TOP 팀들은 지능형 데이터 파이프라인으로 성공합니다
데이터 파이프라인의 모범 사례, 코딩화
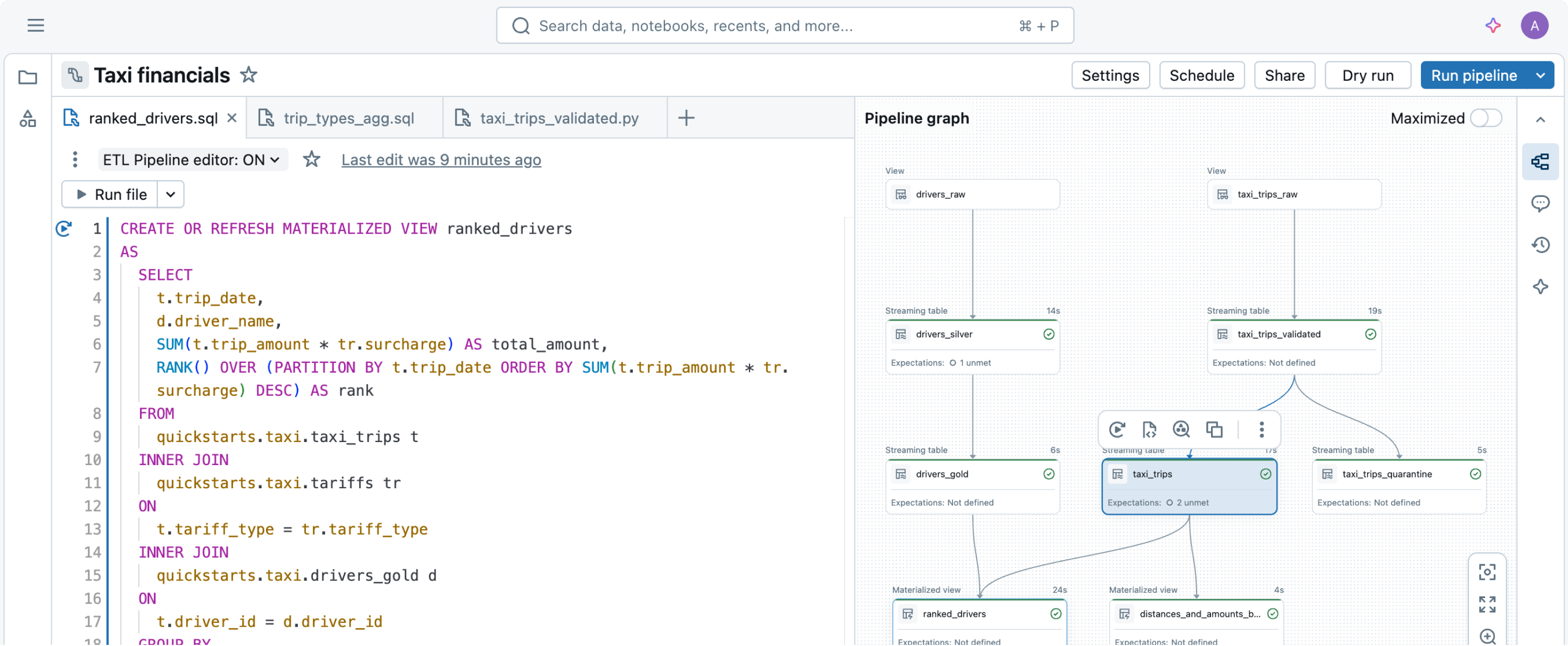
필요한 데이터 변환을 간단히 선언하십시오 - Spark 선언형 파이프라인이 나머지를 처리합니다.효율적인 수집
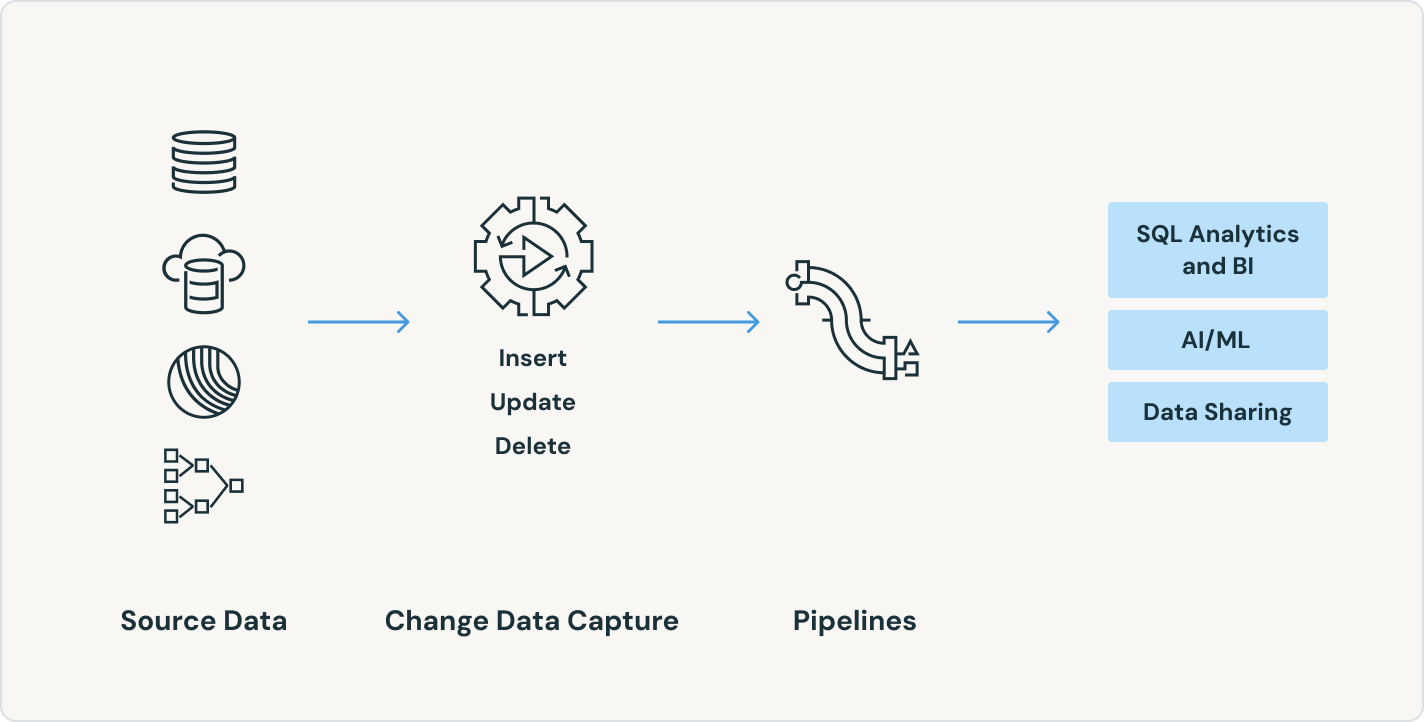
프로덕션에 바로 사용할 수 있는 ETL 파이프라인을 구축하는 첫 단계는 수집입니다. Spark Declarative Pipelines는 데이터 엔지니어, Python 개발자, 데이터 과학자 및 SQL 분석가를 위한 효율적인 데이터 수집을 가능하게 합니다. Databricks에서 Apache Spark™이 지원하는 어떤 소스든지 데이터를 로드하십시오, 배치, 스트리밍 또는 CDC이든 상관없습니다.
