Comment accélérer le flux de données entre Databricks et SAS
par Oleg Mikhov et Satish Garla
Ceci est un article collaboratif entre Databricks et T1A. Nous remercions Oleg Mikhov, Architecte Solutions chez T1A, pour ses contributions.
Ceci est le premier article d'une série de blogs sur les meilleures pratiques pour réunir la Databricks Lakehouse Platform et SAS. Un article de blog Databricks précédent a présenté Databricks et PySpark aux développeurs SAS. Dans cet article, nous discutons des moyens d'échanger des données entre la Databricks Lakehouse Platform et SAS, et des moyens d'accélérer le flux de données. Dans les articles futurs, nous explorerons la création de pipelines de données et d'analyse efficaces impliquant les deux technologies.
Les organisations axées sur les données adoptent rapidement la plateforme Lakehouse pour répondre aux demandes commerciales en constante croissance. La plateforme Lakehouse est devenue une nouvelle norme pour les organisations souhaitant construire des plateformes et des architectures de données. La modernisation implique le déplacement des données, des applications ou d'autres éléments commerciaux vers le cloud. Cependant, la transition vers le cloud est un processus graduel et il est essentiel pour l'entreprise de continuer à tirer parti des investissements existants aussi longtemps que possible. Dans cette optique, de nombreuses entreprises ont tendance à avoir plusieurs plateformes de données et d'analyse, où les plateformes coexistent et se complètent mutuellement.
L'une des combinaisons que nous observons est l'utilisation de SAS avec la Databricks Lakehouse. Il y a de nombreux avantages à permettre aux deux plateformes de travailler ensemble efficacement, tels que :
- Des capacités de stockage de données plus grandes et évolutives des plateformes cloud
- Une plus grande capacité de calcul utilisant des technologies, telles qu'Apache Spark™, nativement construites avec des capacités de traitement parallèle
- Atteindre une plus grande conformité avec la gouvernance et la gestion des données en utilisant Delta Lake
- Réduire le coût de l'infrastructure d'analyse de données grâce à des architectures simplifiées
Certains cas d'utilisation et raisons courants en science des données et en analyse de données observés sont :
- Les praticiens SAS tirent parti de SAS pour ses packages statistiques de base afin de développer des résultats d'analyse avancés qui répondent aux exigences réglementaires, tout en utilisant la Databricks Lakehouse pour la gestion des données, les traitements de type ELT et la gouvernance des données
- Les modèles d'apprentissage automatique développés dans SAS sont évalués sur des quantités massives de données en utilisant l'architecture de traitement parallèle du moteur Apache Spark dans la plateforme Lakehouse
- Les analystes de données SAS obtiennent un accès plus rapide à de grandes quantités de données dans la Lakehouse Platform pour des analyses ad hoc et des rapports en utilisant les points de terminaison Databricks SQL et des connecteurs à large bande passante
- Faciliter le parcours de modernisation et de migration cloud en établissant un flux de travail hybride impliquant à la fois l'architecture cloud et la plateforme SAS sur site
Cependant, un défi clé de cette coexistence est la manière dont les données sont partagées de manière performante entre les deux plateformes. Dans ce blog, nous partageons les meilleures pratiques mises en œuvre par T1A pour leurs clients et les résultats de référence comparant différentes méthodes de transfert de données entre Databricks et SAS.
Scénarios
Le cas d'utilisation le plus populaire est celui d'un développeur SAS essayant d'accéder aux données dans le lakehouse. Les pipelines d'analyse impliquant les deux technologies nécessitent un flux de données dans les deux sens : données déplacées de Databricks vers SAS et données déplacées de SAS vers Databricks.
- Accéder à Delta Lake depuis SAS : Un utilisateur SAS souhaite accéder aux big data dans Delta Lake en utilisant le langage de programmation SAS.
- Accéder aux jeux de données SAS depuis Databricks : Un utilisateur Databricks souhaite accéder aux jeux de données SAS, généralement les jeux de données sas7bdat, sous forme de DataFrame pour les traiter dans les pipelines Databricks ou les stocker dans Delta Lake pour un accès à l'échelle de l'entreprise.
