Simplifier la capture des données de modification avec Databricks Delta Live Tables
par Mojgan Mazouchi
Ce guide vous montrera comment exploiter la capture de données modifiées (Change Data Capture) dans les pipelines Delta Live Tables pour identifier les nouveaux enregistrements et capturer les modifications apportées au jeu de données dans votre lac de données. Les pipelines Delta Live Tables vous permettent de développer des pipelines de données évolutifs, fiables et à faible latence, tout en effectuant la capture de données modifiées dans votre lac de données avec un minimum de ressources de calcul requises et une gestion transparente des données hors séquence.
Contexte sur la capture de données modifiées
La capture de données modifiées (Change Data Capture, CDC) est un processus qui identifie et capture les modifications incrémentielles (suppressions, insertions et mises à jour de données) dans les bases de données, comme le suivi du statut d'un client, d'une commande ou d'un produit pour les applications de données quasi en temps réel. La CDC fournit une évolution des données en temps réel en traitant les données de manière incrémentielle et continue à mesure que de nouveaux événements se produisent.
Étant donné que plus de 80 % des organisations prévoient de mettre en œuvre des stratégies multi-cloud d'ici 2025, choisir la bonne approche pour votre entreprise qui permet une centralisation transparente en temps réel de toutes les modifications de données dans votre pipeline ETL sur plusieurs environnements est essentiel.
En capturant les événements CDC, les utilisateurs de Databricks peuvent rematérialiser la table source sous forme de table Delta dans le Lakehouse et exécuter leurs analyses dessus, tout en pouvant combiner les données avec des systèmes externes. La commande MERGE INTO dans Delta Lake sur Databricks permet aux clients de mettre à jour et de supprimer efficacement des enregistrements dans leurs lacs de données – vous pouvez consulter notre analyse approfondie précédente sur le sujet ici. C'est un cas d'utilisation courant pour lequel nous observons que de nombreux clients Databricks exploitent Delta Lake, et qui maintient leurs lacs de données à jour avec les données commerciales en temps réel.
Bien que Delta Lake fournisse une solution complète pour la synchronisation CDC en temps réel dans un lac de données, nous sommes maintenant ravis d'annoncer la fonctionnalité de capture de données modifiées dans Delta Live Tables qui rend votre architecture encore plus simple, plus efficace et plus évolutive. DLT permet aux utilisateurs d'ingérer des données CDC de manière transparente en utilisant SQL et Python.
Les solutions CDC antérieures avec des tables Delta utilisaient l'opération MERGE INTO qui nécessite de trier manuellement les données pour éviter les échecs lorsque plusieurs lignes du jeu de données source correspondent lors de la tentative de mise à jour des mêmes lignes de la table Delta cible. Pour gérer les données hors séquence, une étape supplémentaire était nécessaire pour prétraiter la table source à l'aide d'une implémentation foreachBatch afin d'éliminer la possibilité de correspondances multiples, en ne conservant que la dernière modification pour chaque clé (voir l'exemple de capture de données modifiées). La nouvelle opération APPLY CHANGES INTO dans les pipelines DLT gère automatiquement et de manière transparente les données hors séquence, sans aucune intervention manuelle de l'ingénieur de données.
CDC avec Databricks Delta Live Tables
Dans cet article, nous allons démontrer comment utiliser la commande APPLY CHANGES INTO dans les pipelines Delta Live Tables pour un cas d'utilisation CDC courant où les données CDC proviennent d'un système externe. Une variété d'outils CDC sont disponibles tels que Debezium, Fivetran, Qlik Replicate, Talend et StreamSets. Bien que les implémentations spécifiques diffèrent, ces outils capturent et enregistrent généralement l'historique des modifications de données dans des journaux ; les applications en aval consomment ces journaux CDC. Dans notre exemple, les données sont déposées dans le stockage objet cloud à partir d'un outil CDC tel que Debezium, Fivetran, etc.
