새로운 Python 데이터 소스 API로 데이터 수집 간소화
작성자: Craig Lukasik , Allison Wang
이 블로그에서는 Spark의 새로운 Python 데이터 소스 API가 IoT 데이터 수집을 어떻게 간소화하는지 살펴봅니다.
데이터 엔지니어링 팀은 수많은 맞춤형, 독점 또는 산업별 데이터 소스에 대한 맞춤형 수집 솔루션을 구축하는 작업을 자주 맡습니다. 많은 팀은 이러한 수집 솔루션 구축 작업이 번거롭고 시간이 많이 걸린다는 것을 알게 됩니다. 이러한 과제를 인식하고 다양한 산업에 걸쳐 수많은 회사를 인터뷰하여 다양한 데이터 통합 요구 사항을 더 잘 이해했습니다. 이러한 포괄적인 피드백을 통해 Apache Spark™용 Python 데이터 소스 API를 개발하게 되었습니다.
긴밀하게 협력해 온 고객 중 하나는 Shell입니다. 에너지 부문에서 장비 고장은 안전, 환경 및 운영 안정성에 영향을 미쳐 심각한 결과를 초래할 수 있습니다. Shell에서는 이러한 위험을 최소화하는 것이 우선 ��순위이며, 이를 수행하는 한 가지 방법은 장비의 안정적인 작동에 중점을 두는 것입니다.
Shell은 1,800억 달러 이상의 가치를 지닌 방대한 자본 자산과 장비를 보유하고 있습니다. Shell 운영에서 생성되는 방대한 양의 데이터를 관리하기 위해 생산성을 향상시키고 데이터 팀이 다양한 이니셔티브에 걸쳐 원활하게 작업할 수 있도록 하는 고급 도구에 의존합니다. Databricks 데이터 인텔리전스 플랫폼은 데이터 액세스를 민주화하고 Shell의 분석가, 엔지니어 및 과학자 간의 협업을 촉진하는 데 중요한 역할을 합니다. 그러나 IoT 데이터 통합은 일부 사용 사례에 어려움을 안겨주었습니다.
Shell과의 작업을 예로 들어, 이 블로그에서는 이 새로운 API가 이전의 과제를 어떻게 해결하는지 살펴보고 적용 사례를 설명하는 코드 예제를 제공할 것입니다.
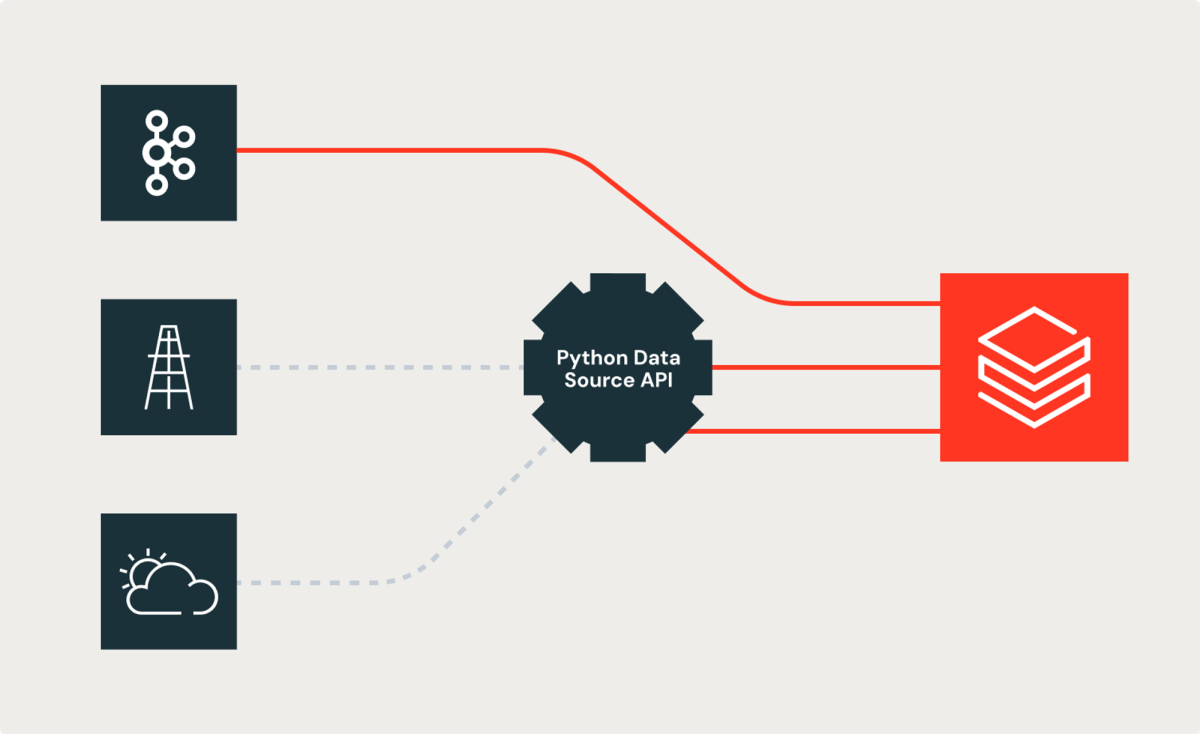
과제
먼저 Shell의 데이터 엔지니어가 경험했던 과제를 살펴보겠습니다. 데이터 파이프라인의 많은 데이터 소스는 내장된 Spark 소스(예: Kafka)를 사용하지만, 일부는 REST API, SDK 또는 기타 메커니즘에 의존하여 소비자에게 데이터를 노출합니다. Shell의 데이터 엔지니어는 이 사실 때문에 어려움을 겪었습니다. 