Dicer 오픈소싱: 데이터브릭스의 자동 샤더
고성능과 저비용으로 대규모의 고가용성 샤딩 서비스 구축
작성자: Atul Adya, 콜린 믹, Jonathan Ellithorpe, 비벡 자인 , Yongxin Xu
- Dicer 오픈 소싱: Databricks에서 빠르고, 확장 가능하며, 가용성이 높은 샤딩 서비스를 구축하는 데 사용되는 기본 자동 샤딩 시스템인 Dicer를 공식적으로 오픈 소싱합니다.
- Dicer란 무엇이며 왜 필요한가: 오늘날 일반적인 서비스 아키텍처의 문제점과 자동 샤더가 필요한 이유, Dicer가 이러한 문제를 해결하는 방법, 그리고 핵심 추상화 및 사용 사례에 대해 설명합니다.
- 성공 사례: 이 시스템은 현재 Unity Catalog 및 SQL 쿼리 오케스트레이션 엔진과 같은 미션 크리티컬 구성 요소를 지원하며, 파드 재시작 중에 가용성 저하를 성공적으로 제거하고 90% 이상의 캐시 적중률을 유지했습니다.
1. 발표
오늘 저희는 가장 중요한 인프라 구성 요소 중 하나이자 짧은 지연 시간, 확장성 및 높은 안정성을 갖춘 샤딩된 서비스를 구축하도록 설계된 기본 시스템인 Dicer: Databricks의 자동 샤더를 오픈소스로 공개하게 되어 기쁩니다. 이는 모든 주요 Databricks 제품의 배후에서 작동하며, 저희가 플릿 효율성을 개선하고 클라우드 비용을 절감하면서 일관되게 빠른 사용자 경험을 제공할 수 있도록 지원합니다. Dicer는 샤딩 할당을 동적으로 관리하여 재시작, 장애, 워크로드 변동 시에도 서비스의 응답성과 복원력을 유지합니다. 이 블로그 게시물에 자세히 설명된 바와 같이, Dicer는 고성능 서빙, 작업 파티셔닝, 배치 파이프라인, 데이터 집계, 멀티테넌시, 소프트 리더 선출, AI 워크로드를 위한 효율적인 GPU 활용 등 다양한 사용 사례에 사용됩니다.
Dicer를 더 넓은 커뮤니티에 공개함으로써 업계 및 학계와 협력하여 견고하고 효율적이며 고성능인 분산 시스템을 구축하는 최신 기술을 발전시키기를 기대합니다. 이 게시물의 나머지 부분에서는 Dicer의 개발 동기 및 설계 철학에 대해 논의하고, Databricks에서의 사용 성공 사례를 공유하며, 시스템을 직접 설치하고 Experiment하는 방법에 대한 가이드를 제공합니다.
2. 동기: 상태 비저장 및 정적 샤딩 아키텍처를 넘어서
데이터브릭스는 데이터 처리, 분석, AI를 위한 제품군을 빠르게 확장하며 제공하고 있습니다. 이를 대규모로 지원하기 위해 저희는 응답성을 유지하면서 방대한 상태를 처리해야 하는 수백 개의 서비스를 운영합니다. 이전에는 데이터브릭스 엔지니어들이 두 가지 일반적인 아키텍처에 의존했지만, 서비스가 성장함에 따라 두 아키텍처 모두 심각한 문제를 야기했습니다.
2.1. 상태 비저장 아키텍처의 숨겨진 비용
Databricks의 대부분의 서비스는 상태 비저장 모델로 시작되었습니다. 일반적인 상태 비저장 모델에서는 애플리케이션이 요청 간에 메모리 내 상�태를 유지하지 않으며, 모든 요청마다 데이터베이스에서 데이터를 다시 읽어야 합니다. 이 아키텍처는 모든 요청이 데이터베이스 히트를 발생시켜 운영 비용과 지연 시간을 모두 증가시키므로 본질적으로 비용이 많이 듭니다 [1].
이러한 비용을 줄이기 위해 개발자들은 데이터베이스의 작업을 오프로드하고자 (Redis나 Memcached 같은) 원격 캐시를 도입하는 경우가 많았습니다. 이를 통해 처리량과 지연 시간이 개선되었지만, 몇 가지 근본적인 비효율성은 해결하지 못했습니다.
- 네트워크 지연 시간: 모든 요청은 캐싱 레이어로의 네트워크 홉이라는 "세금"을 여전히 지불합니다.
- CPU 오버헤드: 데이터가 캐시와 애플리케이션 사이를 이동하면서 (역)직렬화에 상당한 사이클이 낭비됩니다 [2].
- "Overread" 문제: 상태 비저장 서비스는 데이터의 아주 작은 부분만 사용함에도 불구하고 캐시에서 전체 객체나 대용량 블롭을 가져오는 경우가 많습니다. 이러한 overread는 애플리케이션이 방금 가져온 데이터의 대부분을 폐기하므로 대역폭과 메모리를 낭비합니다 [2].