Dans nos tests de référence, nous avons utilisé la configuration d'environnement suivante :
- Microsoft Azure comme plateforme cloud
- SAS 9.4M7 sur Azure (VM Standard D8s v3 à nœud unique)
- Databricks runtime 9.0, Apache Spark 3.1.2 (cluster Standard DS4v2 à 2 nœuds)
La Figure 1 montre le diagramme d'architecture conceptuelle avec les composants discutés. Databricks Lakehouse repose sur le stockage Azure Data Lake avec une architecture de médaillon Delta Lake. SAS 9.4 installé sur une VM Azure se connecte à la Databricks Lakehouse pour lire/écrire des données en utilisant les options de connexion discutées dans les sections suivantes.
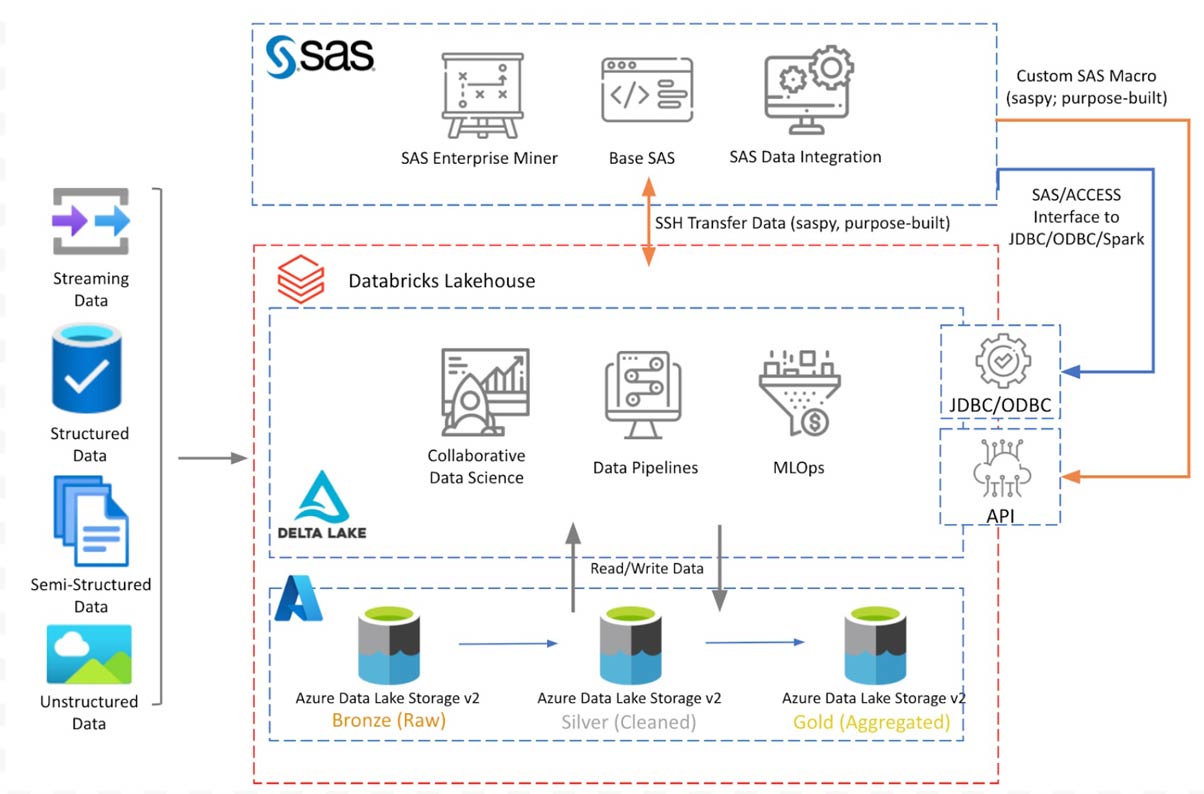
Le diagramme ci-dessus montre une architecture conceptuelle de Databricks déployé sur Azure. L'architecture sera similaire sur d'autres plateformes cloud. Dans ce blog, nous discutons uniquement de l'intégration avec la plateforme SAS 9.4. Dans un futur article de blog, nous étendrons cette discussion à l'accès aux données du lakehouse depuis SAS Viya.
