스파크 튜닝이란 무엇인가요?
Apache Spark의 구성, 메모리 사용량 및 실행 전략을 체계적으로 최적화하여 성능을 극대화하고 리소스 병목 현상을 방지합니다.
작성자: Databricks 직원
- Spark 튜닝은 저장소와 실행 간의 메모리 할당을 조정하고, 네트워크 성능을 위해 데이터 직렬화를 관리하며, 비용이 많이 드는 디스크 스필링을 방지하기 위해 셔플 파티션을 최적화합니다.
- 적응형 쿼리 실행(AQE)은 최적의 셔플 파티션을 자동으로 찾고 데이터 편향을 해결하며, 비용 기반 옵티마이저(CBO)는 테이블 통계를 사용하여 효율적인 조인 전략을 선택합니다.
- 고급 기술에는 작은 테이블에 대한 브로드캐스트 조인, 데이터 전송량을 줄이기 위한 조건자 푸시다운, 반복적인 데이터 액세스에 대한 캐시와 디스크 저장소의 신중한 관리 등이 포함됩니다.
Spark 성능 튜닝이란 무엇입니까?
Spark 성능 튜닝은 시스템이 사용하는 메모리, 코어와 인스턴스를 대상으로 기록할 설정을 조정하는 프로세스를 가리킵니다. 이 프로세스를 거치면 Spark에서 흠잡을 데 없는 성능을 보장할 수 있으며, Spark에서 리소스 병목 현상을 예방하는 효과도 있습니다.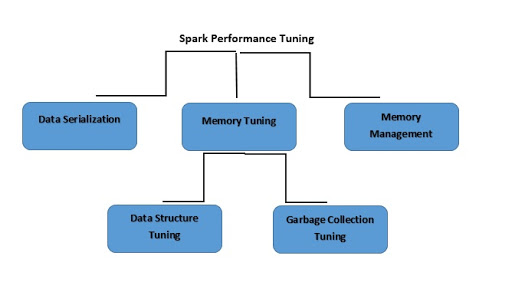
데이터 직렬화란 무엇입니까?
메모리 사용량을 줄이기 위해 Spark RDD를 직렬화 형식으로 저장해야 할 수도 있습니다. 데이터 직렬화는 또한 네트워크 성능이 우수한지 결정하는 요인입니다. Spark 성능 면에서 좋은 결과를 얻으려면 다음과 같이 하면 됩니다.
- 오래 실행되는 작업을 종료합니다.
- 작업이 정확한 실행 엔진에서 실행되도록 보장합니다.
- 모든 리소스를 효율적으로 이용합니다.
- 시스템 성능 시간 강화합니다.
Spark가 지원하는 직렬화 라이브�러리는 다음의 두 가지입니다.
- Java 직렬화
- Kryo 직렬화
메모리 튜닝이란 무엇입니까?
메모리 사용량을 튜닝할 때 눈에 띄는 세 가지 측면이 있습니다.
- Dataset 전체가 메모리에 들어가야 하므로, 개체가 사용하는 메모리를 반드시 고려해야 합니다.
- 개체 회전율을 높이면 가비지 수집 오버헤드가 꼭 필요해집니다.
- 그러한 개체에 액세스할 때 드는 비용을 고려해야 합니다.
기업을 위한 에이전틱 AI 플레이북

데이터 구조 튜닝이란 무엇입니까?
메모리 사용량을 줄이는 한 가지 방법으로 오버헤드를 발생시킬 수 있는 java 기능을 피하는 것이 있습니다. 이렇게 하기 위한 몇 가지 방법을 소개하면 다음과 같습니다.
- RAM 크기가 32GB보다 작은 경우, JVM 플�래그를 –xx:+ UseCompressedOops로 설정해야 합니다. 이 연산으로 8바이트가 아니라 4바이트 포인터를 구축합니다.
- 포인터 외에 작은 개체를 여러 개 사용해도 중첩된 구조를 피할 수 있습니다.
- 키에 문자열을 사용하지 말고 숫자 ID와 열거된 개체를 사용합니다.
가비지 컬렉션 튜닝이란 무엇입니까?
프로그램이 이전에 저장한 RDD와 관련된 큰 규모의 “변동(churn)”을 피하기 위해, Java는 오래된 객체를 제거하여 새로운 객체를 위한 공간을 만듭니다. 하지만 개체가 적은 데이터 구조를 사용하면 비용이 대폭 절감됩니다. 링크된 목록 대신 Ints 어레이를 사용하는 것이 대표적인 예입니다. 아니면 개체를 직렬화된 형식으로 사용하여 각 RDD 파티션마다 개체가 하나씩만 포함되도록 하는 방법도 있습니다.
메모리 관리란 무엇입니까?
우수한 성능을 확보하려면 효율적인 메모리 사용이 필수적입니다. Spark는 메모리를 주로 스토리지와 실행 용도로 사용합니다. 스토리지 메모리는 나중에 다시 사용할 데이터를 캐시하는 데 쓰입니다. 반면 실행 메모리는 섞기(shuffle), 정렬, 조인(join)과 집계 연산에 쓰입니다. 메모리 경합으로 인해 Apache Spark에는 다음과 같은 세 가지 문제점이 생깁니다.
- 실행과 스토리지 사이에서 메모리를 중재하려면 어떻게 해야 합니까?
- 동시에 실행되는 여러 작업에 걸쳐 메모리를 중재하려면 어떻게 해야 합니까?
- 같은 작업 내에서 실행되는 여러 연산자에 걸쳐 메모리를 중재하려면 어떻게 해야 합니까?
정적으로 미리 메모리를 예약하는 방식으로 경합을 방지하는 것이 아니라, 경합이 발생했을 때 멤버들이 강제로 메모리를 버리도록(spill) 하는 방식으로 문제를 해결할 수 있습니다.
추가 자료
최신 게시물을 이메일로 받아보세요
블로그를 구독하고 최신 게시물을 이메일로 받아보세요.