Databricks에서 파이프라인을 구축하는 새로운 방법: 데이터 엔지니어링을 위한 IDE 소개
Lakeflow Spark 선언형 파이프라인 작성을 위해 특별히 제작된 새로운 개발자 환��경
작성자: Adriana Ispas, Lennart Kats, 카미엘 스틴스트라 , Monica Alvarez Vicente
- Spark 선언형 파이프라인에 Databricks Workspace의 전용 IDE 개발자 환경이 추가되었습니다.
- 새로운 IDE는 종속성 그래프, 미리 보기, 실행 인사이트와 같은 기능을 통해 생산성과 디버깅을 향상시킵니다.
- IDE는 빠른 온보딩과 Git 통합, CI/CD, 관찰 가능성과 같은 고급 사용 사례를 모두 지원합니다.
올해 Data + AI Summit에서 저희는 데이터 엔지니어링 IDE를 선보였습니다. Databricks Workspace 내에서 직접 데이터 파이프라인을 작성하기 위해 특별히 설계된 새로운 개발 환경입니다. 새로운 기본 개발 환경으로서 이 IDE는 데이터 엔지니어링에 대한 저희의 확고한 접근 방식을 반영합니다. 즉, 기본적으로 선언적이고, 구조적으로 모듈화되며, Git 통합 및 AI 지원 기능을 갖추고 있습니다.
