멀티모달 데이터 통합: 헬스케어 AI를 위한 프로덕션 아키텍처
대부분의 멀티모달 헬스케어 AI 노력은 프로덕션 전에 중단됩니다. 거버넌스, 파이프라인 및 누락된 데이터를 처리하는 융합 전략으로 유전체학, 영상, 임상 노트 및 웨어러블을 통합하는 실용적인 청사진입니다.
작성자: Maks Khomutskyi
- 거버넌스가 적용된 멀티모달 기반 구축: 유전체학, 영상 특징, 임상 노트 개체 및 웨어러블 스트림을 Unity Catalog 액세스 제어, 감사, 계보 및 거버넌스 태그를 갖춘 Delta로 수집합니다.
- 프로덕션 현실을 견디는 융합 선택: 모달리티 가용성, 차원 및 시간에 따라 조기/중간/후기/주의 기반 융합을 사용합니다. 완벽한 코호트가 아닌 누락된 모달리티를 위해 설계되었습니다.
- 엔드투엔드 운영화: 스트리밍 + 피처 윈도우를 위한 Lakeflow SDP, 유사성/코호팅을 위한 벡터 검색, POC에서 프로덕션으로 이동하기 위한 재현 가능한 파이프라인(버저닝/타임 트래블 + CI/CD + MLflow)을 사용합니다.
의료 분야에서 가장 가치 있는 AI 활용 사례는 단일 데이터셋에 존재하는 경우가 드뭅니다. 멀티모달 데이터 통합—유전체학, 영상, 임상 기록, 웨어러블 기기 데이터 결합—은 정밀 종양학 및 조기 진단에 필수적이지만, 많은 이니셔티브가 프로덕션 단계에 이르기 전에 중단됩니다.
정밀 종양학은 유전체 프로파일링을 통한 분자적 요인과 영상 데이터를 통한 해부학적 맥락을 모두 이해해야 합니다. 유전적 위험 신호와 장기간의 웨어러블 기기 데이터를 결합하면 조기 진단이 향상됩니다. 그리고 “왜”에 대한 많은 세부 정보—증상, 반응, 근거—는 여전히 임상 기록에 남아 있습니다.
연구에서 상당한 진전에도 불구하고, 많은 멀티모달 이니셔티브가 프로덕션 단계에 이르기 전에 중단됩니다. 모델링이 불가능해서가 아니라, 데이터와 운영 모델이 임상 현실에 준비되지 않았기 때문입니다. 제약은 모델의 정교함이 아니라 아키텍처입니다. 모달리티별로 분리된 스택은 불안정한 파이프라인, 중복된 거버넌스, 그리고 임상 배포 요구 사항에 따라 실패하�는 비용이 많이 드는 데이터 이동을 초래합니다.
이 게시물은 멀티모달 정밀 의학을 위한 프로덕션 중심의 레이크하우스 패턴을 설명합니다. 각 모달리티를 거버넌스된 Delta 테이블에 안착시키고, 교차 모달 피처를 생성하며, 실제 누락 데이터를 견딜 수 있는 융합 전략을 선택하는 방법을 다룹니다.