지능형 변환
몇 줄의 코드만으로 Spark Declarative Pipelines는 배치 또는 스트리밍 데이터 파이프라인을 구축하고 실행하는 가장 효율적인 방법을 결정하며, 비용이나 성능을 자동으로 최적화하면서 복잡성을 최소화합니다.
자동화된 작업
Spark 선언형 파이프라인은 기본적으로 최고의 사례를 코딩화하여 ETL 개발을 단순화하고 본질적인 운영 복잡성을 자동으로 제거합니다. Spark 선언형 파이프라인을 사용하면 엔지니어들은 파이프라인 인프라의 운영 및 유지보다는 고품질의 데이터 제공에 집중할 수 있습니다.
데이터 파이프라이닝을 단순화하기 위해 구축됨
데이터 파이프라인을 구축하고 운영하는 것은 어려울 수 있지만, 그렇게 되지 않아도 됩니다. Spark 선언형 파이프라인은 강력한 단순성을 위해 만들어졌으므로, 몇 줄의 코드만으로 강력한 ETL을 수행할 수 있습니다.Spark의 통합 API를 활용하여 배치 및 스트림 처리 사이를 쉽게 전환할 수 있습니다.
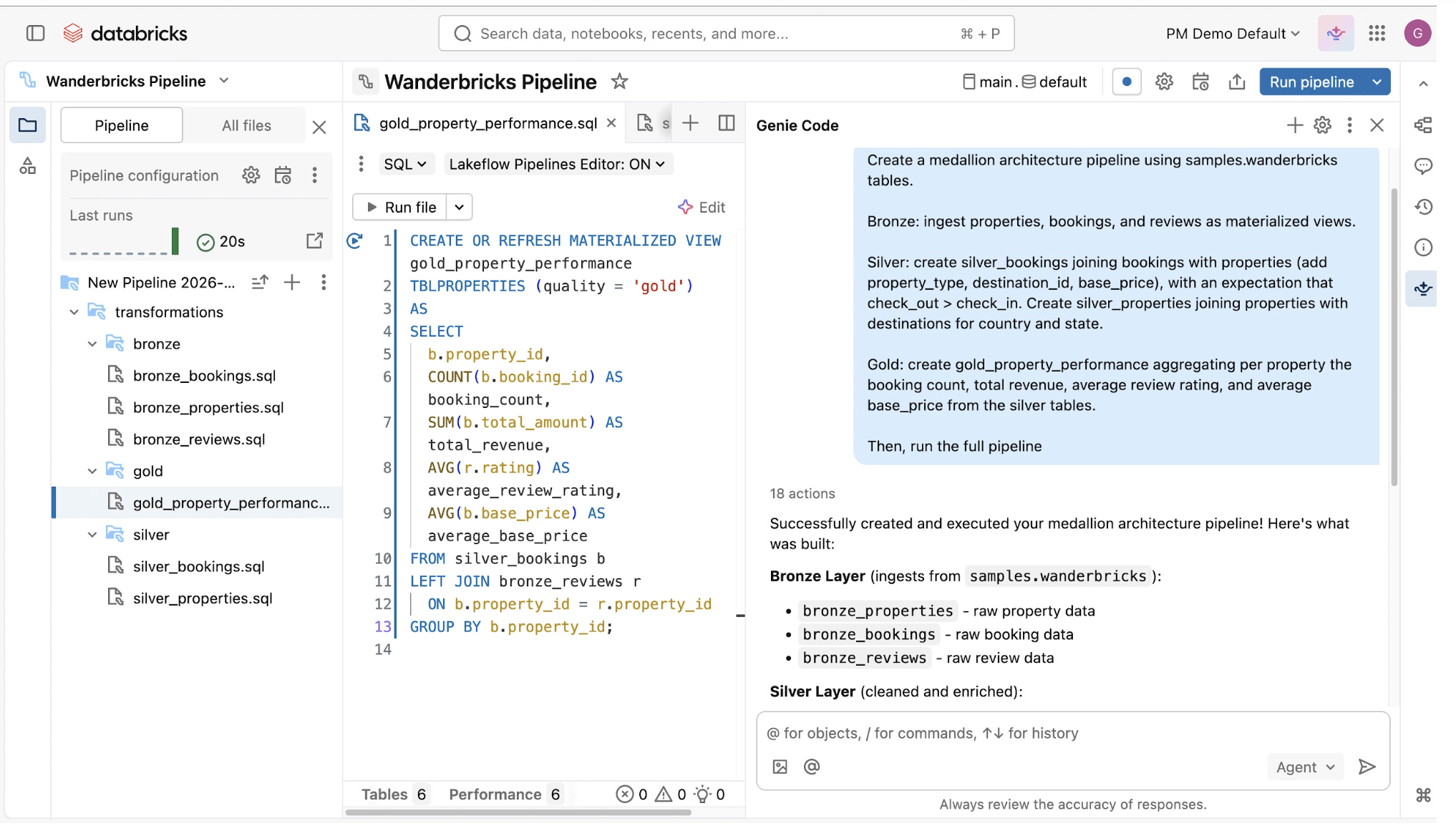
Spark의 통합 API를 활용하여 배치 및 스트림 처리 사이를 쉽게 전환할 수 있습니다.

