기본 키 및 외래 키 제약 조건이 GA가 되어 이제 더 빠른 쿼리가 가능합니다.
작성자: Xinyi Yu, 저스틴 탤벗 , Serge Rielau
Databricks에서 Primary Key (PK) 및 Foreign Key (FK) 제약 조건의 일반 공급(GA)을 발표하게 되어 기쁩니다. 이는 Databricks Runtime 15.2 및 Databricks SQL 2024.30부터 적용됩니다. 이번 릴리스는 수백 명의 주간 활성 고객이 사용한 매우 성공적인 공개 미리 보기 이후에 나왔으며, Lakehouse 내에서 데이터 무결성과 관계형 데이터 관리를 강화하는 중요한 이정표를 더욱 나타냅니다.
또한 Databricks는 이제 이러한 제약 조건을 사용하여 쿼리를 최적화하고 쿼리 계획에서 불필요한 작업을 제거하여 훨씬 더 빠른 성능을 제공할 수 있습니다.
Primary Key 및 Foreign Key 제약 조건
Primary Key (PK)와 Foreign Key (FK)는 관계형 데이터베이스의 필수 요소이며 데이터 모델링을 위한 기본 빌딩 블록 역할을 합니다. 스키마의 데이터 관계에 대한 정보를 사용자, 도구 및 애플리케이션에 제공하며, 쿼리 속도를 높이기 위해 제약 조건을 활용하는 최적화를 가능하게 합니다. Primary Key와 Foreign Key는 이제 Unity Catalog에서 호스팅되는 Delta Lake 테이블에 대해 일반 공급됩니다.
SQL 언어
테이블을 만들 때 제약 조건을 정의할 수 있습니다.
위 예시에서는 UserID 열에 Primary Key 제약 조건을 정의했습니다. Databricks는 여러 열 그룹에 대한 제약 조건도 지원합니다.
기존 Delta 테이블을 수정하여 제약 조건을 추가하거나 제거할 수도 있습니다.
여기서는 기존 테이블의 null이 아닌 열 ProductID에 products_pk라는 Primary Key를 생성합니다. 이 작업을 성공적으로 실행하려면 테이블 소유자여야 합니다. 제약 조건 이름은 스키마 내에서 고유해야 합니다.
이후 명령은 이름을 지정하여 Primary Key를 제거합니다.
Foreign Key에도 동일한 프로세스가 적용됩니다. 다음 테이블은 테이블 생성 시 두 개의 Foreign Key를 정의합니다.
제약 조건과 관련된 구문 및 작업에 대한 자세한 내용은 CREATE TABLE 및 ALTER TABLE 문에 대한 문서를 참조하십시오.
Primary Key 및 Foreign Key 제약 조건은 Databricks 엔진에서 적용되지 않지만, 참이어야 하는 데이터 무결성 관계를 나타내는 데 유용할 수 있습니다. Databricks는 대신 수집 파이프라인의 일부로 Primary Key 제약 조건을 적용할 수 있습니다. 적용되는 제약 조건에 대한 자세한 내용은 Delta Live Tables를 사용한 관리형 데이터 품질을 참조하십시오. Databricks는 또한 적용되는 NOT NULL 및 CHECK 제약 조건을 지원합니다(자세한 내용은 제약 조건 설명서 참조).
파트너 생태계
최신 버전의 Tableau 및 PowerBI와 같은 도구 및 애플리케이션은 JDBC 및 ODBC 커넥터를 통해 Databricks에서 Primary Key 및 Foreign Key 관계를 자동으로 가져와 활용할 수 있습니다.
제약 조건 보기
테이블에 정의된 Primary Key 및 Foreign Key 제약 조건을 보는 몇 가지 방법이 있습니다. DESCRIBE TABLE EXTENDED 명령을 사용하여 SQL 명령으로 제약 조건 정보를 볼 수도 있습니다.
카탈로그 탐색기 및 개체 관계 다이어그램
카탈로그 탐색기를 통해 제약 조건 정보를 볼 수도 있습니다.
