RLVR의 힘: Databricks에서 선도적인 SQL 추론 모델 훈련하기
기업 추론을 위한 간단한 레시피
작성자: Databricks AI 연구팀
Databricks에서는 강화 학습(RL)을 사용하여 고객이 직면한 문제와 제품, 예를 들어 Databricks Assistant 와 AI/BI Genie를 위한 추론 모델을 개발합니다. 이러한 작업에는 코드 생성, 데이터 분석, 조직 지식 통합, 도메인 특정 평가, 그리고 문서에서의 정보 추출 (IE)이 포함됩니다. 코딩이나 정보 추출과 같은 작업들은 검증 가능한 보상이 있을 수 있습니다 -- 정확성은 직접 확인할 수 있습니다 (예: 테스트 통과, 라벨 일치). 이를 통해 학습된 보상 모델 없이 강화 학습을 할 수 있으며, 이를 RLVR (검증 가능한 보상을 가진 강화 학습)라고 합니다. 다른 도메인에서는 맞춤형 보상 모델이 필요할 수 있습니다 -- 이는 Databricks도 지원합니다. 이 포스트에서는 RLVR 설정에 초점을 맞춥니다.
RLVR의 힘을 보여주는 예로, 우리는 데이터 과학에서 인기 있는 학문적 벤치마크인 BIRD에 훈련 스택을 적용했습니다. 이 벤치마크는 자연어 쿼리를 데이터베이스에서 실행되는 SQL 코드로 변환하는 작업을 연구합니다. 이는 Databricks 사용자에게 중요한 문제로, SQL 전문가가 아닌 사람들이 데이터와 대화할 수 있게 합니다. 이는 최고의 독점적인 LLM들조차도 박스에서 잘 작동하지 않는 어려운 작업입니다. BIRD는 이 작업의 실제 세계 복잡성을 완전히 포착하지는 못하며 Databricks AI/BI Genie와 같은 실제 제품의 전체 범위를 포착하지는 못하지만, 그 인기도는 우리가 데이터 과학에 대한 RLVR의 효과성을 잘 이해된 벤치마크에서 측정할 수 있게 합니다.
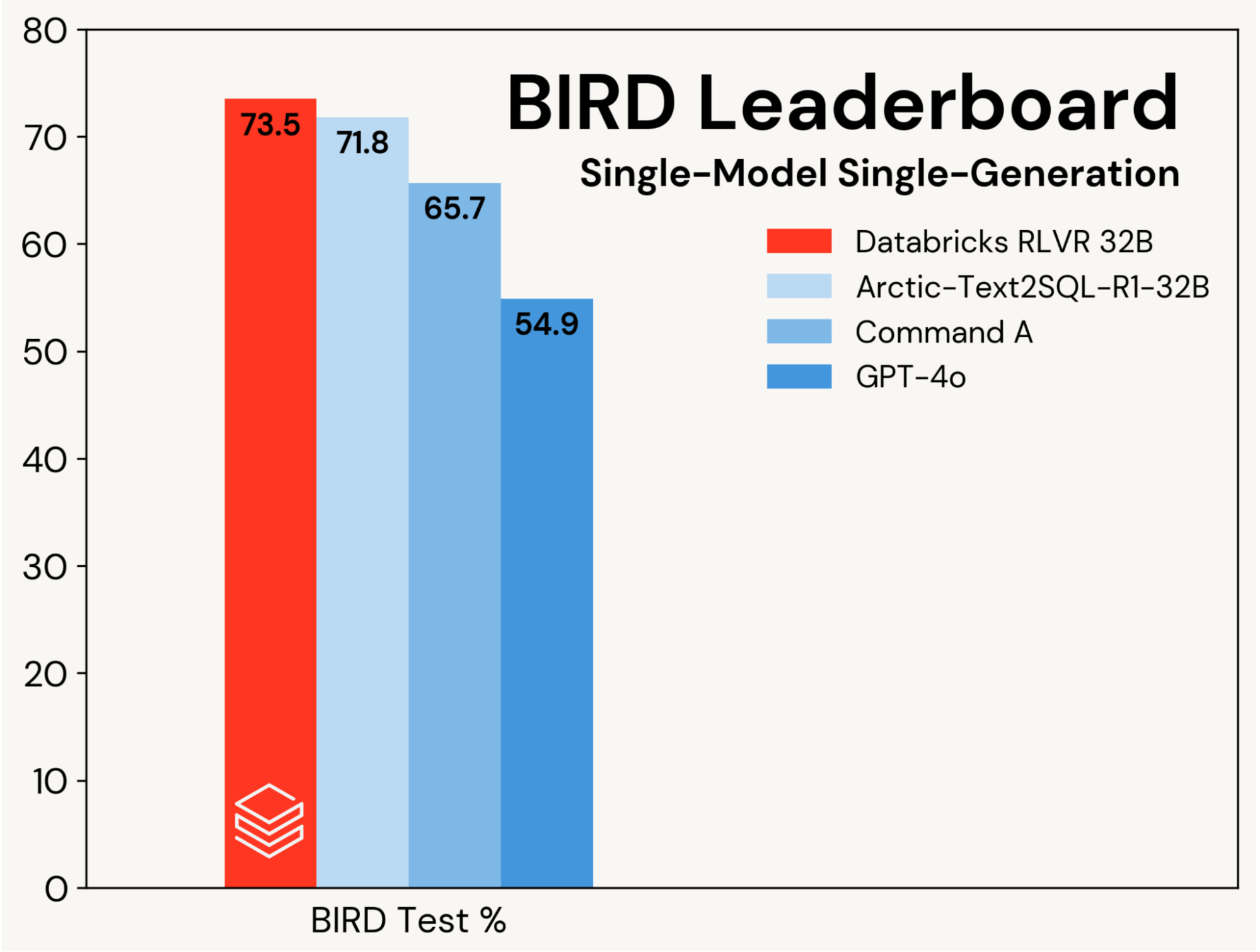
우리는 RLVR을 사용하여 기본 SQL 코딩 모델을 개선하는 데 초점을 맞추며, 이러한 이득을 에이전트 설계에 의해 주도되는 개선으로부터 분리합니다. 진행 상황은 BIRD 리더보드의 단일 모델, 단일 세대 트랙에서 측정되며, 이는 개인 테스트 세트에서 평가합니다.