참조 아키텍처
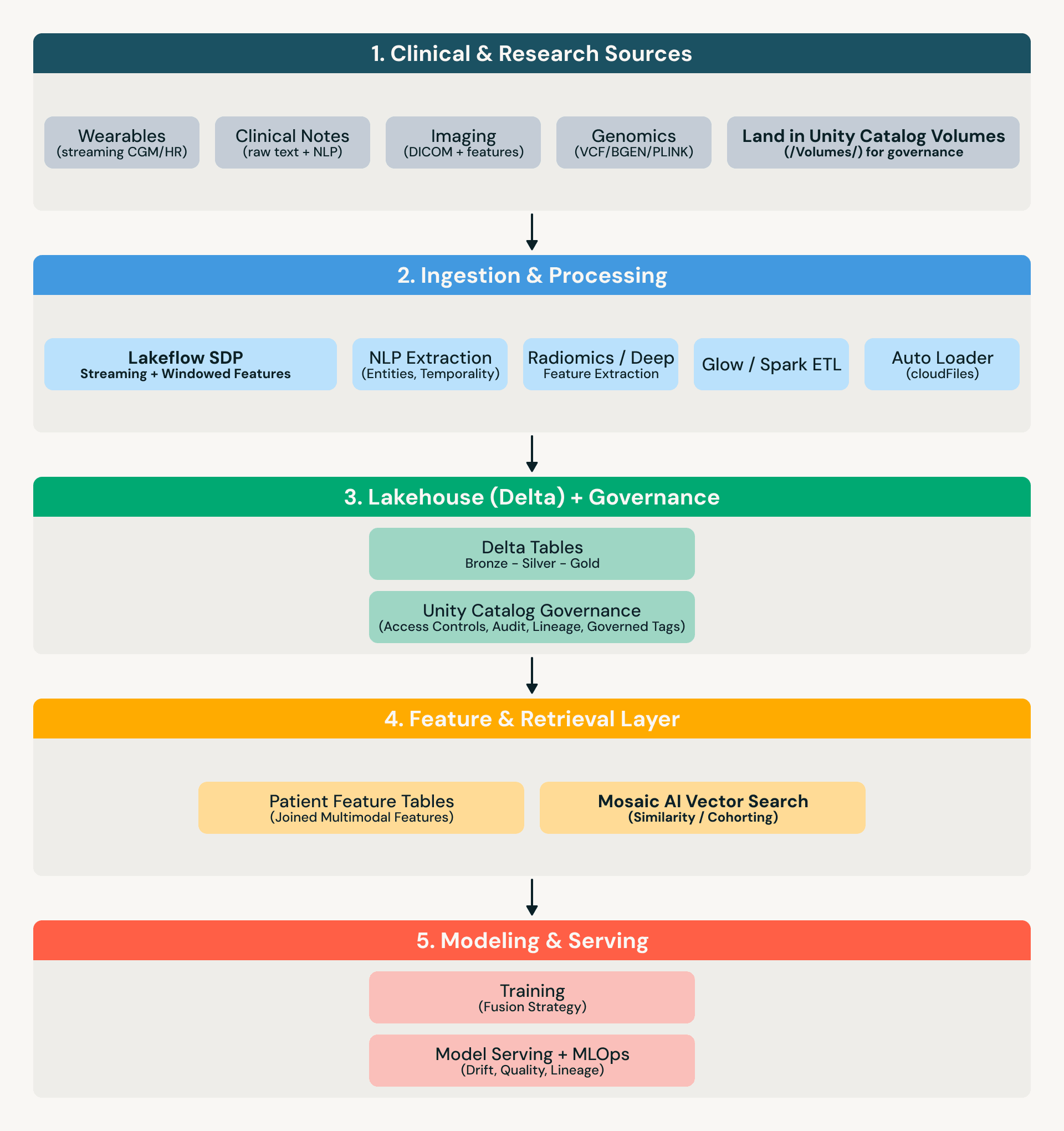
실제에서 “거버넌스”의 의미
이 게시물 전반에 걸쳐 “거버넌스된 테이블”은 Unity Catalog(또는 동등한 제어 기능)를 사용하여 데이터가 보안 및 운영화되었음을 의미하며, 다음을 포함합니다:
거버넌스 태그를 사용한 데이터 분류: PHI/PII/28 CFR Part 202/StudyID/…
- 세분화된 액세스 제어: catalog/schema/table/volume 권한, PHI에 필요한 경우 행/열 수준 제어 포함.
- 감사 가능성: 누가 무엇에 언제 액세스했는지 (규제 환경에 중요).
- 계보: 피처 및 모델 입력 데이터를 원본 데이터셋으로 추적.
- 제어된 공유: 팀 및 도구 전반에 걸친 일관된 정책 경계.
재현성: 데이터셋 버전 관리 및 타임 트래블, 파이프라인/작업에 대한 CI/CD, 실험 및 모델 버전 추적을 위한 MLflow.
이는 기술 아키텍처를 비즈니스 결과와 연결합니다: 민감한 데이터 복사본 감소, 재현 가능한 분석, 프로덕션화 승인 속도 향상.