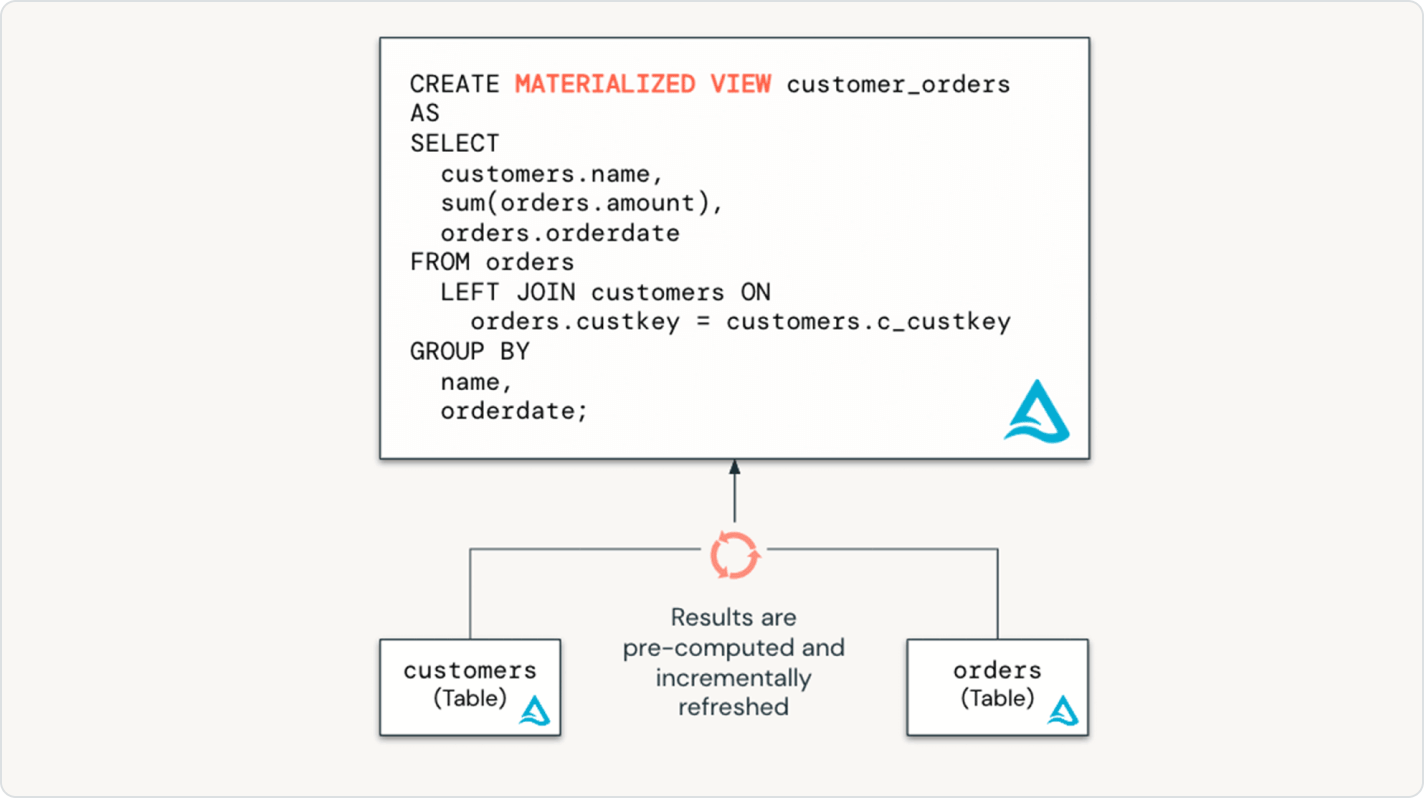
Spark 선언적 파이프라인은 스트리밍 테이블과 물리화 된 뷰를 포함한 전체 증분 데이터 파이프라인을 선언함으로써 파이프라인 성능을 최적화하는 것을 쉽게 만듭니다.