Accéder à Delta Lake depuis SAS
Imaginez que nous ayons une table Delta Lake qui doit être traitée dans un programme SAS. Nous voulons les meilleures performances lors de l'accès à cette table, tout en évitant tout problème potentiel de compatibilité d'intégrité ou de types de données. Il existe différentes manières d'atteindre l'intégrité et la compatibilité des données. Ci-dessous, nous discutons de quelques méthodes et les comparons en termes de facilité d'utilisation et de performance.
Dans nos tests, nous avons utilisé le jeu de données sur le comportement e-commerce (5,67 Go, 9 colonnes, ~ 42 millions d'enregistrements) de Kaggle.
Crédit de la source de données : Données sur le comportement e-commerce d'un magasin multi-catégories et REES46 Marketing Platform.
Méthodes testées
1. Utilisation des connecteurs de l'interface SAS/ACCESS
Traditionnellement, les utilisateurs SAS utilisent le logiciel SAS/ACCESS pour se connecter à des sources de données externes. Vous pouvez utiliser une instruction LIBNAME SAS pointant vers le cluster Databricks ou utiliser la facilité de passage de requêtes SQL. Actuellement, pour SAS 9.4, trois options de connexion sont disponibles.
L'interface SAS/ACCESS pour Spark a récemment été dotée de fonctionnalités avec un support exclusif pour les clusters Databricks. Voir cette vidéo pour une courte démonstration. La vidéo mentionne SAS Viya mais cela s'applique également à SAS 9.4.
Des exemples de code sur la façon d'utiliser ces connecteurs peuvent être trouvés dans ce dépôt git : T1A Git - Exemples de bibliothèques SAS.
2. Utilisation du package saspy
La bibliothèque open-source, saspy, de SAS Institute permet aux utilisateurs de Notebook Databricks d'exécuter des instructions SAS à partir d'une cellule Python dans le notebook pour exécuter du code sur le serveur SAS, ainsi que pour importer et exporter des données des jeux de données SAS vers Pandas DataFrame.
Comme l'objectif de cette section est l'accès aux données du lakehouse par un programmeur SAS utilisant la programmation SAS, cette méthode a été encapsulée dans un programme macro SAS, similaire à la méthode d'intégration dédiée discutée ensuite.
Pour obtenir de meilleures performances avec ce package, nous avons testé la configuration avec une option char_length définie (détails disponibles ici). Avec cette option, nous pouvons définir les longueurs des champs caractères dans le jeu de données. Dans nos tests, l'utilisation de cette option a entraîné une augmentation supplémentaire de 15 % des performances. Pour la couche de transport entre les environnements, nous avons utilisé la configuration saspy avec une connexion SSH au serveur SAS.
3. Utilisation d'une intégration dédiée
Bien que les deux méthodes mentionnées ci-dessus aient leurs avantages, les performances peuvent être encore améliorées en abordant certaines lacunes, discutées dans la section suivante (Résultats des tests), des méthodes précédentes. Dans cette optique, nous avons développé un utilitaire d'intégration basé sur des macros SAS, axé principalement sur la performance et la facilité d'utilisation pour les utilisateurs SAS. La macro SAS peut être facilement intégrée dans le code SAS existant sans aucune connaissance de la plateforme Databricks, d'Apache Spark ou de Python.
La macro orchestre un processus en plusieurs étapes utilisant l'API Databricks :
- Demandez au cluster Databricks d'interroger et d'extraire les données selon la requête SQL fournie et de mettre les résultats en cache dans DBFS, en s'appuyant sur ses capacités de traitement distribué Spark SQL.
- Compressez et transférez de manière sécurisée le jeu de données vers le serveur SAS (CSV en GZIP) via SSH
- Décompressez et importez les données dans SAS pour les rendre disponibles à l'utilisateur dans la bibliothèque SAS. À cette étape, exploitez les métadonnées des colonnes du catalogue de données Databricks (types de colonnes, longueurs et formats) pour une présentation des données cohérente, correcte et efficace dans SAS.
Notez que pour les types de données de longueur variable, l'intégration prend en charge différentes options de configuration, en fonction de ce qui correspond le mieux aux exigences de l'utilisateur, telles que :
- la nécessité d'utiliser une valeur par défaut configurable
- le profilage de 10 000 lignes (+ ajout de marge) pour identifier la plus grande valeur
- le profilage de la colonne entière dans le jeu de données pour identifier la plus grande valeur
Une version simplifiée du code est disponible ici : T1A Git - SAS DBR Custom Integration.