결국 내장된 Spark 소스의 데이터와 이러한 소스의 데이터를 조인하기 위한 맞춤형 솔루션을 만들게 되었습니다. 이 과제는 데이터 엔지니어��의 시간과 에너지를 소모했습니다. 대규모 조직에서 흔히 볼 수 있듯이 이러한 맞춤형 구현은 구현 및 결과의 불일치를 초래합니다. Shell의 최고 디지털 기술 고문인 Bryce Bartmann은 단순함을 원하며 다음과 같이 말했습니다. “우리는 스트리밍 사용 사례를 포함하여 많은 멋진 REST API를 작성하며, 모든 연결 코드를 직접 작성하는 대신 Databricks에서 데이터 소스로 사용하고 싶습니다.”
“우리는 스트리밍 사용 사례를 포함하여 많은 멋진 REST API를 작성하며, 모든 연결 코드를 직접 작성하는 대신 Databricks에서 데이터 소스로 사용하고 싶습니다.” - Bryce Bartmann, Shell 최고 디지털 기술 고문
솔루션
새로운 Python 사용자 지정 데이터 소스 API는 객체 지향 개념을 사용하여 문제를 접근할 수 있도록 하여 불편함을 완화합니다. 새로운 API는 REST API 기반 조회와 같은 사용자 지정 코드를 캡슐화하고 다른 Spark 소스 또는 싱크로 노출할 수 있는 추상 클래스를 제공합니다.
데이터 엔지니어는 단순성과 구성 가능성을 원합니다. 예를 들어, 데이터 엔지니어이고 스트리밍 파이프라인에 날씨 데이터를 수집하고 싶다고 가정해 보겠습니다. 이상적으로는 다음과 같이 보이는 코드를 작성하고 싶을 것입니다.
이 코드는 간단해 보이며, 데이터 엔지니어는 이미 DataFrame API에 익숙하기 때문에 사용하기 쉽습니다. 이전에는 Spark 작업에서 REST API에 액세스하는 일반적인 접근 방식은 PandasUDF를 사용하는 것이었습니다. 이 문서는 Pandas UDF를 사용하여 REST API로 데이터를 싱크하는 재사용 가능한 코드를 작성하는 것이 얼마나 복잡할 수 있는지 보여줍니다. 반면에 새로운 API는 Spark 작업(스트리밍 또는 배치, 싱크 또는 소스)이 비 네이티브 소스 및 싱크와 작동하는 방식을 단순화하고 표준화합니다.
다음으로 실제 사례를 살펴보고 새로운 API를 사용하여 새 데이터 소스("weather" 예시)를 만드는 방법을 보여드리겠습니다. 새로운 API는 소스, 싱크, 배치 및 스트리밍에 대한 기능을 제공하며 아래 예제는 새 스트리밍 API를 사용하여 새 "weather" 소스를 구현하는 데 중점을 둡니다.