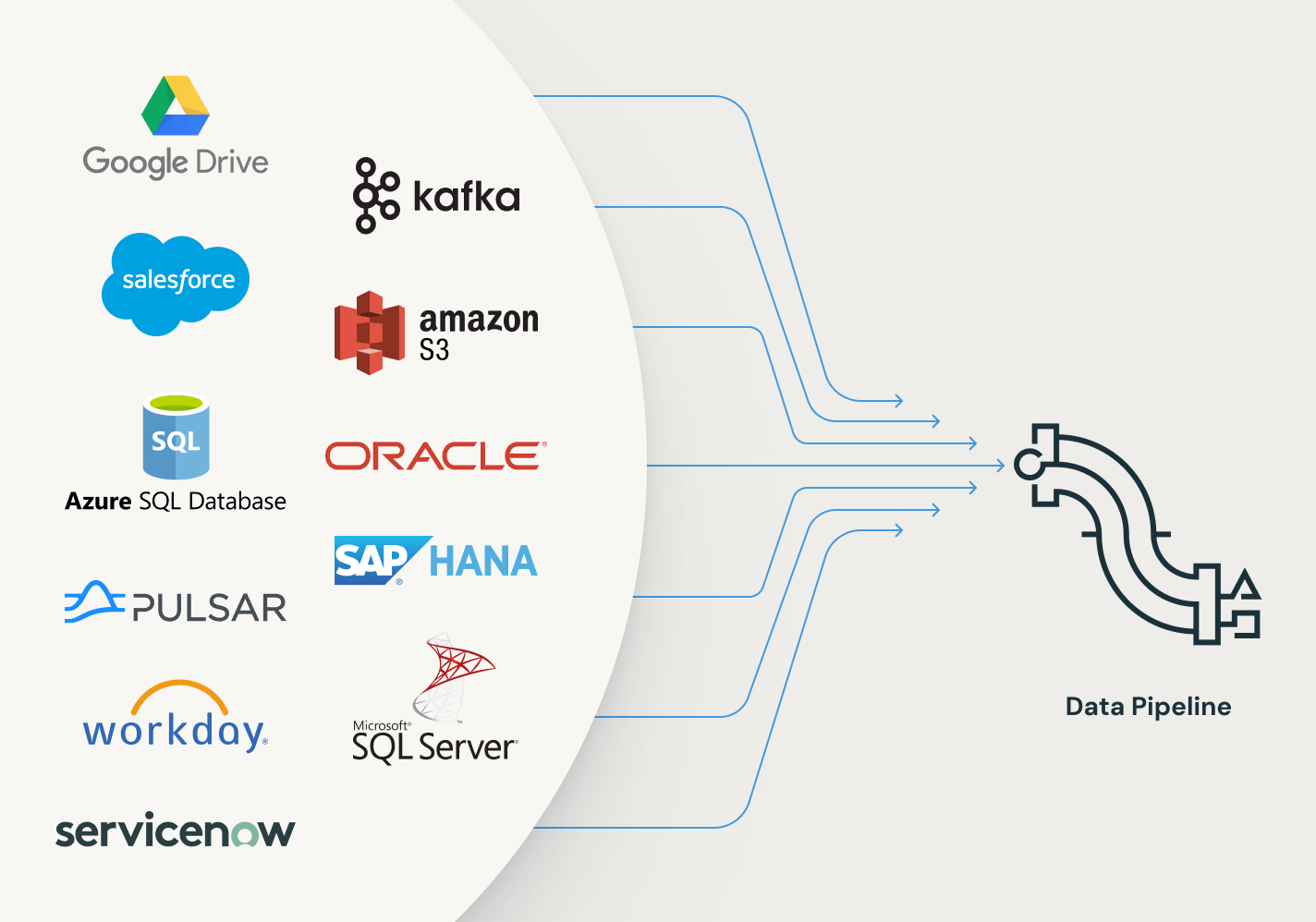
Spark 선언형 파이프라인은 광범위한 소스와 싱크를 지원합니다. 어떤 소스에서든 데이터를 로드하십시오 - 클라우드 저장소, 메시지 버스, 변경 데이터 피드, 데이터베이스, 기업 앱을 포함하여.
