Agentic 워크플로우를 위한 SOTA 임베딩 모델, 공개 프리뷰 출시
Qwen3-Embedding-0.6B는 모든 임베딩 작업에서 최고의 성능을 제공하는 Foundation Model Serving의 첫 번째 다국어 임베딩 모델입니다.
작성자: Felix Zhu, Cade Daniel , Wai Wu
- Qwen3-Embedding-0.6B가 Model Serving에 출시되어 벡터 검색 및 AI 에이전트 워크로드에 최적화된 컴팩트한 0.6B 모델로 최첨단 검색 성능을 제공합니다.
- Databricks 최초의 다국어 임베딩 모델로, 100개 이상의 언어에 걸쳐 교차 언어 검색을 지원하여 글로벌 엔터프라이즈 데이터를 활용합니다.
- Matryoshka 임베딩은 유연한 비용-성능 절충을 가능하게 하여, 더 빠른 검색과 더 낮은 스토리지 비용을 위해 임베딩을 1024에서 32 차원으로 잘라낼 수 있습니다.
검색은 최�신 AI 시스템의 기반이며, 임베딩 모델의 품질은 애플리케이션이 엔터프라이즈 데이터를 얼마나 효과적으로 찾고 추론하는지를 결정합니다. 오늘 Databricks에서 강력한 검색 성능, 다국어 지원, 안전한 서버리스 배포를 제공하는 최첨단 임베딩 모델인 Qwen3-Embedding-0.6B를 출시합니다.
Agent Bricks 및 AI Search와 함께 이 모델을 사용하면 팀이 Databricks에서 직접 엔터프라이즈 데이터로 AI 에이전트를 구축하고, 데이터를 플랫폼 외부로 이동하지 않고도 관련 컨텍스트를 검색하며 거버넌스된 데이터를 기반으로 추론할 수 있습니다.
Agent Bricks로 검색 기반 에이전트 구축
최첨단 임베딩 모델은 최신 AI 시스템의 중요한 기반으로, 애플리케이션이 엔터프라이즈 데이터의 대규모 컬렉션에서 올바른 컨텍스트를 검색할 수 있도록 합니다. Databricks에서 사용할 수 있는 Qwen3-Embedding-0.6B는 이러한 워크로드에 대해 강력한 검색 성능을 제공합니다.
Qwen3-Embedding-0.6B는 강력한 Qwen3 기반 모델을 기반으로 하며 널리 사용되는 GTE 시리즈의 동일한 연구팀에서 개발했습니다. 32k 토큰의 최대 컨텍스트 길이를 통해 이 모델은 문서를 다양한 크기로 분할하는 데 있어 놀라운 유연성을 제공합니다. 또한, 지침 인식 설계를 통해 개발자는 간단한 프롬프트로 특정 작업 및 언어에 맞게 모델을 조정할 수 있으며, 일반적으로 검색 성능을 1~5% 향상시킵니다.
Databricks에서는 이를 Agent Bricks 및 AI Search와 결합하여 엔터프라이즈 데이터에서 직접 검색 기반 AI 에이전트를 구축할 수 있습니다. 팀은 AI Search를 사용하여 문서를 인덱싱하고 에이전트 실행 중에 관련 컨텍스트를 검색하여 Databricks에 저장된 거버넌스된 데이터에 에이전트를 기반으로 둘 수 있습니다.
Databricks의 AI 에이전트 개선 방법
Qwen3-Embedding-0.6B는 크기 대비 최첨단 품질을 제공합니다. MTEB 다국어 및 영어 v2 리더보드에서 대부분의 다른 0.6B 클래스 모델을 능가하고 OpenAI 및 Cohere의 플래그십 임베딩 모델을 능가하며 훨씬 더 큰 7B+ 모델과 경쟁합니다. 이는 매우 큰 모델의 지연 시간과 비용 없이 최고 수준의 검색 성능을 달성할 수 있음을 의미합니다.
이 모델은 Matryoshka Representation Learning(MRL)을 통해 비용과 검색률을 세밀하게 제어할 수 있으며, 가장 중요한 정보를 초기 벡터 차원에 집중시킵니다. 이를 통해 임베딩을 안전하게 잘라내어 더 저렴한 스토리지와 더 빠른 검색을 가능하게 하면서도 대부분의 신호를 유지할 수 있습니다. Qwen3-Embedding-0.6B를 사용하면 요청 시 32에서 1024 차원까지 모든 임베딩 크기를 선택할 수 있습니다. 대규모 검색률 인덱스의 경우 더 작은 벡터를 사용하고, 더 높은 정밀도의 재순위 지정의 경우 전체 크기 벡터를 사용합니다.