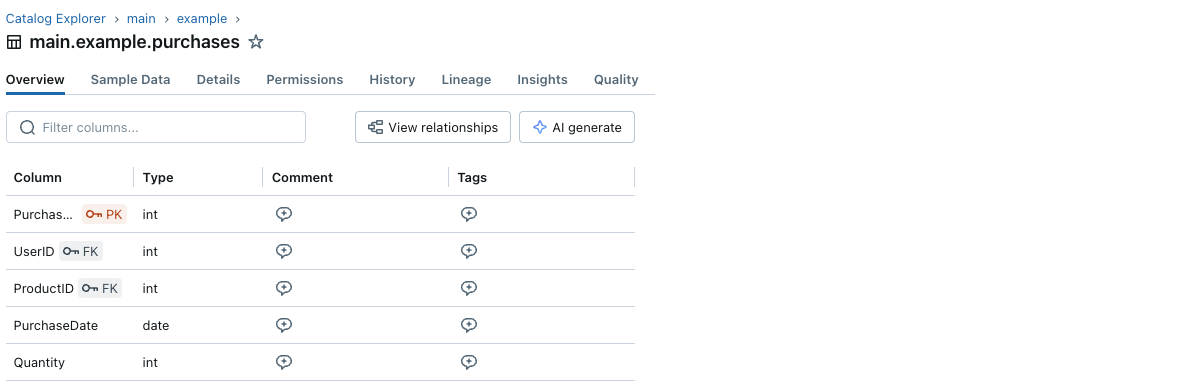
각 Primary Key 및 Foreign Key 열 옆에는 작은 키 아이콘이 있습니다.
또한 카탈로그 탐색기의 개체 관계 다이어그램을 사용하여 Primary Key 및 Foreign Key 정보와 테이블 간의 관계를 시각화할 수 있습니다. 다음은 users 및 products 테이블을 참조하는 purchases 테이블의 예입니다.

정보 스키마
다음 INFORMATION_SCHEMA 테이블도 제약 조건 정보를 제공합니다.
TABLE_CONSTRAINTS: 카탈로그 내의 모든 Primary Key 및 Foreign Key 제약 조건에 대한 메타데이터를 설명합니다.KEY_COLUMN_USAGE: 카탈로그 내의 Primary Key 또는 Foreign Key 제약 조건의 열을 나열합니다.CONSTRAINT_TABLE_USAGE: 카탈로그에서 테이블을 참조하는 제약 조건을 설명합니다.CONSTRAINT_COLUMN_USAGE: 카탈로그에서 열을 참조하는 제약 조건을 설명합니다.REFERENTIAL_CONSTRAINTS: 카탈로그에 정의된 참조(Foreign Key) 제약 조건을 설명합니다.
RELY 옵션을 사용하여 최적화 활성화
Primary Key 제약 조건이 유효하다는 것을 알고 있다면(예: 데이터 파이프라인 또는 ETL 작업에서 적용하는 경우), RELY 옵션을 지정하여 제약 조건을 기반으로 최적화를 활성화할 수 있습니다. 예를 들면 다음과 같습니다.
RELY 옵션을 사용하면 데이터 무결성이 유지된다고 보장하므로 Databricks는 제약 조건의 유효성에 따라 쿼리를 최적화할 수 있습니다. 제약 조건이 RELY로 표시되었지만 데이터가 제약 조건을 위��반하는 경우 쿼리 결과가 잘못될 수 있으므로 주의해서 사용하십시오.
제약 조건에 RELY 옵션을 지정하지 않으면 기본값은 NORELY이며, 이 경우 제약 조건은 정보 또는 통계 목적으로 사용될 수 있지만 쿼리는 올바르게 실행하기 위해 제약 조건에 의존하지 않습니다.
RELY 옵션과 이를 활용하는 최적화는 현재 Primary Key에 사용할 수 있으며, 곧 Foreign Key에도 제공될 예정입니다.