Python 데이터 소스 API 사용 – 실제 시나리오
예를 들어, 유정 장비의 압력 데이터가 필요한 예측 유지 보수 사용 사례에 대한 데이터 파이프라인을 구축하는 작업을 맡은 데이터 엔지니어라고 가정해 보겠습니다. 유정의 온도 및 압력 메트릭이 IoT 센서에서 Kafka를 통해 흐른다고 가정해 보겠습니다. Structured Streaming이 Kafka에서 데이터를 처리하는 데 네이티브 지원이 있다는 것을 알고 있습니다. 지금까지는 좋습니다. 그러나 비즈니스 요구 사항은 과제를 제시합니다. 동일한 데이터 파이프라인은 유정 현장과 관련된 날씨 데이터도 캡처해야 하며, 이 데이터는 Kafka를 통해 스트리밍되는 것이 아니라 REST API를 통해 액세스할 수 있습니다. 비즈니스 이해 관계자와 데이터 과학자는 날씨가 장비의 수명과 효율성에 영향을 미치며, 이러한 요인이 장비 유지 보수 일정에 영향을 미친다는 것을 알고 있습니다.
간단하게 시작하기
새 API는 많은 사용 사례에 적합한 간단한 옵션인 SimpleDataSourceStreamReader API를 제공합니다. SimpleDataSourceStreamReader API는 데이터 소스의 처리량이 낮고 파티셔닝이 필요하지 않은 경우에 적합합니다. 이 예제에서는 제한된 수의 유정 현장에 대한 날씨 데이터 판독값만 필요하고 날씨 판독 빈도가 낮기 때문에 이 API를 사용할 것입니다.
SimpleDataSourceStreamReader API를 사용하는 간단한 예제를 살펴보겠습니다.
나중에 더 복잡한 접근 방식을 설명하겠습니다. 다른 더 복잡한 접근 방식은 파티션 인식 Python 데이터 소스를 구축할 때 이상적입니다. 지금은 그것이 무엇을 의미하는지에 대해 걱정하지 않을 것입니다. 대신 간단한 API를 사용하는 예제를 보여드리겠습니다.
코드 예제
아래 코드 예제는 "simple" API가 충분하다고 가정합니다. __init__ 메서드는 리더 클래스(아래 WeatherSimpleStreamReader)가 모니터링해야 하는 유정 현장을 이해하는 방법이므로 필수적입니다. 이 클래스는 "locations" 옵션을 사용하여 날씨 정보를 내보낼 위치를 식별합니다.
이제 간단한 리더 클래스를 정의했으므로, 이를 DataSource 추상 클래스의 구현에 연결해야 합니다.
이제 DataSource를 정의하고 스트리밍 리더 구현을 ��연결했으므로, DataSource를 Spark 세션에 등록해야 합니다.
이는 날씨 데이터 소스가 데이터 엔지니어가 익숙하게 사용할 수 있는 DataFrame 작업을 제공하는 새로운 스트리밍 소스임을 의미합니다. 이 점은 강조할 가치가 있습니다. 이러한 사용자 지정 데이터 소스는 더 넓은 팀에 이점을 제공하기 때문입니다. 객체 지향적인 접근 방식을 사용하면 더 넓은 팀이 사용 사례의 일부로 날씨 데이터가 필요한 경우 이 데이터 소스의 이점을 누릴 수 있습니다. 따라서 데이터 엔지니어는 재사용을 위해 사용자 지정 데이터 소스를 Python wheel 라이브러리로 추출하고 싶을 수 있습니다.
아래에서 데이터 엔지니어가 사용자 지정 스트림을 얼마나 쉽게 활용할 수 있는지 볼 수 있습니다.