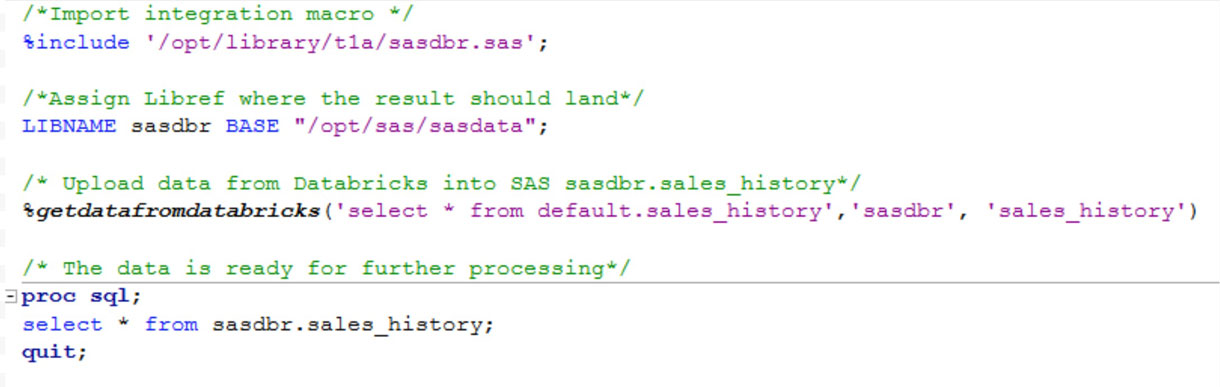
L'utilisation par l'utilisateur final de cette macro SAS se présente comme suit et prend trois entrées :
- Requête SQL, sur la base de laquelle les données seront extraites de Databricks
- Libref SAS où les données doivent atterrir
- Nom à donner au jeu de données SAS
Résultats des tests
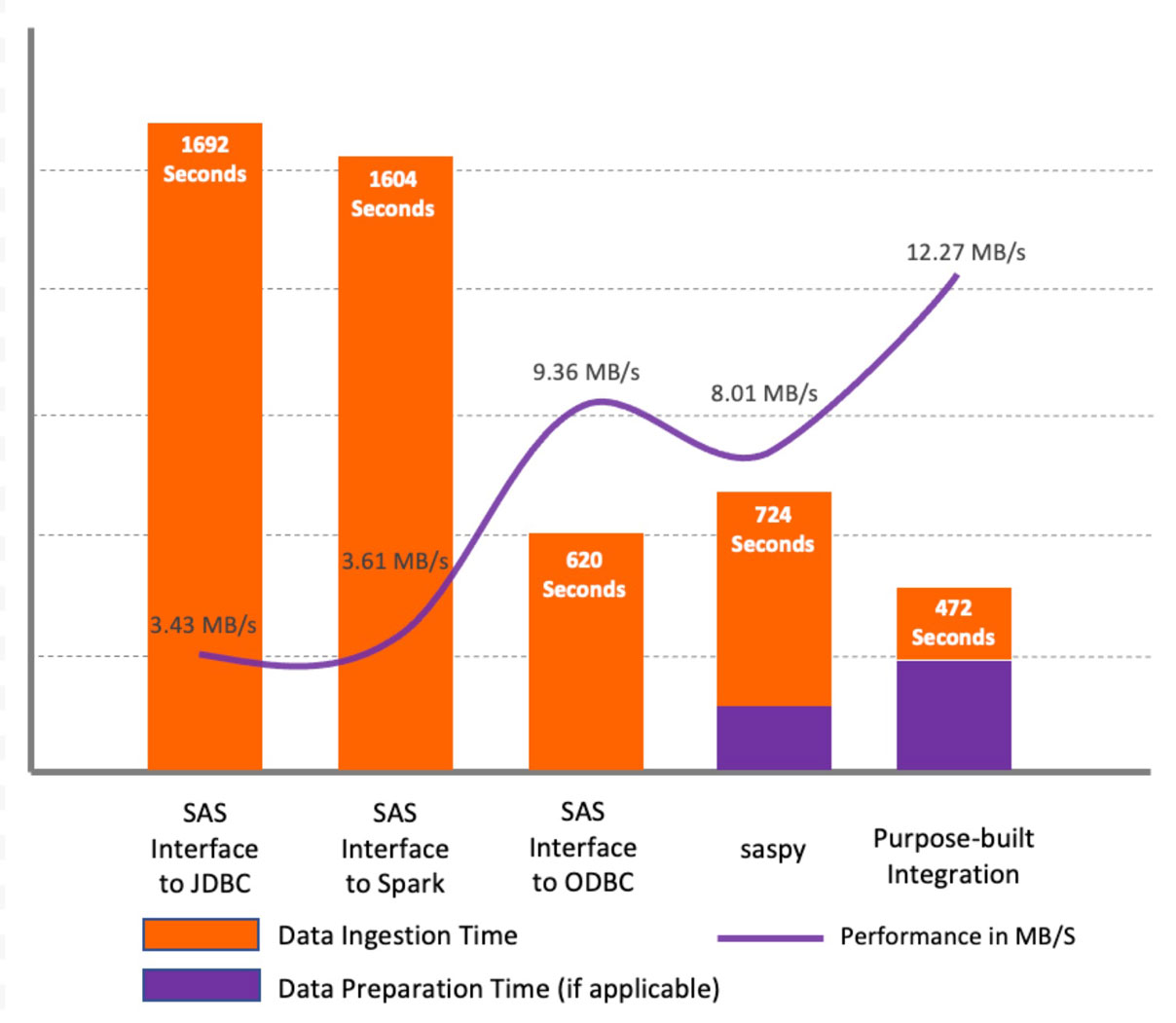
Comme le montre le graphique ci-dessus, pour le jeu de données de test, les résultats indiquent que SAS/ACCESS Interface to JDBC et SAS/ACCESS Interface to Apache Spark ont montré des performances similaires et inférieures par rapport aux autres méthodes. La raison principale est que les méthodes JDBC ne profilent pas les colonnes de caractères dans les jeux de données afin de définir une longueur de colonne appropriée dans le jeu de données SAS. Au lieu de cela, elles définissent la longueur par défaut pour tous les types de colonnes de caractères (String et Varchar) à 765 symboles. Cela entraîne non seulement des problèmes de performance lors de la récupération initiale des données, mais aussi pour tout traitement ultérieur. De plus, cela consomme un espace de stockage supplémentaire important. Dans nos tests, pour le jeu de données source de 5,6 Go, nous avons obtenu un fichier de 216 Go dans la bibliothèque WORK. Cependant, avec SAS/ACCESS Interface to ODBC, la longueur par défaut était de 255 symboles, ce qui a entraîné une augmentation significative des performances.
L'utilisation des méthodes SAS/ACCESS Interface est l'option la plus pratique pour les utilisateurs SAS existants. Il y a quelques considérations importantes lorsque vous utilisez ces méthodes :
- Les deux solutions prennent en charge le passage implicite de requêtes, mais avec quelques limitations :