간단히 말해, 데이터 엔지니어링 IDE는 데이터 파이프라인을 작성하고 테스트하는 데 필요한 모든 것을 한 곳에서 제공합니다.
Public Preview로 제공되는 이 새로운 개발 환경을 통해, 선언적 파이프라인이 전용 IDE 환경으로부터 어떻게 이점을 얻는지 설명하고 파이프라인 개발을 더 빠르고 체계적이며 디버깅하기 쉽게 만드는 주요 기능을 강조하고자 합니다.
선언적 데이터 엔지니어링을 위한 전용 개발 환경
선언적 파이프라인은 구축 방법에 대한 단계별 지침을 작성하는 대신 달성하고자 하는 바를 선언함으로써 데이터 엔지니어링을 단순화합니다. 선언적 프로그래밍은 데이터 파이프라인 구축에 매우 강력한 접근 방식이지만, 여러 데이터 세트를 다루고 전체 개발 수명 주기를 관리하는 것은 전용 도구 없이는 다�루기 어려워질 수 있습니다.
이것이 바로 저희가 Databricks Workspace 내에서 선언적 파이프라인을 위한 완전한 IDE 환경을 구축한 이유입니다. Lakeflow Spark Declarative Pipelines를 위한 새로운 편집기로 제공되며, 파일을 사용하여 데이터 세트와 품질 제약 조건을 선언하고, 폴더로 구성하고, 코드와 함께 표시되는 자동 생성된 종속성 그래프를 통해 연결을 볼 수 있습니다. 편집기는 파일을 평가하여 가장 효율적인 실행 계획을 결정하고, 단일 파일, 변경된 데이터 세트 집합 또는 전체 파이프라인을 다시 실행하여 빠르게 반복할 수 있도록 합니다.