ALTER TABLE을 사용하여 테이블의 Primary Key를 수정하여 RELY 또는 NORELY인지 변경할 수 있습니다. 예를 들면 다음과 같습니다.
불필요한 집계를 제거하여 쿼리 속도 향상
RELY Primary Key 제약 조건을 사용하여 수행할 수 있는 간단한 최적화 중 하나는 불필요한 집계를 제거하는 것입니다. 예를 들어, RELY를 사용하는 Primary Key가 있는 테이블에 대해 DISTINCT 작업을 적용하는 쿼리에서:
불필요한 DISTINCT 작업을 제거할 수 있습니다.
보시다시피 이 쿼리는 RELY Primary Key 제약 조건의 유효성에 의존합니다. customer 테이블에 중복된 customer ID가 있는 경우 변환된 쿼리는 잘못된 중복 결과를 반환합니다. RELY 옵션을 설정하는 경우 제약 조건의 유효성을 적용할 책임이 있습니다.
기본 키가 NORELY(기본값)인 경우 옵티마이저는 쿼리에서 DISTINCT 연산을 제거하지 않습니다. 그러면 실행 속도가 느려질 수 있지만 중복이 있더라도 항상 올바른 결과를 반환합니다. 기본 키가 RELY인 경우 Databricks는 DISTINCT 연산을 제거하여 쿼리 속도를 크게 높일 수 있습니다. 위의 예에서는 약 2배 빨라집니다.
불필요한 조인을 제거하여 쿼리 속도 높이기
RELY 기본 키로 수행할 수 있는 또 다른 매우 유용한 최적화는 불필요한 조인을 제거하는 것입니다. 쿼리가 조인 조건 외에는 어디에서도 참조되지 않는 테이블을 조인하는 경우 옵티마이저는 조인이 불필요하다고 판단하여 쿼리 계획에서 조인을 제거할 수 있습니다.
예를 들어, store_sales 테이블과 customer 테이블을 고객 테이블의 기본 키 PRIMARY KEY (c_customer_sk) RELY를 기준으로 조인하는 쿼리가 있다고 가정해 보겠습니다.
기본 키가 없으면 store_sales의 각 행은 customer의 여러 행과 일치할 수 있으며 올바른 SUM 값을 계산하기 위해 조인을 실행해야 합니다. 그러나 customer 테이블이 기본 키를 기준으로 조인되므로 조인은 store_sales의 각 행에 대해 한 행을 출력한다는 것을 알고 있습니다.
따라서 쿼리는 실제로 store_sales 팩트 테이블의 ss_quantity 열만 필요합니다. 따라서 쿼리 옵티마이저는 조인을 쿼리에서 완전히 제거하여 다음과 같이 변환할 수 있습니다.
전체 조인을 피함으로써 훨씬 빠르게 실행됩니다. 이 예에서는 최적화로 인해 쿼리 속도가 1.5분에서 6초로 빨라지는 것을 관찰했습니다. 조인에 제거할 수 있는 많은 테이블이 포함되는 경우 이점은 훨씬 더 클 수 있습니다!