Nous avons des données provenant de divers outils CDC qui arrivent dans un stockage objet cloud ou une file d'attente de messages comme Apache Kafka. Généralement, nous voyons la CDC utilisée dans une ingestion vers ce que nous appelons l'architecture médaillon. Une architecture médaillon est un modèle de conception de données utilisé pour organiser logiquement les données dans un Lakehouse, dans le but d'améliorer progressivement la structure et la qualité des données à mesure qu'elles traversent chaque couche de l'architecture. Delta Live Tables vous permet d'appliquer de manière transparente les modifications provenant des flux CDC aux tables de votre Lakehouse ; combiner cette fonctionnalité avec l'architecture médaillon permet aux modifications incrémentielles de circuler facilement dans les charges de travail analytiques à grande échelle. L'utilisation de la CDC avec l'architecture médaillon offre de multiples avantages aux utilisateurs car seules les données modifiées ou ajoutées doivent être traitées. Ainsi, elle permet aux utilisateurs de maintenir de manière rentable les tables gold à jour avec les dernières données commerciales.
NOTE : L'exemple ici s'applique aux versions SQL et Python de la CDC ainsi qu'à une manière spécifique d'utiliser les opérations. Pour évaluer les variations, veuillez consulter la documentation officielle ici.
Prérequis
Pour tirer le meilleur parti de ce guide, vous devriez avoir une connaissance de base de :
- SQL ou Python
- Delta Live Tables
- Développement de pipelines ETL et/ou travail avec des systèmes Big Data
- Notebooks interactifs Databricks et clusters
- Vous devez avoir accès à un espace de travail Databricks avec les autorisations nécessaires pour créer de nouveaux clusters, exécuter des tâches et enregistrer des données dans un emplacement sur un stockage objet cloud externe ou DBFS.
- Pour le pipeline que nous créons dans cet article, l'édition produit "Advanced" qui prend en charge l'application des contraintes de qualité des données, doit être sélectionnée.
Le jeu de données
Ici, nous consommons des données CDC réalistes provenant d'une base de données externe. Dans ce pipeline, nous utiliserons la bibliothèque Faker pour générer le jeu de données qu'un outil CDC comme Debezium peut produire et importer dans le stockage cloud pour l'ingestion initiale dans Databricks. En utilisant Auto Loader, nous chargeons de manière incrémentielle les messages depuis le stockage objet cloud et les stockons dans la table Bronze, car elle contient les messages bruts. Les tables Bronze sont destinées à l'ingestion de données, permettant un accès rapide à une source unique de vérité. Ensuite, nous effectuons APPLY CHANGES INTO à partir de la table Bronze nettoyée pour propager les mises à jour en aval vers la table Silver. À mesure que les données parviennent aux tables Silver, elles deviennent généralement plus raffinées et optimisées ("juste assez") pour offrir à une entreprise une vue de toutes ses entités commerciales clés. Voir le schéma ci-dessous.
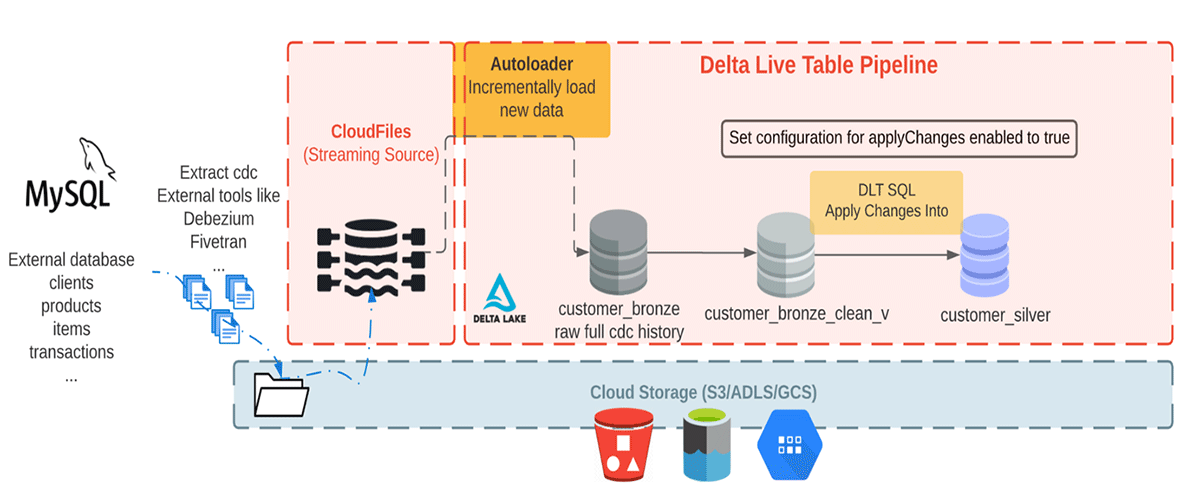
Cet article se concentre sur un exemple simple qui nécessite un message JSON avec quatre champs : nom du client, email, adresse et id, ainsi que deux champs : operation (qui stocke le code de l'opération (DELETE, APPEND, UPDATE, CREATE) et operation_date (qui stocke la date et l'heure de l'action de chaque opération) pour décrire les données modifiées.