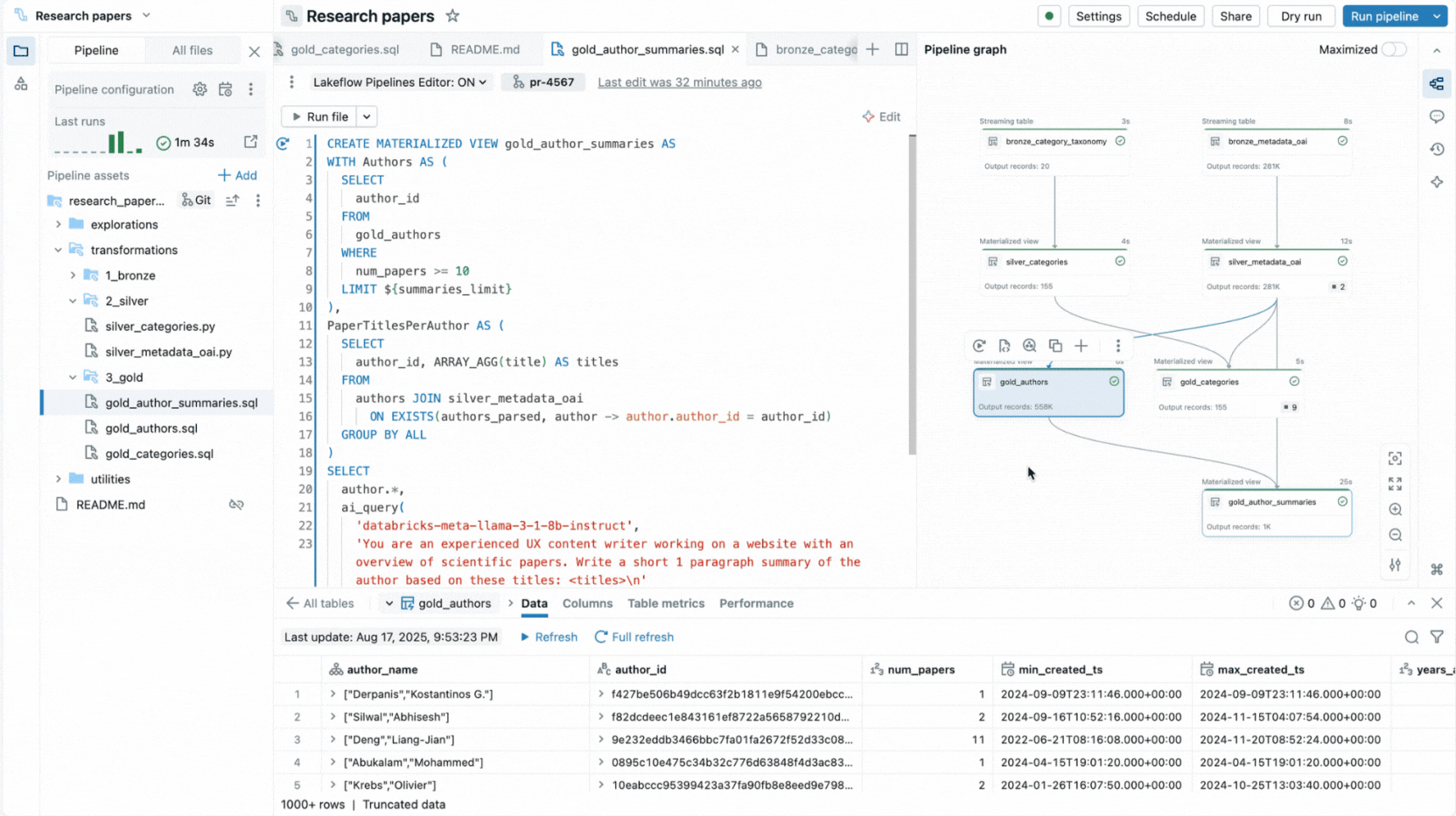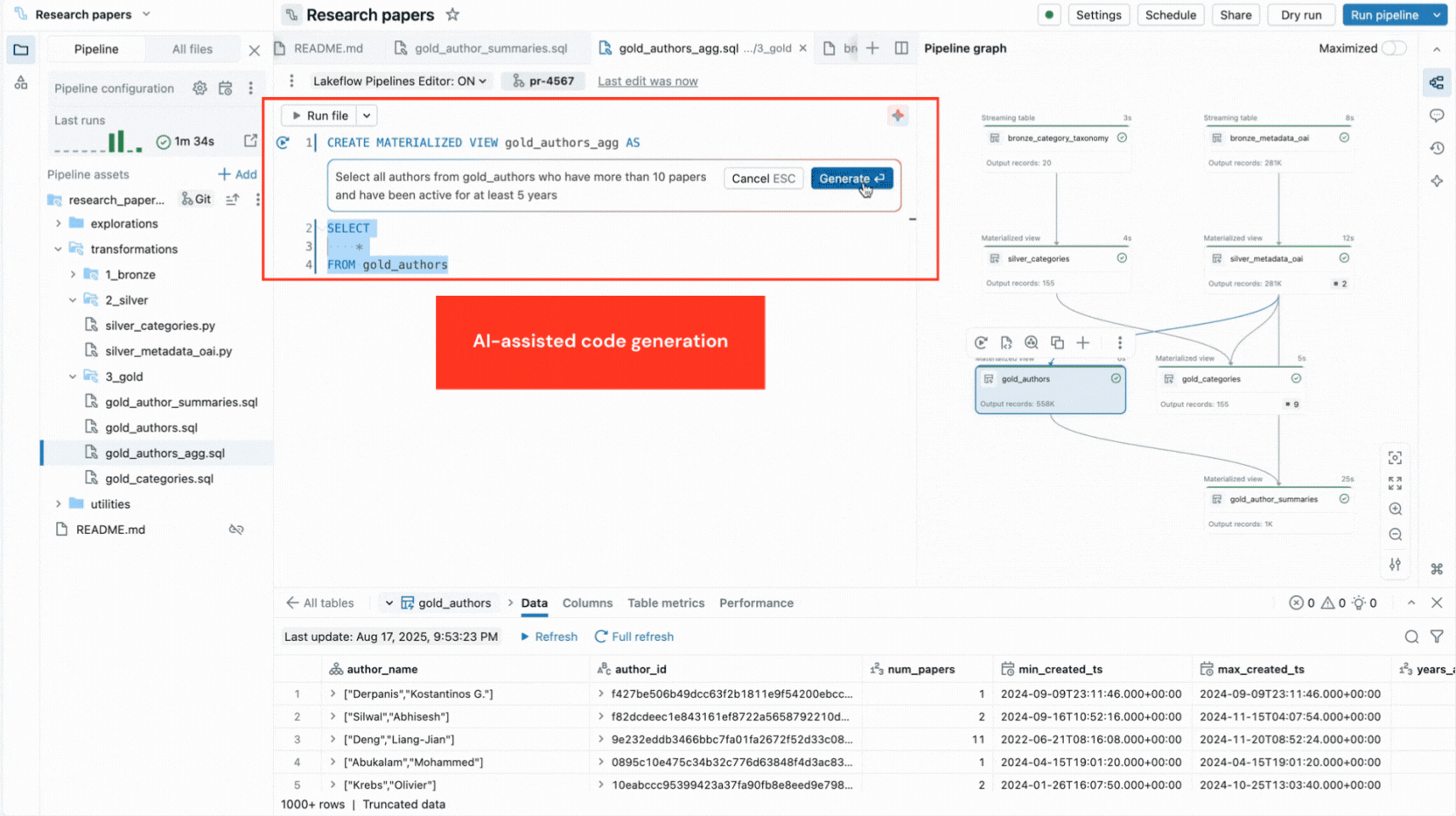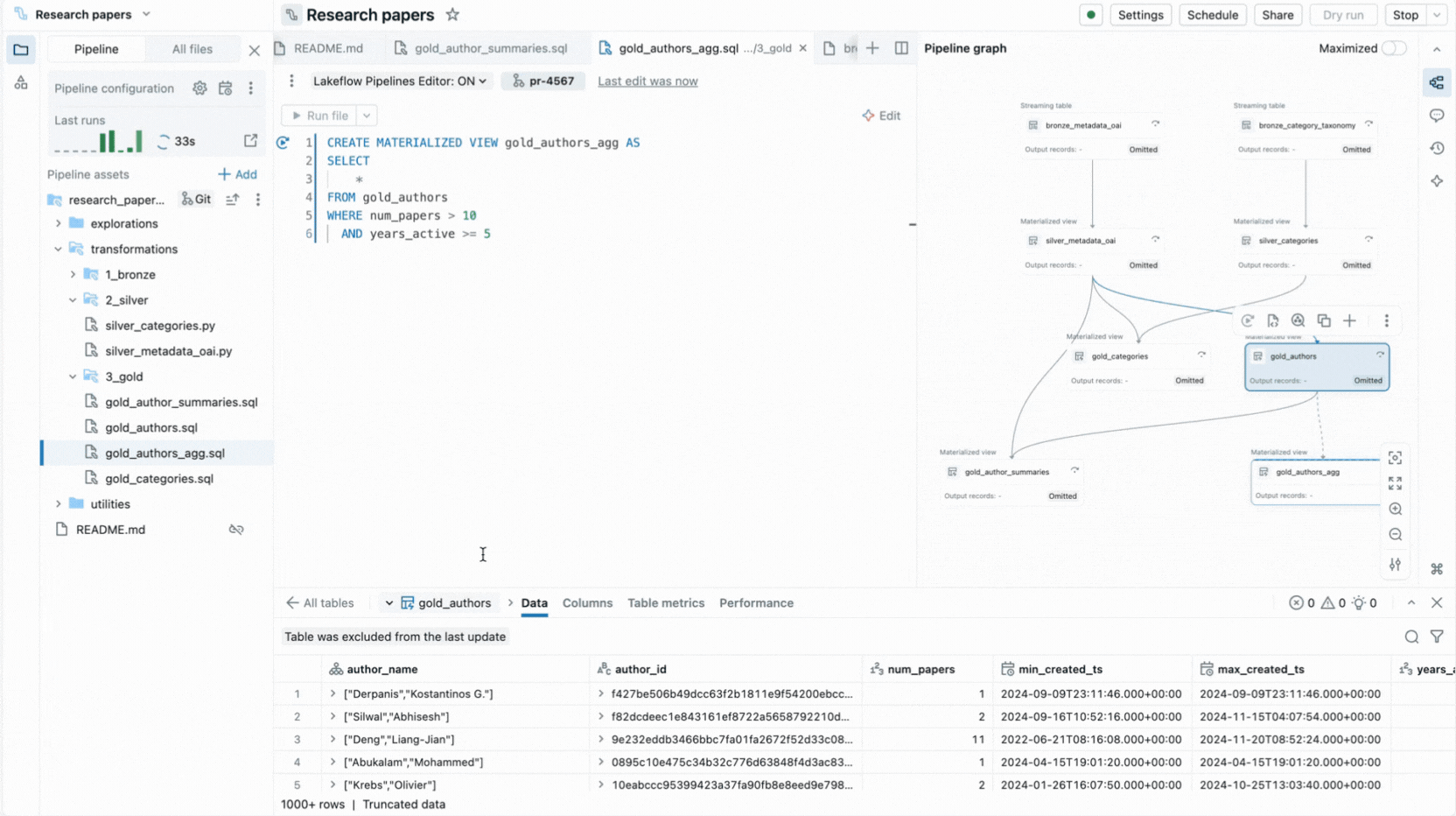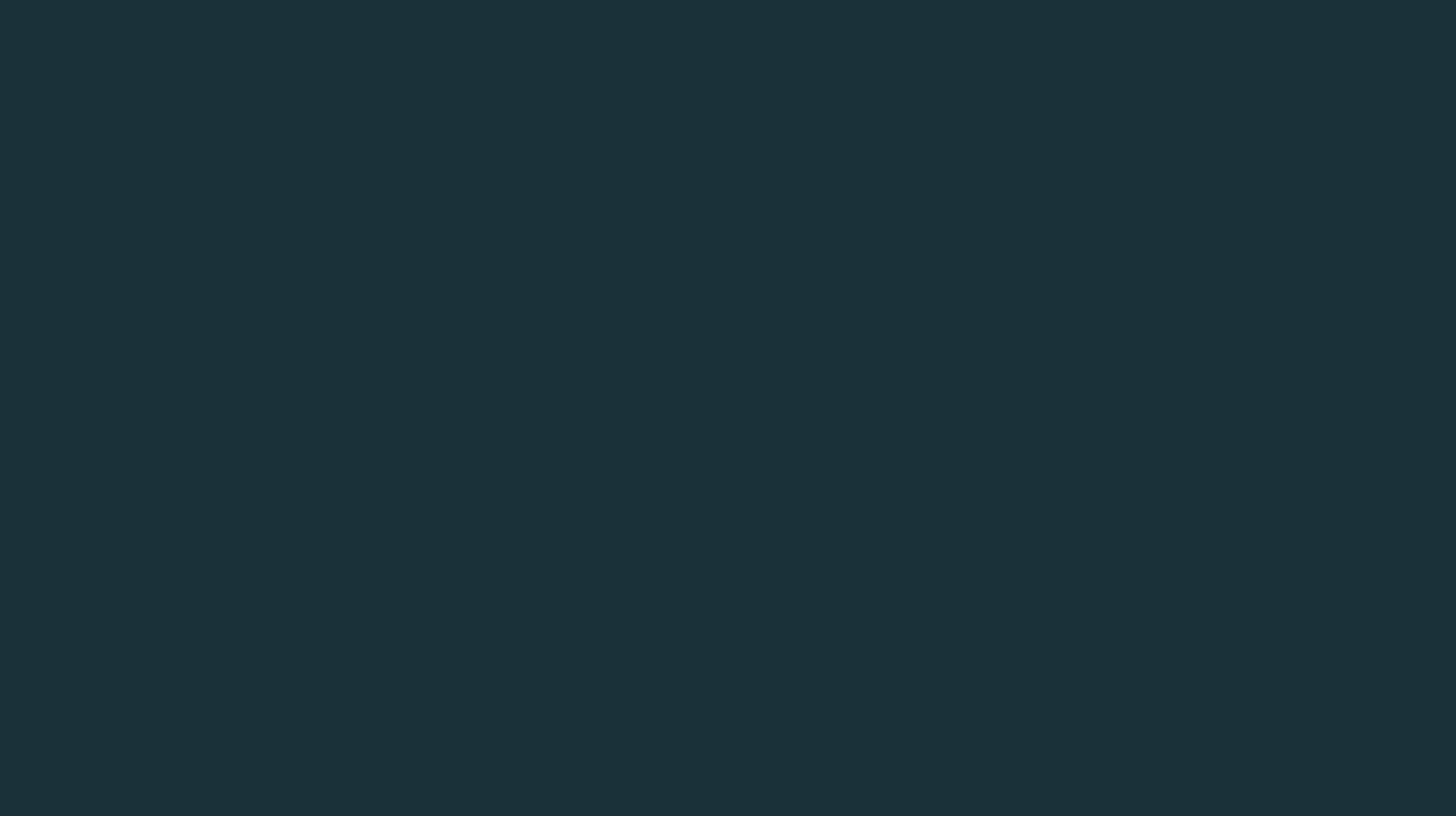
이 편집기는 또한 실행 인사이트를 제공하고, 내장된 데이터 미리보기를 제공하며, 코드를 미세 조정하는 데 도움이 되는 디버깅 도구를 포함합니다. 또한 버전 관리 및 Lakeflow Jobs를 사용한 예약 실행과 통합됩니다. 따라서 단일 환경에서 파이프라인과 관련된 모든 작업을 수행할 수 있습니다.
이러한 모든 기능을 단일 IDE와 유사한 환경으로 통합함으로써, 이 편집기는 선언적 패러다임을 유지하면서 데이터 엔지니어가 최신 IDE에서 기대하는 관행과 생산성을 제공합니다.
아래에 포함된 동영상은 이러한 기능이 작동하는 모습을 보여주며, 다음 섹션에서 더 자세한 내용을 다룹니다.