- SAS/ACCESS Interface to JDBC/ODBC ne prend en charge le passage de requêtes que pour les instructions PROC SQL.
- En plus du passage de requêtes PROC SQL, SAS/ACCESS Interface to Apache Spark prend en charge le passage pour la plupart des fonctions SQL. Cette méthode permet également de pousser des procédures SAS courantes vers les clusters Databricks.
- Le problème de la définition de la longueur des colonnes de caractères décrit précédemment. Comme solution de contournement, nous suggérons d'utiliser l'option DBSASTYPE pour définir explicitement la longueur des colonnes pour les tables SAS. Cela aidera au traitement ultérieur du jeu de données, mais n'affectera pas la récupération initiale des données depuis Databricks.
- SAS/ACCESS Interface to Apache Spark/JDBC/ODBC ne permet pas de combiner des tables de différentes bases de données (schémas) Databricks assignées comme différents librefs dans la même requête (en les joignant) avec la facilité de passage de requêtes. Au lieu de cela, cela entraînera l'exportation de tables entières dans SAS et leur traitement dans SAS. Comme solution de contournement, nous suggérons de créer un schéma dédié dans Databricks qui contiendra des vues basées sur des tables de différentes bases de données (schémas).
L'utilisation de la méthode saspy a montré des performances légèrement meilleures par rapport aux méthodes SAS/ACCESS Interface to JDBC/Spark, cependant, le principal inconvénient est que la bibliothèque saspy ne fonctionne qu'avec des DataFrames pandas et qu'elle exerce une charge importante sur le programme pilote Apache Spark et nécessite que l'intégralité du DataFrame soit chargée en mémoire.