샤딩된 모델로 전환하고 상태를 메모리에 캐싱함으로써 상태를 작동시키는 로직과 직접 같은 위치에 배치하여 이러한 오버헤드 계층을 제거했습니다. 하지만 정적 샤딩은 새로운 문제를 야기했습니다.
2.2. 정적 샤딩의 취약성
Dicer 이전에는 Databricks의 샤딩된 서비스가 정적 샤딩 기술(예: 일관된 해싱)에 의존했습니다. 이 접근 방식은 간단하고 서비스가 메모리에 상태를 효율적으로 캐시할 수 있게 해주었지만, 프로덕션에서 세 가지 심각한 문제를 야기했습니다.
- 재시작 및 자동 확장 중 비가용성: 클러스터 관리자와의 협력 부족은 롤링 업데이트와 같은 유지 관리 운영 중이나 서비스를 동적으로 확장할 때 다운타임 또는 성능 저하로 이어졌습니다. 정적 샤딩 방식은 백엔드 멤버십 변경에 사전에 조정하지 못하고, 노드가 이미 제거된 후에만 반응했습니다.
- 장애 발생 시 스플릿 브레인 및 다운타임 장기화: 중앙 조정이 없으면 Pod가 충돌하거나 간헐적으로 응답하지 않을 때 클라이언트가 백엔드 Pod 집합에 대한 일관성 없는 뷰를 개발할 수 있습니다. 이로 인해 "스플릿 브레인" 시나리오(두 Pod가 동일한 키를 소유했다고 믿는 경우)가 발생하거나 심지어 고객의 트래픽이 완전히 삭제(어떤 Pod도 키를 소유했다고 믿지 않는 경우)되기도 했습니다.
- 핫 키 문제: 정의에 따르면, 정적 샤딩은 부하 변동에 대응하여 동적으로 키 할당의 균형을 재조정하거나 복제를 조정할 수 없습니다. 결과적으로 단일 "핫 키"가 특정 파드를 압도하여 플릿 전체에 연쇄 장애를 trigger할 수 있는 병목 현상을 만듭니다.
수요에 맞춰 서비스가 점점 더 성장함에 따라 결국 정적 샤딩은 끔찍한 아이디어처럼 보였습니다. 이로 인해 엔지니어들 사이에서는 성능 및 리소스 비용을 감수하더라도 상태 비저장 아키텍처가 강력한 시스템을 구축하는 가장 좋은 방법이라는 공통된 믿음이 생겼습니다. 이때쯤 Dicer가 도입되었습니다.
2.3. 샤딩된 서비스 서사 재정의
정적 샤딩의 프로덕션 위험은 상태 비저장(stateless)으로 전환하는 비용과 대조를 이루며 가장 중요한 여러 서비스를 어려운 상황에 놓이게 했습니다. 이러한 서비스는 정적 샤딩을 사용하여 고객에게 빠른 사용자 환경을 제공했습니다. 이를 상태 비저장 모델로 전환하면 추가적인 클라우드 비용은 물론이고 상당한 성능 저하가 발생했을 것입니다.
이를 바꾸기 위해 Dicer를 구축했습니다. Dicer는 서비스의 샤드 할당을 지속적이고 비동기적으로 업데이트하는 지능형 컨트롤 플레인을 도입하여 정적 샤딩의 근본적인 단점을 해결합니다. 이는 애플리케이션 상태, 부하, 종료 알림, 기타 환경 입력을 비롯한 광범위한 신호에 반응합니다. 결과적으로 Dicer는 롤링 재시작, 충돌, 오토스케일링 이벤트 및 심각한 로드 쏠림 기간에도 서비스의 고가용성과 균형을 잘 유지합니다.
자동 샤더인 Dicer는 Centrifuge [3], Slicer [4], Shard Manager [5]를 포함한 기존의 여러 시스템을 기반으로 합니다. 다음 섹션에서는 Dicer를 소개하고, Dicer가 저희 서비스의 성능, 안정성, 효율성 개선에 어떻게 기여했는지 설명�합니다.
3. Dicer: 고성능 및 고가용성을 위한 동적 샤딩
이제 Dicer의 개요, 핵심 추상화 및 다양한 사용 사례에 대해 설명하겠습니다. 향후 블로그 게시물에서 Dicer의 설계와 아키텍처를 기술적으로 자세히 다룰 예정이니 기대해 주세요.
3.1 Dicer 개요
Dicer는 애플리케이션을 논리적 키와 연결된 요청을 처리하거나(또는 다른 작업을 수행하는) 것으로 모델링합니다. 예를 들어, 사용자 프로필을 제공하는 서비스는 사용자 ID를 키로 사용할 수 있습니다. Dicer는 서비스의 고가용성과 로드 밸런싱을 유지하기 위해 키를 포드에 할당하는 작업을 지속적으로 생성하여 애플리케이션을 샤딩합니다.