"새로운 편집기는 코드, 파이프라인 그래프, 결과, 구성 및 문제 해결 등 모든 것을 한 곳으로 가져옵니다. 더 이상 브라우저 탭을 바꾸거나 컨텍스트를 잃을 필요가 없습니다. 개발이 더 집중적이고 효율적으로 느껴집니다. 각 코드 변경의 영향을 직접 확인할 수 있습니다. 클릭 한 번으로 정확한 오류 줄로 이동할 수 있어 디버깅이 빨라집니다. 모든 것이 연결됩니다. 코드와 데이터; 코드와 테이블; 테이블과 코드. 파이프라인 간 전환이 쉽고, 자동 구성된 유틸리티 폴더와 같은 기능은 복잡성을 제거합니다. 이것이 파이프라인 개발이 작동해야 하는 방식처럼 느껴집니다."—Chris Sharratt, 데이터 엔지니어, Rolls-Royce
"제 생각에 새로운 파이프라인 편집기는 엄청난 개선입니다. 멀티 소프트 탭 환경 덕분에 복잡한 폴더 구조를 관리하고 파일 간에 전환하는 것이 훨씬 쉽습니다. 통합 DAG 보기는 복잡한 파이프라인을 파악하는 데 정말 도움이 되며, 향상된 오류 처리는 게임 체인저입니다. 문제를 신속하게 파악하는 데 도움이 되고 개발 워크플로우를 간소화합니다."—Matt Adams, 수석 데이터 플랫폼 개발자, PacificSource Health Plans
시작하기 쉬움
선언적 패러다임이 처음인 사용자도 첫 파이프라인을 빠르게 구축할 수 있도록 편집기를 설계했습니다.
