PDF를 프로덕션으로: Databricks에서 최첨단 문서 인텔리전스를 발표합니다
ai_parse_document를 사용하면 3~5배 낮은 비용으로 최고의 품질로 SQL에서 직접 PDF를 파싱하고 이해할 수 있습니다.
작성자: Databricks AI 연구팀
- 오늘, Agent Bricks의 최신 추가 기능인 ai_parse_document(공개 프리뷰)를 소개합니다. 이 기능은 대규모 멀티모달 이해를 위한 저희 연구팀의 에이전틱 시스템으로 구동됩니다.
- 최첨단 지능형 문서 처리 기술로 엔터프라이즈 데이터의 80%를 활용하세요. 단일 SQL 함수에 담긴 획기적인 AI 연구의 힘으로 수백만 개의 복잡한 문서(표, 그림, 다이어그램)를 처리합니다.
- 최고의 품질과 비용 경쟁력: 최고의 경쟁사 제품과 대등한 품질의 문서 인텔리전스 시스템을 3~5배 낮은 비용으로 개발했습니다.
- 전체 플랫폼 통합: Spark Declarative 파이프라인을 사용한 자동 증분 처리, Unity Catalog를 사용한 거버넌스, Agent Bricks, AI Search, AIBI 전반에 걸친 원활한 사용을 지원합니다.
이번 Week of Agents 기간 동안 Databricks는 Agent Bricks를 확장합니다. Agent Bricks는 데이터에 대해 정확하게 추론하는 거버넌스가 적용된 프로덕션 지원 AI 에이전트 구축을 위한 Databricks 플랫폼입니다. 기업이 에이전트를 확장할 때 직면하는 가장 큰 과제 중 하나는 비정형 데이터에 대한 액세스입니다. 기업 지식의 약 80%가 에이전트가 읽거나, 이해하거나, 추론할 수 없는 PDF, 보고서, 다이어그램에 갇혀 있습니다. 이러한 문서에는 중요한 컨텍스트가 포함되어 있지만, 지금까지 대부분의 AI 에이전트는 이를 읽을 수 없었습니다.
기존 파싱 도구는 텍스트 추출에 그칩니다. 실제 문서에서 의미를 전달하는 레이아웃, 시각적 요소, 관계를 놓칩니다. 팀들은 실제 데이터에서는 여전히 실패하는 불안정한 사용자 지정 코드를 작성하는 데 몇 달을 소비합니다. ai_parse_document 는 이러한 복잡성을 제거합니다. 완전한 문서 이해 기능을 Databricks Data Intelligence Platform에 직접 통합하여 모든 에이전트가 비즈니스 컨텍스트의 전체 충실도에 정확하고 안전하며 대규모로 액세스할 수 있도록 지원합니다.
단일 SQL 명령으로 문서를 구조화되고 거버넌스가 적용되며 쿼리 가능한 데이터로 변환할 수 있습니다:
결과물은 단순히 PDF의 텍스트뿐만 아니라, layout 정보, 파싱된 테이블, 경계 상자, 캡션이 있는 그림 및 이미지 등 구조화된 정보로서 문서에 대한 포괄적인 설명을 포함합니다.
