Delta Live Tables annonce de nouvelles fonctionnalités et des optimisations de performances
DLT annonce le développement d'Enzyme, une optimisation des performances spécialement conçue pour les charges de travail ETL, et lance plusieurs nouvelles fonctionnalités, dont l'autoscaling amélioré
par Paul Lappas et Michael Armbrust
Depuis la disponibilité de Delta Live Tables (DLT) sur tous les clouds en avril (annonce), nous avons introduit de nouvelles fonctionnalités pour faciliter le développement, amélioré la gestion automatisée de l'infrastructure, annoncé une nouvelle couche d'optimisation appelée Project Enzyme pour accélérer le traitement ETL, et activé plusieurs fonctionnalités d'entreprise et améliorations de l'UX.
DLT permet aux analystes et aux ingénieurs de données de créer rapidement des pipelines ETL de streaming ou batch prêts pour la production en SQL et Python. DLT simplifie le développement ETL en vous permettant de définir votre pipeline de traitement de données de manière déclarative. DLT comprend les dépendances de votre pipeline et automatise la quasi-totalité des complexités opérationnelles.
Delta Live Tables alimente désormais des cas d'utilisation ETL en production dans des entreprises leaders du monde entier depuis sa création. DLT est utilisé par plus de 1 000 entreprises, des startups aux grandes entreprises, notamment ADP, Shell, H&R Block, Jumbo, Bread Finance et JLL.
Avec DLT, les ingénieurs peuvent se concentrer sur la fourniture de données plutôt que sur l'exploitation et la maintenance des pipelines, et tirer parti des fonctionnalités clés. Nous avons activé plusieurs fonctionnalités d'entreprise et améliorations de l'UX, notamment la prise en charge de la capture des données modifiées (CDC) pour capturer efficacement et facilement les données arrivant en continu, et lancé une préversion de la mise à l'échelle automatique améliorée qui offre des performances supérieures pour les charges de travail de streaming. Examinons les améliorations en détail :
Faciliter le développement
Nous avons étendu notre interface utilisateur pour faciliter la gestion du cycle de vie de bout en bout de l'ETL.
Améliorations de l'UX. Nous avons étendu notre interface utilisateur pour faciliter la gestion des pipelines DLT, visualiser les erreurs et fournir aux membres de l'équipe un accès aux ACL de pipeline riches. Nous avons également ajouté une interface utilisateur d'observabilité pour visualiser les métriques de qualité des données en une seule vue, et il est devenu plus facile de planifier des pipelines directement depuis l'interface utilisateur. En savoir plus.
Bouton Planifier le pipeline. DLT vous permet d'exécuter des pipelines ETL en continu ou en mode déclenché. Les pipelines continus traitent les nouvelles données au fur et à mesure de leur arrivée et sont utiles dans les scénarios où la latence des données est critique. Cependant, de nombreux clients choisissent d'exécuter les pipelines DLT en mode déclenché pour contrôler plus étroitement l'exécution du pipeline et les coûts. Pour faciliter le déclenchement des pipelines DLT selon un calendrier récurrent avec Databricks Jobs, nous avons ajouté un bouton « Planifier » dans l'interface utilisateur DLT pour permettre aux utilisateurs de définir un calendrier récurrent en quelques clics seulement, sans quitter l'interface utilisateur DLT. Vous pouvez également voir un historique des exécutions et naviguer rapidement vers les détails de votre Job pour configurer les notifications par e-mail. En savoir plus.
Capture des données modifiées (CDC). Avec DLT, les ingénieurs de données peuvent facilement implémenter la CDC avec une nouvelle API déclarative APPLY CHANGES INTO, en SQL ou en Python. Cette nouvelle fonctionnalité permet aux pipelines ETL de détecter facilement les modifications des données sources et de les appliquer aux jeux de données dans le lakehouse. DLT traite les modifications de données dans Delta Lake de manière incrémentielle, en marquant les enregistrements à insérer, mettre à jour ou supprimer lors du traitement des événements CDC. En savoir plus.