우리는 이 벤치마크에서 새로운 최고의 테스트 정확도인 73.5%를 설정했습니다. 우리는 표준 RLVR 스택을 사용하고 BIRD 훈련 세트에서만 훈련하여 이를 달성했습니다. 이 트랙에서 이전 최고 점수는 71.8%[1]로, 추가 데이터를 사용하여 BIRD 훈련 세트를 확장하고 독점적인 LLM (GPT-4o)을 사용하여 달성되었습니다. 우리의 점수는 또한 원래의 기본 모델보다 8.7 퍼센트 포인트 더 좋고, 독점적인 LLM들에 비해 상당한 개선입니다 (그림 2 참조). 이 결과는 RLVR의 단순성과 일반성을 보여줍니다: 우리는 일반적인 데이터와 우리가 Agent Bricks에서 출시하는 표준 RL 구성 요소를 사용하여 이 점수를 달성했고, 우리는 BIRD에 첫 제출로 이를 달성했습니다. RLVR은 충분한 훈련 데이터가 있는 경우 AI 개발자들이 고려해야 할 강력한 기준입니다.
우리는 BIRD 개발 세트를 기반으로 제출물을 구성했습니다. 우리는 Qwen 2.5 32B Coder Instruct가 가장 좋은 시작점이라는 것을 발견했습니다. 우리는 이 모델을 Databricks TAO – 오프라인 RL 방법, 그리고 우리의 RLVR 스택을 사용하여 세밀하게 조정했습니다. 이 접근법과 신중한 프롬프트와 모델 선택은 우리를 BIRD 벤치마크의 정상으로 이끌었습니다. 이 결과는 우리가 AI/BI Genie와 어시스턴트와 같은 인기 있는 Databricks 제품을 개선하고 고객이 Agent Bricks를 사용하여 에이전트를 구축하는 데 도움을 주는 동일한 기술의 공개적인 시연입니다.
우리의 결과는 RLVR의 힘과 우리의 훈련 스택의 효과성을 강조합니다. Databricks 고객들도 그들의 추론 도메인에서 우리의 스택을 사용하여 훌륭한 결과를 보고했습니다. 우리는 이 레시피가 강력하고, 조합 가능하며, 다양한 작업에 널리 적용 가능하다고 생각합니다. Databricks에서 RLVR을 미리 보고 싶다면 여기에서 연락해 주세요.
1표 1을 참조하십시오 https://arxiv.org/pdf/2505.20315
저자: 알누르 알리, 아슈토시 바헤티, 조나단 창, 타-충 치, 브랜든 쿠이, 앤드류 드로즈도프, 조나단 프랭클, 아배이 구프타, 팔라비 코폴, 숀 쿨린스키, 조나단 리, 디펜드라 쿠마르 미스라, 호세 하비에르 곤잘레스 오르티즈, 크리스타 옵사흘-옹
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.