Pour générer un jeu de données d'exemple avec les champs ci-dessus, nous utilisons un package Python qui génère des données fictives, Faker. Vous pouvez trouver le notebook lié à cette section de génération de données ici. Dans ce notebook, nous fournissons le nom et l'emplacement de stockage pour y écrire les données générées. Nous utilisons la fonctionnalité DBFS de Databricks, consultez la documentation DBFS pour en savoir plus sur son fonctionnement. Ensuite, nous utilisons une fonction définie par l'utilisateur PySpark pour générer le jeu de données synthétique pour chaque champ, et nous réécrivons les données à l'emplacement de stockage défini, auquel nous ferons référence dans d'autres notebooks pour accéder au jeu de données synthétique.
Ingestion du jeu de données brut à l'aide d'Auto Loader
Selon le paradigme de l'architecture médaillon, la couche bronze contient les données brutes de la plus haute qualité. À ce stade, nous pouvons lire de manière incrémentielle de nouvelles données à l'aide d'Autoloader à partir d'un emplacement de stockage cloud. Ici, nous ajoutons le chemin de notre jeu de données généré à la section de configuration sous les paramètres du pipeline, ce qui nous permet de charger le chemin source comme variable. Notre configuration sous les paramètres du pipeline ressemble donc à ceci :
Ensuite, nous chargeons cette propriété de configuration dans nos notebooks.
Jetons un coup d'œil à la table Bronze que nous allons ingérer : a. En SQL, et b. En utilisant Python
a. SQL
b. Python
Les instructions ci-dessus utilisent Auto Loader pour créer une table Streaming Live appelée customer_bronze à partir de fichiers JSON. Lorsque vous utilisez Autoloader dans Delta Live Tables, vous n'avez pas besoin de fournir d'emplacement pour le schéma ou le point de contrôle, car ces emplacements seront gérés automatiquement par votre pipeline DLT.
Auto Loader fournit une source Structured Streaming appelée cloud_files en SQL et cloudFiles en Python, qui prend un chemin de stockage cloud et un format comme paramètres.
Pour réduire les coûts de calcul, nous recommandons d'exécuter le pipeline DLT en mode Déclenché sous forme de micro-batch, en supposant que vous n'avez pas d'exigences de latence très faibles.
Attentes et données de haute qualité
Dans la prochaine étape pour créer un ensemble de données de haute qualité, diversifié et accessible, nous imposons des critères d'attente de contrôle de qualité en utilisant des Contraintes. Actuellement, une contrainte peut être de conserver, de supprimer ou d'échouer. Pour plus de détails, voir ici. Toutes les contraintes sont enregistrées pour permettre une surveillance de la qualité rationalisée.
a. SQL
b. Python
Utilisation de l'instruction APPLY CHANGES INTO pour propager les modifications à la table cible en aval
Avant d'exécuter la requête Apply Changes Into, nous devons nous assurer qu'une table de flux cible qui contiendra les données les plus à jour existe. Si elle n'existe pas, nous devons en créer une. Les cellules ci-dessous sont des exemples de création d'une table de flux cible. Notez qu'au moment de la publication de ce blog, l'instruction de création de table de flux cible est requise avec la requête Apply Changes Into, et les deux doivent être présentes dans le pipeline, sinon votre requête de création de table échouera.
a. SQL
b. Python
Maintenant que nous avons une table de flux cible, nous pouvons propager les modifications à la table cible en aval en utilisant la requête Apply Changes Into. Alors que le flux CDC est livré avec des événements INSERT, UPDATE et DELETE, le comportement par défaut de DLT est d'appliquer les événements INSERT et UPDATE de tout enregistrement dans l'ensemble de données source correspondant aux clés primaires, et séquencé par un champ qui identifie l'ordre des événements. Plus précisément, il met à jour toute ligne dans la table cible existante qui correspond à la ou aux clés primaires, ou insère une nouvelle ligne lorsqu'un enregistrement correspondant n'existe pas dans la table de flux cible. Nous pouvons utiliser APPLY AS DELETE WHEN en SQL, ou son équivalent apply_as_deletes en Python pour gérer les événements DELETE.
