Introduction aux fonctions de fenêtre dans Spark SQL
par Yin Huai et Michael Armbrust
Dans cet article de blog, nous présentons la nouvelle fonctionnalité de fonctions de fenêtre qui a été ajoutée dans Apache Spark. Les fonctions de fenêtre permettent aux utilisateurs de Spark SQL de calculer des résultats tels que le rang d'une ligne donnée ou une moyenne mobile sur une plage de lignes d'entrée. Elles améliorent considérablement l'expressivité des API SQL et DataFrame de Spark. Ce blog présentera d'abord le concept des fonctions de fenêtre, puis expliquera comment les utiliser avec Spark SQL et l'API DataFrame de Spark.
Qu'est-ce qu'une fonction de fenêtre ?
Avant la version 1.4, Spark SQL prenait en charge deux types de fonctions pouvant être utilisées pour calculer une seule valeur de retour. Les fonctions intégrées ou UDF, telles que substr ou round, prennent des valeurs d'une seule ligne en entrée et génèrent une seule valeur de retour pour chaque ligne d'entrée. Les fonctions d'agrégation, telles que SUM ou MAX, opèrent sur un groupe de lignes et calculent une seule valeur de retour pour chaque groupe.
Bien que ces deux types soient très utiles en pratique, il existe toujours un large éventail d'opérations qui ne peuvent pas être exprimées en utilisant uniquement ces types de fonctions. Plus précisément, il n'y avait aucun moyen d'opérer sur un groupe de lignes tout en retournant une seule valeur pour chaque ligne d'entrée. Cette limitation rend difficile la réalisation de diverses tâches de traitement de données telles que le calcul d'une moyenne mobile, le calcul d'une somme cumulative ou l'accès aux valeurs d'une ligne apparaissant avant la ligne actuelle. Heureusement pour les utilisateurs de Spark SQL, les fonctions de fenêtre comblent cette lacune.
Fondamentalement, une fonction de fenêtre calcule une valeur de retour pour chaque ligne d'entrée d'une table en fonction d'un groupe de lignes, appelé le Frame. Chaque ligne d'entrée peut avoir un cadre unique qui lui est associé. Cette caractéristique des fonctions de fenêtre les rend plus puissantes que les autres fonctions et permet aux utilisateurs d'exprimer diverses tâches de traitement de données qui sont difficiles (voire impossibles) à exprimer sans fonctions de fenêtre de manière concise. Examinons maintenant deux exemples.
Supposons que nous ayons une table productRevenue comme illustré ci-dessous.
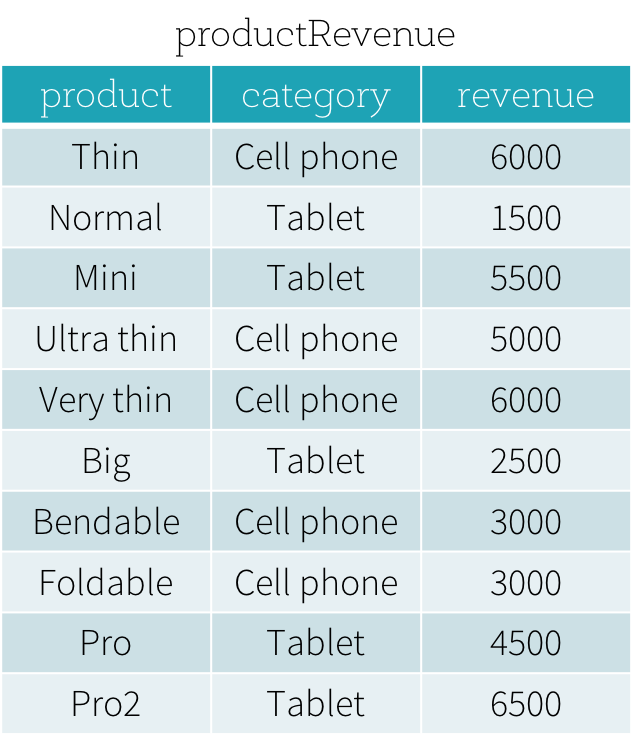
Nous voulons répondre à deux questions :
- Quels sont les produits les mieux vendus et les deuxièmes mieux vendus dans chaque catégorie ?