"Databricks의 ai_parse_document는 구성 오버헤드를 줄여 데이터 사이언티스트가 설정에 소요되는 시간을 줄이고 복잡한 고객 중심 솔루션을 발전시키는 데 더 많은 시간을 할애할 수 있도록 합니다."—Meiling He, Rockwell Automation 수석 Data Science 매니저
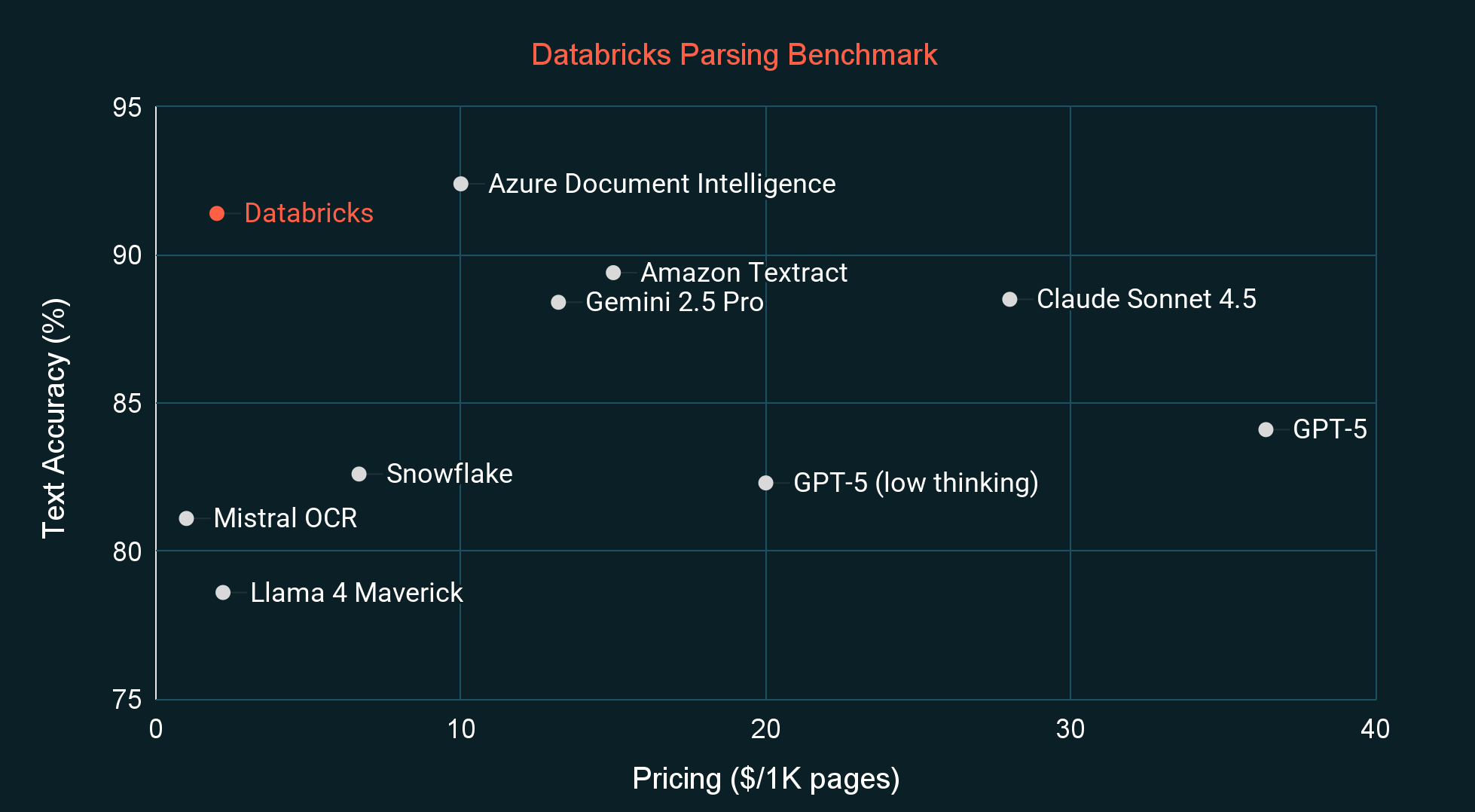
최첨단 가격 대비 성능
다른 최첨단 파싱 시스템 및 비전 언어 모델(VLM)과 비교하여 벤치마킹했을 때, ai_parse_document는 일반적인 외부 벤치마크(OmniOCR)와 자체 내부 벤치마크(아래 그림 참조) 모두에서 측정한 결과 해당 가격대에서 최고의 품질을 자랑합니다. 내부 벤치마크는 고객 문서 분포와 더 유사하며, 모델의 학습 데이터에 포함될 가능성도 낮습니다. 앞으로 몇 주 내에 일부 라벨링 오류를 수정하고 경계 상자 및 계층 구조 정보를 도입한 새로운 OmniOCR 라벨도 공개할 예정입니다.

작동 방식
ai_parse_document 는 AI가 생성한 설명 및 공간 메타데이터와 함께 표, 그림, 다이어그램을 캡처하여 그 결과를 Unity Catalog에 저장합니다. 이제 문서는 테이블처럼 작동하여 AI Search 를 통해 검색하고 Agent Bricks 워크플로에서 실행할 수 있습니다.