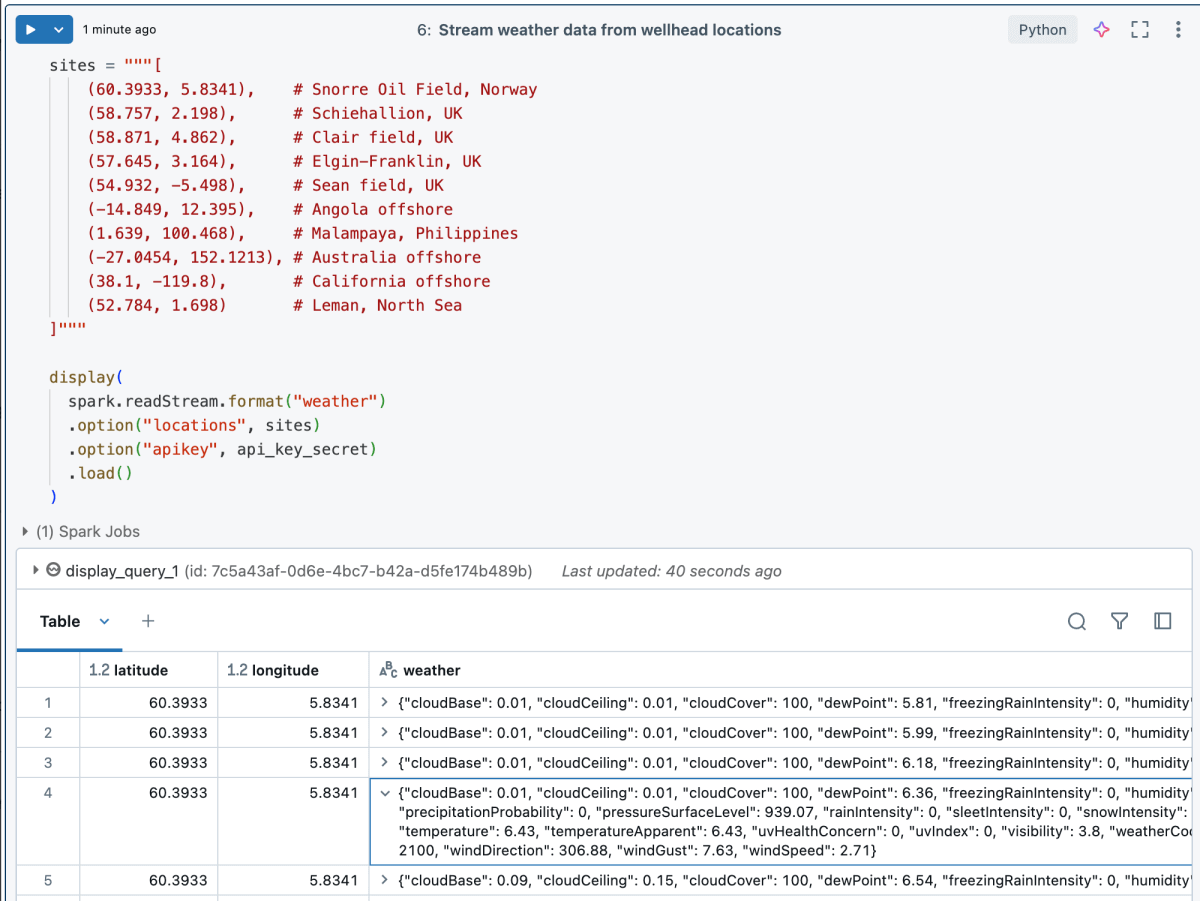
예시 결과:
기타 고려 사항
파티션 인식 API는 언제 사용해야 할까요?
Python 데이터 소스의 "간단한" API를 살펴보았으므로, 파티션 인식을 위한 옵션에 대해 설명하겠습니다. 파티션 인식 데이터 소스를 사용하면 데이터 생성을 병렬화할 수 있습니다. 저희 예시에서 파티션 인식 데이터 소스 구현은 REST API 호출이 워커에 분산될 수 있도록 위치를 여러 작업으로 분할하는 워커 작업을 결과로 생성합니다. 다시 말하지만, 예상 데이터 볼륨이 낮기 때문에 저희 예시에는 이러한 복잡성이 포함되지 않았습니다.
