Comment simplifier la CDC avec le flux de données de modification de Delta Lake
par Surya Sai Turaga et John O'Dwyer
Essayez ce notebook dans Databricks
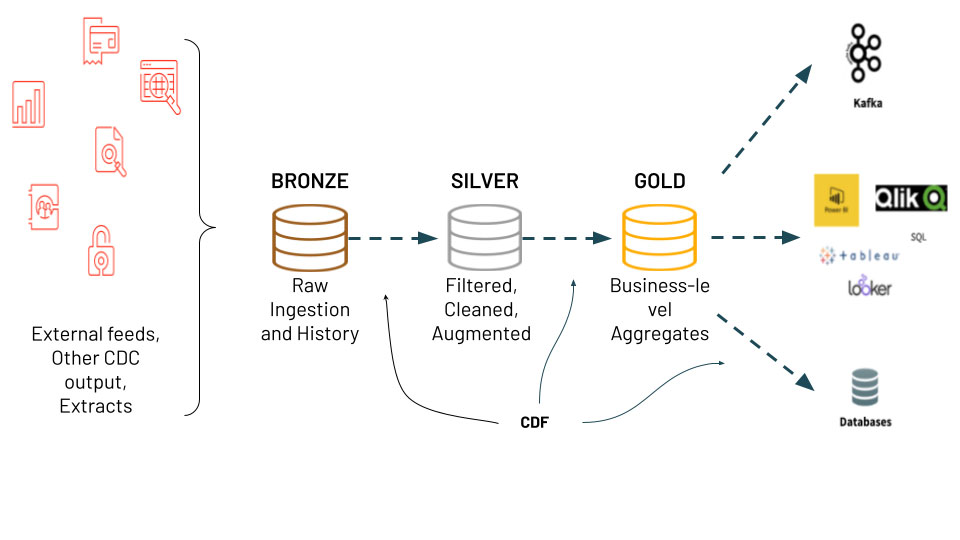
La capture de données modifiées (CDC) est un cas d'utilisation que de nombreux clients implémentent dans Databricks – vous pouvez consulter notre précédente analyse approfondie sur le sujet ici. Généralement, nous voyons la CDC utilisée dans une architecture d'ingestion vers l'analytique appelée architecture médaillon. L'architecture médaillon prend les données brutes débarquées des systèmes sources et affine les données à travers des tables bronze, silver et gold. La CDC et l'architecture médaillon offrent de multiples avantages aux utilisateurs car seules les données modifiées ou ajoutées doivent être traitées. De plus, les diff�érentes tables de l'architecture permettent à différents personas, tels que les Data Scientists et les analystes BI, d'utiliser les données correctes et à jour pour leurs besoins. Nous sommes heureux d'annoncer la nouvelle fonctionnalité passionnante Change Data Feed (CDF) dans Delta Lake qui rend cette architecture plus simple à implémenter et les opérations MERGE ainsi que la gestion des versions de log de Delta Lake possibles !
Obtenez un aperçu en avant-première du nouveau livre électronique d'O'Reilly pour obtenir les instructions étape par étape dont vous avez besoin pour commencer à utiliser Delta Lake.
Pourquoi la fonctionnalité CDF est-elle nécessaire ?
De nombreux clients utilisent Databricks pour effectuer la CDC, car elle est plus simple à implémenter avec Delta Lake par rapport à d'autres technologies Big Data. Cependant, même avec les bons outils, la CDC peut encore être difficile à exécuter. Nous avons conçu la CDF pour simplifier encore plus le codage et résoudre les principaux problèmes liés à la CDC, notamment :
- Contrôle qualité - Les modifications au niveau des lignes sont difficiles à obtenir entre les versions.
- Inefficacité - Il peut être inefficace de tenir compte des lignes qui ne changent pas, car les modifications de la version actuelle se font au niveau du fichier et non au niveau de la ligne.
Voici comment l'implémentation du Change Data Feed (CDF) aide à résoudre les problèmes ci-dessus :
- Simplicité et commodité - Utilise un modèle courant et facile à utiliser pour identifier les modifications, rendant votre code simple, pratique et facile à comprendre.