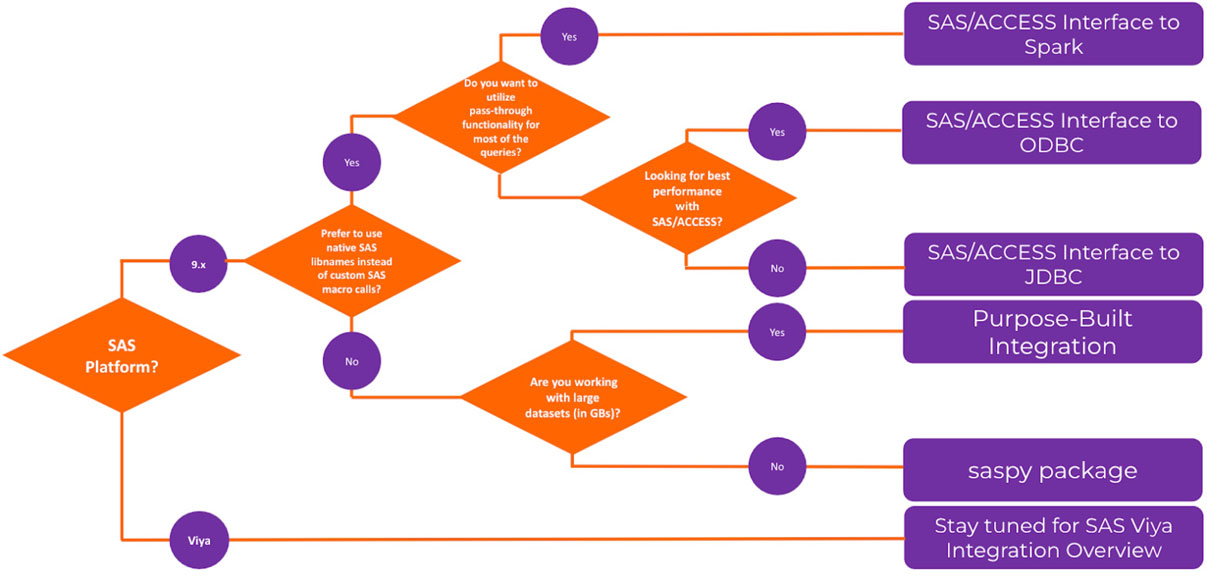
La méthode d'intégration spécialement conçue a montré les meilleures performances par rapport aux autres méthodes testées. La figure 3 montre un organigramme avec des directives générales pour choisir parmi les méthodes discutées.
Accéder aux jeux de données SAS depuis Databricks
Cette section répond au besoin des développeurs Databricks d'ingérer un jeu de données SAS dans Delta Lake et de le rendre disponible dans Databricks pour la business intelligence, l'analyse visuelle et d'autres cas d'utilisation d'analyse avancée. Bien que certaines des méthodes décrites précédemment soient applicables ici, d'autres méthodes supplémentaires sont discutées.
Dans le test, nous commençons avec un jeu de données SAS (au format sas7bdat) sur le serveur SAS, et à la fin, nous avons ce jeu de données disponible en tant que DataFrame Spark (si l'invocation paresseuse est applicable, nous forçons le chargement des données dans un DataFrame et mesurons le temps total) dans Databricks.
Nous avons utilisé le même environnement et le même jeu de données pour ce scénario que pour le scénario précédent. Les tests ne prennent pas en compte le cas d'utilisation où un utilisateur SAS écrit un jeu de données dans Delta Lake en utilisant la programmation SAS. Cela implique de prendre en compte les outils et les capacités des fournisseurs de cloud, qui seront abordés dans un article de blog ultérieur.
Méthodes testées
1. Utilisation du package saspy depuis SAS
La méthode sd2df de la bibliothèque saspy convertit un jeu de données SAS en un DataFrame pandas, en utilisant SSH pour le transfert de données. Elle offre plusieurs options de stockage temporaire (Mémoire, CSV, DISK) pendant le transfert. Dans notre test, l'option CSV, qui utilise PROC EXPORT en fichier CSV et les méthodes read_csv() de pandas, qui est l'option recommandée pour les grands jeux de données, a montré les meilleures performances.
