Utiliser un graphe de connaissances pour alimenter une couche sémantique de données pour Databricks
par Prasad Kona et Aaron Wallace
Ceci est un article collaboratif entre Databricks et Stardog. Nous remercions Aaron Wallace, chef de produit principal chez Stardog, pour sa contribution.
Les graphes de connaissances sont devenus omniprésents, sans même que nous le sachions. Nous les expérimentons chaque jour lorsque nous effectuons des recherches sur Google ou que nous regardons les flux qui parcourent nos comptes de réseaux sociaux des personnes que nous connaissons, des entreprises que nous suivons ou du contenu que nous aimons. De même, les graphes de connaissances d'entreprise fournissent une base pour structurer le contenu, les données et les actifs informationnels de votre organisation en extrayant, en reliant et en fournissant des connaissances sous forme de réponses, de recommandations et d'informations à chaque application axée sur les données, des chatbots aux moteurs de recommandation, en passant par l'amélioration de votre BI et de vos analyses.
Dans ce blog, vous apprendrez comment Databricks et Stardog résolvent le défi du dernier kilomètre dans la démocratisation des données et des insights. Databricks fournit une plateforme lakehouse pour les charges de travail de données, d'analyse et d'intelligence artificielle (IA) sur une plateforme multi-cloud. Stardog fournit une plateforme de graphe de connaissances capable de modéliser des relations complexes sur des données larges, et pas seulement volumineuses, pour décrire des personnes, des lieux, des choses et leurs relations. La Databricks Lakehouse Platform, associée à la couche sémantique basée sur les graphes de connaissances de Stardog, offre aux organisations une base pour une architecture de tissu de données d'entreprise qui permet aux équipes interfonctionnelles, inter-entreprises ou inter-organisationnelles de poser et de répondre à des requêtes complexes à travers les silos de domaines.
Le besoin croissant d'une architecture de tissu de données
L'innovation rapide et les perturbations dans le domaine de la gestion des données aident les organisations à exploiter la valeur des données disponibles à l'intérieur et à l'extérieur de l'entreprise. Les organisations opérant à travers des frontières physiques et numériques trouvent de nouvelles opportunités pour servir les clients de la manière dont ils souhaitent être servis.
Ces organisations ont connecté toutes les données pertinentes tout au long de la chaîne d'approvisionnement des données pour créer une image complète et précise dans le contexte de leurs cas d'utilisation. La plupart des industries qui cherchent à opérer et à partager des données au-delà des frontières organisationnelles pour harmoniser les données et permettre le partage de données adoptent des normes ouvertes sous forme d'ontologies prescrites, de FIBO dans les services financiers à D3FEND dans le domaine de la cybersécurité. Ces ontologies métier (ou modèles sémantiques) reflètent la façon dont nous pensons aux données avec un sens attaché, c'est-à-dire des « choses » plutôt que la façon dont les données sont structurées et stockées, c'est-à-dire des « chaînes de caractères », et rendent le partage et la réutilisation des données possibles.
L'idée d'une couche sémantique n'est pas nouvelle. Elle existe depuis plus de 30 ans, souvent promue par les fournisseurs de BI aidant les entreprises à créer des tableaux de bord dédiés. Cependant, l'adoption généralisée a été entravée, étant donné la nature intégrée de cette couche dans le cadre d'un système de BI propriétaire. Cette couche est souvent trop rigide et complexe, souffrant des mêmes limitations qu'un système de base de données relationnelle physique qui modélise les données pour optimiser son langage de requête structuré plutôt que la façon dont les données sont liées dans le monde réel — plusieurs-à-plusieurs. Une couche de données sémantique alimentée par un graphe de connaissances qui opère entre vos couches de stockage et de consommation fournit ce lien et ce multiplicateur qui connecte toutes les données pour fournir de la valeur dans le contexte du cas d'utilisation métier aux scientifiques de données citoyens et aux analystes qui, autrement, ne peuvent pas participer et collaborer dans des architectures centrées sur les données en dehors d'une poignée de spécialistes.