- Quelle est la différence entre le chiffre d'affaires de chaque produit et le chiffre d'affaires du produit le mieux vendu dans la même catégorie que ce produit ?
Pour répondre à la première question « Quels sont les produits les mieux vendus et les deuxièmes mieux vendus dans chaque catégorie ? », nous devons classer les produits d'une catégorie en fonction de leur chiffre d'affaires, et sélectionner les produits les mieux vendus et les deuxièmes mieux vendus en fonction du classement. Voici la requête SQL utilisée pour répondre à cette question en utilisant la fonction de fenêtre dense_rank (nous expliquerons la syntaxe d'utilisation des fonctions de fenêtre dans la section suivante).
Le résultat de ce programme est montré ci-dessous. Sans utiliser de fonctions de fenêtre, les utilisateurs doivent trouver toutes les valeurs de chiffre d'affaires les plus élevées de toutes les catégories, puis joindre cet ensemble de données dérivé avec la table productRevenue d'origine pour calculer les différences de chiffre d'affaires.
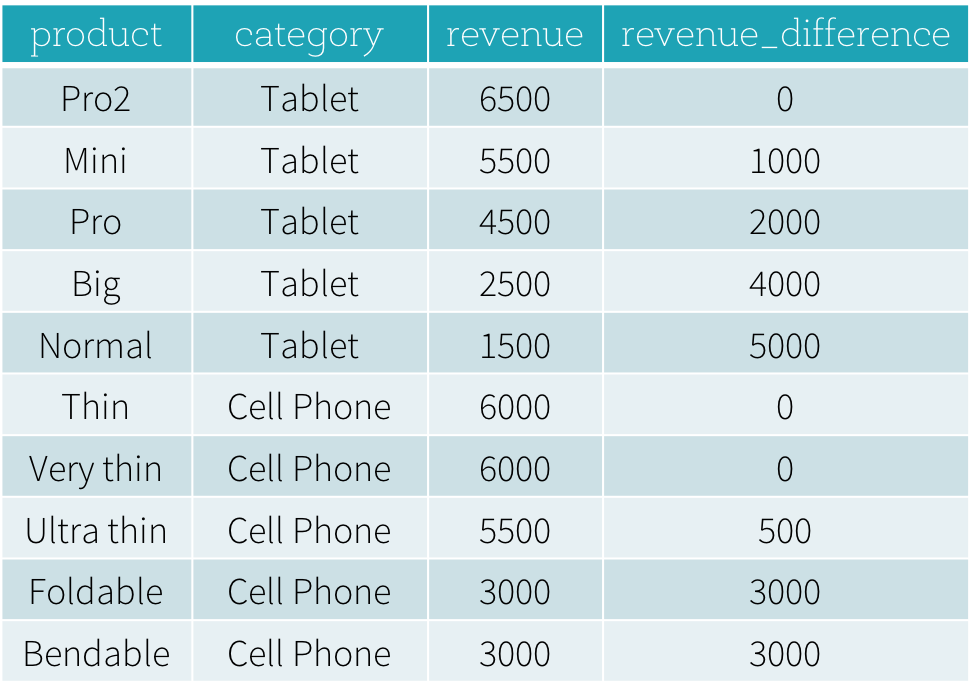
Utilisation des fonctions de fenêtre
Spark SQL prend en charge trois types de fonctions de fenêtre : les fonctions de classement, les fonctions analytiques et les fonctions d'agrégation. Les fonctions de classement et les fonctions analytiques disponibles sont résumées dans le tableau ci-dessous. Pour les fonctions d'agrégation, les utilisateurs peuvent utiliser n'importe quelle fonction d'agrégation existante comme fonction de fenêtre.
| SQL | DataFrame API | |
| Fonctions de classement | rank | rank |
| dense_rank | denseRank | |
| percent_rank | percentRank | |
| ntile | ntile | |
| row_number | rowNumber | |
| Fonctions analytiques | cume_dist | cumeDist |
| first_value | firstValue | |
| last_value | lastValue | |
| lag | lag | |
| lead | lead |
Pour utiliser les fonctions de fenêtre, les utilisateurs doivent indiquer qu'une fonction est utilisée comme fonction de fenêtre en
- Ajoutant une clause OVER après une fonction prise en charge en SQL, par exemple
avg(revenue) OVER (...); ou - Appelant la méthode over sur une fonction prise en charge dans l'API DataFrame, par exemple
rank().over(...).