배치 vs. 스트��림 API
사용 사례와 API가 소스 스트림을 생성해야 하는지 또는 데이터를 싱크해야 하는지에 따라 다른 메서드를 구현하는 데 집중해야 합니다. 저희 예시에서는 데이터를 싱크하는 것에 대해 걱정하지 않습니다. 또한 배치 리더 구현을 포함했어야 합니다. 그러나 특정 사용 사례에서 필요한 클래스를 구현하는 데 집중할 수 있습니다.
| 소스 | 싱크 | |
|---|---|---|
| 배치 | reader() | writer() |
| 스트리밍 | streamReader() 또는 simpleStreamReader() | streamWriter() |
Writer API는 언제 사용해야 할까요?
이 문서는 readStream에서 사용되는 Reader API에 중점을 두었습니다. Writer API는 데이터 파이프라인의 출력 측에서 유사한 임의 로직을 허용합니다. 예를 들어, 유정 헤드의 운영 관리자가 파이프라인의 로직을 활용하는 빨간색/노란색/녹색 장비 상태를 보여주는 API를 호출하도록 데이터 파이프라인을 원한다고 가정해 보겠습니다. Writer API를 사용하면 데이터 엔지니어가 로직을 캡슐화하고 익숙한 writeStream 형식과 유사하게 작동하는 데이터 싱크를 노출할 수 있는 동일한 기회를 얻을 수 있습니다.
결론
"단순함은 궁극의 정교함입니다." - 레오나르도 다 빈치
설계자 및 데이터 엔지니어로서 우리는 이제 PySpark 사용자 지정 데이터 소스 API를 사용하여 배치 및 스트리밍 워크로드를 단순화할 기회를 갖게 되었습니다. 데이터 팀에 도움이 될 새로운 데이터 소스 기회를 찾으면, 예를 들어 Python wheel을 사용하여 데이터 소스를 분리하여 엔터프라이즈 전체에서 재사용하는 것을 고려해 보세요.
Python 데이터 소스 API는 우리가 필요로 했던 것입니다. 데이터 엔지니어들이 REST API 및 SDK와 상호 작용하는 데 필요한 코드를 모듈화할 수 있는 기회를 제공합니다. 이제 조직 전체에서 재사용 가능한 Spark 데이터 소스를 구축, 테스트 및 제공할 수 있다는 사실은 우리 팀이 더 빠르게 발전하고 작업에 더 많은 확신을 갖도록 도울 것입니다." - Bryce Bartmann, Chief Digital Technology Advisor, Shell
결론적으로, Apache Spark™용 Python 데이터 소스 API는 복잡한 데이터 소스 및 싱크, 특히 스트리밍 컨텍스트를 다루는 데이터 엔지니어가 이전에 직면했던 상당한 문제를 해결하는 강력한 기능입니다. "간단한" API 또는 파티션 인식 API를 사용하든 엔지니어는 이제 더 광범위한 데이터 소스 및 싱크를 Spark 파이프라인에 효율적으로 통합할 수 있는 도구를 갖추게 되었습니다. 워크스루와 예제 코드가 보여주었듯이 이 API를 구현하고 사용하는 것은 간단하며 예측 유지보수 및 기타 사용 사례에 대한 빠른 성과를 가능하게 합니다. Databricks 설명서(및 오픈 소스 설명서)는 API에 대해 더 자세히 설명하고 있으며, 여러 Python 데이터 소스 예제는 여기에서 찾을 수 있습니다.
마지막으로, 사용자 지정 데이터 소스를 모듈식의 재사용 가능한 구성 요소로 만드는 것의 중요성은 아무리 강조해도 지나치지 않습니다. 이러한 데이터 소스를 독립 실행형 라이브러리로 추상화함으로써 팀은 코드 재사용 및 협업 문화를 조성하여 생산성과 혁신을 더욱 향상시킬 수 있습니다. 빅 데이터 및 IoT로 가능한 것의 경계를 계속 탐색하고 확장함에 따라 Python 데이터 소스 API와 같은 기술은 에너지 부문 및 그 이상의 분야에서 데이터 기반 의사 결정의 미래를 형성하는 데 중요한 역할을 할 것입니다.
이미 Databricks 고객이라면 이러한 예제 중 하나를 가져와 수정하여 REST API 뒤에 있는 데이터를 활용하세요. 아직 Databricks 고객이 아니라면 무료로 시작하여 오늘 예제 중 하나를 사용해 보세요.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.