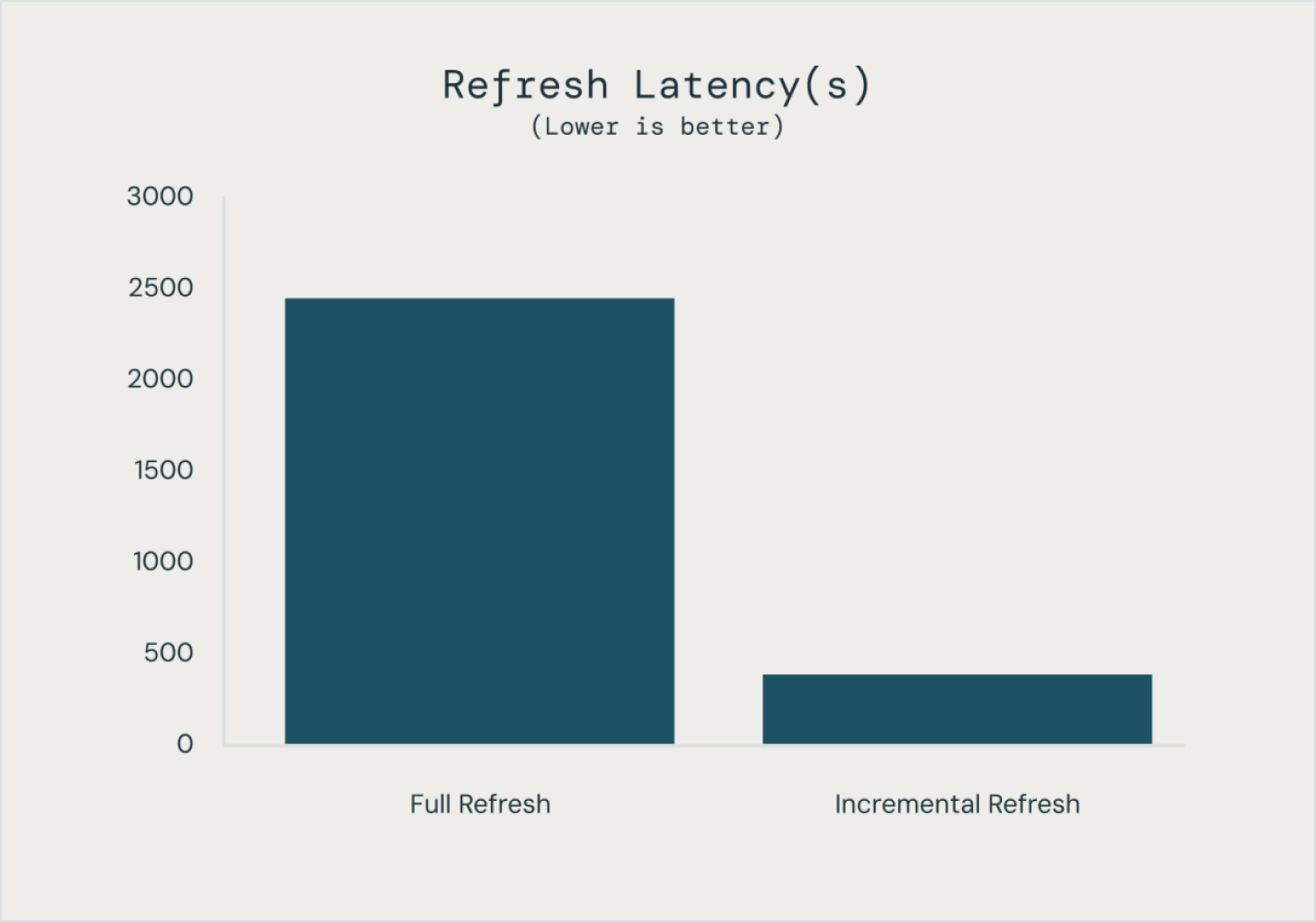
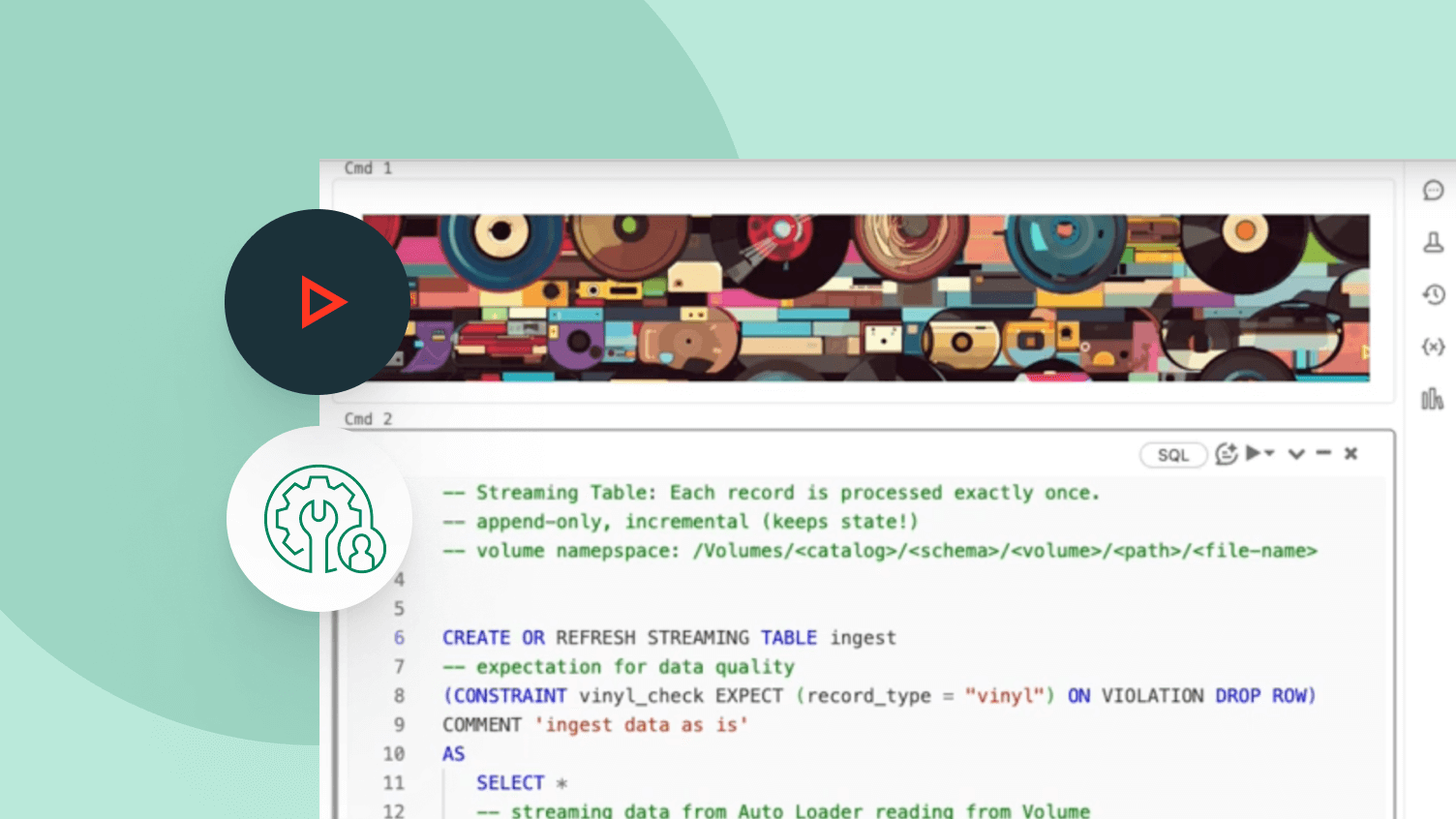
기대치는 테이블에 도착하는 데이터가 데이터 품질 요구사항을 충족하도록 보장하고, 각 파이프라인 업데이트에 대한 데이터 품질에 대한 통찰력을 제공합니다.