Une fois qu'une fonction est marquée comme fonction de fenêtre, l'étape clé suivante consiste à définir la spécification de fenêtre associée à cette fonction. Une spécification de fenêtre définit quelles lignes sont incluses dans le cadre associé à une ligne d'entrée donnée. Une spécification de fenêtre comprend trois parties :
- Spécification de partitionnement : contrôle quelles lignes seront dans la même partition que la ligne donnée. De plus, l'utilisateur peut vouloir s'assurer que toutes les lignes ayant la même valeur pour la colonne de catégorie sont collectées sur la même machine avant l'ordonnancement et le calcul du cadre. Si aucune spécification de partitionnement n'est donnée, toutes les données doivent être collectées sur une seule machine.
- Spécification d'ordonnancement : contrôle la manière dont les lignes d'une partition sont ordonnées, déterminant la position de la ligne donnée dans sa partition.
- Spécification de cadre : indique quelles lignes seront incluses dans le cadre pour la ligne d'entrée actuelle, en fonction de leur position relative par rapport à la ligne actuelle. Par exemple, « les trois lignes précédant la ligne actuelle jusqu'à la ligne actuelle » décrit un cadre incluant la ligne d'entrée actuelle et trois lignes apparaissant avant la ligne actuelle.
En SQL, les mots-clés PARTITION BY et ORDER BY sont utilisés pour spécifier les expressions de partitionnement pour la spécification de partitionnement, et les expressions d'ordonnancement pour la spécification d'ordonnancement, respectivement. La syntaxe SQL est montrée ci-dessous.
OVER (PARTITION BY ... ORDER BY ...)
Dans l'API DataFrame, nous fournissons des fonctions utilitaires pour définir une spécification de fenêtre. En prenant Python comme exemple, les utilisateurs peuvent spécifier les expressions de partitionnement et les expressions d'ordonnancement comme suit.
En plus de l'ordonnancement et du partitionnement, les utilisateurs doivent définir la limite de début du cadre, la limite de fin du cadre et le type de cadre, qui sont les trois composantes d'une spécification de cadre.
Il existe cinq types de limites, qui sont UNBOUNDED PRECEDING, UNBOUNDED FOLLOWING, CURRENT ROW, UNBOUNDED PRECEDING et UNBOUNDED FOLLOWING représentent respectivement la première ligne de la partition et la dernière ligne de la partition. Pour les trois autres types de limites, ils spécifient le décalage par rapport à la position de la ligne d'entrée actuelle et leurs significations spécifiques sont définies en fonction du type de cadre. Il existe deux types de cadres, cadre ROW et cadre RANGE.
Cadre ROW
Les trames ROW sont basées sur des décalages physiques par rapport à la position de la ligne d'entrée actuelle, ce qui signifie que CURRENT ROW, CURRENT ROW est utilisé comme limite, il représente la ligne d'entrée actuelle. 1 PRECEDING comme limite de début et 1 FOLLOWING comme limite de fin (ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING dans la syntaxe SQL).
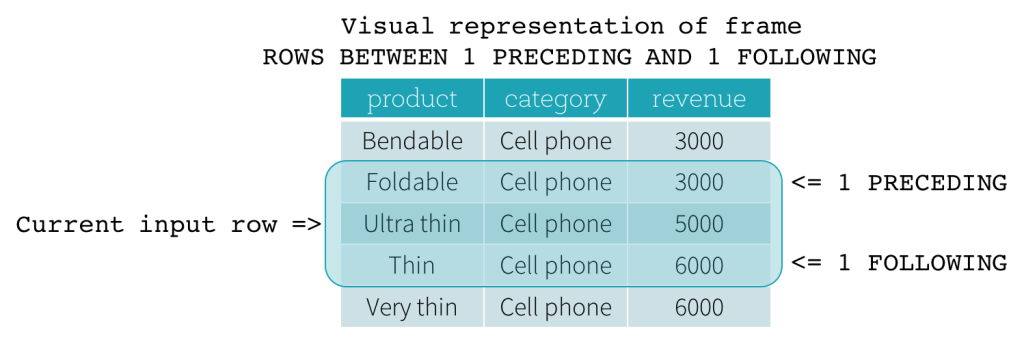
Trame RANGE
Les trames RANGE sont basées sur des décalages logiques par rapport à la position de la ligne d'entrée actuelle et ont une syntaxe similaire à la trame ROW. Un décalage logique est la différence entre la valeur de l'expression d'ordonnancement de la ligne d'entrée actuelle et la valeur de cette même expression de la ligne limite de la trame. En raison de cette définition, lorsqu'une trame RANGE est utilisée, une seule expression d'ordonnancement est autorisée. De plus, pour une trame RANGE, toutes les lignes ayant la même valeur d'expression d'ordonnancement que la ligne d'entrée actuelle sont considérées comme la même ligne en ce qui concerne le calcul de la limite.