Activer un cas d'utilisation autour de l'assurance
Examinons un exemple concret d'une organisation d'assurance multi-compagnies pour illustrer comment Stardog et Databricks travaillent ensemble. Comme la plupart des grandes entreprises, de nombreuses compagnies d'assurance sont confrontées à des défis similaires en matière de données, tels que le manque de disponibilité généralisée des données provenant de sources internes et externes pour la prise de décision par les parties prenantes critiques. Tout le monde, de l'évaluation des risques de souscription à l'administration des polices, en passant par la gestion des sinistres et les agences, a du mal à exploiter les bonnes données et les bons insights pour prendre des décisions critiques. Ils ont tous besoin d'un tissu de données d'entreprise qui rassemble les éléments d'une architecture de données et d'analyse moderne pour rendre les données FAIR — Trouvable, Accessible, Interopérable et Réutilisable. La plupart des entreprises commencent leur parcours en intégrant toutes les sources de données dans un data lake. L'approche lakehouse de Databricks fournit aux entreprises une excellente base pour stocker toutes leurs données analytiques et rendre toutes les données accessibles à toute personne au sein de l'entreprise. Dans cette couche de données, tout le nettoyage, la transformation et la désambiguïsation ont lieu. La prochaine étape de ce parcours est l'harmonisation des données, en connectant les données en fonction de leur signification pour fournir un contexte plus riche. Une couche sémantique, fournie par un graphe de connaissances, déplace l'accent sur l'analyse et le traitement des données et fournit un tissu connecté d'insights inter-domaines aux souscripteurs, aux analystes des risques, aux agents et aux équipes de service client pour gérer les risques et offrir une expérience client exceptionnelle.
Nous examinerons comment cela fonctionnerait avec un modèle sémantique simplifié comme point de départ.
Modéliser facilement des entités spécifiques au domaine et des relations inter-domaines
La création visuelle d'un modèle de données sémantique via une expérience de type tableau blanc est la première étape de la création d'une couche de données sémantique. Dans le projet Stardog Designer, cliquez simplement pour créer des classes (ou entités) spécifiques qui sont essentielles pour répondre à vos questions métier. Une fois une classe créée, vous pouvez ajouter tous les attributs et types de données nécessaires pour décrire cette nouvelle entité. Lier des classes (ou entités) ensemble est facile. Avec une entité sélectionnée, cliquez simplement pour ajouter un lien et faites glisser le point de la nouvelle relation jusqu'à ce qu'il s'accroche à l'autre entité. Donnez à cette nouvelle relation un nom qui décrit le sens métier (par exemple, un « Client » « possède » un « Véhicule »).
Ajoutez une nouvelle classe et liez-la à une classe existante pour créer une relation
Mapper les métadonnées de la Databricks Lakehouse Platform
Qu'est-ce qu'un modèle sans données ? Les utilisateurs de Stardog peuvent se connecter à une variété de sources de données structurées, semi-structurées et non structurées en persistant ou en virtualisant les données, ou une combinaison des deux, quand et où cela est pertinent. Dans Designer, il est facile de connecter des données à partir de sources existantes comme Delta Lake pour connecter les métadonnées à partir de tables spécifiées par l'utilisateur. Cela permet un accès initial à ces données via sa couche de virtualisation sans les déplacer ou les copier dans le graphe de connaissances. La couche de virtualisation traduit automatiquement les requêtes entrantes de Stardog de SPARQL basé sur des standards ouverts en requêtes SQL optimisées et poussées dans Databricks SQL.
Ajoutez une nouvelle source de données comme ressource de projet
Cliquez pour ajouter une nouvelle ressource de projet et sélectionnez parmi les connexions disponibles, comme Databricks. Cette connexion exploite le nouveau point de terminaison SQL récemment publié par Databricks. Définissez une portée pour les données et spécifiez toute propriété supplémentaire. Utilisez le volet d'aperçu pour jeter un coup d'œil rapide aux données avant de les ajouter à votre projet.
Incorporer des données supplémentaires provenant de divers emplacements
Designer simplifie l'incorporation de données provenant d'autres sources de données et fichiers tels que des CSV, pour les équipes cherchant à effectuer des analyses de données ad hoc, en combinant des données de Delta avec ces nouvelles informations. Une fois ajoutée en tant que ressource, il suffit d'ajouter un lien et de faire glisser-déposer vers une classe pour mapper les données. Donnez un nom significatif au mappage, spécifiez une colonne de données pour l'identifiant principal, le libellé et toute autre colonne de données qui correspond aux attributs de l'entité.