수백만 또는 수십억 개의 키가 있는 애플리케이션으로 확장하기 위해 Dicer는 개별 키가 아닌 키 범위에서 작동합니다. 애플리케이션은 SliceKey (애플리케이션 키의 해시)를 사용하여 Dicer에 키를 나타내며, 연속적인 SliceKey 범위를 Slice라고 합니다. 그림 1과 같이 Dicer Assignment는 전체 애플리케이션 키스페이스에 걸쳐 있는 Slice의 모음이며, 각 Slice는 하나 이상의 리소스(즉, 포드). Dicer는 애플리케이션 상태 및 로드 신호에 따라 동적으로 Slice를 분할, 병합, 복제 및 재할당하여 전체 키스페이스가 항상 정상 포드에 할당되고 단일 포드에 과부하가 걸리지 않도록 합니다. Dicer는 또한 핫 키를 감지하여 자체 슬라이스로 분할하고 이러한 슬라이스를 여러 포드에 할당하여 부하를 분산할 수 있습니다.
그림 1은 사용자 ID별로 샤딩된 애플리케이션에 대한 3개의 Pod(P0, P1 및 P2)에 걸친 Dicer 할당의 예를 보여줍니다. 여기서 ID 13을 가진 사용자는 SliceKey K26 (즉, ID 13의 해시)으로 표시되며 현재 Pod P0에 할당되어 있습니다. 사용자 ID가 42이고 SliceKey K10 으로 표시되는 핫 유저는 자체 슬라이스에서 격리되어 부하를 처리하기 위해 여러 Pod(P1 및 P2)에 할당되었습니다.

{kind=link}
그림 2는 Dicer와 통합된 샤딩된 애플리케이션의 개요를 보여줍니다. 애플리케이션 파드는 Slicelet (S는 서버 측을 의미)이라는 라이브러리를 통해 현재 할당을 학습합니다. Slicelet은 Dicer 서비스에서 최신 할당을 가져오고 업데이트를 감시하여 로컬 캐시를 유지합니다. 업데이트된 할당을 받으면 Slicelet은 리스너 API를 통해 애플리케이션에 알립니다.
Slicelet이 관찰한 할당은 최종적으로 일관성이 있으며, 이는 강력한 키 소유권 보장보다 가용성과 빠른 복구를 우선시하는 의도적인 설계 선택입니다. 저희 경험상 이는 대다수 애플리케이션에 적합한 모델이었지만, 향후에는 Slicer 및 Centrifuge와 유사하게 더 강력한 보장을 지원할 계획입니다.
할당을 최신 상태로 유지하는 것 외에도 애플리케이션은 키에 대한 요청을 처리하거나 작업을 수행할 때 Slicelet을 사용하여 키별 로드를 기록합니다. Slicelet은 이 정보를 로컬에서 집계하고 Dicer 서비스에 요약을 비동기적으로 보고합니다. 참고로, 할당 감시와 마찬가지로 이 작업도 애플리케이션의 크리티컬 패스 외부에서 발생하여 고성능을 보장합니다.
Dicer 샤딩 애플리케이션의 클라이언트는 Clerk (C는 클라이언트 사이드를 의미)라는 라이브러리를 통해 특정 키에 할당된 파드를 찾습니다. Slicelet과 마찬가지로 Clerk도 백그라운드에서 최신 할당 정보의 로컬 캐시를 적극적으로 유지하여 중요한 경로의 키 조회에 대한 고성능을 보장합니다.

마지막으로 Dicer Assigner 는 애플리케이션 상태 및 부하 신호에 따라 할당을 생성하고 분배하는 컨트롤러 서비스입니다. 핵심에는 Slice 분할, 병합, 복제/복제 해제, 이동을 통해 키를 정상 파드에 할당하고 전체 애플리케이션의 부하를 충분히 분산시키도록 최소한의 조정을 계산하는 샤딩 알고리즘이 있습니다. Assigner 서비스는 멀티 테넌트이며, 한 리전 내의 모든 샤딩된 애플리케이션에 자동 샤딩 서비스를 제공하도록 설계되었습니다. Dicer가 제공하는 각 샤딩된 애플리케이션을 Target이라고 합니다.
3.2 Dicer로 향상된 광범위한 애플리케이션 클래스
Dicer는 워크로드에 대한 파드 어피니티를 설정하는 기능이 상당한 성능 개선을 가져오므로 광범위한 시스템에 유용합니다. 프로덕션 경험을 바탕으로 몇 가지 핵심적인 사용 사례 카테고리를 확인했습니다.
인메모리 및 GPU 서빙
Dicer는 대규모 데이터 코퍼스를 메모리에서 직접 로드하여 제공해야 하는 시나리오에 탁월합니다. 특정 키에 대한 요청이 항상 동일한 파드에 도달하도록 보장함으로써 키-값 저장소와 같은 서비스는 원격 스토리지에서 데이터를 가져오는 오버헤드를 피하면서 밀리초 미만의 지연 시간과 높은 처리량을 달성할 수 있습니다.
Dicer는 어피니티 유지가 중요한 최신 LLM 추론 워크로드에도 매우 적합합니다. 예를 들어 세션별 KV 캐시에 컨텍스트를 축적하는 상태 저장 사용자 세션, 그리고 많은 수의 LoRA 어댑터를 제공하고 이를 제한된 GPU 리소스에 효율적으로 샤딩해야 하는 배포가 있습니다.