2. Utilisation de la méthode pandas
Dès les premières versions, pandas a permis aux utilisateurs de lire des fichiers sas7bdat en utilisant l'API pandas.read_sas. Le fichier SAS doit être accessible au programme Python. Les méthodes couramment utilisées sont FTP, HTTP, ou le déplacement vers un stockage d'objets cloud tel que S3. Nous avons plutôt utilisé une approche plus simple pour déplacer un fichier SAS du serveur SAS distant vers le cluster Databricks en utilisant SCP.
3. Utilisation de spark-sas7bdat
Spark-sas7bdat est un package open-source développé spécifiquement pour Apache Spark. Similaire à la méthode pandas.read_sas(), le fichier SAS doit être disponible sur le système de fichiers. Nous avons téléchargé le fichier sas7bdat depuis un serveur SAS distant en utilisant SCP.
4. Utilisation d'une intégration spécialement conçue
Une autre méthode explorée consiste à utiliser des techniques conventionnelles en mettant l'accent sur l'équilibre entre la commodité et la performance. Cette méthode abstrait les intégrations principales et est mise à la disposition de l'utilisateur sous forme de bibliothèque Python exécutée depuis le Notebook Databricks.
- Utilisez le package saspy pour exécuter un code macro SAS (sur un serveur SAS) qui fait ce qui suit :
- Exportez sas7bdat en fichier CSV en utilisant du code SAS
- Compressez le fichier CSV en GZIP
- Déplacez le fichier compressé vers le nœud pilote du cluster Databricks en utilisant SCP
- Décompressez le fichier CSV
- Lisez le fichier CSV dans un DataFrame Apache Spark
Résultats des tests
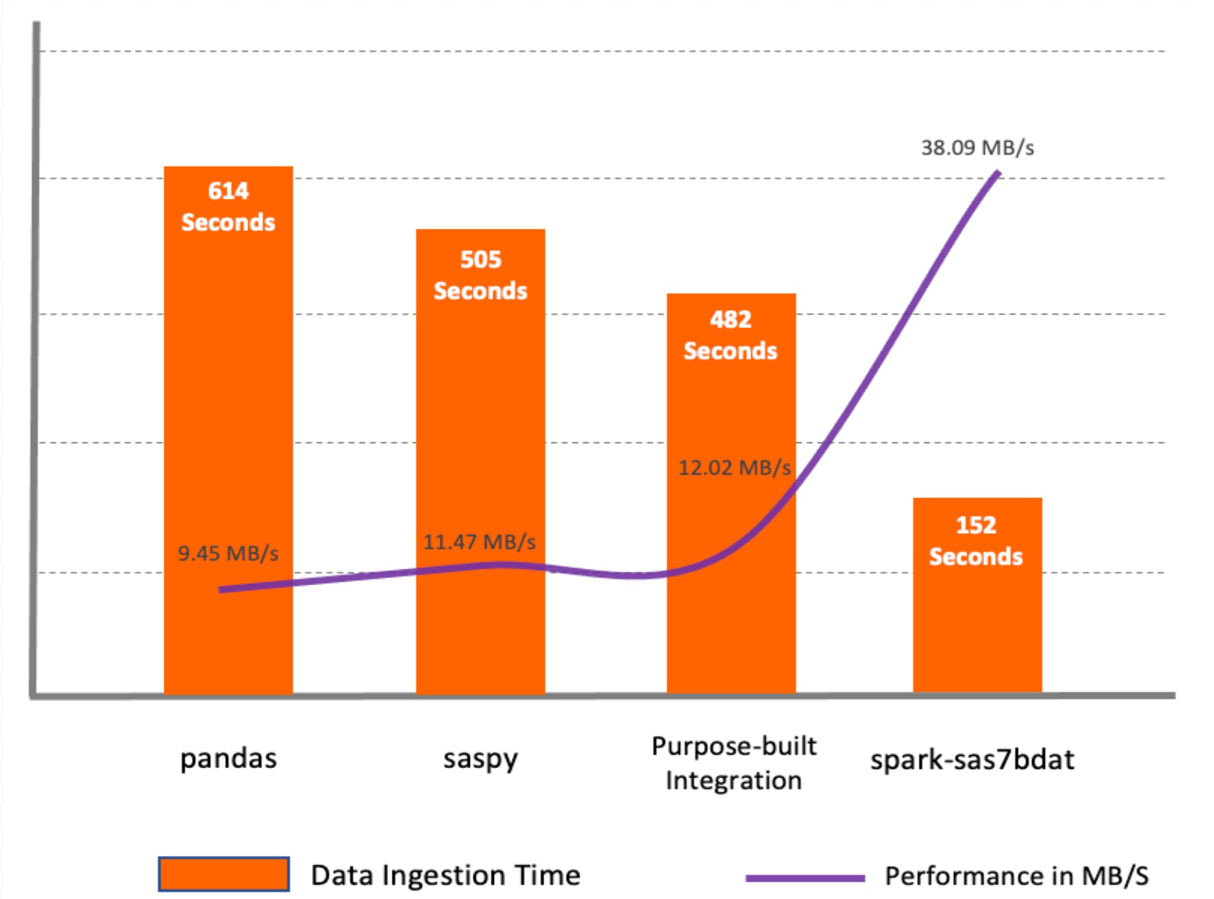
Le package spark-sas7bdat a montré les meilleures performances parmi toutes les méthodes. Ce package tire pleinement parti du traitement parallèle dans Apache Spark. Il distribue des blocs de fichiers sas7bdat sur les nœuds workers. Le principal inconvénient de cette méthode est que sas7bdat est un format binaire propriétaire, et la bibliothèque a été construite sur la base de l'ingénierie inverse de ce format binaire, elle ne prend donc pas en charge tous les types de fichiers sas7bdat, et elle n'est pas officiellement prise en charge par le fournisseur (commercialement).
Les méthodes saspy et pandas sont similaires dans la mesure où elles sont toutes deux conçues pour un environnement à nœud unique et lisent toutes deux les données dans un DataFrame pandas, nécessitant une étape supplémentaire avant que les données ne soient disponibles sous forme de DataFrame Spark.