- Efficacité - La capacité de n'avoir que les lignes qui ont changé entre les versions rend la consommation en aval des opérations Merge, Update et Delete extrêmement efficace.
La CDF capture les modifications uniquement à partir d'une table Delta et est uniquement prospective une fois activée.
Change Data Feed en action !
Plongeons dans un exemple de CDF pour un cas d'utilisation courant : les prévisions financières. Le notebook référencé en haut de ce blog ingère des données financières. Les estimations de bénéfices par action (BPA) sont des données financières d'analystes prédisant les bénéfices par action trimestriels d'une entreprise. Les données brutes peuvent provenir de nombreuses sources différentes et de plusieurs analystes pour plusieurs actions.
Avec la fonctionnalité CDF, les données sont simplement insérées dans la table bronze (ingestion brute), puis filtrées, nettoyées et augmentées dans la table silver, et enfin, les valeurs agrégées sont calculées dans la table gold en fonction des données modifiées dans la table silver.
Bien que ces transformations puissent devenir complexes, heureusement, la fonctionnalité CDF basée sur les lignes est maintenant simple et efficace. Mais comment l'utiliser ? Creusons !
NOTE : L'exemple ici se concentre sur la version SQL de la CDF et également sur une manière spécifique d'utiliser les opérations ; pour évaluer les variations, veuillez consulter la documentation ici
Activation de la CDF sur une table Delta Lake
Pour que la fonctionnalité CDF soit disponible sur une table, vous devez d'abord activer la fonctionnalité sur ladite table. Ci-dessous, un exemple d'activation de la CDF pour la table bronze lors de la création de la table. Vous pouvez également activer la CDF sur une table en tant que mise à jour de la table. De plus, vous pouvez activer la CDF sur un cluster pour toutes les tables créées par le cluster. Pour ces variations, veuillez consulter la documentation ici.

Le Change Data Feed est une fonctionnalité prospective ; il capturera les modifications une fois la propriété de la table configurée et pas avant.
Interrogation des données modifiées
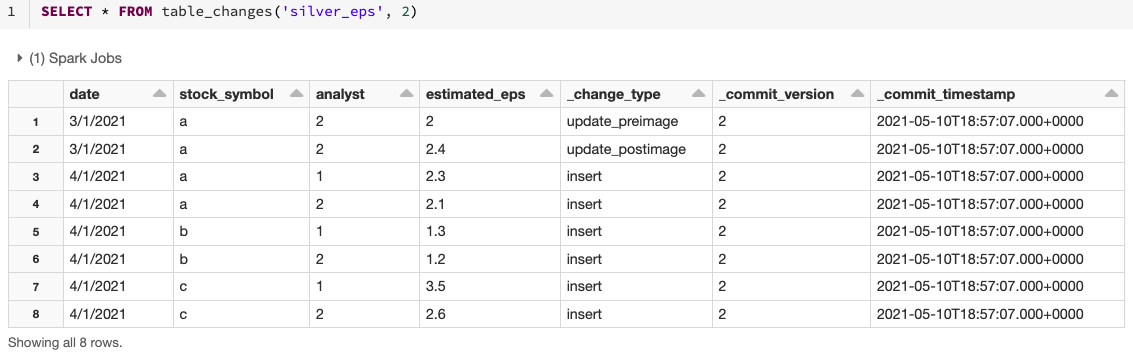
Pour interroger les données modifiées, utilisez l'opération table_changes. L'exemple ci-dessous inclut les lignes insérées et deux lignes représentant l'image avant et après une ligne mise à jour, afin que nous puissions évaluer les différences dans les modifications si nécessaire. Il existe également un type de modification delete qui est retourné pour les lignes supprimées.
