데이터 수집 참조 아키텍처
이 데이터 수집 참조 아키텍처는 다양한 기업 출처로부터 데이터를 Databricks 데이터 인텔리전스 플랫폼으로 로드하는데 간소화되고, 통합되며, 효율적인 기반을 제공합니다.
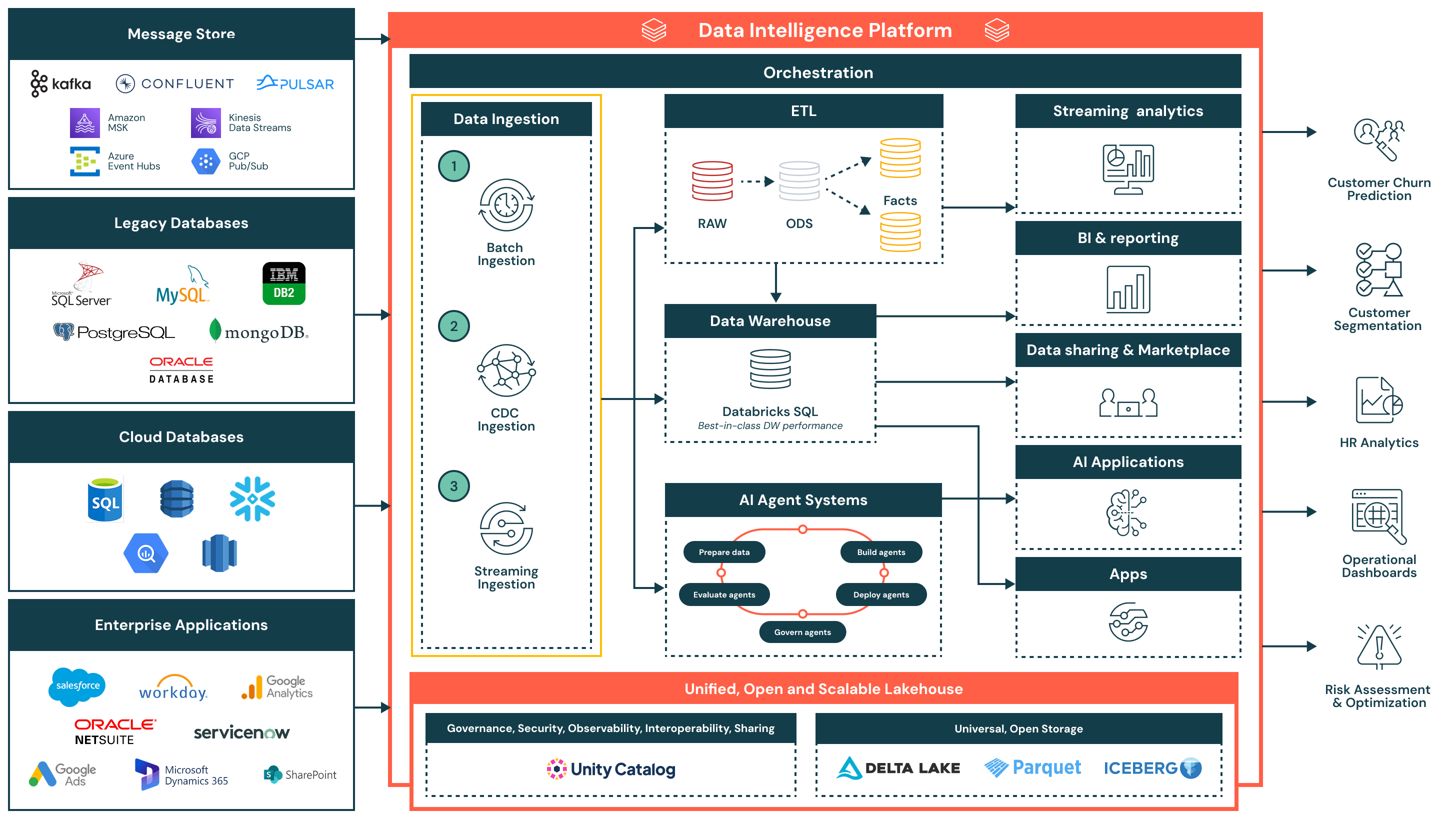
아키텍처 요약
데이터 수집 참조 아키텍처는 다양한 수집 패턴을 지원하며 — 배치, 변경 데이터 캡처(CDC), 스트리밍 등 — 동시에 거버넌스, 성능, 상호 운용성을 보장합니다. 수집된 데이터는 정제되어 분석, AI 및 조직 전체의 안전한 데이터 공유를 위해 사용 가능하게 됩니다.
