인할 수 있습니다. 데이터셋의 필터링된 버전은 AI2에서 제공해 주셨습니다.
평가 작업
Lambada: 책 코퍼스에서 큐레이션된 5153개의 텍스트 샘플입니다. 모델이 다음 단어를 예측해야 하는 수백 단어의 문단으로 구성됩니다.
PIQA: 물리적 직관 이진 객관식 질문 1838개입니다. 예: "질문: 옷걸이에 옷을 걸고 이사할 때 어떻게 쉽게 옮길 수 있을까요?", "답변: "빈 무거운 옷걸이 몇 개를 가져와서 옷걸이에 옷을 걸고 한 번에 모두 옮기세요."
COPA: XYZ이므로/때문에 TUV 형식의 문장 100개입니다. 모델이 따라서/때문에 뒤에 올 두 가지 가능한 방법 중 하나를 선택해야 하는 이진 객관식 질문으로 구성됩니다. 예: {"query": "여자가 기분이 안 좋았기 때문에", "gold": 1, "choices": ["그녀는 친구와 잡담을 나눴습니다.", "그녀는 친구에게 혼자 두라고 말했습니다."]}
BoolQ: 관련 정보가 포함된 구절을 기반으로 한 예/아니오 질문 3270개입니다. 질문 주제는 대중문화부터 과학, 법률, 역사 등 다양합니다. 예: {"query": "구절: 커밋 개구리는 머펫 캐릭터이며 짐 헨슨의 가장 잘 알려진 창작물입니다. 1955년에 소개된 커밋은 수많은 머펫 프로덕션, 특히 세서미 스트리트와 머펫 쇼의 직설적인 주인공 역할을 하며, 다른 텔레비전 시리즈, 영화, 스페셜, 공익 광고에서도 수년간 활약했습니다. 헨슨은 원래 1990년 사망할 때까지 커밋을 연기했으며, 스티브 휘트마이어가 그 역할을 맡다가 2016년 해고될 때까지 연기했습니다. 현재 커밋은 맷 보겔이 연기하고 있습니다. 그는 또한 머펫 베이비스에서 프랭크 웰커가 목소리를 맡았고, 다른 애니메이션 프로젝트에서도 가끔 목소리를 맡았으며, 2018년 머펫 베이비스 리부트에서는 맷 대너가 목소리를 맡았습니다.\n질문: 커밋 개구리가 세서미 스트리트에 출연한 적이 있나요?\n", "choices": ["아니요", "예"], "gold": 1}
Arc-Challenge: 과학에 대한 4가지 선택 객관식 질문 1172개입니다.
Arc-Easy: 쉬운 4가지 선택 객관식 과학 질문 2376개입니다.
HellaSwag: 실제 시나리오가 제시되고 모델이 시나리오에 대한 가장 가능성 있는 결론을 선택해야 하는 4가지 선택 객관식 질문 10042개입니다.
Jeopardy: 과학, 세계사, 미국사, 단어 기원, 문학의 5가지 범주에서 나온 Jeopardy 질문 2117개입니다. 모델은 정확한 정답을 제공해야 합니다.
MMLU: 57개의 다양한 학술 범주에서 나온 객관식 질문 14,042개입니다.
TriviaQA: 자유 응답 형식의 대중문화 퀴즈 질문 11313개입니다.
Winograd: 모델이 대명사의 어떤 참조 대상이 가장 가능성이 높은지 해결해야 하는 스키마 질문 273개입니다.
Winogrande: 모델이 어��떤 모호한 문장이 논리적으로 더 가능성이 높은지 해결해야 하는 스키마 질문 1,267개입니다(문장의 두 버전 모두 구문적으로 유효함).
MPT Hugging Face Spaces 개인정보처리방침
저희의 MPT Hugging Face Spaces 개인정보처리방침을 참조하세요.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.