멀티모달이 기본이 되어가는 이유
단일 모달리티 모델은 복잡한 임상 환경에서 실제 한계에 부딪힙니다. 영상은 강력할 수 있지만, 많은 복잡한 ��예측은 분자 + 장기간의 맥락에서 이점을 얻습니다. 유전체학은 요인을 포착하지만, 표현형, 환경 또는 일상적인 생리학은 포착하지 못합니다. 기록과 웨어러블 기기는 구조화된 데이터가 종종 놓치는 “행간의” 신호를 추가합니다.
실제 볼륨이 중요합니다: Databricks는 약 80%의 의료 데이터가 비정형(예: 텍스트 및 이미지)이라고 언급합니다. 그렇기 때문에 멀티모달 데이터 통합은 구조화된 EHR 필드뿐만 아니라 비정형 기록과 이미지를 대규모로 처리해야 합니다.
실질적인 교훈: 각 모달리티는 자체적으로 불완전합니다. 멀티모달 시스템은 다음을 수행하도록 설계될 때 작동합니다:
- 모달리티별 신호를 보존합니다.
- 일부 입력이 누락된 경우에도 견고하게 유지됩니다.
네 가지 융합 전략 (그리고 각각이 프로덕션에서 살아남는 시점)
융합 선택이 팀이 실패하는 유일한 이유는 드물지만, 파일럿이 전환되지 않는 이유를 설명하는 경우가 많습니다. 데이터가 희소하고, 모달리티가 다른 시점에 도착하며, 거버넌스 요구 사항이 데이터 유형별로 다르기 때문입니다.
1) 조기 융합 (훈련 전에 원시 입력을 연결합니다.)
- 사용 시점: 모달리티 가용성이 일관된 소규모, 엄격하게 통제된 코호트.
- 절충점: 고차원 유전체학 및 대규모 피처 세트에 대한 확장성이 낮습니다.
2) 중간 융합 (각 모달리티를 별도로 인코딩한 다음, 은닉 표현을 병합합니다.)
- 사용 시점: 고차원 오믹스를 저차원 EHR/임상 피처와 결합할 때.
- 절충점: 모�달리티별로 신중한 표현 학습과 규율 있는 평가가 필요합니다.
3) 후기 융합 (모달리티별 모델을 훈련한 다음, 예측을 결합합니다.)
- 사용 시점: 누락된 모달리티가 흔한 프로덕션 롤아웃.
- 이점: 하나 이상의 모달리티가 누락된 경우에도 점진적으로 성능이 저하됩니다.
4) 어텐션 기반 융합 (모달리티 및 시간 전반에 걸쳐 동적 가중치를 학습합니다.)
- 사용 시점: 시간이 중요하고(웨어러블 기기 + 장기간의 기록, 반복 영상) 상호 작용이 복잡할 때.
- 절충점: 검증이 더 어렵고, 잘못된 상관 관계를 피하기 위해 신중한 제어가 필요합니다.
의사 결정 프레임워크: 배포 현실에 맞게 융합을 조정합니다. 모달리티 가용성 패턴, 차원 균형, 시간적 역학.
레이크하우스의 멀티모달 기질
레이크하우스 접근 방식은 모달리티 간의 데이터 이동을 줄입니다. 유전체학 테이블, 영상 메타데이터/피처, 텍스트에서 파생된 엔티티, 스트리밍 웨어러블 기기 데이터는 각 팀을 위해 파이프라인을 재구축할 필요 없이 한 곳에서 거버넌스 및 쿼리될 수 있습니다.
유전체학 처리 (Glow + Delta)
Glow는 일반적인 형식(예: VCF/BGEN/PLINK)에서 Spark를 사용하여 분산 유전체학 처리를 가능하게 하며, 파생된 출력은 Delta 테이블로 저장되어 임상 피처와 조인될 수 있습니다.
영상 유사성 (파생 피처 + 벡터 검색)
영상 데이터의 경우 패턴은 다음과 같습니다: (1) 업스트림에서 피처/임베딩을 파생(라디오믹스 또는 딥 모델 출력), (2) 거버넌스된 Delta 테이블에 피처 저장(Unity Catalog를 통해 보안), (3) 벡터 검색을 사용하여 유사성 쿼리(예: “글리오블라스토마 내에서 유사한 표현형 찾기”).