Dans cet exemple, nous avons utilisé "id" comme clé primaire, qui identifie de manière unique les clients et permet aux événements CDC de s'appliquer à ces enregistrements clients identifiés dans la table de flux cible. Étant donné que "operation_date" conserve l'ordre logique des événements CDC dans l'ensemble de données source, nous utilisons "SEQUENCE BY operation_date" en SQL, ou son équivalent "sequence_by = col("operation_date")" en Python pour gérer les événements de changement qui arrivent dans le désordre. Gardez à l'esprit que la valeur du champ que nous utilisons avec SEQUENCE BY (ou sequence_by) doit être unique parmi toutes les mises à jour de la même clé. Dans la plupart des cas, la colonne de séquence sera une colonne contenant des informations de timestamp.
Enfin, nous avons utilisé "COLUMNS * EXCEPT (operation, operation_date, _rescued_data)" en SQL, ou son équivalent "except_column_list"= ["operation", "operation_date", "_rescued_data"] en Python pour exclure trois colonnes de "operation", "operation_date", "_rescued_data" de la table de flux cible. Par défaut, toutes les colonnes sont incluses dans la table de flux cible, lorsque nous ne spécifions pas la clause "COLUMNS".
a. SQL
b. Python
Pour consulter la liste complète des clauses disponibles, voir ici.
Veuillez noter qu'au moment de la publication de ce blog, une table qui lit à partir de la cible d'une requête APPLY CHANGES INTO ou d'une fonction apply_changes doit être une table live et ne peut pas être une table de flux live.
Un notebook SQL et Python est disponible comme référence pour cette section. Maintenant que toutes les cellules sont prêtes, créons un pipeline pour ingérer des données à partir du stockage objet cloud. Ouvrez Jobs dans un nouvel onglet ou une nouvelle fenêtre de votre espace de travail, et sélectionnez "Delta Live Tables".
Le pipeline associé à ce blog a les paramètres de pipeline DLT suivants :
- Sélectionnez "Create Pipeline" pour créer un nouveau pipeline
- Spécifiez un nom tel que "Retail CDC Pipeline"
- Spécifiez les chemins des notebooks que vous avez déjà créés, un pour l'ensemble de données généré à l'aide du package Faker, et un autre chemin pour l'ingestion des données générées dans DLT. Le deuxième chemin de notebook peut faire référence au notebook écrit en SQL ou en Python, selon votre choix de langue.
- Pour accéder aux données générées dans le premier notebook, ajoutez le chemin du jeu de données dans la configuration. Ici, nous avons stocké les données dans "/tmp/demo/cdc_raw/customers", nous avons donc défini "source" sur "/tmp/demo/cdc_raw/" pour référencer "source/customers" dans notre second notebook.
- Spécifiez la Cible (ce qui est facultatif et fait référence à la base de données cible), où vous pouvez interroger les tables résultantes de votre pipeline.
- Spécifiez l'Emplacement de stockage dans votre stockage objet (ce qui est facultatif), pour accéder à vos jeux de données produits par DLT et aux journaux de métadonnées de votre pipeline.
- Définissez le Mode de pipeline sur Déclenché. En mode Déclenché, le pipeline DLT consommera toutes les nouvelles données de la source en une seule fois, et une fois le traitement terminé, il terminera automatiquement la ressource de calcul. Vous pouvez basculer entre les modes Déclenché et Continu lors de la modification des paramètres de votre pipeline. Définir "continuous": false dans le JSON équivaut à définir le pipeline en mode Déclenché.
- Pour cette charge de travail, vous pouvez désactiver la mise à l'échelle automatique sous Options Autopilot, et utiliser un seul worker cluster. Pour les charges de travail de production, nous recommandons d'activer la mise à l'échelle automatique et de définir le nombre maximum de workers nécessaires pour la taille du cluster.
- Sélectionnez "Démarrer"
- Votre pipeline est créé et en cours d'exécution !