- 안내 설정을 통해 신규 사용자는 샘플 코드로 시작할 수 있으며, 기존 사용자는 Databricks Asset Bundles를 통한 CI/CD 통합과 같은 고급 설정을 구성할 수 있습니다.
- 제안된 폴더 구조는 엄격한 규칙을 강제하지 않고 에셋을 구성하기 위한 시작점을 제공하므로 팀은 자체적으로 확립된 조직 패턴을 구현할 수도 있습니다. 예를 들어, 각 메달리온 단계별 폴더로 변환을 그룹화하고 파일당 하나의 데이터 세트를 사용할 수 있습니다.
- 기본 설정을 통해 사용자는 무거운 사전 구성 오버헤드 없이 첫 코드를 작성하고 실행할 수 있으며, 엔드투엔드 워크로드가 정의되면 나중에 설정을 조정할 수 있습니다.
이러한 기능은 사용자가 빠르게 생산성을 높이고 작업을 프로덕션 준비 파이프라인으로 전환하는 데 도움이 됩니다.
내부 개발 루프의 효율성
파이프라인 구축은 반복적인 프로세스입니다. 편집기는 작성 작업을 단순화하고 논리를 테스트하고 개선하는 것을 더 빠르게 만드는 기능으로 이 프로세스를 간소화합니다.
- AI 기반 코드 생성 및 코드 템플릿은 코드 데이터 세트 정의 및 데이터 품질 제약 조건을 빠르게 처리하고 반복적인 단계를 제거합니다.
- 선택적 실행을 통해 단일 테이블, 파일의 모든 테이블 또는 전체 파이프라인을 실행할 수 있습니다.