이를 통해 별도의 시스템으로 데이터를 내보내지 않고도 코호트 검색 및 회고적 비교가 가능합니다.
임상 기록 (NLP에서 거버넌스된 피처로)
기록에는 종종 누락된 맥락—타임라인, 증상, 반응, 근거—이 포함됩니다. 실용적인 접근 방식은 엔티티 + 시간 정보를 테이블(약물 변경, 증상, 절차, 가족력, 타임라인)로 추출하고, 엄격한 거버넌스(Unity Catalog + 액세스 제어) 하에 원시 텍스트를 유지하며, 기록에서 파생된 피처를 영상 및 오믹스와 다시 조인하여 모델링 및 코호트 구성을 수행하는 것입니다.
웨어러블 기기 데이터 (스트리밍용 Lakeflow SDP + 피처 창)
웨어러블 기기 스트림은 스키마 진화, 지연 도착 이벤트, 지속적인 집계와 같은 운영 요구 사항을 도입합니다. Lakeflow Spark Declarative Pipelines(SDP)는 스트리밍 테이블 및 구체화된 뷰를 위한 강력한 수집-피처 패턴을 제공합니다. 가독성을 위해 아래에서는 Lakeflow SDP라고 지칭합니다.
구문 참고: pyspark.pipelines 모듈(@dp.table 및 @dp.materialized_view 데코레이터 포함, dp로 가져옴)은 현재 Databricks Lakeflow SDP Python 의미론을 따릅니다.
통합 스토리지 + 거버넌스 모델이 중요한 이유
운영상의 이점은 일관성입니다:
클라우드 배포에서 흔히 발생하는 실패 모드는 “모달리티별 특수 스토어” 접근 방식입니다(예: FHIR 스토어, 별도의 오믹스 스토어, 별도의 영상 스토어, 별도의 피처 또는 벡터 스토어). 실제로는 종종 중복된 거버넌스와 불안정한 스토어 간 파이프라인을 의미하며, 이는 계보, 재현성 및 멀티모달 조인��을 운영화하기 훨씬 어렵게 만듭니다.
- 재현성: 일관된 훈련 세트 및 재분석을 위한 ACID + 타임 트래블.
이것이 멀티모달 프로토타입을 프로덕션에서 실행, 모니터링 및 방어할 수 있는 것으로 바꿔주는 것입니다.
누락된 양식 문제 해결
실제 배포는 불완전한 데이터에 직면합니다. 모든 환자가 포괄적인 유전체 프로파일링을 받는 것은 아닙니다. 영상 연구를 사용할 수 없을 수도 있습니다. 웨어러블은 등록된 인구에게만 존재합니다. 누락은 예외적인 경우가 아니라 기본값입니다.
프로덕션 디자인은 희소성을 가정하고 이를 계획해야 합니다:
- 훈련 중 양식 마스킹: 배포 현실을 시뮬레이션하기 위해 개발 중에 입력을 제거합니다.
- 희소 주의/양식 인식 모델: 단일 양식에 과도하게 의존하지 않고 사용 가능한 것을 학습합니다.
- 전이 학습 전략: 더 풍부한 코호트에서 훈련하고 신중한 검증을 통해 희소 임상 코호트에 적응합니다.
핵심 통찰력: 완전한 데이터를 가정하는 아키텍처는 프로덕션에서 실패하는 경향이 있습니다. 희소성을 위해 설계된 아키텍처는 일반화됩니다.
정밀 종양학 패턴: 아키텍처에서 임상 워크플로까지
실용적인 정밀 종양학 패턴은 다음과 같습니다:
- 유전체 프로파일링 -> 거버넌스된 분자 테이블 (Unity Catalog). 계보 및 제어된 액세스가 있는 쿼리 가능한 테이블로 변이, 바이오마커 및 주석을 저장합니다.
- 영상에서 파생�된 특징 -> 유사성 + 코호트. “유사 사례 찾기” 및 표현형-유전형 상관 관계를 위해 영상 특징 벡터를 인덱싱합니다.