La macro d'intégration dédiée a montré de meilleures performances par rapport à saspy et pandas car elle lit les données à partir de CSV via les API Apache Spark. Cependant, elle ne surpasse pas les performances du package spark-sas7bdat. La méthode dédiée peut être pratique dans certains cas car elle permet d'ajouter des transformations de données intermédiaires sur le serveur SAS.
Conclusion
De plus en plus d'entreprises se tournent vers la construction d'un Databricks Lakehouse et il existe plusieurs façons d'accéder aux données du Lakehouse via d'autres technologies. Ce blog explique comment les développeurs SAS, les data scientists et les autres utilisateurs professionnels peuvent exploiter les données du Lakehouse et écrire les résultats dans le cloud. Dans notre expérience, nous avons testé plusieurs méthodes différentes pour lire et écrire des données entre Databricks et SAS. Les méthodes varient non seulement par leurs performances, mais aussi par leur commodité et les capacités supplémentaires qu'elles offrent.
Pour ce test, nous avons utilisé la plateforme SAS 9.4M7. SAS Viya prend en charge la plupart des approches discutées, mais offre également des options supplémentaires. Si vous souhaitez en savoir plus sur les méthodes ou d'autres approches d'intégration spécialisées non abordées ici, n'hésitez pas à nous contacter à Databricks ou à databricks@t1a.com.
Dans les prochains articles de cette série de blogs, nous discuterons des meilleures pratiques pour la mise en œuvre de pipelines de données intégrés, des flux de travail de bout en bout, de l'utilisation de SAS et Databricks, et de la manière d'exploiter les technologies SAS In-Database pour le scoring des modèles SAS dans les clusters Databricks.
SAS® et tous les autres noms de produits ou services de SAS Institute Inc. sont des marques déposées ou des marques commerciales de SAS Institute Inc. aux États-Unis et dans d'autres pays. ® indique l'enregistrement aux États-Unis.
Pour commencer
Essayez le cours, Databricks pour les utilisateurs SAS, sur Databricks Academy pour acquérir une expérience pratique de base avec la programmation PySpark pour les constructions du langage de programmation SAS et contactez-nous pour en savoir plus sur la façon dont nous pouvons aider votre équipe SAS à intégrer ses charges de travail ETL sur Databricks et à adopter les meilleures pratiques.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.