- 대화형 파이프라인 그래프는 데이터 세트 종속성에 대한 개요를 제공하고 데이터 미리보기, 다시 실행, 코드로 이동 또는 자동 생성된 보일러플레이트로 새 데이터 세트 추가와 같은 빠른 작업을 제공합니다.
- 내장된 데이터 미리보기를 통해 편집기를 벗어나지 않고 테이블 데이터를 검사할 수 있습니다.
- 컨텍스트 오류는 관련 코드와 함께 표시되며 Databricks Assistant의 제안된 수정 사항이 제공됩니다.
- 실행 인사이트 패널은 데이터 세트 메트릭, 기대값, 쿼리 성능을 표시하며 성능 튜닝을 위한 쿼리 프로필에 액세스할 수 있습니다.
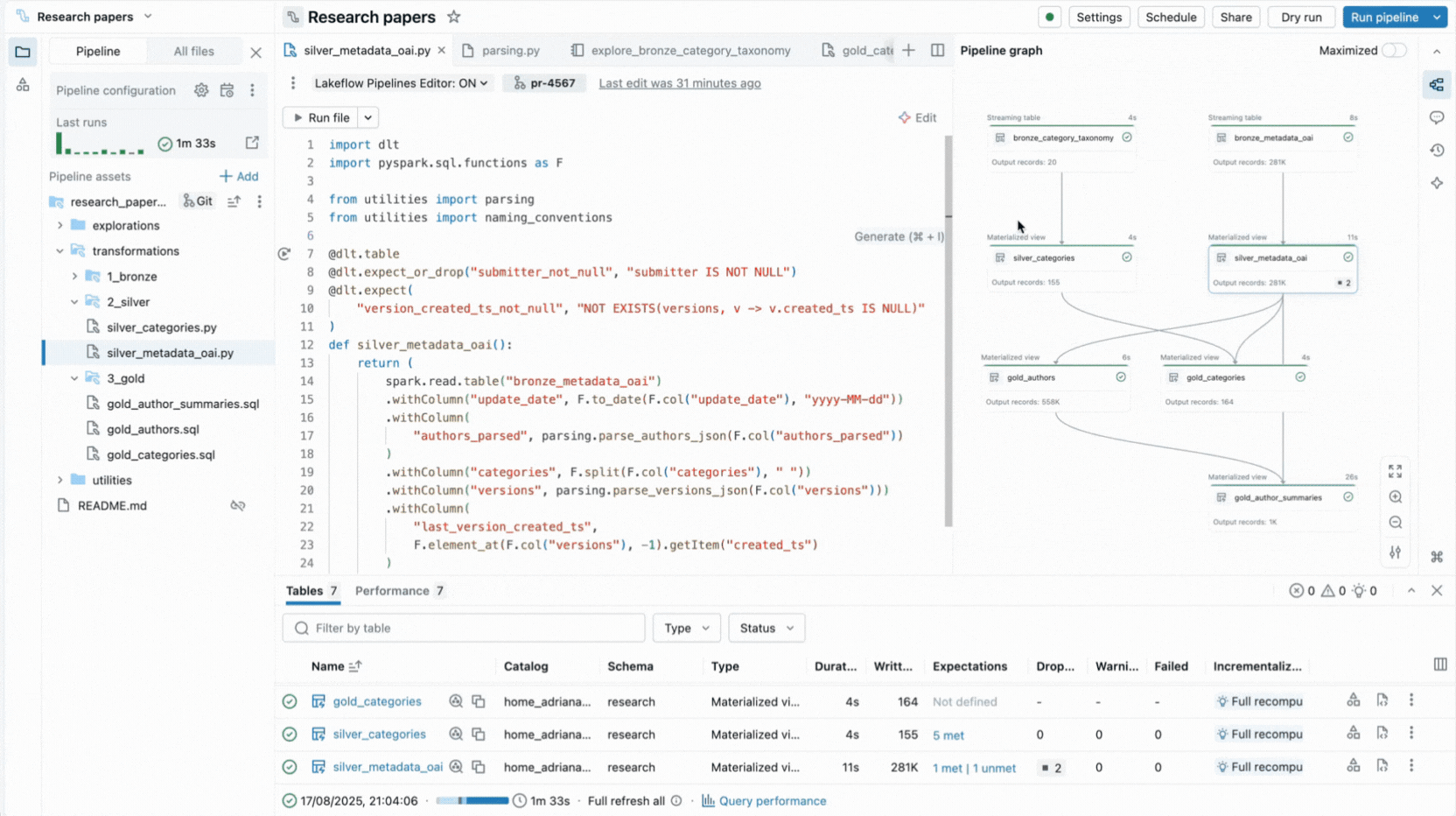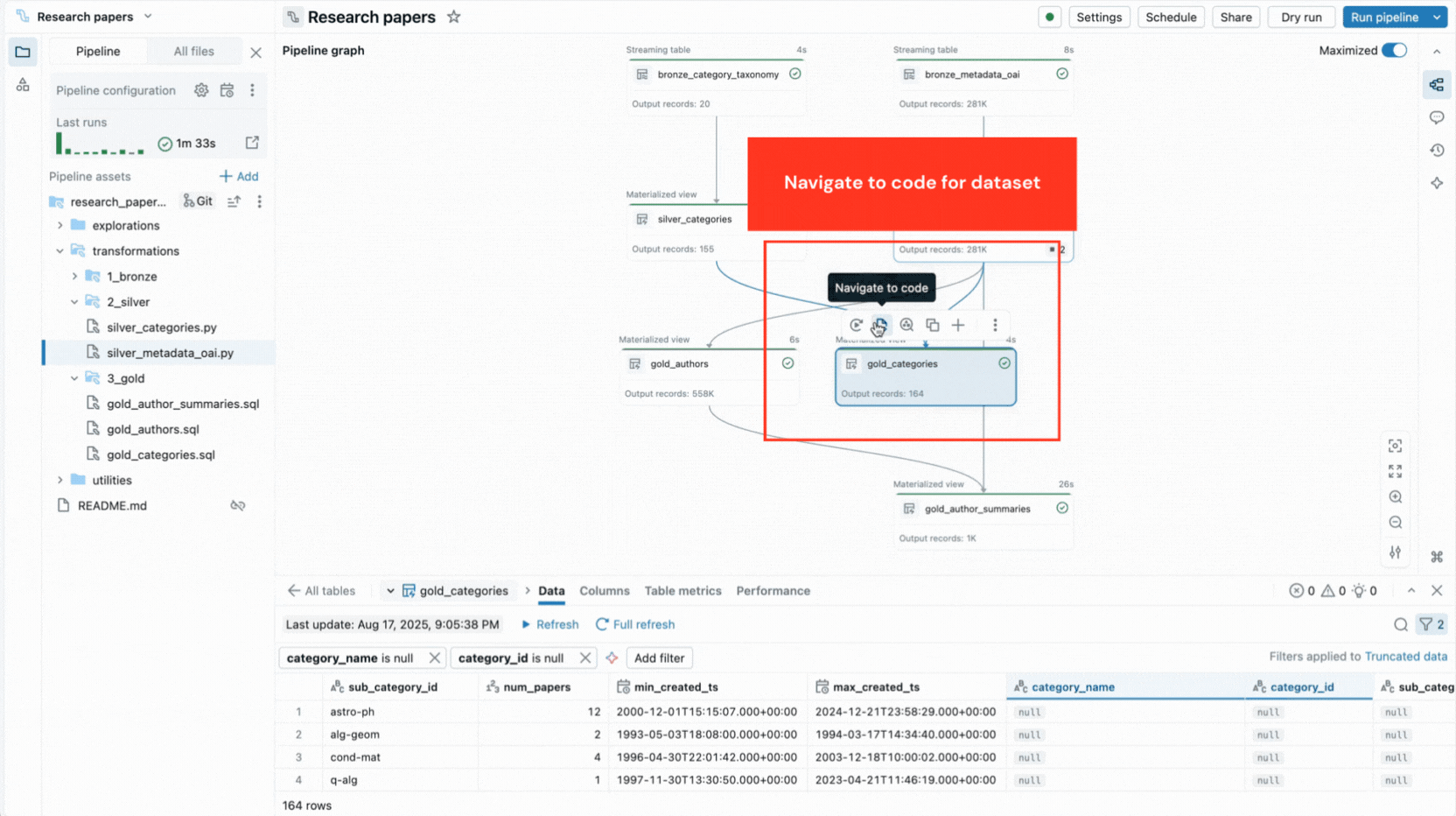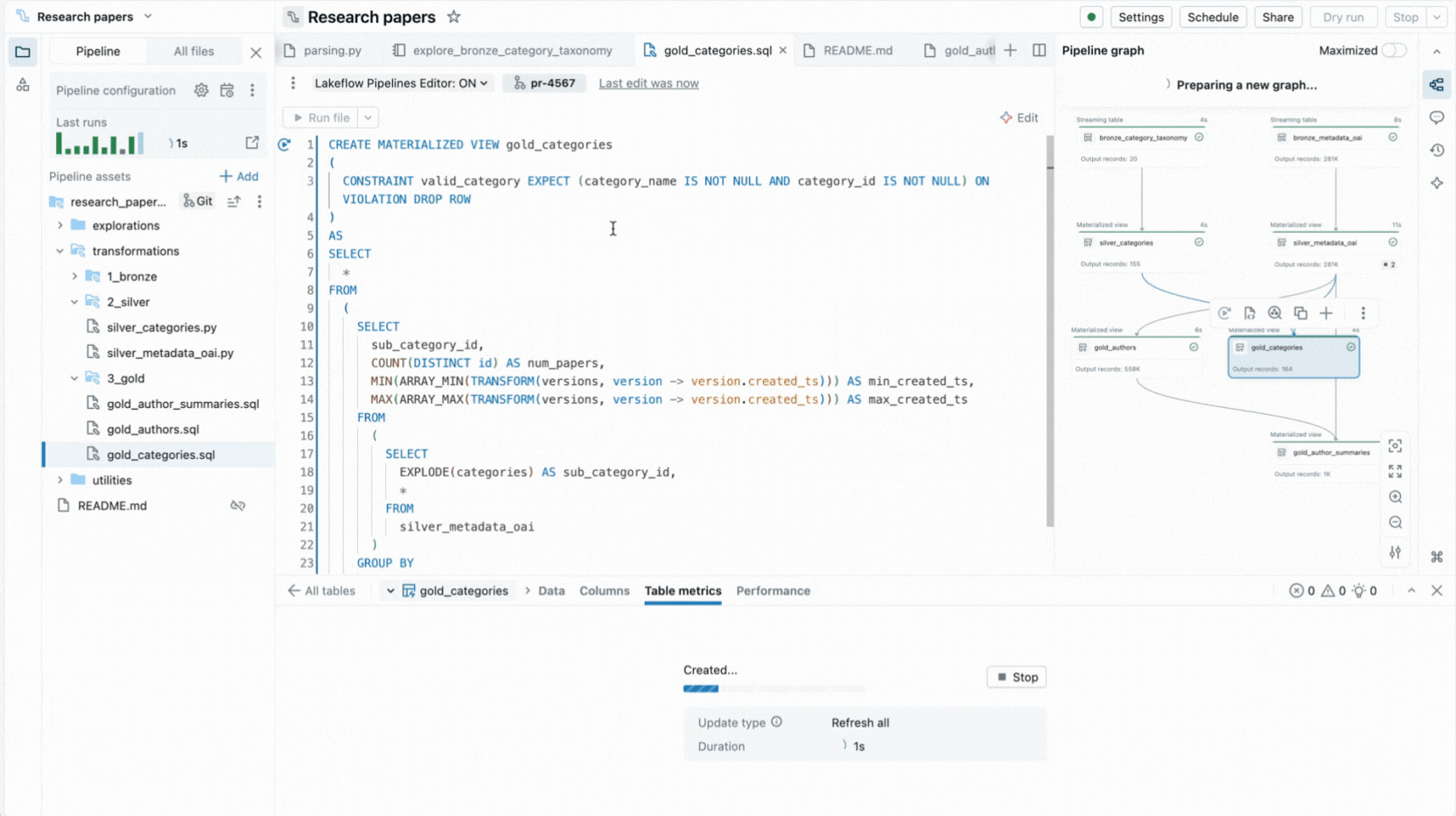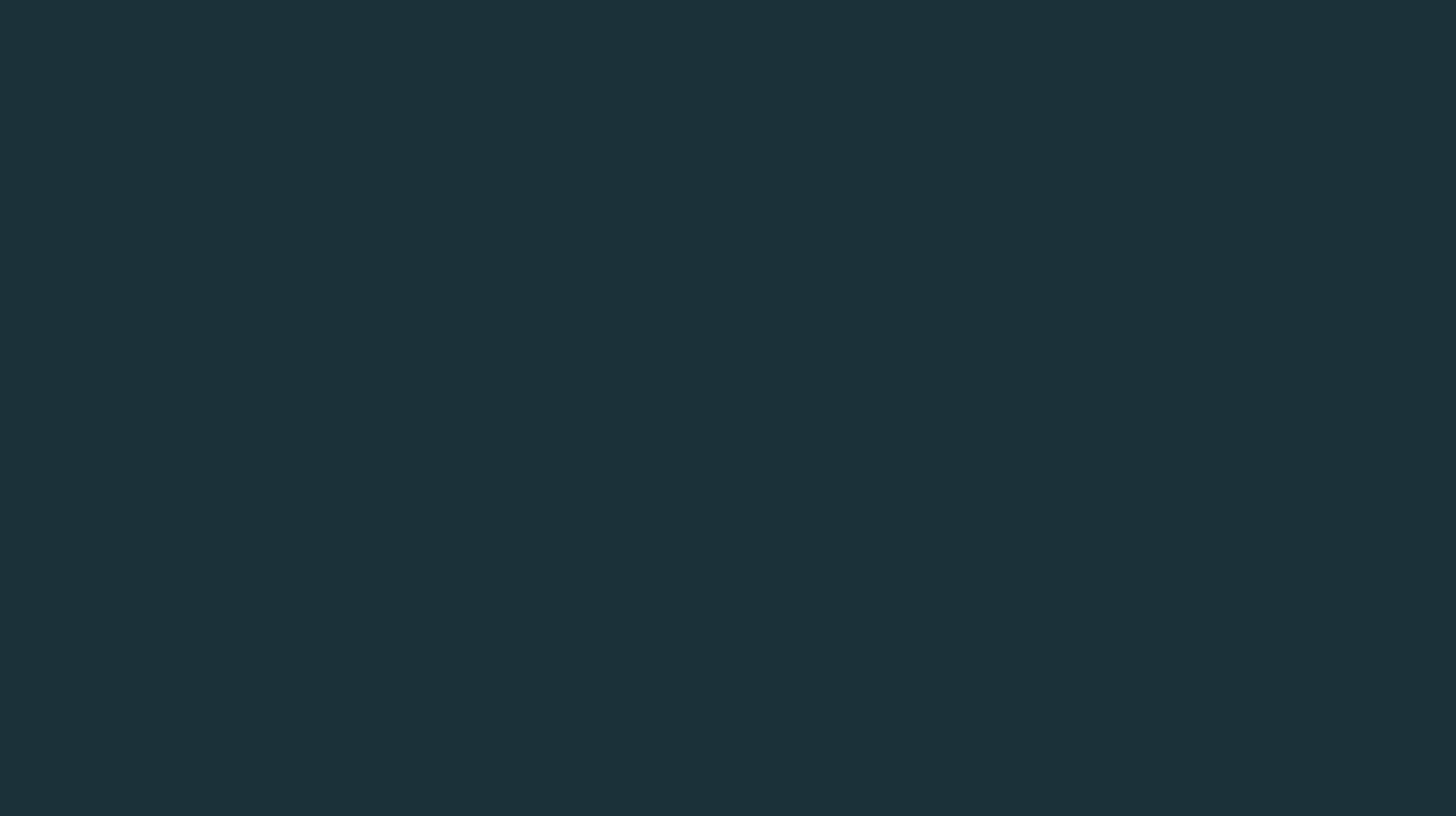
이러한 기능은 컨텍스트 전환을 줄이고 개발자가 파이프라인 논리 구축에 집중하도록 합니다.
모든 작업을 위한 단일 환경
파이프라인 개발은 코드 작성 이상의 것을 포함합니다. 새로운 개발 환경은 유지 관리를 위한 코드 모듈화부터 자동화 및 관찰 가능성 설정까지 모든 관련 작업을 단일 환경으로 가져옵니다.