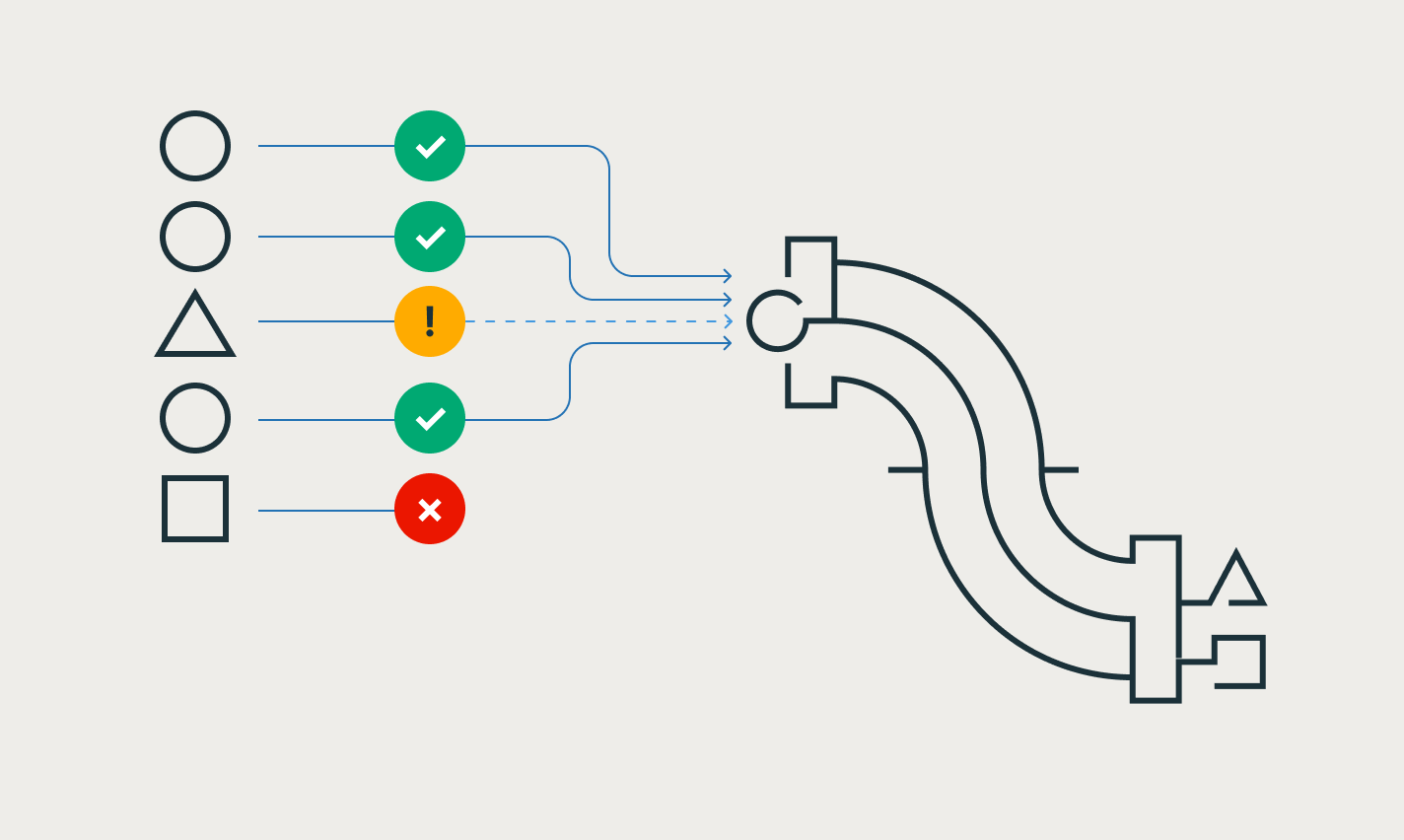
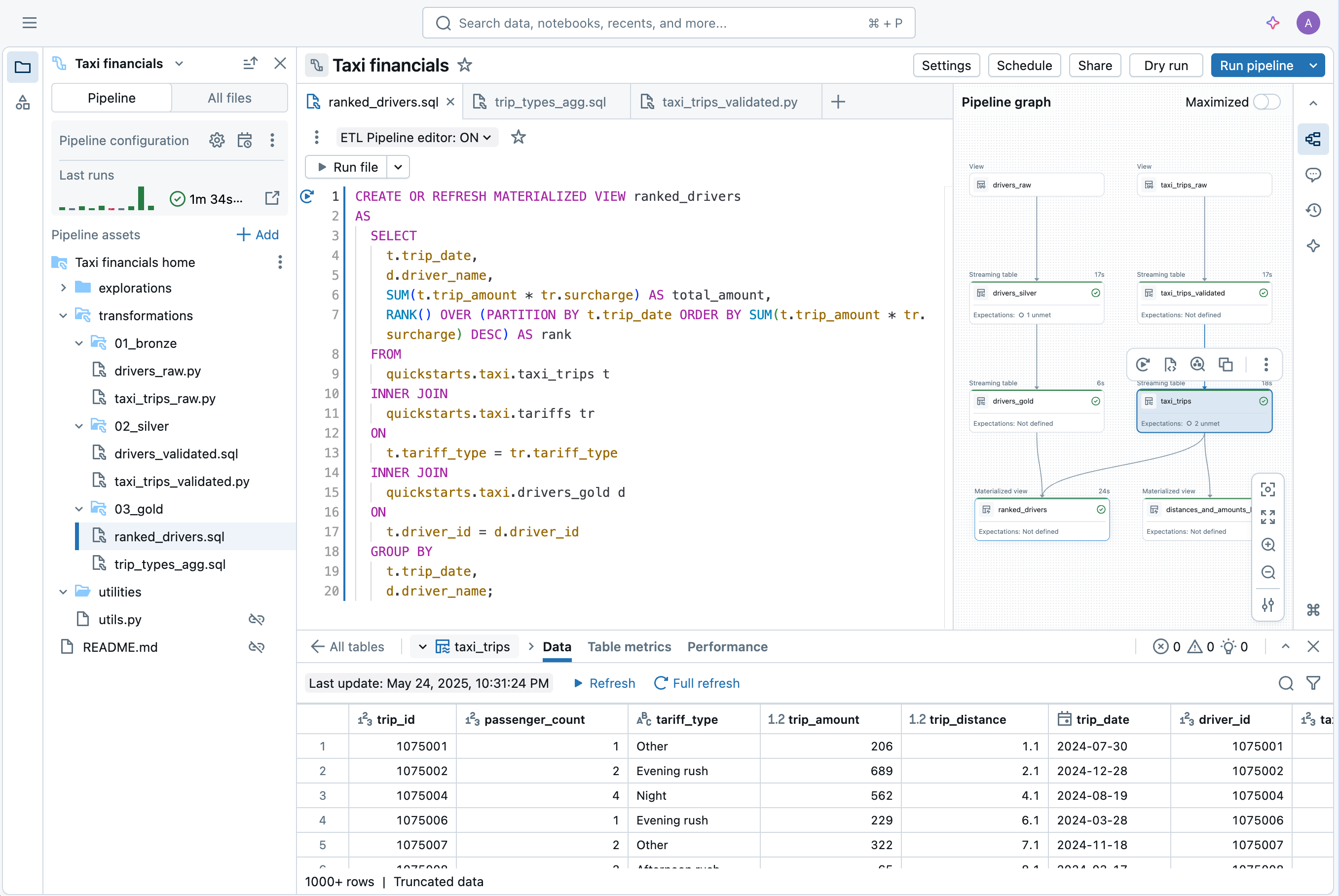
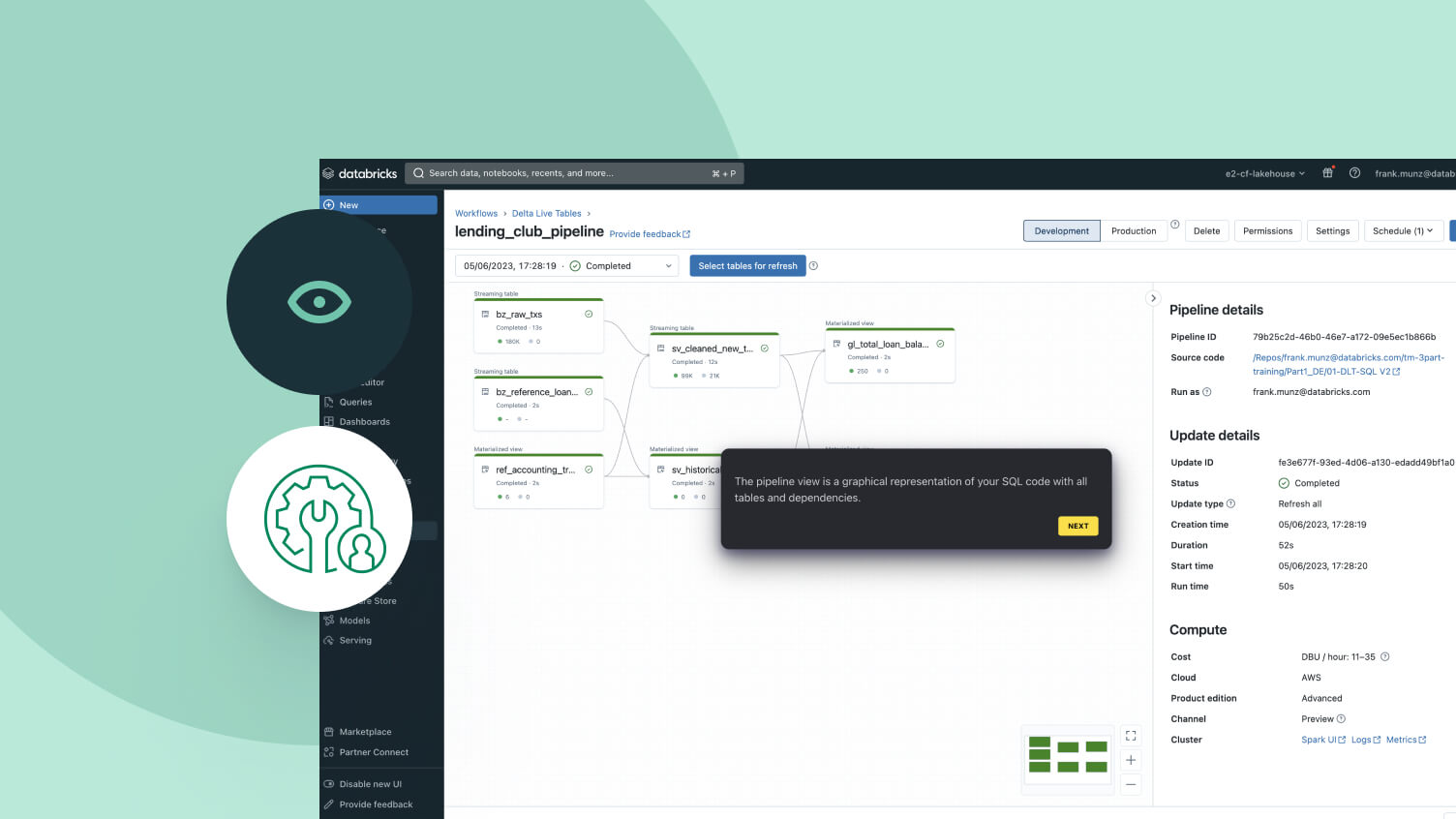
컨텍스트 전환 없이 IDE에서 데이터 엔지니어링을 위한 파이프라인을 개발하세요. 한 UI에서 DAG, 데이터 미리보기 및 실행 통찰을 확인하세요. 자동완성, 인라인 오류 및 진단을 사용하여 쉽게 코드를 개발합니다.