제어 및 스케줄링 시스템
이는 Databricks에서 가장 일반적인 사용 사례 중 하나입니다. 여기에는 확장, compute 스케줄링, 멀티테넌시를 관리하기 위해 리소스를 지속적으로 모니터링하는 클러스터 관리자 및 쿼리 오케스트레이션 엔진과 같은 시스템이 포함됩니다. 효율적으로 작동하기 위해 이러한 시스템은 모니터링 및 제어 상태를 로컬에 유지하여 반복적인 직렬화를 피하고 변경에 대한 시기적절한 응답을 가능하게 합니다.
원격 캐시
Dicer는 고성능 분산 원격 캐시를 구축하는 데 사용할 수 있으며, Databricks에서는 이를 프로덕션 환경에서 구축했습니다. Dicer의 기능을 사용하여 캐시를 적중률 손실 없이 원활하게 자동 확장 및 재시작하고 핫 키로 인한 부하 불균형을 방지할 수 있습니다.
작업 분할 및 백그라운드 작업
Dicer는 서버 집합 전반에 걸쳐 백그라운드 작업과 비동기 워크플로를 분할하는 효과적인 도구입니다. 예를 들어, 대규모 테이블에서 상태를 정리하거나 가비지 수집을 담당하는 서비스는 Dicer를 사용하여 각 Pod가 키스페이스의 고유하고 겹치지 않는 범위를 책임지도록 하여 중복 작업 및 잠금 경합을 방지할 수 있습니다.
일괄 처리 및 집계
대용량 쓰기 경로의 경우, Dicer는 효율적인 레코드 집계를 가능하게 합니다. 관련 레코드를 동일한 파드로 라우팅함으로써 시스템은 업데이트를 영구 스토리지에 commit하기 전에 메모리에서 배치할 수 있습니다. 이는 필요한 초당 입출력 작업을 크게 줄이고 데이터 파이프라인의 전체 throughput을 개선합니다.
소프트 리더 선택
Dicer는 특정 파드를 지정된 키 또는 샤드의 기본 코디네이터로 지정하여 "소프트" 리더 선출을 구현하는 데 사용될 수 있습니다. 예를 들어, 서빙 스케줄러는 Dicer를 사용하여 단일 파드가 리소스 그룹을 관리하는 기본 주체 역할을 하도록 보장할 수 있습니다. Dicer는 현재 선호도 기반 리더 선출을 제공하지만, 기존 합의 프로토콜의 과도한 오버헤드 없이 조정된 프라이머리를 필요로 하는 시스템을 위한 강력한 기반 역할을 합니다. 저희는 이러한 워크로드에 대한 상호 배제를 더욱 강력하게 보장하기 위해 향후 개선 사항을 검토하고 있습니다.
랑데부 및 조정
Dicer는 실시간 조정이 필요한 분산 클라이언트를 위한 자연스러운 접점 역할을 합니다. 특정 키에 대한 모든 요청을 동일한 파드로 라우팅함으로써 해당 파드는 외부 네트워크 홉 없이 로컬 메모리에서 공유 상태를 관리할 수 있는 중심지가 됩니다.
예를 들어, 실시간 채팅 서비스에서 동일한 "채팅�방 ID"에 참여하는 두 클라이언트는 자동으로 동일한 파드로 라우팅됩니다. 이를 통해 파드는 공유 데이터베이스나 통신을 위한 복잡한 백플레인의 지연 시간을 피하면서 메모리에서 메시지와 상태를 즉시 동기화할 수 있습니다.
4. 성공 사례
Databricks의 수많은 서비스가 Dicer를 통해 상당한 이점을 얻었으며, 아래에서 이러한 성공 사례 중 몇 가지를 소개합니다.
4.1 Unity Catalog
Unity Catalog(UC)는 Databricks 플랫폼 전반의 데이터 및 AI 자산을 위한 통합 거버넌스 솔루션입니다. 원래 상태 비저장 서비스로 설계된 UC는 인기가 높아짐에 따라 주로 매우 높은 읽기 볼륨으로 인해 상당한 확장 문제에 직면했습니다. 각 요청을 처리하려면 백엔드 데이터베이스에 반복적으로 액세스해야 했으며, 이는 엄청난 지연 시간을 유발했습니다. 원격 캐싱과 같은 기존 접근 방식은 캐시를 증분적으로 업데이트하고 스토리지와 스냅샷 일관성을 유지해야 했기 때문에 실행 가능하지 않았습니다. 또한 고객 카탈로그는 크기가 기가바이트에 달할 수 있으므로 상당한 오버헤드를 유발하지 않고 원격 캐시에 부분 또는 복제 스냅샷을 유지하는 것은 비용이 많이 듭니다.