이 아키텍처는 복잡성과 통합 오버헤드를 줄이면서 데이터 파이프라인을 현대화하고 운영화하려는 조직에 이상적입니다. 세 가지 핵심 원칙을 중심으로 구축되었습니다:
- 간단하고 유지 관리가 쉬움: 수집 파이프라인은 구축하고 관리하기 쉬워, 가치 창출 시간을 단축하고 운영 병목 현상을 줄이며, 팀 간에 데이터 접근성을 넓힙니다
- 레이크하우스 아키텍처와 통합: 데이터는 오픈 포맷을 사용하여 Unity Catalog의 거버넌스 하에 직접 레이크하우스로 흐르며, BI, AI 및 운영적 사용 사례 간의 일관성을 보장합니다
- 효율적인 종단간 흐름: 수집에서 변환 및 전달까지, 플랫폼은 중복, 지연 및 리소스 사용을 최소화하는 효율적인 증분 처리를 지원합니다
사용 사례
기술 사용 사례
- 주기적인 배치 수집 플랫 파일, 내보내기 또는 API에서 스테이징 영역으로
- 변경 데이터 캡처 (CDC) Oracle이나 PostgreSQL과 같은 트랜잭션 시스템에서 점진적으로 업데이트를 동기화하기 위한 수집
- 스트리밍 수집 실시간 대시보드나 알림 시스템에서 사용하기 위해 Kafka나 메시지 큐에서 실시간 이벤트 수집
- 레거시 시스템, 클라우드 네이티브 데이터베이스그리고 엔터프라이즈 SaaS 애플리케이션 간의 데이터 수집을 조화롭게
- 정제되고 변환된 데이터를 데이터 웨어하우스, AI 애플리케이션 및 외부 API에 공급
비즈니스 사용 사례
- 행동, 거래 및 지원 데이터를 수집하여 고객 이탈 예측
- ERP 및 CRM 시스템에서 신선한 운영 지표를 사용하여 경영진 대시보드를 구동
- 캠페인, 판매 및 제품 사용 데이터를 결합하여 고객 세분화
- Workday와 생산성 플랫폼에서 데이터를 통합하여 HR 분석 수행
- 거의 실시간으로 거래와 알림 피드를 분석하여 위험 평가 수행
데이터 수집 흐름 및 주요 기능
- 배치 수집
- 플랫 파일, API 또는 데이터베이스 내보내기와 같은 소스에서 예정된 간격이나 요청에 따라 데이터를 로드
- 일일 보고서, 역사적 데이터 로드 및 기록 시스템 스냅샷에 적합
- SQL 또는 Python을 사용한 네이티브 스케줄링, 재시도 로직 및 변환을 지원하는 전체 및 증분 로드 모두 지원
- 변경 데이터 캡처 (CDC) 수집
- Oracle, PostgreSQL 및 MySQL과 같은 트랜잭션 시스템에서 증분 변경을 캡처
- 전체 리로드 없이 레이크하우스 테이블을 업데이트하여 효율성과 데이터 신선도를 향상
- 사실 테이블, 감사 추적 및 보고 레이어에 대한 거의 실시간 데이터 동기화 가능
- 스트리밍 수집
- Kafka, Kinesis, Pub/Sub 또는 Event Hubs와 같은 이벤트 소스에서 데이터를 지속적으로 처리
- 실시간 대시보드, 알림 시스템 및 이상 탐지에 이상적
- 구조화된 스트리밍은 상태, 장애 허용성 및 처리량을 관리하여 운영 오버헤드를 줄임
추가 플랫폼 기능
- 통합 거버넌스
- Unity 카탈로그 는 접근 제어, 계보 및 감사 추적을 포함한 통합 거버넌스를 제공합니다
- 데이터는 델타 레이크 와 아파치 아이스버그™, 를 사용하여 개방적이고 상호 운용 가능한 형식으로 저장되어 도구와 환경 간의 유연성과 상호 운용성을 보장
- 중앙 집중식 오케스트레이션 계층은 파이프라인 스케줄링, 종속성, 모니터링 및 복구를 관리
- 레이크하우스 아키텍처: 수집된 데이터는 메달리온 아키텍처(Bronze, Silver, Gold)로 변환 및 모델링되어 Databricks SQL에서 고성능 쿼리를 가능하게 함
- 오케스트레이션: 내장된 오케스트레이션은 데이터 파이프라인, AI 워크플로우 및 배치 및 스트리밍 작업 간의 스케줄링된 작업을 관리하며, 종속성 관리 및 오류 처리에 대한 네이티브 지원을 제공
- AI 및 에이전트 시스템: 데이터는 피처를 준비하고, 모델을 평가하며, AI 기반 애플리케이션을 배포하기 위해 에이전트 시스템으로 피드됩니다
- 하류 소비:
- 스트리밍 분석: 핵심 지표와 운영 신호의 실시간 시각화
- BI/분석: Power BI, Lakeview 및 SQL 클라이언트와 같은 도구에 제공되는 정제된 데이터 세트
- AI 애플리케이션: 훈련 파이프라인과 추론 엔진에서 사용하는 관리된 데이터셋
- 데이터 공유 및 마켓플레이스: Delta Sharing을 통한 안전한 내부 및 외부 데이터 공유
- 운영 앱: 기업 도구에서의 임베디드 인텔리전스와 맥락적 인사이트