Dimensions à variation lente (SCD) CDC — Type 2. Lorsque vous traitez des données modifiées (CDC), vous devez souvent mettre à jour les enregistrements pour suivre les données les plus récentes. SCD Type 2 est une méthode pour appliquer des mises à jour à une cible afin que les données d'origine soient préservées. Par exemple, si une entité utilisateur dans la base de données déménage à une autre adresse, nous pouvons stocker toutes les adresses précédentes de cet utilisateur. DLT prend en charge SCD type 2 pour les organisations qui nécessitent de maintenir une piste d'audit des modifications. SCD2 conserve un historique complet des valeurs. Lorsque la valeur d'un attribut change, l'enregistrement actuel est fermé, un nouvel enregistrement est créé avec les valeurs de données modifiées, et ce nouvel enregistrement devient l'enregistrement actuel. En savoir plus.
Gestion automatisée de l'infrastructure
Mise à l'échelle automatique améliorée (préversion). Le dimensionnement manuel des clusters pour des performances optimales compte tenu des volumes de données changeants et imprévisibles – comme avec les charges de travail de streaming – peut être difficile et entraîner un surprovisionnement. La mise à l'échelle automatique actuelle des clusters n'est pas consciente des SLO de streaming et peut ne pas monter en charge rapidement même si le traitement est en retard par rapport au taux d'arrivée des données, ou elle peut ne pas réduire la charge lorsque celle-ci est faible. DLT utilise un algorithme de mise à l'échelle automatique amélioré spécialement conçu pour le streaming. La mise à l'échelle automatique améliorée de DLT optimise l'utilisation des clusters tout en garantissant que la latence globale de bout en bout est minimisée. Pour ce faire, elle détecte les fluctuations des charges de travail de streaming, y compris les données en attente d'ingestion, et provisionne la bonne quantité de ressources nécessaires (jusqu'à une limite spécifiée par l'utilisateur). De plus, la mise à l'échelle automatique améliorée arrêtera gracieusement les clusters lorsque l'utilisation est faible, tout en garantissant l'évacuation de toutes les tâches pour éviter d'impacter le pipeline. Par conséquent, les charges de travail utilisant la mise à l'échelle automatique améliorée économisent des coûts car moins de ressources d'infrastructure sont utilisées. En savoir plus.
Mise à niveau et canaux de publication automatisés. Les clusters Delta Live Tables (DLT) utilisent un runtime DLT basé sur Databricks runtime (DBR). Databricks met à niveau automatiquement le runtime DLT environ tous les 1 à 2 mois. DLT mettra à niveau automatiquement le runtime DLT sans nécessiter d'intervention de l'utilisateur final et surveillera la santé du pipeline après la mise à niveau. Si DLT détecte que le pipeline DLT ne peut pas démarrer en raison d'une mise à niveau du runtime DLT, nous rétablirons le pipeline à la version précédente connue comme étant fonctionnelle. Vous pouvez obtenir des avertissements précoces sur les changements majeurs des scripts d'initialisation ou d'autres comportements DBR en utilisant les canaux DLT pour tester la version préliminaire du runtime DLT et être informé automatiquement en cas de régression. Databricks recommande d'utiliser le canal CURRENT pour les charges de travail de production. En savoir plus.