이 문제를 해결하기 위해 팀은 Dicer를 통합하여 샤딩된 인메모리 상태 저장 캐시를 구축했습니다. 이러한 전환을 통해 UC는 비용이 많이 드는 원격 네트워크 호출을 로컬 메서드 호출로 대체하여 데이터베이스 부하를 크게 줄이고 응답성을 개선할 수 있었습니다. 아래 그림은 Dicer의 초기 출시와 이후 전체 Dicer 통합 배포 과정을 보여줍니다. Dicer의 상태 저장 어피니티를 활용하여 UC는 90~95%의 캐시 적중률을 달성했고, 데이터베이스 왕복 빈도를 크게 낮췄습니다.

{kind=link}
4.2 SQL 쿼리 오케스트레이션 엔진
Spark 클러스터의 쿼리 스케줄링을 관리하는 Databricks의 쿼리 오케스트레이션 엔진은 원래 정적 샤딩을 사용하는 인메모리 상태 저장 서비스로 구축되었습니다. 서비스가 확장됨에 따라 이 아키텍처의 한계는 심각한 병목 현상이 되었습니다. 단순한 구현으로 인해 확장 시 수동 리샤딩이 필요했는데 이는 매우 힘든 작업이었으며, 시스템은 롤링 재시작 중에도 잦은 가용성 저하를 겪었습니다.
Dicer와 통합한 후 이러한 가용성 문제는 해결되었습니다(그림 4 참조). Dicer는 재시작 및 스케일링 이벤트 중 다운타임 제로를 가능하게 하여 팀이 모든 곳에서 오토스케일링을 활성화함으로써 수고를 줄이고 시스템 견고성을 개선할 수 있도록 했습니다. 