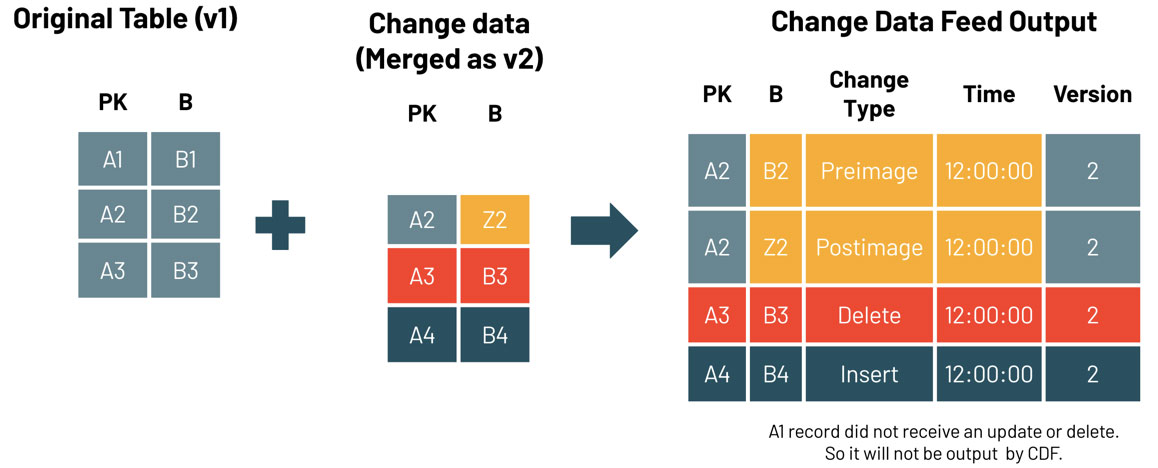
Cet exemple accède aux enregistrements modifiés en fonction de la version de départ, mais vous pouvez également limiter les versions en fonction de la version de fin, ainsi que des horodatages de début et de fin si nécessaire. Cet exemple se concentre sur SQL, mais il existe également des moyens d'accéder à ces données en Python, Scala, Java et R. Pour ces variations, veuillez consulter la documentation ici.
Utilisation des données de ligne CDF dans une instruction MERGE
Les instructions MERGE agrégées, comme la fusion dans la table gold, peuvent être complexes par nature, mais la fonctionnalité CDF simplifie et rend plus efficaces le codage de ces instructions.
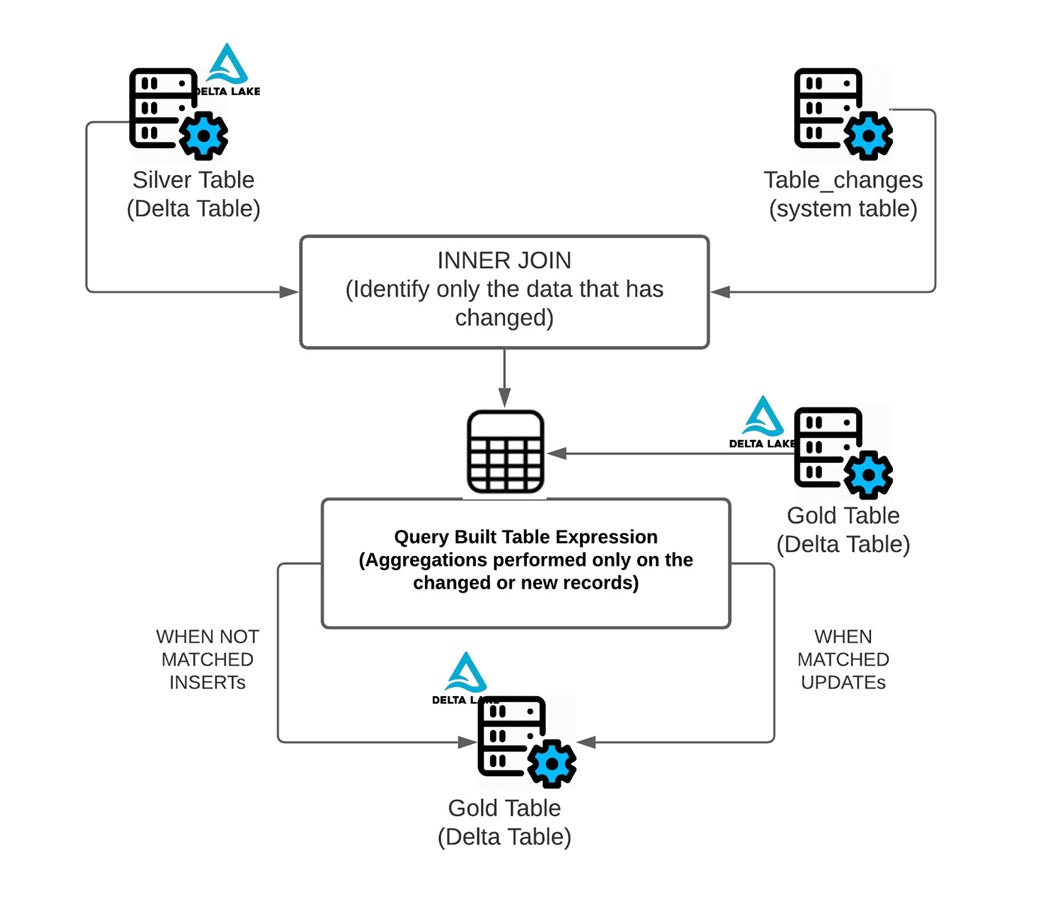
Comme vu dans le diagramme ci-dessus, la CDF permet de dériver facilement les lignes qui ont changé, car elle n'effectue l'agrégation nécessaire que sur les données qui ont changé ou sont nouvelles en utilisant l'opération