“이전에는 PDF나 이미지에서 테이블, 텍스트, 메타데이터를 추출하는 작업이 코드가 많이 필요한 복잡한 프로세스였습니다. Databricks는 이를 단일 SQL 함수인 ai_parse_document로 통합하여 대규모 비정형 데이터 처리를 획기적으로 간소화하고, 데이터 사이언티스트뿐만 아니라 모든 데이터 팀이 사용할 수 있게 했습니다.”—Rajesh Balakrishnan, TE Connectivity 수석 데이터 사이언티스트
하나의 SQL 문으로 고객은 이미 수백만 개의 문서를 병렬로 처리하고 있습니다.
각 결과에는 다음이 포함됩니다.
- Merge된 셀과 중첩 구조를 포함하여 테이블이 보이는 그대로 보존됩니다.
- AI가 생성한 캡션으로 그림과 다이어그램을 자동으로 설명합니다.
- 인용 및 검증을 위한 공간 메타데이터와 경계 상자입니다.
- 멀티모달 검색 또는 시각화를 위해 Unity Catalog 볼륨에 저장되는 선택적 이미지 출력입니다.
모든 것이 Databricks 내부에 유지되므로 일관된 거버넌스, 리니지, 관찰 �가능성을 유지할 수 있습니다.
외부 파서 스택을 다른 Databricks 운영처럼 작동하는 단일 SQL 함수로 교체하세요. 일반적으로 팀에서는 문서를 OCR 서비스, layout 감지 APIs, 그림 캡션 도구로 내보내지만, ai_parse_document 는 Databricks 환경을 벗어나지 않고도 이를 처리합니다:
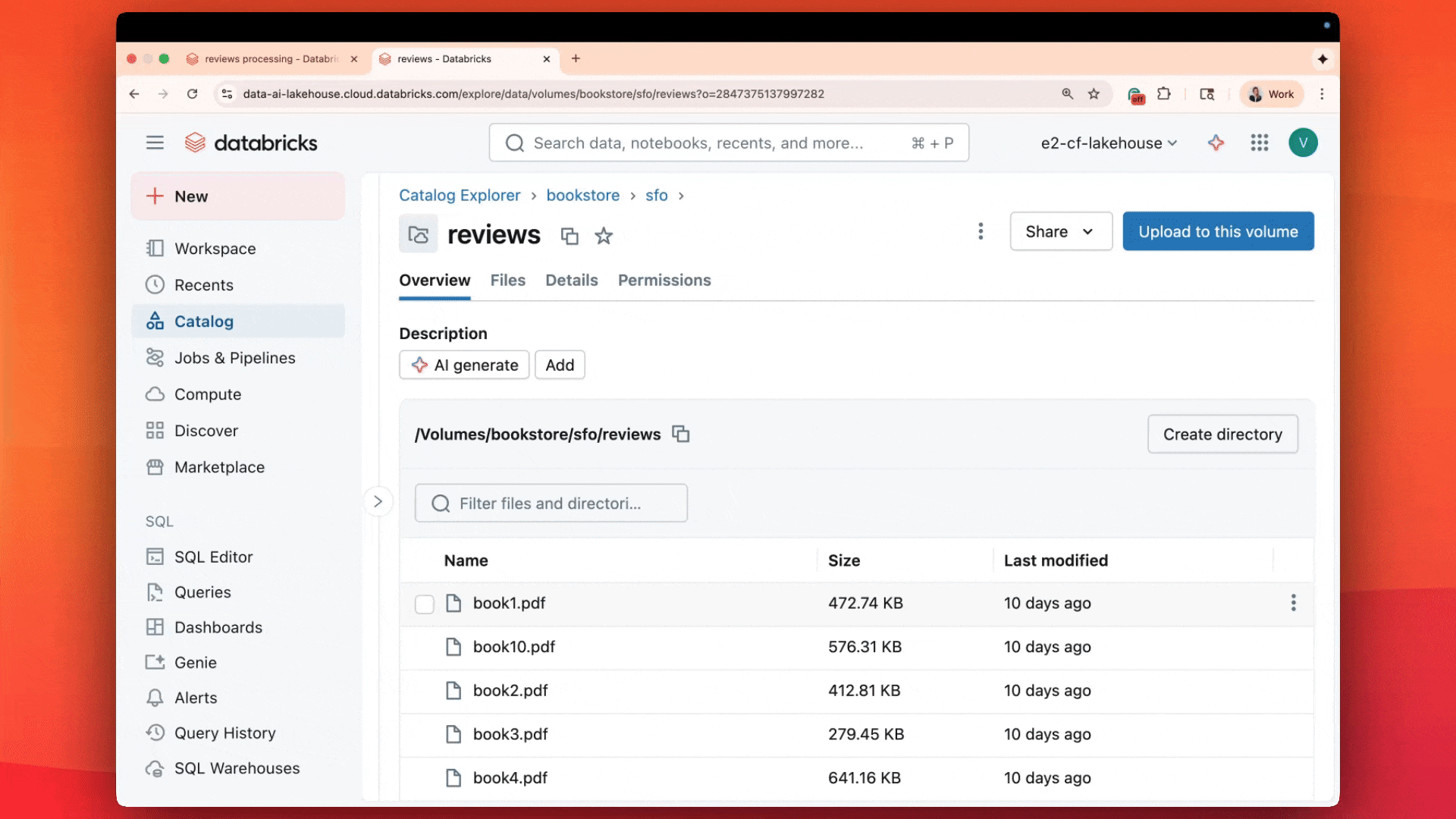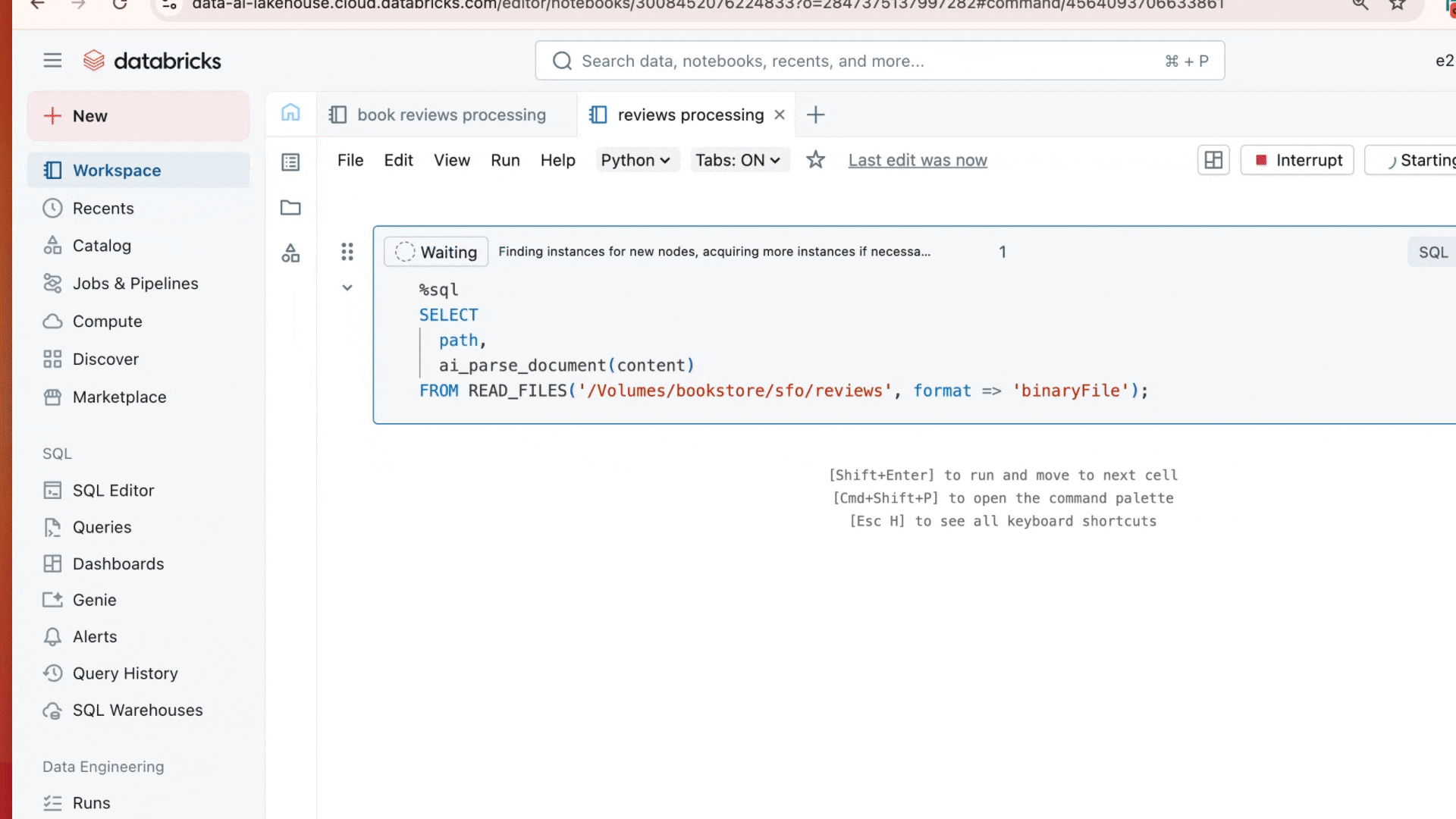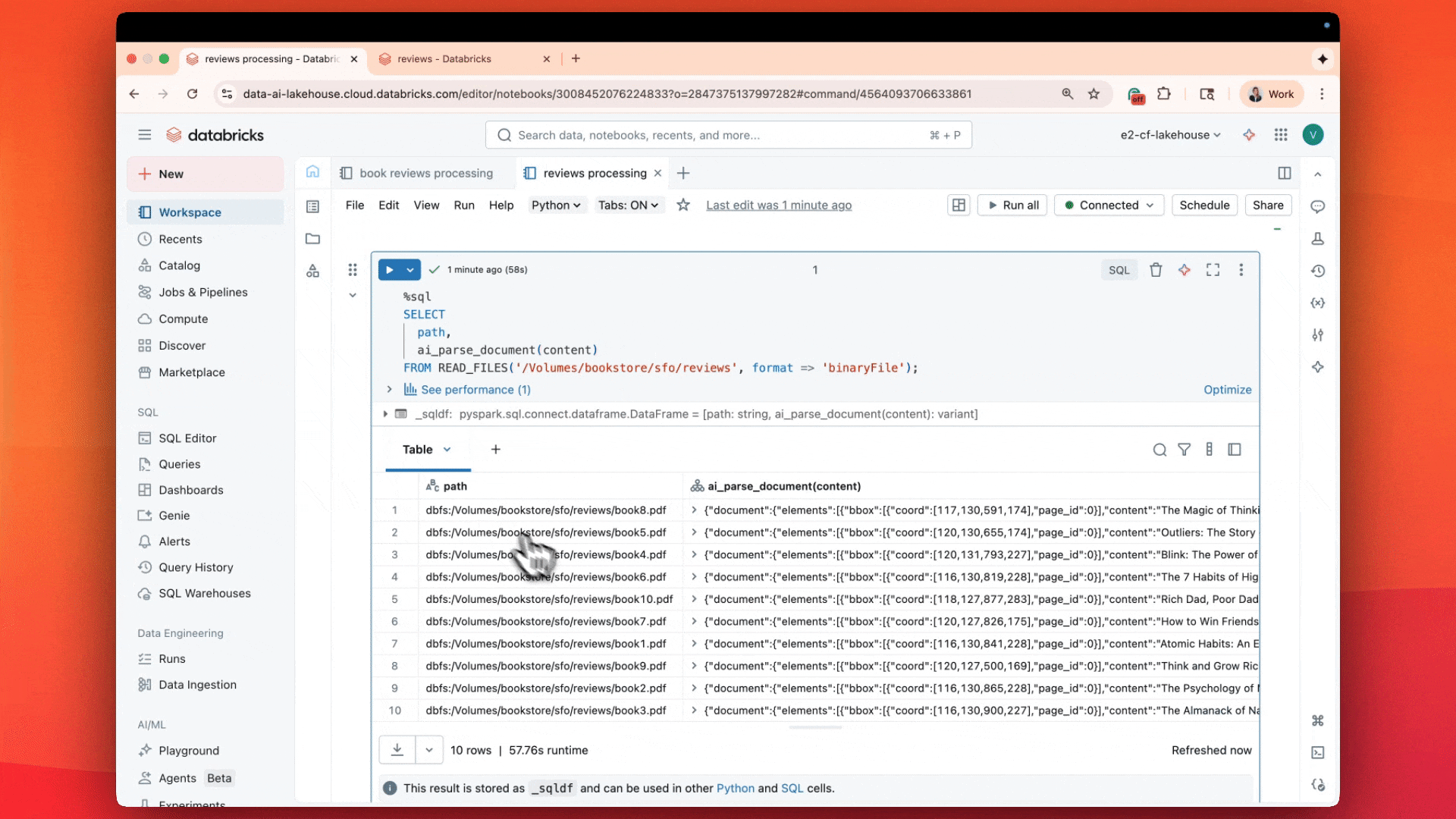