- 탐색용 노트북이나 재사용 가능한 Python 모듈과 같은 인접 코드를 전용 폴더로 구성하고, 여러 탭에서 파일을 편집하고 파이프라인 논리와 별도로 실행합니다. 이렇게 하면 관련 코드를 쉽게 찾을 수 있고 파이프라인을 깔끔하게 유지할 수 있습니다.
- Git 폴더를 통한 통합 버전 관리로 안전하고 격리된 작업, 코드 검토 및 공유 리포지토리로의 풀 요청을 활성화합니다.
- 파이프라인에 대한 Databricks Asset Bundles 지원을 통한 CI/CD는 내부 루프 개발을 배포에 연결합니다. 데이터 관리자는 데이터 실무자의 워크플로우에 복잡성을 추가하지 않고도 템플릿과 구성 파일을 사용하여 테스트를 적용하고 프로덕션으로의 승격을 자동화할 수 있습니다.
- 내장된 자동화 및 관찰 가능성은 예약된 파이프라인 실행을 가능하게 하고 모니터링 및 문제 해결을 위해 과거 실행에 빠르게 액세스할 수 있도록 합니다.
이러한 기능을 통합함으로써 이 편집기는 일상적인 개발과 장기적인 파이프라인 운영을 모두 간소화합니다.
이 모든 기능이 작동하는 모습에 대한 자세한 내용은 아래 동영상을 확인하세요.
다음 단계
저희는 여기서 멈추지 않습니다. 현재 탐색 중인 내용의 미리보기입니다.
- Lakeflow Spark Declarative Pipelines의 데이터 테스트에 대한 기본 지원 및 편집기의 테스트 실행기
- 검증을 가속화하기 위한 AI 지원 테스트 생성
- Lakeflow Spark Declarative Pipelines용 에이전트 경험.
더 보고 싶은 것이 있다면 알려주세요. 여러분의 피드백이 저희가 구축하는 것을 이끌어갑니다.
지금 바로 새로운 개발 환경 시작하기
데이터 엔지니어링 IDE는 모든 클라우드에서 사용할 수 있습니다. 활성화하려면 기존 파이프라인과 관련된 파일을 열고 'Lakeflow Pipelines Editor: OFF' 배너를 클릭한 다음 토글을 켭니다. 유사한 토글을 사용하거나 사용자 설정 페이지에서 파이프라인 생성 중에 활성화할 수도 있습니다.
이러한 리소스를 사용하여 자세히 알아보세요.
- 설명서를 확인하세요.
- Data + AI Summit 2025의 새로운 편집기를 사용한 데이터 파이프라인 작성 발표를 시청하세요.
- Data + AI Summit 2025의 실제 환경에서의 Lakeflow: 대규모 CI/CD, 테스트 및 모니터링을 확인해 보세요.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.