table_changes. Ci-dessous, vous pouvez voir comment utiliser les données modifiées pour déterminer quelles dates et quels symboles boursiers ont changé.
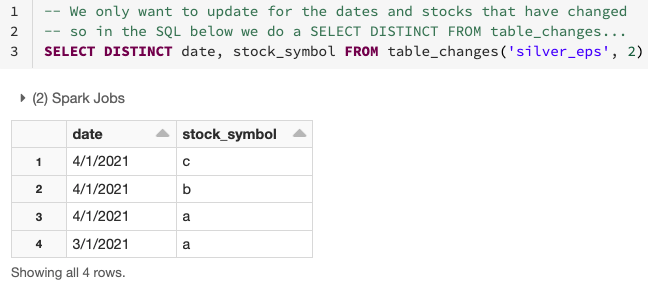
Comme indiqué ci-dessous, vous pouvez utiliser les données modifiées de la table silver pour agréger uniquement les données des lignes qui doivent être mises à jour ou insérées dans la table gold. Pour ce faire, utilisez INNER JOIN sur table_changes('nom_table','version')
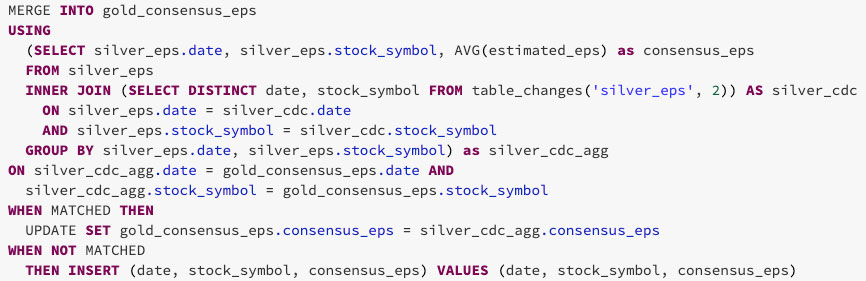
Le résultat final est une version claire et concise d'une table gold qui peut changer de manière incrémentielle au fil du temps !
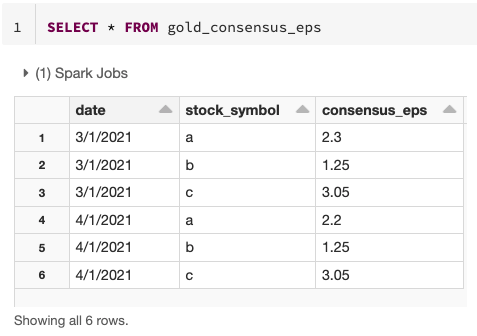
Cas d'utilisation typiques
Voici quelques cas d'utilisation courants et avantages de la nouvelle fonctionnalité CDF :
Tables Silver et Gold
Améliorez les performances de Delta en ne traitant que les modifications suivant la comparaison MERGE initiale pour accélérer et simplifier les opérations ETL/ELT.