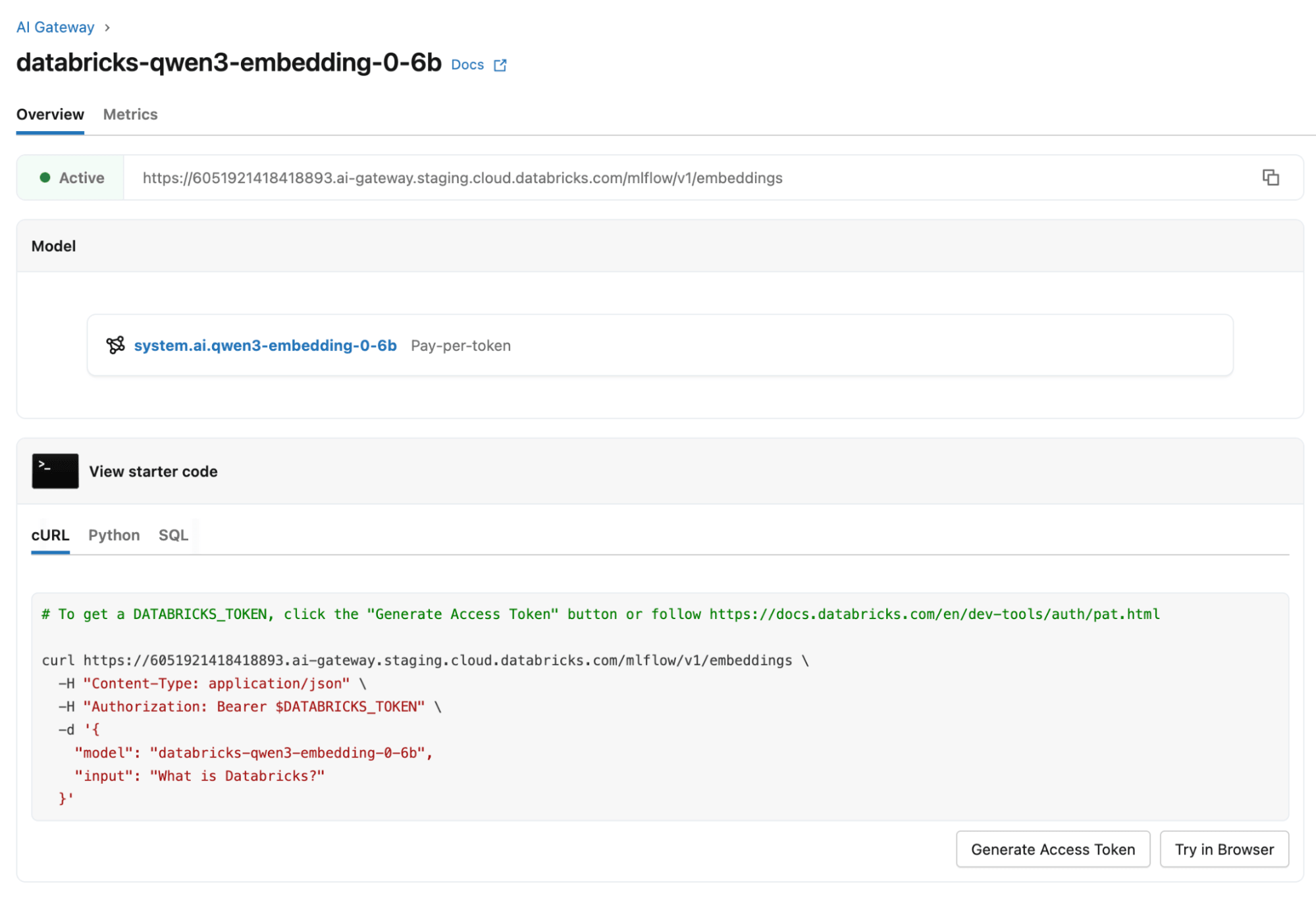
이 기능을 databricks-qwen3-embedding-0-6b와 함께 사용하려면 Embeddings REST API 요청에서 ��선택적 dimensions 필드를 원하는 출력 크기(32에서 1024 사이의 2의 거듭제곱)로 설정하세요. 자세한 내용은 Foundation Model REST API 설명서를 참조하세요.
다국어 설계
Qwen3-Embedding-0.6B는 Databricks에서 호스팅하는 최초의 다국어 임베딩 모델로, 처음부터 글로벌 워크로드를 위해 설계되었습니다. 많은 임베딩 모델이 영어 우선이며 다국어 지원이 제한적인 반면, Qwen3-Embedding-0.6B는 100개 이상의 언어에 걸쳐 텍스트로 사전 훈련된 Qwen3 기본 모델의 광범위한 언어 적용 범위를 상속합니다.
이를 통해 영어 검색뿐만 아니라 다국어 및 교차 언어 작업에서도 강력한 성능을 발휘합니다. 애플리케이션은 한 언어로 검색하고 다른 언어로 결과를 검색하거나, 여러 프로그래밍 언어에 걸쳐 혼합 언어 데이터셋 및 코드 검색을 지원할 수 있습니다.
안전한 서버리스 배포
다른 Databricks 호스팅 파운데이션 모델과 마찬가지로 Qwen3-Embedding-0.6B는 Databricks 플랫폼 내에서 안전하고 완전히 관리되는 서버리스 GPU에서 실행됩니다.
파운데이션 모델 API를 호출하기만 하면 Databricks가 프로비저닝, 자동 확장 및 안정성을 처리합니다. 이 모델은 지리적으로 인식되고 규정을 준수하는 인프라에서 실행되므로 데이터를 가까이에 임베딩을 유지하고, 데이터 상주 요구 사항을 준수하며, 기존 Databricks 워크로드와 검색을 직접 통합할 수 있습니다.
지금 Qwen3-Embedding-0.6B를 사용해 보세요!
의미론적 검색, RAG 파이프라인, 다국어 검색 또는 텍스트 분류 시스템을 구축하든 관계없이 Qwen3-Embedding-0.6B는 속도, 효율성 및 최첨단 정확도의 탁월한 조합을 제공합니다. 이 모델은 모든 클라우드 및 Foundation Model Serving을 지원하는 모든 지역에서 databricks-qwen3-embedding-0-6b로 사용할 수 있으며, Databricks Serving 페이지에서 이 모델을 사용해 볼 수 있습니다. Pay-Per-Token, AI Functions(배치 추론) 및 Provisioned Throughput 등 모든 Model Serving 표면에서 사용할 수 있습니다. AI Search 사용 사례에도 이 모델을 선택할 수 있습니다.
(이 글은 AI의 도움을 받아 번역되었습니다. 원문이 궁금하시다면 여기를 클릭해 주세요)
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.