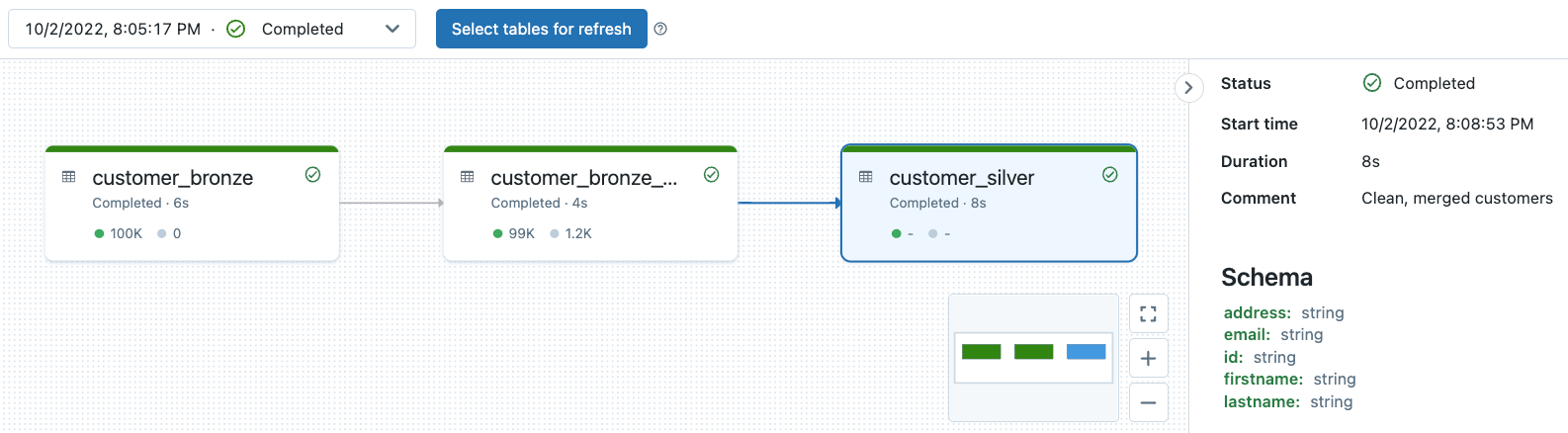
Observabilité de la lignée du pipeline DLT et surveillance de la qualité des données
Tous les journaux de pipeline DLT sont stockés dans l'emplacement de stockage du pipeline. Vous pouvez spécifier votre emplacement de stockage uniquement lors de la création de votre pipeline. Notez qu'une fois le pipeline créé, vous ne pouvez plus modifier l'emplacement de stockage.
Vous pouvez consulter notre précédente analyse approfondie sur le sujet ici. Essayez ce notebook pour voir l'observabilité du pipeline et la surveillance de la qualité des données sur l'exemple de pipeline DLT associé à ce blog.
Conclusion
Dans ce blog, nous avons montré comment nous avons rendu transparent pour les utilisateurs l'implémentation efficace de la capture de données modifiées (CDC) dans leur plateforme Lakehouse avec Delta Live Tables (DLT). DLT fournit des contrôles de qualité intégrés avec une visibilité approfondie sur les opérations du pipeline, en observant la lignée du pipeline, en surveillant le schéma et les contrôles de qualité à chaque étape du pipeline. DLT prend en charge la gestion automatique des erreurs et une capacité de mise à l'échelle automatique de premier ordre pour les charges de travail de streaming, ce qui permet aux utilisateurs d'avoir des données de qualité avec les ressources optimales requises pour leur charge de travail.
Les ingénieurs de données peuvent désormais implémenter facilement la CDC avec une nouvelle API déclarative APPLY CHANGES INTO avec DLT en SQL ou Python. Cette nouvelle fonctionnalité permet à vos pipelines ETL d'identifier facilement les modifications et d'appliquer ces modifications sur des dizaines de milliers de tables avec une prise en charge à faible latence.
Veuillez regarder ce webinaire pour apprendre comment Delta Live Tables simplifie la complexité de la transformation des données et de l'ETL, et consultez notre document Capture de données modifiées avec Delta Live Tables, le github officiel et suivez les étapes de cette vidéo pour créer votre pipeline !
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.