기타 기능
데이터 파이프라인을 간소화하세요

사용량 기반 가격 책정으로
지출 통제
사용 제품에 대해 초 단위로 지불합니다.더 자세히 알아보기
데이터 인텔리전스 플랫폼에서 다른 통합된 지능형 제공을 탐색하세요.
LakeFlow Connect
어떤 소스에서든 효율적인 데이터 수집 커넥터와 데이터 인텔리전스 플랫폼과의 기본 통합은 통합된 거버넌스와 함께 분석 및 AI에 쉽게 접근할 수 있게 해줍니다.

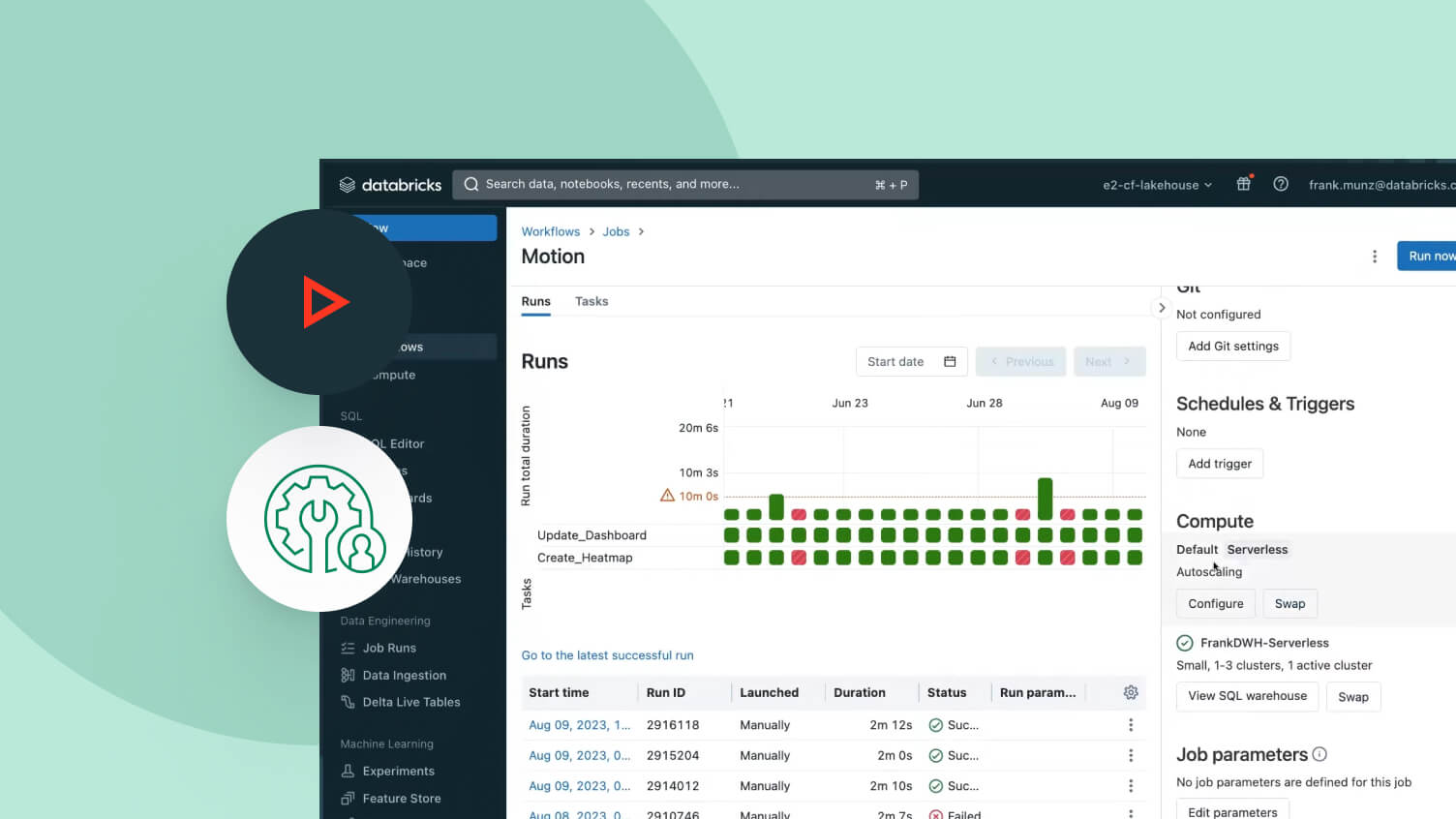
Lakeflow 작업
ETL, 분석 및 머신러닝 파이프라인에 대한 다중 작업 워크플로우를 쉽게 정의, 관리 및 모니터링합니다. 데이터 팀은 다양한 지원 작업 유형, 심층적인 관측 기능 및 높은 안정성을 기반으로 모든 파이프라인을 보다 효과적으로 자동화 및 오케스트레이션하고 생산성을 높일 수 있습니다.
Lakeflow 작업
ETL, 분석 및 머신러닝 파이프라인에 대한 다중 작업 워크플로우를 쉽게 정의, 관리 및 모니터링합니다. 데이터 팀은 다양한 지원 작업 유형, 심층적인 관측 기능 및 높은 안정성을 기반으로 모든 파이프라인을 보다 효과적으로 자동화 및 오케스트레이션하고 생산성을 높일 수 있습니다.

레이크하우스 스토리지
레이크하우스의 모든 형식과 유형의 데이터를 통합하여 모든 분석 및 AI 작업에 사용합니다.

Unity Catalog
업계 유일의 통합된 오픈 거버넌스 솔루션을 통해 모든 데이터 자산을 원활하게 관리하십시오. 이 솔루션은 Databricks Data Intelligence Platform에 내장되어 있습니다.
Data Intelligence Platform
Databricks Data Intelligence Platform을 통해 데이터 및 AI 워크로드를 지원하는 방법에 대해 자세히 알아보세요