Examinons maintenant un exemple. Dans cet exemple, l'expression d'ordonnancement est revenue ; la limite de début est 2000 PRECEDING ; et la limite de fin est 1000 FOLLOWING (cette trame est définie comme RANGE BETWEEN 2000 PRECEDING AND 1000 FOLLOWING dans la syntaxe SQL). Les cinq figures suivantes illustrent comment la trame est mise à jour avec la mise à jour de la ligne d'entrée actuelle. Fondamentalement, pour chaque ligne d'entrée actuelle, en fonction de la valeur du chiffre d'affaires, nous calculons la plage de chiffre d'affaires [valeur du chiffre d'affaires actuel - 2000, valeur du chiffre d'affaires actuel + 1000]. Toutes les lignes dont les valeurs de chiffre d'affaires se situent dans cette plage font partie de la trame de la ligne d'entrée actuelle.
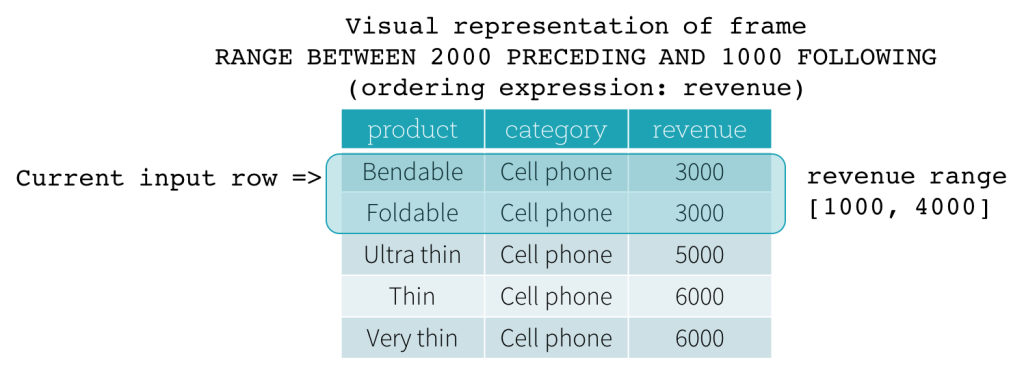
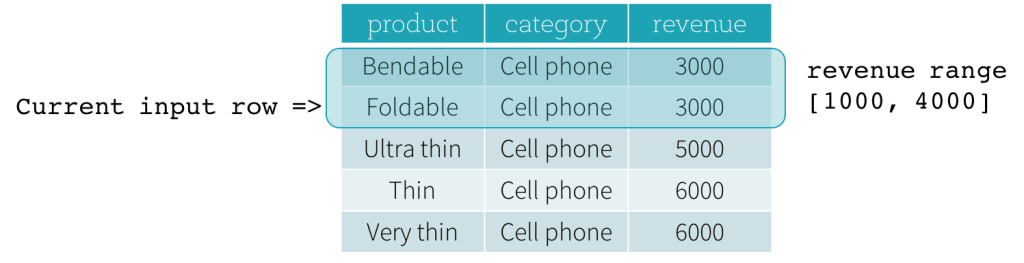
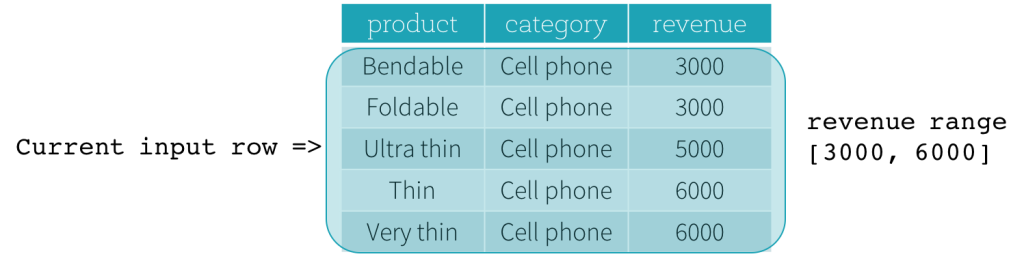
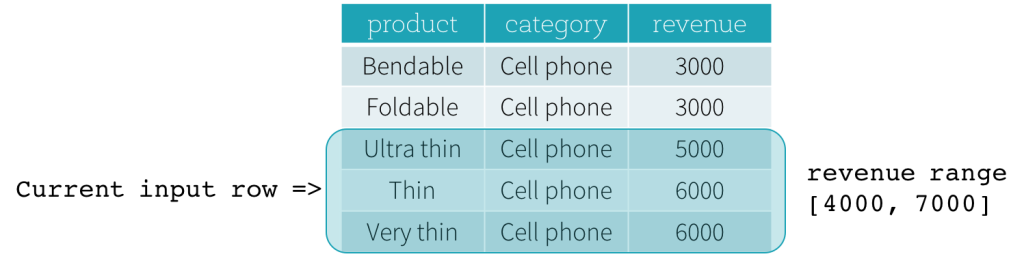
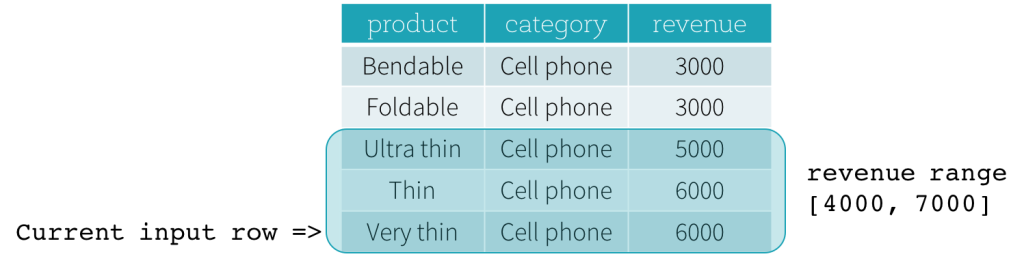
En résumé, pour définir une spécification de fenêtre, les utilisateurs peuvent utiliser la syntaxe suivante en SQL.
OVER (PARTITION BY ... ORDER BY ... frame_type BETWEEN start AND end)
Ici, frame_type peut être ROWS (pour la trame ROW) ou RANGE (pour la trame RANGE) ; start peut être UNBOUNDED PRECEDING, CURRENT ROW, end peut être UNBOUNDED FOLLOWING, CURRENT ROW,
Dans l'API DataFrame Python, les utilisateurs peuvent définir une spécification de fenêtre comme suit.
Et ensuite ?
Depuis la sortie de Spark 1.4, nous avons activement travaillé avec les membres de la communauté sur des optimisations qui améliorent les performances et réduisent la consommation mémoire de l'opérateur évaluant les fonctions de fenêtre. Certaines d'entre elles seront ajoutées dans Spark 1.5, et d'autres dans nos futures versions. Outre le travail d'amélioration des performances, nous allons ajouter deux fonctionnalités dans un avenir proche pour rendre le support des fonctions de fenêtre dans Spark SQL encore plus puissant. Premièrement, nous avons travaillé à l'ajout du support du type de données Interval pour les types de données Date et Timestamp (SPARK-8943). Avec le type de données Interval, les utilisateurs peuvent utiliser des intervalles comme valeurs spécifiées dans
Pour essayer ces fonctionnalités Spark, obtenez un essai gratuit de Databricks ou utilisez la Community Edition.
Remerciements
Le développement du support des fonctions de fenêtre dans Spark 1.4 est le fruit d'un travail conjoint de nombreux membres de la communauté Spark. En particulier, nous tenons à remercier Wei Guo pour avoir contribué au patch initial.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.