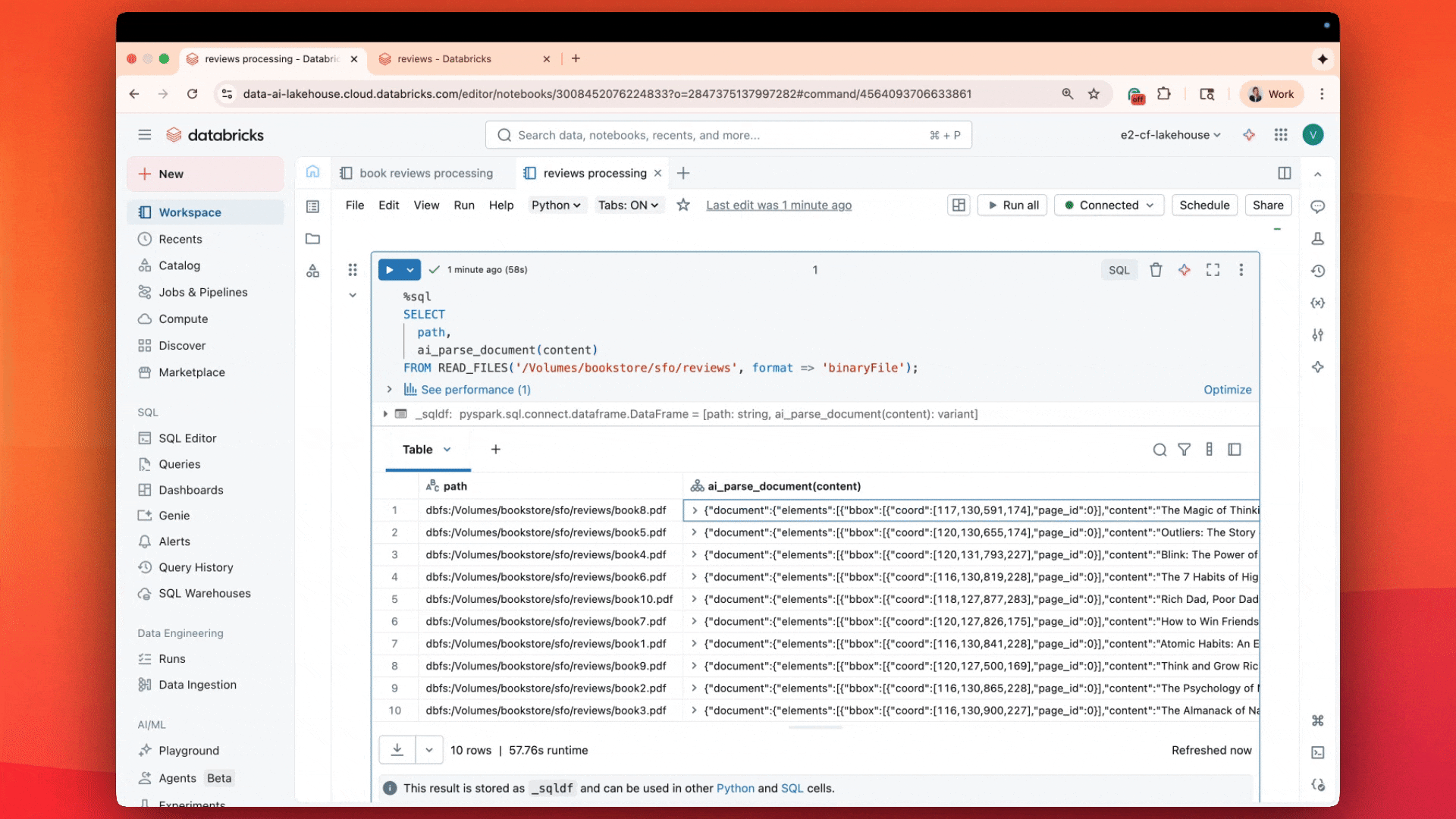
“ai_parse_document는 이미 사용 중인 Delta 테이블 내에서 직접 병렬 문서 파싱을 지원하여 Databricks에서 RAG를 빠르고 간단하게 만들어줍니다.”—Hunter Johnson, Emerson Electric Co. 수석 데이터 사이언티스트
Agent Bricks로 파싱부터 액션까지
파싱이 완료되면 문서 데이터는 나머지 Agent Bricks 생태계로 자연스럽게 흘러갑니다.