또한 Dicer의 동적 로드 밸런싱 기능은 고질적인 CPU 스로틀링을 추가로 해결하여 플릿 전반에 걸쳐 더 일관된 성능을 제공했습니다.
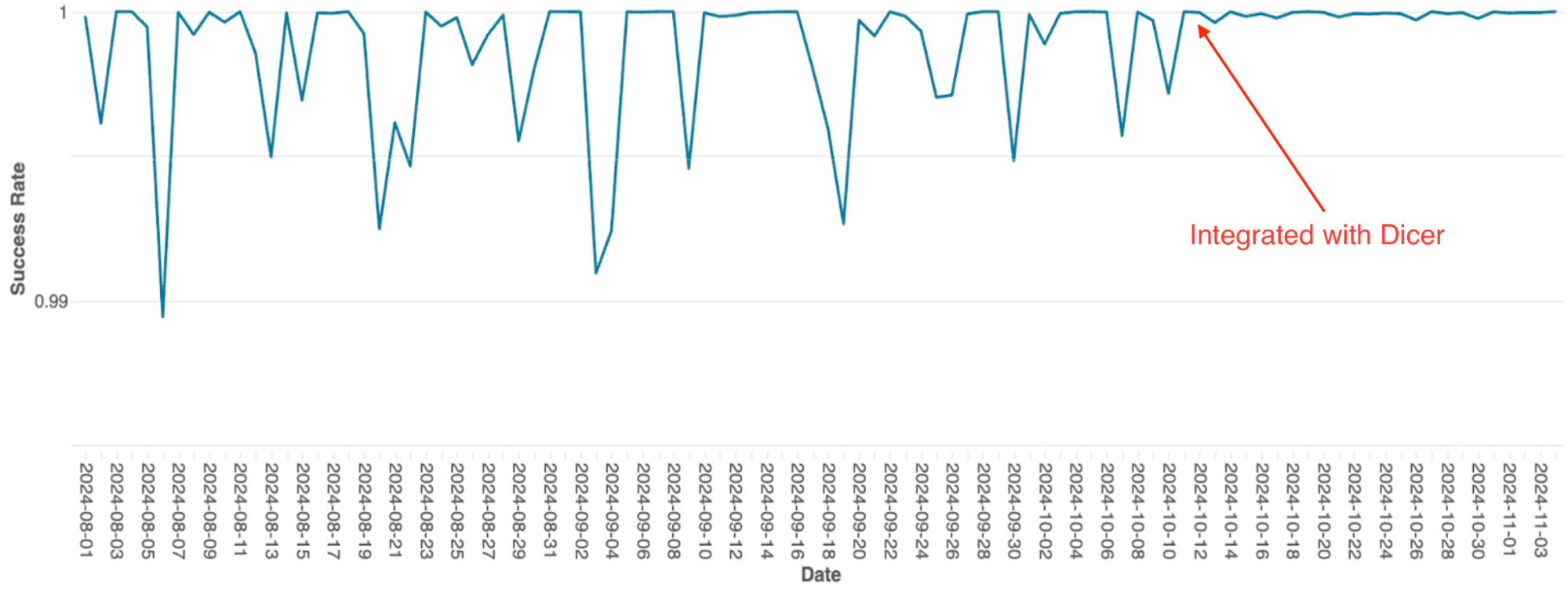
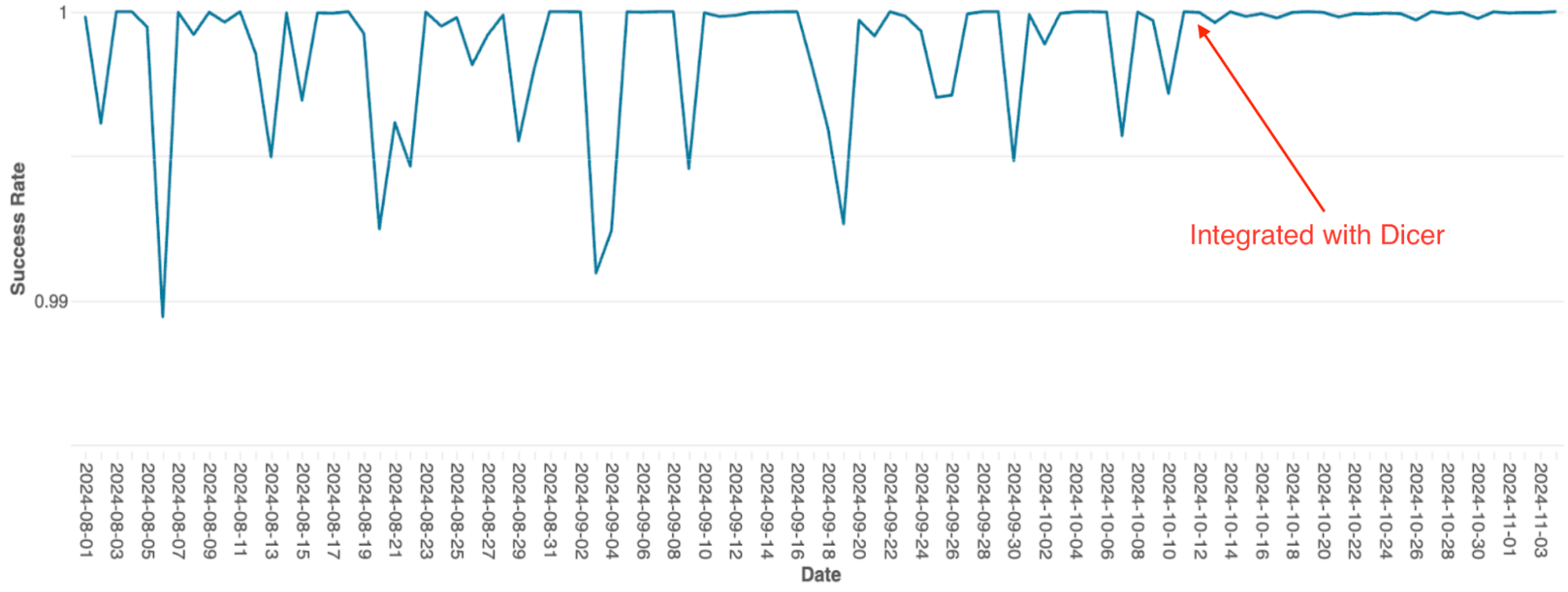{kind=link}
4.3 Softstore 원격 캐시
샤딩되지 않은 서비스를 위해 분산 원격 키-값 캐시인 Softstore를 개발했습니다. Softstore는 상태 전송(state transfer)이라는 Dicer 기능을 활용하며, 이 기능은 리샤딩 중에 파드(pod) 간에 데이터를 마이그레이션하여 애플리케이션 상태를 보존합니다. 이는 전체 키스페이스가 불가피하게 변동되는 계획된 롤링 재시작 중에 특히 중요합니다. 당사의 프로덕션 플릿에서 계획된 재시작은 전체 재시작의 약 99.9%를 차지하므로 이 메커니즘은 특히 영향력이 크며 캐시 적중률에 미미한 영향을 미치면서 원활한 재시작을 가능하게 합니다. 그림 5는 롤링 재시작 중 Softstore 적중률을 보여줍니다. 여기서 상태 전송은 대표적인 사용 사례에 대해 약 85%의 안정적인 적중률을 유지하며 나머지 변동성은 정상적인 워크로드 변동으로 인해 발생합니다.