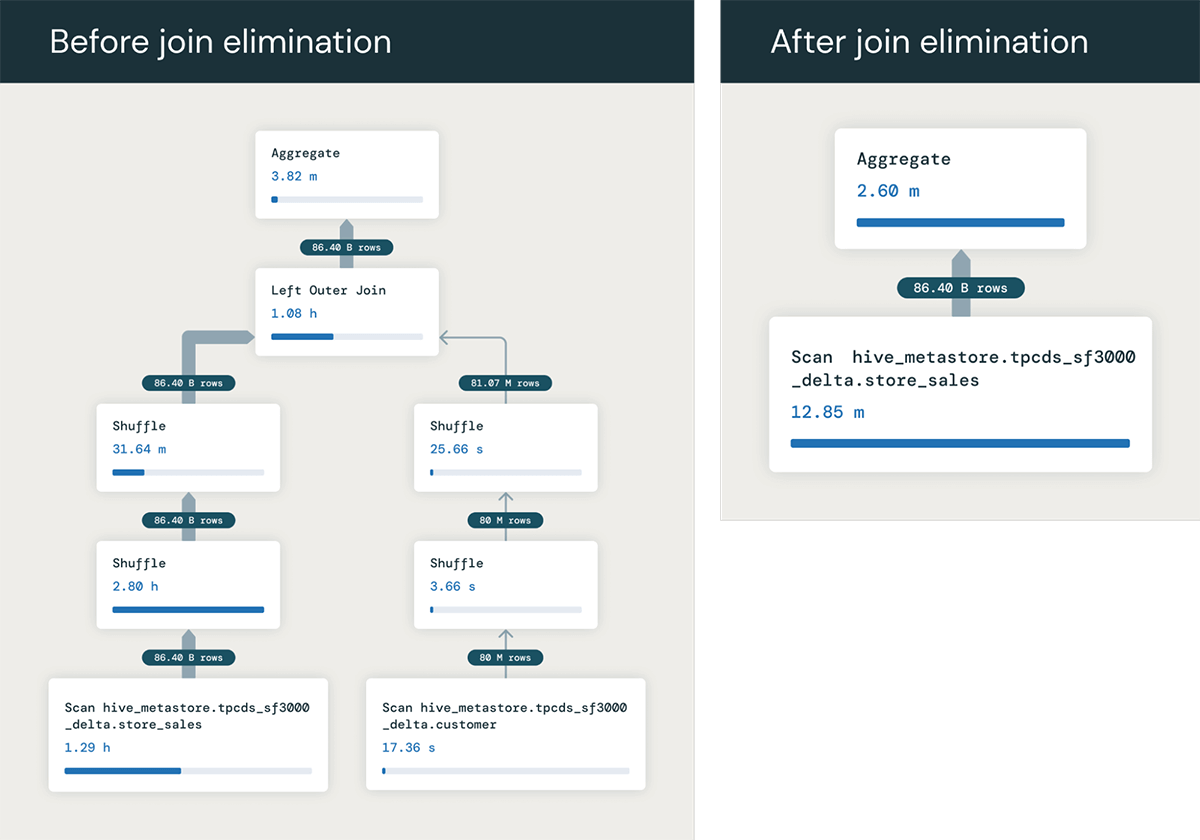
이런 쿼리를 왜 실행하냐고 물어볼 수 있습니다. ��생각보다 훨씬 흔합니다! 한 가지 일반적인 이유는 사용자가 여러 테이블을 조인하는 뷰를 구성하기 때문입니다. 예를 들어 많은 팩트 테이블과 차원 테이블을 조인하는 경우입니다. 이러한 뷰에 대해 쿼리를 작성하는데, 종종 일부 테이블의 열만 사용하고 모든 테이블의 열을 사용하지는 않습니다. 따라서 옵티마이저는 각 쿼리에서 필요하지 않은 테이블에 대한 조인을 제거할 수 있습니다. 이 패턴은 많은 비즈니스 인텔리전스(BI) 도구에서도 흔히 볼 수 있는데, 이러한 도구는 종종 쿼리가 일부 테이블의 열만 사용하더라도 스키마의 많은 테이블을 조인하는 쿼리를 생성합니다.
결론
공개 미리 보기 이후 2600개 이상의 Databricks 고객이 기본 키 및 외래 키 제약 조건을 사용했습니다. 오늘, 이 기능의 일반 공급을 발표하게 되어 기쁘게 생각합니다. 이는 Databricks에서 데이터 관리 및 무결성을 향상시키기 위한 우리의 노력을 새로운 단계로 이끌 것입니다.
또한 Databricks는 이제 RELY 옵션이 있는 키 제약 조건을 활용하여 불필요한 집계 및 조인을 제거하는 등 쿼리를 최적화하여 쿼리 성능을 훨씬 빠르게 향상시킵니다.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.