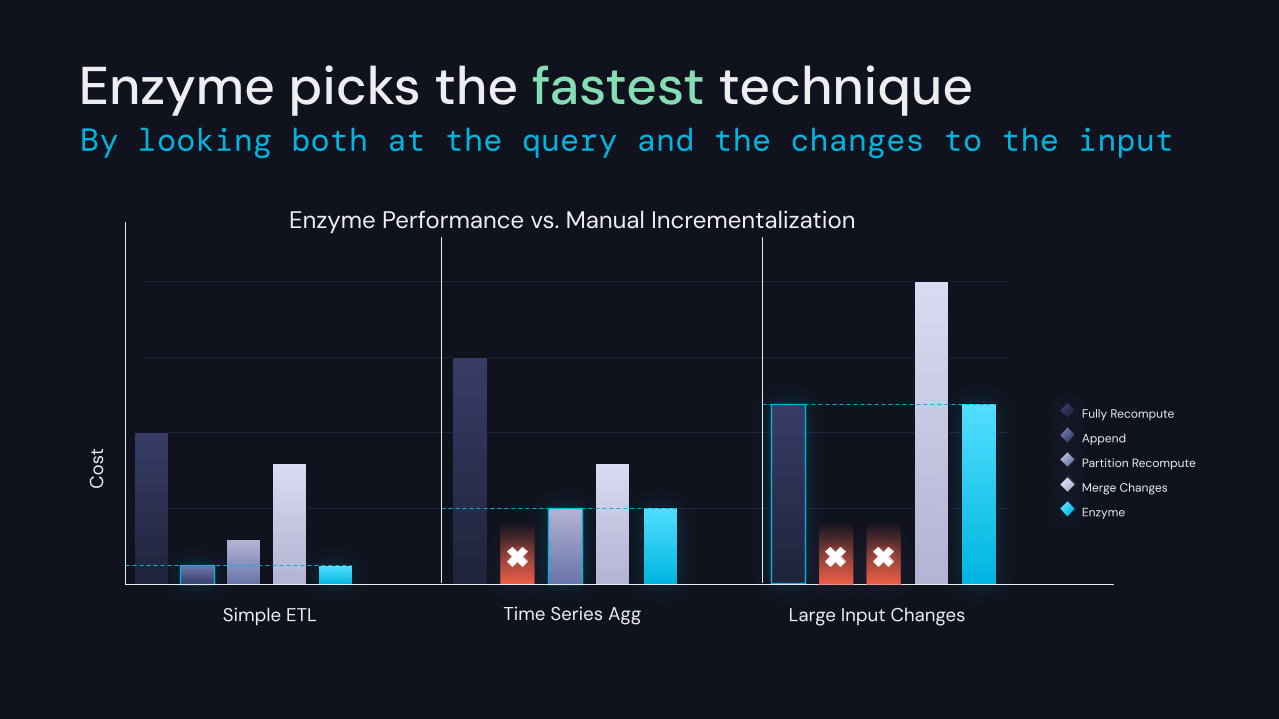
Annonce d'Enzyme, une nouvelle couche d'optimisation conçue spécifiquement pour accélérer le processus d'ETL
La transformation des données pour les préparer à l'analyse en aval est une condition préalable à la plupart des autres charges de travail sur la plateforme Databricks. Bien que SQL et DataFrames permettent aux utilisateurs d'exprimer relativement facilement leurs transformations, les données d'entrée changent constamment. Cela nécessite une recomputation des tables produites par l'ETL. Recalculer les résultats à partir de zéro est simple, mais souvent trop coûteux à l'échelle à laquelle opèrent nombre de nos clients.
Nous sommes heureux d'annoncer que nous développons le projet Enzyme, une nouvelle couche d'optimisation pour l'ETL. Enzyme maintient efficacement à jour une matérialisation des résultats d'une requête donnée stockée dans une table Delta. Il utilise un modèle de coûts pour choisir entre diverses techniques, y compris les techniques utilisées dans les vues matérialisées traditionnelles, le streaming delta-vers-delta et les modèles ETL manuels couramment utilisés par nos clients.
Commencez avec Delta Live Tables sur le Lakehouse
Regardez la démo ci-dessous pour découvrir la facilité d'utilisation de DLT pour les ingénieurs de données et les analystes :
Si vous êtes un client Databricks, suivez simplement le guide pour commencer. Lisez les notes de mise en production pour en savoir plus sur ce qui est inclus dans cette version GA. Si vous n'êtes pas un client Databricks existant, inscrivez-vous pour un essai gratuit, et vous pouvez consulter nos tarifs DLT détaillés ici.
Rejoignez la conversation dans la Communauté Databricks où des pairs passionnés de données discutent des annonces et des mises à jour du Data + AI Summit 2022. Apprenez. Réseautez. Célébrez.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.