- AI Search 는 텍스트와 시각 자료를 모두 이해하는 멀티모달 RAG 애플리케이션을 위해 모든 요소를 인덱싱합니다.
- Declarative Agents 는 자연어를 사용하여 추출, 분류, 요약을 최적화하여 throughput을 개선하고 비용을 절감합니다.
- AI Functions 는 SQL만으로 엔터티를 추출하고, 콘텐츠를 분류하고, 텍스트를 요약합니다.
- Supervisor Agent 는 문서 분석 에이전트를 다른 전문 에이전트와 조율하여 복잡한 다단계 워크플로를 지원합니다.
- AI/BI Dashboards 와 Spark Declarative 파이프라인 는 분석 및 지속적인 처리를 위해 동일한 파싱 데이터를 사용합니다.
이러한 기능들을 통해 비정형 데이터를 Agent Bricks 플랫폼에 완벽하게 통합할 수 있습니다.
프로덕션 규모 및 안정성을 위해 구축됨
많은 기업은 파싱해야 할 수백만 개의 비정형 문서를 보유하고 있으며, 일부는 매일 수백만 개의 문서가 유입되기도 합니다. 며칠씩 걸리지 않고 이 데이터를 안정적으로 확장하여 처리할 수 있는 솔루션이 중요합니다. Databricks는 ai_parse_document 를 Spark Declarative 파이프라인과 통합하여 대규모의 자동 증분 문서 처리를 제공합니다. SharePoint, S3 또는 ADLS 등 어디서든 새로운 문서가 도착하면 자동으로 파싱됩니다. Lakeflow가 재시도, 체크포인트 설정, 확장을 처리하므로 기존 데이터를 다시 처리하거나 사용자 지정 오케스트레이션 코드를 작성할 필요가 전혀 없습니다.
모든 것은 Unity Catalog를 통해 관리되므로, 정형 데이터와 똑같은 방식으로 파싱된 콘텐츠의 권한을 관리하고, 액세스를 감사하며, 리니지를 추적할 수 있습니다.
Agent Bricks로 비정형 데이터 활용
ai_parse_document 는 Agent Bricks AI Functions에 가장 최근에 추가된 기능으로, ai_extract, ai_classify, ai_summarize, ai_query와 같은 기능과 함께 제공됩니다. 이러한 기능들을 함께 사용하면 모든 팀이 Databricks 플랫폼 내에서 직접 모든 엔터프라이즈 데이터에 대해 추론할 수 있습니다. Databricks는 문서 인텔리전스와 기본 내장된 거버넌스, 관찰 가능성, 오케스트레이션을 결합하여 기업이 비즈니스 컨텍스트를 진정으로 이해하고 자신 있게 조치를 취하는 AI 에이전트를 구축할 수 있도록 지원합니다.
비정형 데이터에 숨겨진 가치를 발견할 준비가 되셨나요?
연구 저자(동일 기여): Ziyi Yang, Jasmine Collins, Adyasha Maharana, Cory Stephenson, Erich Elsen, Adam Gurary
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.