- 메모에서 파생된 타임라인 -> 자격 + 컨텍스트. 시험 선별 및 일관된 종단적 이해를 지원하기 위해 시간 인식 엔티티를 추출합니다.
- 종양 위원회 지원 계층 (인간 루프 내). 출처가 포함된 일관된 검토 보기에 멀티모달 증거를 결합합니다. 목표는 결정을 자동화하는 것이 아니라 주기 시간을 줄이고 증거 수집의 일관성을 개선하는 것입니다.
비즈니스 영향: 멀티모달이 운영 가능해지면 무엇이 달라지는가
시장 성장이 이것이 중요한 이유 중 하나이지만 즉각적인 동인은 운영상의 것입니다:
- 새로운 양식이 도착할 때 더 빠른 코호트 조립 및 재분석.
- 더 적은 데이터 복사 및 더 적은 일회성 파이프라인.
- 번역 워크플로에 대한 더 짧은 반복 주기 (몇 주 대 몇 달).
환자 유사성 분석은 또한 유사한 멀티모달 프로파일을 가진 과거 일치 항목을 식별하여 실용적인 “N-of-1” 추론을 가능하게 할 수 있습니다. 이는 특히 희귀 질환 및 이질적인 종양학 인구에게 가치가 있습니다.
시작하기: 실용적인 첫 30일
- 하나의 임상 결정 (예: 시험 일치, 위험 계층화)을 선택하고 성공 지표를 정의합니다.
- 양식 + 누락 인벤토리 (누가 유전체학? 영상? 종단적 웨어러블을 가지고 있습니까?).
- Unity Catalog를 통해 보안이 적용된 거버넌스된 브론즈/실버/골드 테이블을 설정합니다.
- 누락을 허용하는 융합 기준선을 선택합니다 (후기 융합은 종종 안전한 시작입니다).
- 운영화: 계보, 데이터 품질 검사, 드리프트 모니터링, 재현 가능한 훈련 세트.
- 검증 계획: 평가 코호트, 편향 검사, 임상의 워크플로 체크포인트.
키워드: 멀티모달 AI, 정밀 의학, 유전체학 처리, 의료 영상 AI, 의료 데이터 통합, 융합 전략, 레이크하우스 아키텍처
높은 우선순위
Unity Catalog: https://www.databricks.com/product/unity-catalog
의료 및 생명 과학: https://www.databricks.com/solutions/industries/healthcare-and-life-sciences
의료 및 생명 과학을 위한 데이터 인텔리전스 플랫폼: https://www.databricks.com/resources/guide/data-intelligence-platform-for-healthcare-and-life-sciences
중간 우선순위
Databricks AI Search 문서: https://docs.databricks.com/en/generative-ai/vector-search.html
Databricks의 Delta Lake: https://www.databricks.com/product/delta-lake-on-databricks
데이터 레이크하우스 (용어집): https://www.databricks.com/glossary/data-lakehouse
추가 관련 블로그
멀티모달 RAG로 환자의 데이터 통합: https://www.databricks.com/blog/unite-your-patients-data-multi-modal-rag
Databricks 데이터 인텔리전스 플랫폼에서 오믹스 데��이터 관리 변환: https://www.databricks.com/blog/transforming-omics-data-management-databricks-data-intelligence-platform
Glow 소개 (유전체학): https://www.databricks.com/blog/2019/10/18/introducing-glow-an-open-source-toolkit-for-large-scale-genomic-analysis.html
databricks.pixels를 사용한 DICOM 이미지 대규모 처리: https://www.databricks.com/blog/2023/03/16/building-lakehouse-healthcare-and-life-sciences-processing-dicom-images.html
의료 및 생명 과학 솔루션 가속기: https://www.databricks.com/solutions/accelerators
멀티모달 의료 AI를 파일럿에서 프로덕션으로 전환할 준비가 되셨습니까? HLS 아키텍처, Unity Catalog를 사용한 거버넌스 및 엔드투엔드 구현 패턴에 대한 Databricks 리소스를 살펴보세요.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.