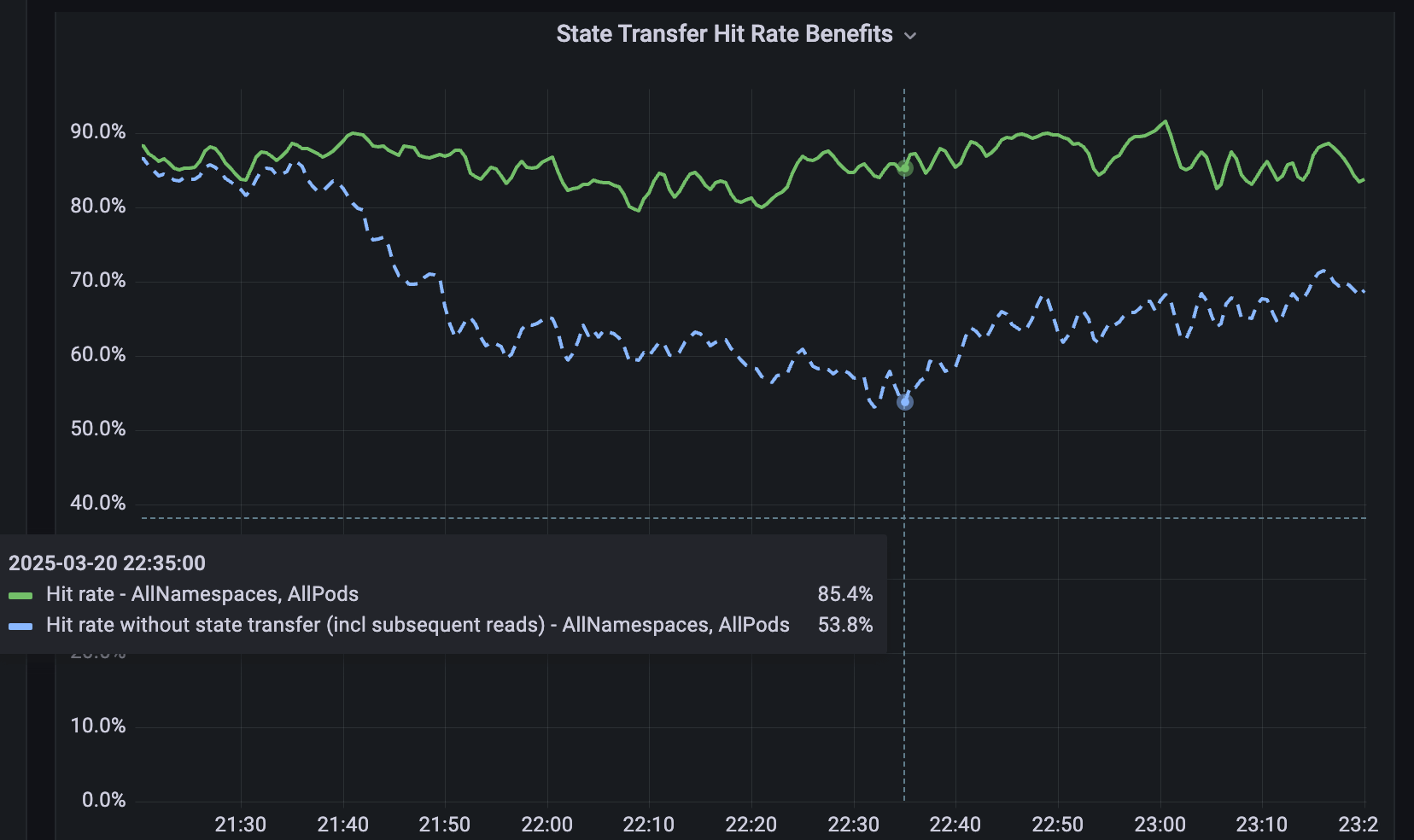
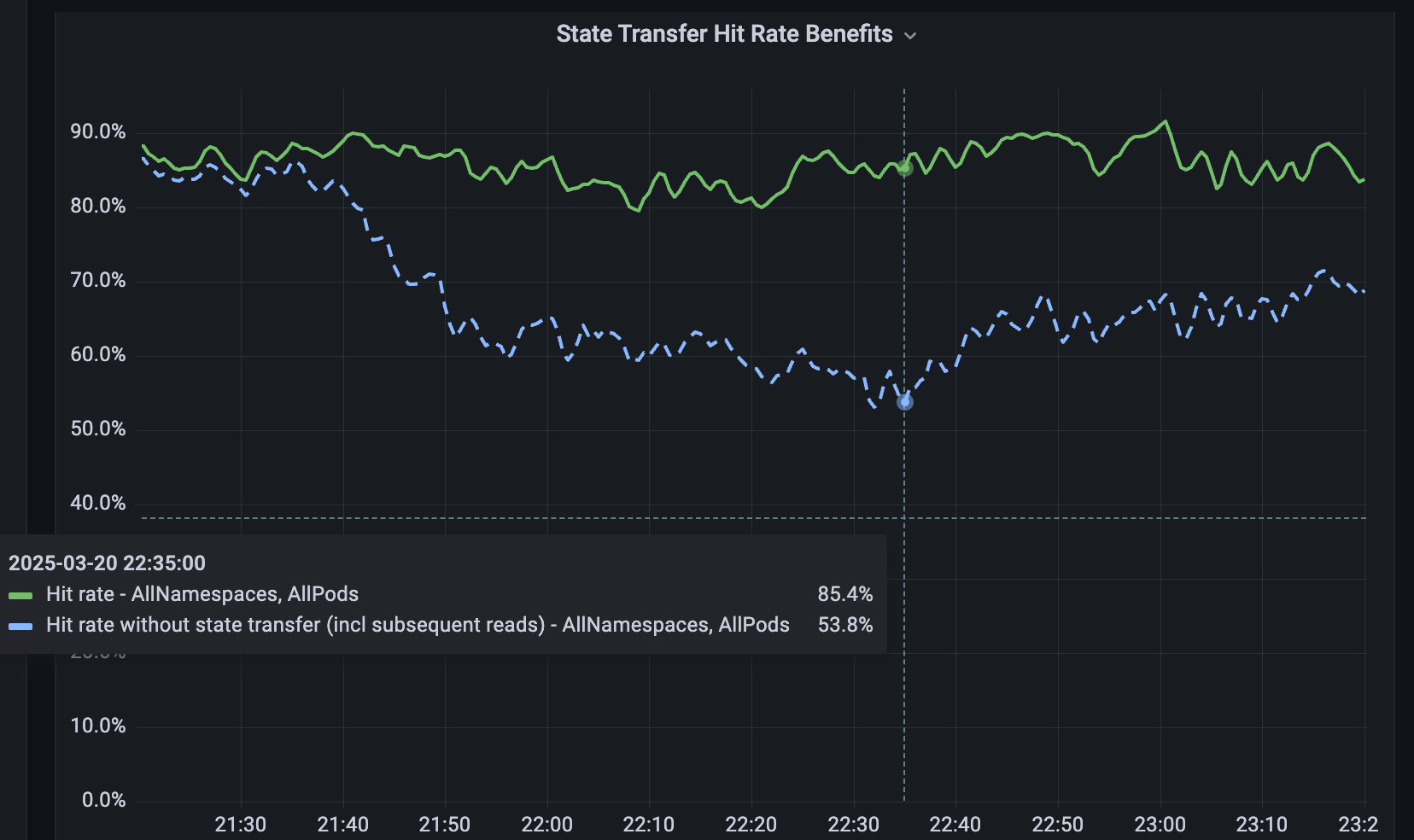{kind=link}
5. 이제 여러분도 사용할 수 있습니다!
지금 바로 여기에서 Dicer를 다운로드하여 사용해 보세요. 여기 에서 사용법을 보여주는 간단한 데모를 제공합니다. 이 데모는 애플리케이션을 위한 하나의 클라이언트와 몇 개의 서버로 구성된 샘플 Dicer 설정을 보여줍니다. Dicer에 대한 README 와 사용자 가이드 를 참조하세요.
6. 출시 예정 기능 및 기사
Dicer는 Databricks 전반에서 사용되는 중요한 서비스이며, 그 사용량이 빠르게 증가하고 있습니다. 앞으로 Dicer의 내부 작동 방식과 설계에 대한 더 많은 기사를 게시할 예정입니다. 또한 내부적으로 기능을 구축하고 테스트하면서 클라이언트 및 서버용 Java 및 Rust 라이브러리, 이 게시물에서 언급된 상태 전송 기능과 같은 더 많은 기능을 출시할 예정입니다. 피드백을 보내주시고 앞으로도 계속 지켜봐 주세요!
어려운 엔지니어링 문제 해결을 즐기고 Databricks에 합류하고 싶다면 databricks.com/careers를 확인해 보세요!
7. 참고 문헌
[1] Ziming Mao, Jonathan Ellithorpe, Atul Adya, Rishabh Iyer, Matei Zaharia, Scott Shenker, Ion Stoica (2025). 데이터센터 서비스를 위한 분산 캐시 비용에 대한 재고찰. 제24회 ACM 네트워크 핫 토픽 워크숍 프로시딩, 1–8.
[2] Atul Adya, Robert Grandl, Daniel Myers, Henry Qin. 빠른 키-값 저장소: 한때 유행했다가 사라진 아이디어. 운영 체제 핫 토픽 워크숍(HotOS '19) 프로시딩, 2019년 5월 13~15일, 이탈리아 베르티노로. ACM, 7페이지. DOI: 10.1145/3317550.3321434.