Mapper des données d'une ressource de projet à une classe
Publiez votre travail
Dans Designer, vous pouvez publier le modèle et les données de ce projet directement sur votre serveur Stardog pour une utilisation dans Stardog Explorer. Le designer vous permet également de publier et de consommer la sortie du graphe de connaissances de diverses manières. Vous pouvez publier directement dans un dossier zippé de fichiers, y compris votre modèle et vos mappages, vers votre système de contrôle de version.
Publiez directement dans une base de données Stardog
Une fois les données publiées sur Stardog, les analystes de données peuvent également utiliser des outils de BI populaires comme Tableau pour se connecter via le point d'accès BI/SQL de Stardog afin d'extraire des données à travers la couche sémantique pour un rapport ou un tableau de bord. Le schéma généré automatiquement dans tout outil compatible SQL permet aux utilisateurs d'écrire des requêtes SQL sur le graphe de connaissances. Les requêtes provenant de la couche SQL sont automatiquement traduites en SPARQL, le langage de requête du graphe de connaissances, et transmises en utilisant des requêtes optimisées par source générées automatiquement, via la couche virtuelle, pour le calcul à la source, dans ce cas, Databricks via le point d'accès Databricks SQL. Les mêmes informations peuvent également être mises à la disposition des utilisateurs de Databricks dans un notebook en utilisant l'API Python de Stardog, pystardog. Vous pouvez également intégrer le graphe virtuel pour une utilisation directe dans vos applications en utilisant l'API GraphQL de Stardog. La couche sémantique au-dessus du lakehouse fournit un environnement unique pour tous les types d'utilisateurs et leurs outils préférés, en maintenant les opérations soutenues par un ensemble cohérent de données.
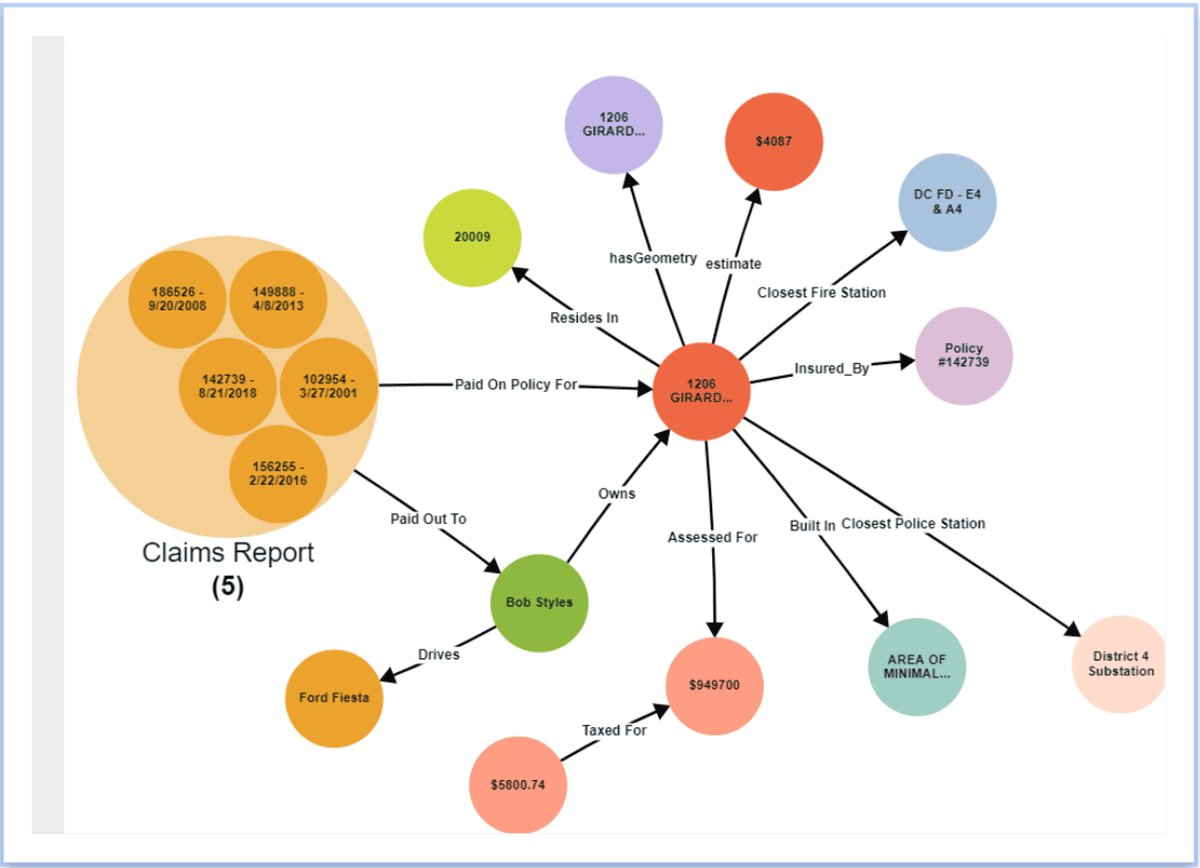
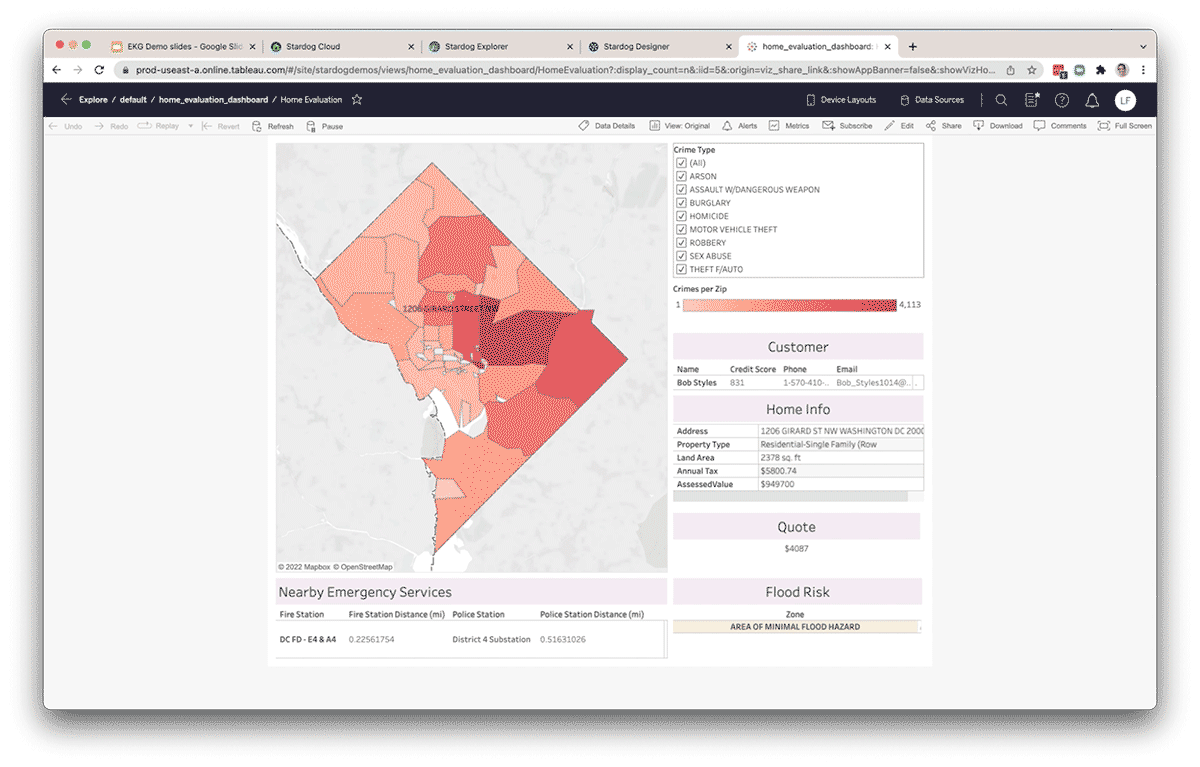
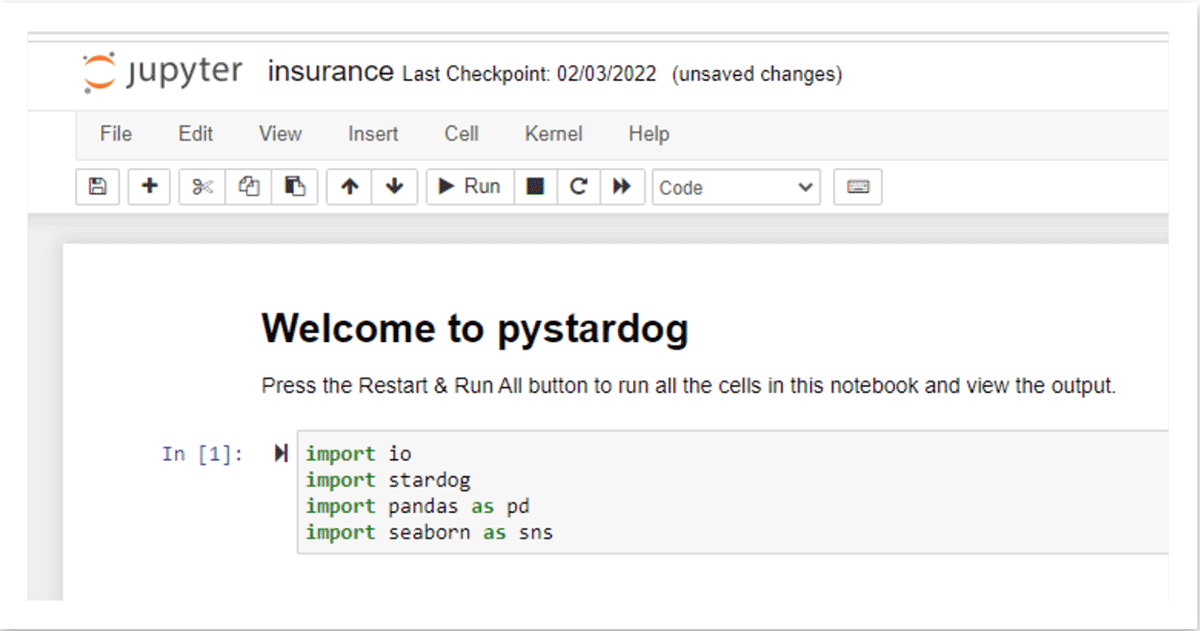
Augmentez la productivité & découvrez de nouvelles perspectives
En organisant les données dans un graphe de connaissances, les équipes de données augmentent leur productivité en réduisant le temps passé à organiser des données provenant de sources externes pour l'analyse ad hoc. Les données externes à Databricks peuvent être fédérées via la couche de virtualisation de Stardog et connectées aux données internes à Databricks. De plus, de nouvelles relations peuvent être déduites entre les entités sans les modéliser explicitement dans le graphe de connaissances en utilisant des techniques comme l'inférence statistique et/ou logique. Comme Databricks et Stardog fonctionnent ensemble de manière transparente, la combinaison offre une expérience de bout en bout qui simplifie les requêtes et analyses inter-domaines complexes. De plus, la couche sémantique devient une couche vivante, partageable et facile à utiliser dans le cadre d'une fondation de tissu de données d'entreprise, fournissant des connaissances à l'échelle de l'entreprise pour soutenir de nouvelles initiatives axées sur les données.
Démarrer avec Databricks et Stardog
Dans ce blog, nous avons fourni un aperçu général de la manière dont Stardog permet une couche de données sémantique alimentée par un graphe de connaissances sur la plateforme Databricks Lakehouse. Pour un aperçu approfondi, consultez notre démo détaillée. Stardog fournit aux travailleurs du savoir des informations critiques juste-à-temps sur un univers connecté d'actifs de données pour dynamiser leur analyse et accélérer la valeur de leurs investissements en data lake. En utilisant Databricks et Stardog ensemble, les équipes de données et d'analyse peuvent rapidement établir un tissu de données qui évolue avec les besoins croissants de votre organisation.
Pour commencer avec Databricks et Stardog, demandez un essai gratuit ci-dessous :
https://www.databricks.com/try-databricks
https://cloud.stardog.com/get-started
https://www.stardog.com/learn-stardog/
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.