Vues matérialisées
Créez des vues d'informations à jour et agrégées à utiliser dans la BI et l'analytique sans avoir à retraiter les tables sous-jacentes complètes, en mettant plutôt à jour uniquement là où des modifications sont survenues.
Transmission des modifications
Envoyez le Change Data Feed aux systèmes en aval tels que Kafka ou RDBMS qui peuvent l'utiliser pour traiter de manière incrémentielle les étapes ultérieures des pipelines de données.
Table d'audit
La capture des sorties du Change Data Feed sous forme de table Delta permet un stockage perpétuel et une capacité de requête efficace pour visualiser toutes les modifications au fil du temps, y compris lorsque des suppressions se produisent et quelles mises à jour ont été effectuées.
Quand utiliser le Change Data Feed
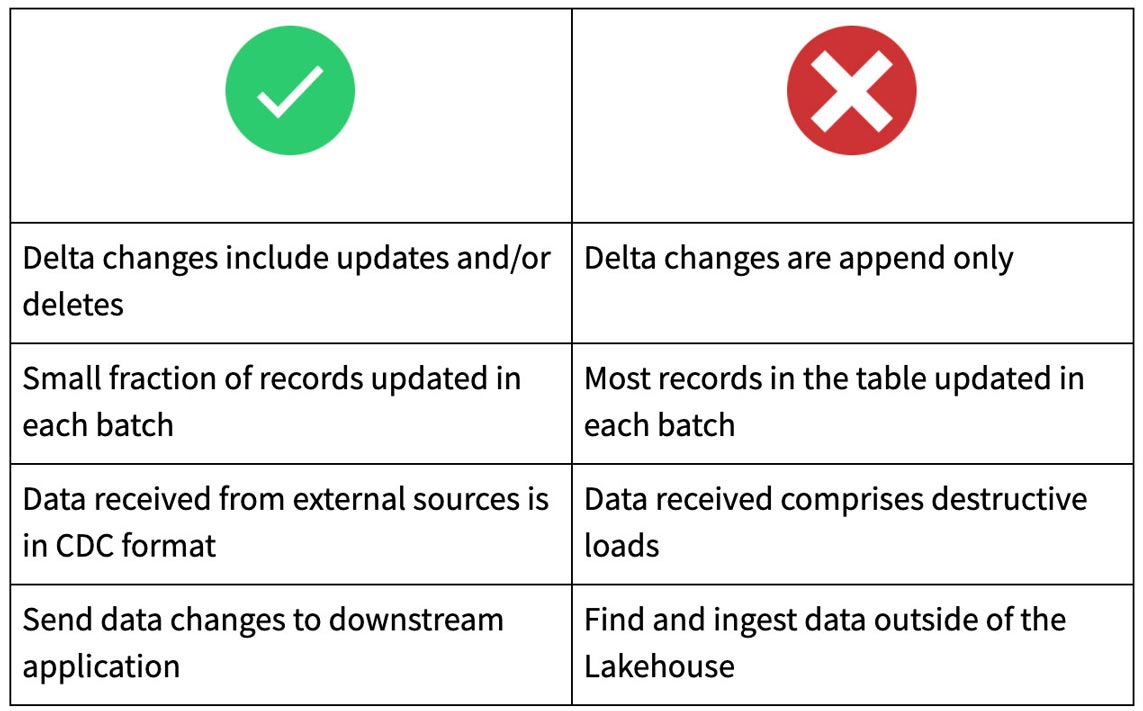
Conclusion
Chez Databricks, nous nous efforçons de rendre l'impossible possible et le difficile simple. La CDC, le versionnement des journaux et l'implémentation MERGE étaient pratiquement impossibles à grande échelle jusqu'à la création de Delta Lake. Nous le rendons maintenant plus simple et plus efficace avec la nouvelle fonctionnalité passionnante Change Data Feed (CDF) !
Essayez ce notebook dans Databricks
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.