[3] Atul Adya, James Dunagan, Alexander Wolman. Centrifuge: Integrated Lease Management and Partitioning for 클라우드 Services. Proceedings of the 7th USENIX Symposium on Networked Systems Design and Implementation (NSDI), 2010.
[4] Atul Adya, Daniel Myers, Jon Howell, Jeremy Elson, Colin Meek, Vishesh Khemani, Stefan Fulger, Pan Gu, Lakshminath Bhuvanagiri, Jason Hunter, Roberto Peon, Larry Kai, Alexander Shraer, Arif Merchant, Kfir Lev-Ari. Slicer: 데이터센터 애플리케이션을 위한 자동 샤딩. 제12회 USENIX 운영 체제 설계 및 구현 심포지엄(OSDI) 프로시딩, 2016, pp. 739~753.
[5] Sangmin Lee, Zhenhua Guo, Omer Sunercan, Jun Ying, Chunqiang Tang, et al. Shard Manager: A Generic Shard Management Framework for Geo distributed Applications. Proceedings of the ACM SIGOPS 28th Symposium on Operating Systems Principles (SOSP), 2021. DOI: 10.1145/3477132.3483546.
[6] Atul Adya, Jonathan Ellithorpe. Stateful 서비스: 짧은 지연 시간, 효율성, 확장성 — 세 가지 모두 선택. 고성능 트랜잭션 시스템 워크숍(HPTS) 2024, 캘리포니아주 퍼시픽 그로브, 2024년 9월 15일~18일.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.